[Paper Review] (2018, IEEE) Self-Attentive Sequential Recommendation (SASRec)
Recommender_System

작성자: 이예지

Overview

- 해당 논문은 기존의 sequential recommender인 Markov Chains(MC)과 RNN 계열의 단점을 동시에 보완하고자 하였습니다.
- 이를 위해 당시 NLP task에서 sota인 Transformer 모델을 추천 시스템에 도입하였습니다.
(Sequential data 특성 상, NL model에 적용하는 것은 어렵지 않기 때문에 해당 논문에서도 모델에 큰 변형을 가하지는 않았습니다.) - 제안된 모델은 기존의 추천시스템에서 좋은 성능을 보여주던 MC/CNN/RNN based model을 뛰어넘는 실험 결과를 보여주었습니다.
이번 리뷰에서는 Transformer의 핵심만을 간단히 살펴보고, 기존 Transformer와의 차이를 위주로 진행하겠습니다.
Introduction

- Sequential recommender system은 유저의 최근 행동의 context를 기반으로 한 추천을 목표로 하고 있습니다.
- 이런 sequential recommