
작성자 : 김태욱
Contents
- Community Structure in Networks
- Network Communities
- Louvain Algorithm
- Detecting Overlapping Communities: BigCLAM
Community Structure in Networks
1. Community Structure in Networks
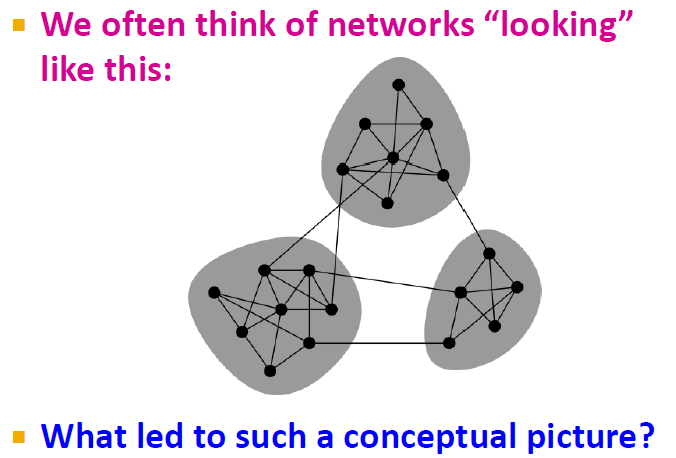
이번 챕터의 목적, 즉 Community Structure는 '서로간에 밀접하게(densely) 연결된 노드들의 집합을 구분하는 것'입니다.
알고리즘에 들어가기 전에, 사회과학적으로 군집이 생성되는 원리에 대해 먼저 보겠습니다.
Granovetter's Answer
Granovetter는 '사람들은 어떻게 새로운 직장을 찾는가?'에 대한 연구를 진행
-> 사람들은 자주 만나는 친한 친구가 아닌, 드물게 만나는 지인(Acquaintances)을 통해 직장에 대한 정보를 얻는다고 밝혔습니다.
이런 관계를 생각했을 때, 두 가지 관점의 frendships으로 나누어집니다.
- Structual: 링크가 네트워크의 어떤 부분을 연결하는가?
- Interpersonal: 링크가 강한 연결관계를 가지고 있는가 약한 연결관계를 가지고 있는가?
Triadic Closure
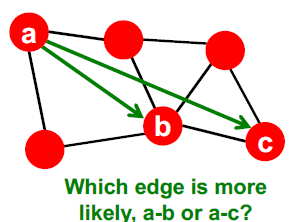
-
어떤 edge가 더 연결될 가능성이 높은가?
답은 a-b입니다. a-c는 3칸 떨어져 있지만 a-b는 두 명의 공통된 이웃을 가지고 있기 때문에 a-b의 edge가 더 연결될 가능성이 높습니다.
Granovetter's Explanation
-
First Point: Structure
- 구조적으로 결속된(embedded) edge들은 사회적으로도 강하게 연결되어 있음.
- 서로 다른 네트워크를 연결하고 있는(long-range) edge들은 사회적으로 약하게 연결되어 있음.
-
Second point: Information
- 구조적으로 결속된(embedded) edge들은 정보 접근의 관점에서 매우 중복(redundant)됨.
- Long-range edge들은 지인(Acquaintances)들로부터 새로운 정보를 얻을 수 있게 됨.
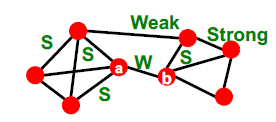
- S
Structure: Socially Strong
Information: Redudant - W
Structure: Socially Weak
Information: Useful information
Edge Overlap
위의 이론은 Onnela에 의해 2007년 증명되었는데, 사용한 데이터는 EU 소속 국가 인구의 20%의 휴대폰 네트워크 데이터이며 Edge Weight는 통화횟수로 정의하였습니다.
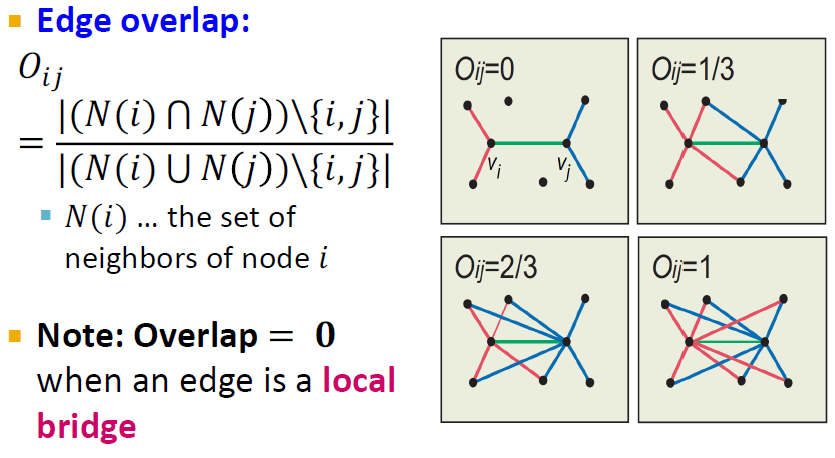
네트워크에서 얼마나 많은 지인(nodes)을 공유하고 있는가(overlap)에 대한 정보를 나타내는 수치를 Oij로 정의했습니다.
여기서 분자는 두 노드간의 겹치는 지인의 숫자이며, 분모는 두 노드의 모든 지인의 숫자(합집합)입니다.
즉, 지인을 공유할수록 해당 수치는 1에 가까워집니다.
2. Network Communities
Granovetter's의 이론에 따르면 네트워크는 강하게 연결된 노드의 집합(tightly connected sets of nodes)입니다.
- Network communities: 내부적으로 연결된 많은 노드와 몇몇 외부적으로 연결된 노드들로 이루어진 집합.
Modularity Q
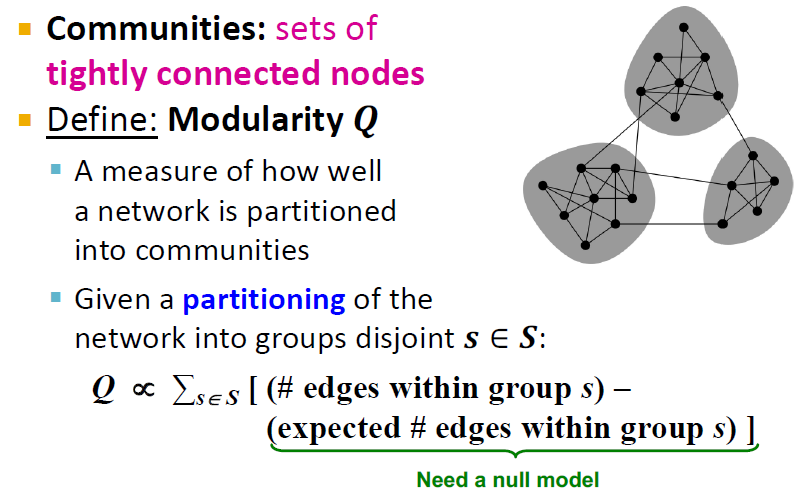
Communities는 강하게 연결된 노드들의 집합인데, 이 Communities를 찾기 위해 Modularity를 이용하며 이것을 최대화 하는것이 Communities입니다.
- Modularity Q란?
네트워크가 communities로 얼마나 잘 나누어져(partitioning) 있는가에 대한 수치 - partitioning이란?
하나의 노드가 어떠한 그룹(community)에 속하도록 네트워크를 쪼개는 것.
Q = community s의 edge 수 - 기대되는 community s의 edge 수
이 수치가 클수록(즉, edge수 차이가 클수록) 매우 strong group이라고 할 수 있습니다.
따라서, "기대되는 community s의 edge 수"를 찾기 위해 null model이 필요합니다.
Null model : Configuration Model

Real network G는 n개의 노드와 m개의 엣지를 가지고 있으며, 이를 이용해 rewired network G'을 만들 수 있습니다.
G'은 G와 같은 차수의 분포(degree distribution)를 가지고 있지만 uniformly random하게 연결되어 있으며, multigraph로 가정합니다.
노드 i, 노드 j의 degree를 라고 할 때, edge의 기대값은 입니다.
는 노드 j와 연결될 확률입니다. 또한 모든 노드는 2번씩 count되기 때문에 2m이 분모가 되며, multi-graph이기 때문에 노드 i의 degree인 를 곱해주는 것입니다.
Modularity

- : 두 노드 사이의 edge 개수
- : expected number of edges
- : Normalizing constant
m개의 엣지를 가진 그래프가 가질 수 있는 엣지의 합이 최대 2m 였으므로, 2m으로 나눠줘 normalizing 해주면 Q는 -1과 1사이의 값을 가지게 됩니다.
또한 보통 0.3과 0.7 사이 정도면 Significant Community Structure가 있음을 의미합니다.
강의 중 질문에서 Q의 값이 negative일 때의 의미는 서로간에 거의 상관이 없는, 연결되어 있지 않은 community를 정의한 경우라고 합니다.(연결 되어야 하지만 연결되지 않은 경우)

Equivalently modularity는 위와 같이 표현될 수 있으며 와 는 노드들의 community입니다. 는 indicator function으로 같은 그룹일시 1, 아니면 0 입니다.
3. Louvain Algorithm
Community detection을 위한 Greedy Algorithm이며, 시간복잡도 O(nlogn)으로 매우 빠른 휴리스틱 알고리즘 입니다.
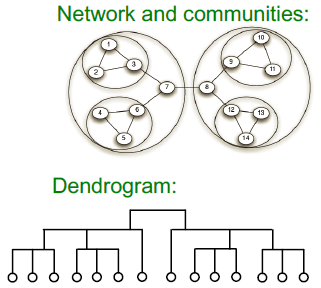
가중치 그래프도 지원하고, Hierarchical communities detection도 가능한데 이 경우 Dendrogram을 통해 네트워크의 Hierarchical한 구조를 나타낼 수 있습니다.
이 알고리즘은 빠르고, 수렴도 빠르고, High Modularity output을 도출해주기 때문에 네트워크에 널리 사용됩니다.
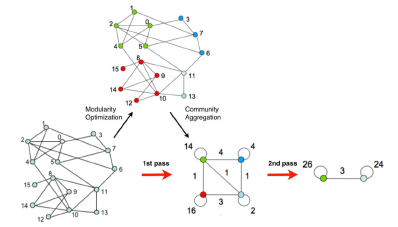
- Phase 1:
- 가장 처음은 각각의 노드가 single community라고 생각
- 노드 i를 어떤 neighbor j의 community 속에 넣으면 발생하는 modularity 값의 증가량(Modularity delta: )을 측정
- 노드 i를, 가장 큰 를 발생시키는 community로 이동
- 의 변화가 없을 때까지 Phase1 계속 실행
- Phase 2:
- Phase 1에서 찾은 community들을 모아 single super-node를 만들어 줌.
- Super-node들 사이에 하나의 Edge라도 있으면 연결
- 두 Super-node 간의 edge 가중치는 커뮤니티 간 모든 Edge 가중치들의 합
- 다시 Phase 1으로(한 개의 Community를 찾을 때까지 계속 반복).
- Phase 1에서 찾은 community들을 모아 single super-node를 만들어 줌.

: 노드 i를 C community에 추가시켰을 때 Q의 증가량
: D community 에서 노드i를 제거시켰을 때 Q의 증가량
=
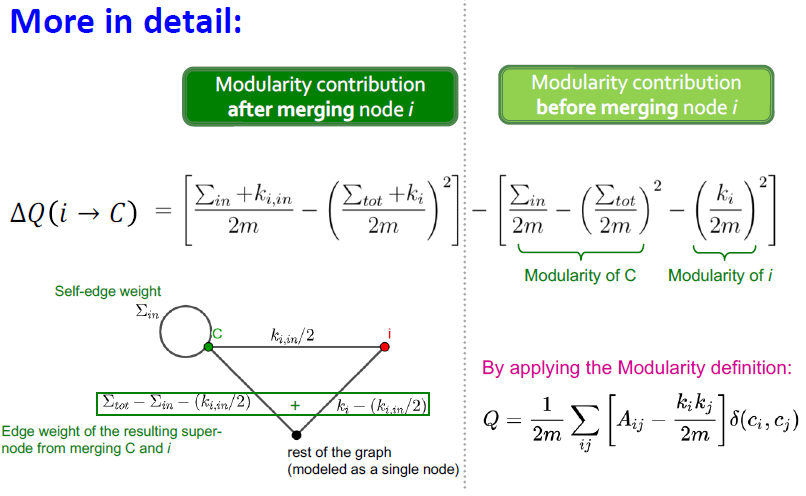
위의 그림은 식을 더 구체적으로 보여주는 내용입니다.
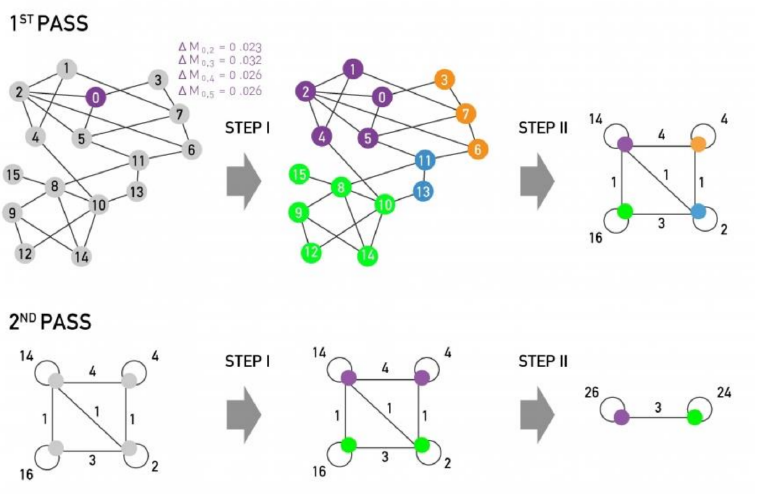
위의 그림은 Louvain algorithm의 전체적인 과정을 나타냅니다.
4. Detecting Overlapping Communities: BigCLAM
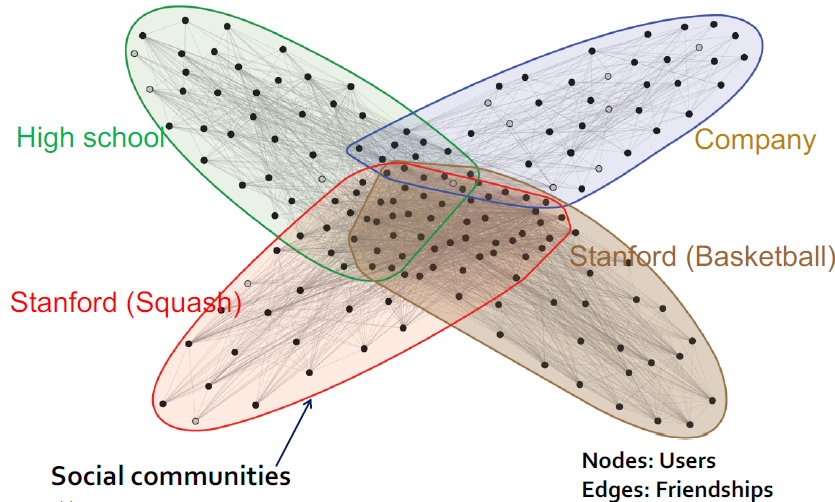
앞에서의 Community들은 모두 Non-Overlapping 이었지만 실제로는 고등학교 동창이면서 대학교 동창일수도 있는 것처럼 Community가 겹치기도 합니다. 여기서는 이에 해당하는 Overlapping Community를 Detect할 수 있는 방법을 알아봅니다.
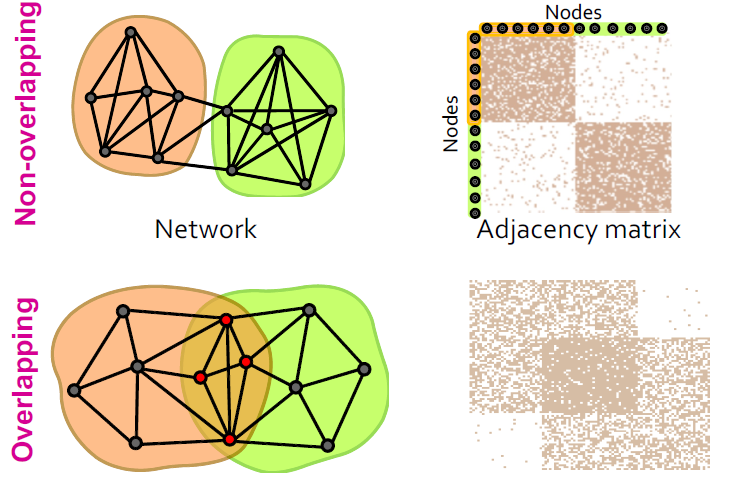
이는 인접행렬(adjacency matrix)에서도 확인할 수 있는데 만약 community가 discrete하다면 위의 그림처럼 겹치는(overlap) 부분이 존재하지 않을 것이며,
반대로 한 노드가 여러 community에 속할 수 있다면 아래의 그림처럼 겹치는 부분이 존재할 것 입니다.

마찬가지로 Overlapping Communities도 2가지 step으로 진행됩니다.
- Step1
- Node Community affiliation에 근거하여 graph generative model을 정의
- Community Affiliation Graph Model (AGM)
- Step2
- Graph G가 AGM을 통해 만들어졌다는 가정 하에 진행.
- AGM의 파라미터는 Graph G를 만드는데 사용되며, AGM이 G를 generative하도록 파라미터를 학습시킴. (MLE)
- 여기서 파라미터는 node가 community에 얼마나 속하는지 알려줌.
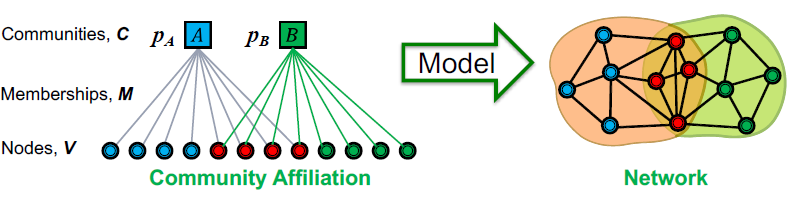
왼쪽 그림의 A, B는 communities이며, 밑의 점들은 네트워크 노드 입니다. community와 노드가 이어져 있다면 해당 노드는 해당 community에 속해있는 것이며, 양쪽 community에 모두 이어져 있다면 양쪽 모두에 속하는 것입니다.
이러한 Community affiliation가 모델을 거쳐 네트워크(오른쪽 그림)가 됩니다.
- Generative model issue: 어떻게 edges를 design할 것인가?

- Model Parameters:
- : 어떤 노드가 c community와 연결될 확률
- : 노드 u, 노드 v의 공통 communities
- : u,v가 서로 연결되어 있을 확률,
1 - 두 노드의 공통 community에 속하지 않을 확률들의 곱
-> 적어도 하나의 공통 커뮤니티에 속할 확률
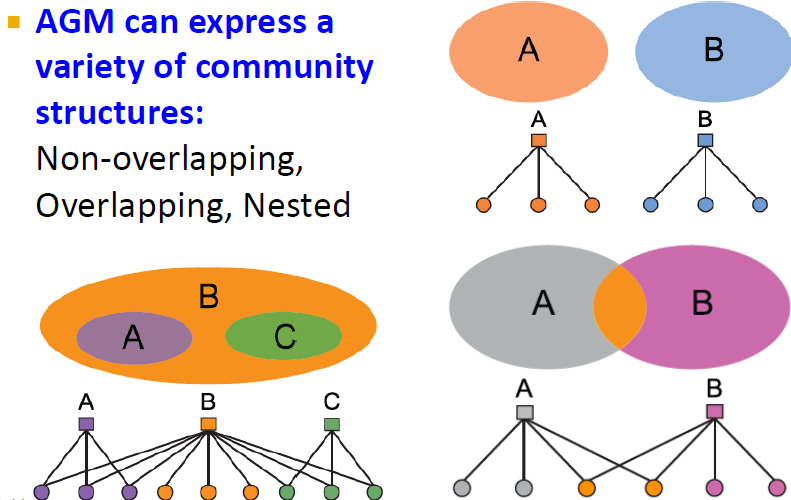
AGM은 Overlapping 양상에 따라서 다양한 Community Structure를 표현할 수 있음.
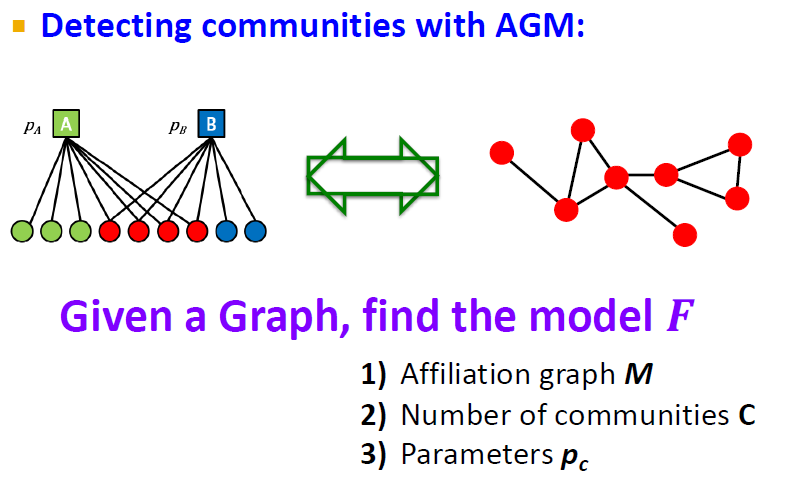
지금까지는 model로 네트워크를 생성했지만, 반대로 네트워크로 model(어떤 노드가 어떤 커뮤니티에 속하는지)도 만들어야 합니다.
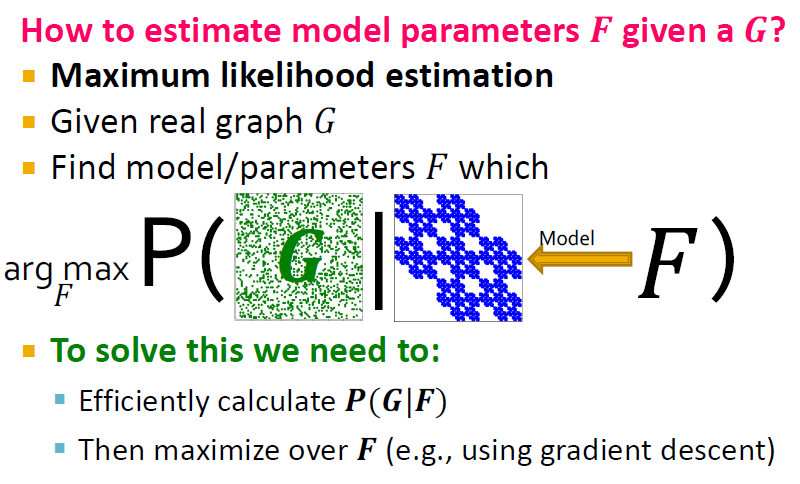
- Maximum Likelihood Estimation 사용
- F에서 생성된 network가 G이길 바라기 때문에 G를 잘 만들어낼 수 있는 F(model/parameter)를 찾으면 됨. -> real G와 가장 비슷한 G를 만들자!
이를 위해 F(model/parameter)가 주어졌을 때 G가 나올 확률(Graph Probability)을 구하고, 이 확률을 최대화(argmax) 시키는 F를 찾아야 합니다.
이것을 위해 우리는 (1) F가 주어졌을 때 G가 나올 확률을 구해야하고, 이 확률을 (2) 최대화시키는 F를 찾아야 한다.
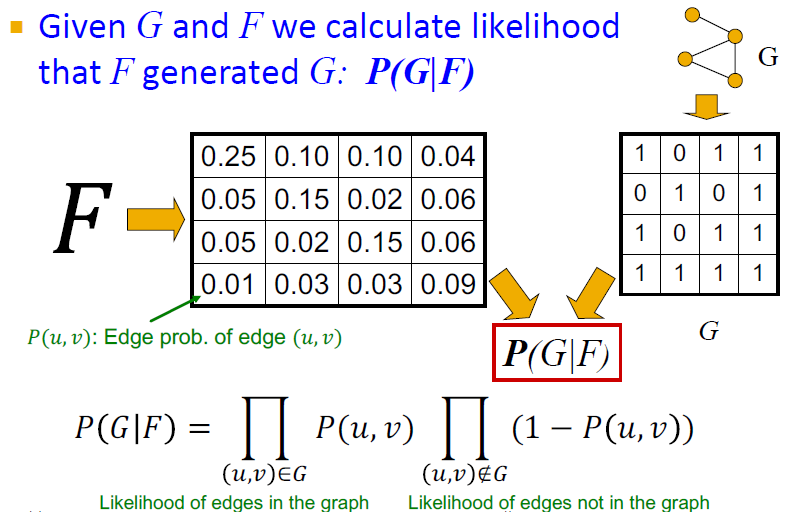
- Graph Likelihood : F가 주어졌을 때 G가 나올 확률
- 오른쪽 행렬에서 일 때 1, 일 때 0
"Relaxing" AGM: Towards P(u,v)
위의 모델은 0,1을 사용하여 노드들이 given community의 member인지 아닌지를 따졌지만, 여기선 모든 node community membership의 strength를 따져보기로 합니다.
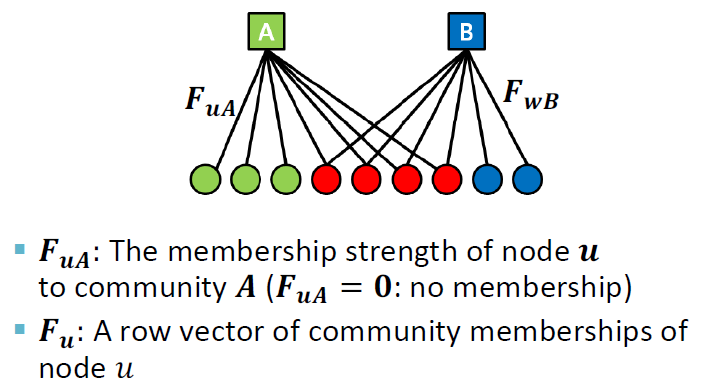
- : 노드 u가 각각의 커뮤니티에 속할 확률을 가진 벡터
- : 노드 u가 community A에 속할 확률

- : 노드 u와 노드v가 각각의 커뮤니티에 동시에 속할 확률 (하나의 노드라도 어떤 커뮤니티에 할 확률이 0이라면 둘의 product는 0)
노드 u와 v가 각각의 커뮤니티에 동시에 속할 확률은, shared memberships의 strength에 비례합니다.
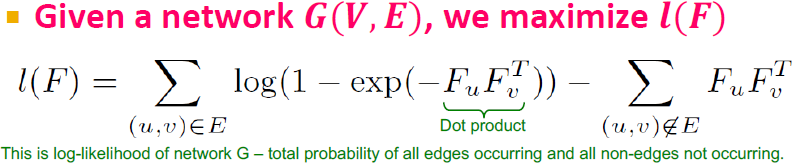
- : log-likelihood
결국 BigCLAM Model은 F가 주어졌을 때 G가 나올 확률을 구하고, 이 확률을 최대화시키는 F를 찾고자 하는 것입니다. 즉, log-likelihood를 최대화 하는 F를 찾는 것입니다.
Reference
https://tobigs.gitbook.io/tobigs-graph-study/chapter4.-community-structure-in-networks
https://data-weirdo.github.io/data/2020/09/05/data-graph-04.communities

4개의 댓글

1. Community
- Definition : 서로간에 밀접하게(densely) 연결된 노드들의 집합
- Edge Overlap : 겹치는 지인 (교집합) / 모든 노드(합집합), 네트워크에서 얼마나 많은 지인(nodes)을 공유하고 있는가(overlap)에 대한 정보를 나타내는 수치
2. Modularity
- Definition : 네트워크가 communities로 얼마나 잘 나누어져(partitioning) 있는가에 대한 수치
- Community 를 찾기 위해 modularity 가 최대가 되는 값을 찾습니다.
- Q = community s의 edge 수 - 기대되는 community s의 edge 수, 이 수치가 클수록(즉, edge수 차이가 클수록) 매우 strong group이라고 할 수 있습니다.
기대되는 communitys의 edge 수를 찾기 위해 Configuration Model (null model) 이 필요합니다.
-> n개의 node와 m개의 edge가 있는 그래프 G 에서, edge를 rewire 해서 random graph인 G' network 를 만듭니다.
3. Louvain Algorithm
- Definition : Community detection을 위한 Greedy Algorithm, hierarchy로 community를 찾습니다.
- Step 1. Modularity Optimization -> Step 2. Community Aggregation 순서로 진행됩니다.
- 노드 i를 C community에 추가시켰을 때 Q의 증가량 + D community 에서 노드i를 제거시켰을 때 Q의 증가량 으로 계산합니다.
4. Detecting Overlapping Community
- Step 1. AGM (Community Affiliation Graph Model) 정의 -> Step 2. AGM으로 그래프 G가 generate 되었다고 가정하고, G가 최적 parameter를 가지고 있는 그래프가 되는 AGM을 찾습니다. -> 이를 통해 community를 찾습니다.
- (1 - 두 노드의 공통 community에 속하지 않을 확률들의 곱) = 적어도 하나의 공통 커뮤니티에 속할 확률 기반으로 확률값을 정의합니다.
네트워크를 잘 설명하는 최적의 model(어떤 노드가 어떤 커뮤니티에 속하는지)을 만들기 위해서는, MLE 방법론으로 접근합니다.
- F(model/parameter)가 주어졌을 때 G가 나올 확률(Graph Probability)을 구하고, 이 확률을 최대화(argmax) 시키는 F를 찾습니다.
자세한 건 리뷰에 적었어요 좋은 강의 감사함니다 ~

이번 강의에서는 community structure와 이를 detection하는 방법인 BigCLAM에 대하여 배웠습니다.
community structure는 서로 밀접하게 연결된 노드들의 집합 구조입니다. Granovetter는 사람들이 구직할 때 주로 동네 친구가 아닌 그냥 아는 사람을 통해 일자리를 소개받는다는 점을 발견했습니다. 이러한 관계를 고려했을 때, 네트워크에서의 연결 관계는 structural과 interpersonal 2가지 관점으로 나눌 수 있습니다. 중요한 점은 structural 관점으로는 dense하게 연결되어있더라도 interpersonal 한 관점으로는 weak edge냐 strong edge냐에 따라 정보의 교류가 다를 수 있다는 것입니다. interpersonal한 관점에서의 edge weight를 구하는 방법은 edge overlap을 계산하는 것입니다. 단순히 이해해보면 두 노드 사이에 서로 같은 이웃을 얼마나 공유하는지 비교하면 됩니다. common neighbor를 많이 공유할 수록 1에 가깝고 그 반대는 0에 가까워집니다.
복잡한 네트워크 속에서 많은 node의 모임 중 community가 될 수 있는지부터 정하기 위해서 modularity를 사용할 수 있습니다. 네트워크의 communities마다 분할 정도를 나타내는 modularity Q를 정의하고 높은 점수를 가진 community가 중요한 것으로 간주할 수 있습니다. Q를 구하는 방법은 원래 community의 edge수에 통계적 모델링인 null model에 따라 기대되는 edge 수를 빼면됩니다. modularity Q를 구하였으니 Louvain algorithm으로 hierarchical하게 community를 찾을 수 있습니다. 이 알고리즘의 시간복잡도는 O(nlogn)이며 dendrogram으로 hierarchy를 표현할 수 있습니다. 이 알고리즘은 각 노드를 single community라 정의하고 특정 노드의 community를 바꾸면서 Q의 증가량을 비교하여 clustering을 진행합니다. 그리고 2가지 score를 매기는데, node를 새로운 community에 추가했을 때 증가하는 Q와 기존 community에서 node를 제거했을 때 증가하는 Q를 합하여 최종 Q를 도출합니다.
이렇게 interpersonal한 관점에서 community를 규명할 수 있는데, 모든 군집이 명확히 구분되지는 않고 겹치는 부분이 있을 수 있습니다. 이러한 overlapping community를 탐색하기 위해서는 BigCLAM 모델을 사용합니다. 이 모델은 node community affiliation를 바탕으로 학습하는 graph generative model입니다. model이 우리에게 주어진 그래프를 생성하도록 학습하고 생성된 노드가 원래 community에 얼마나 속해있는지 확인하여 loss를 구합니다. 이 때 각 community에 해당되는 edge type이 존재하는데, 모든 노드마다 복잡한 연결관계를 나타낼 수 있어야합니다. 따라서 노드가 서로 연결 되어있을 확률을 common community에 속하지 않을 확률들의 곱 즉, 적어도 하나의 common community를 가질 확률을 구합니다. AGM을 통해 다양한 community structure를 탐색할 수 있으나 지도학습인만큼 모든 community 종류의 정보가 주어져야합니다. AGM으로 regression task도 진행할 수 있습니다. MLE를 사용하여 원래 그래프를 복원하는 학습을 진행하고 주어진 community의 strength를 각 노드마다 구할 수 있습니다. 이 strength는 두 노드가 common community를 가질 확률로 하나라도 커뮤니티에 속할 확률이 0이라면 둘의 product는 0이 됩니다. 이 확률은 shared memberships의 strength에 비례합니다. 좋은 강의 ㄳ

이번 강의에서는 네트워크 구조를 분석하고 연결된 정도를 평가하는 방법들에 대해 소개한다.
1. Community Structure in Networks
2. Modularity
3. Louvain Algorithm
4. Detecting Overlapping Communities
감사합니다 :)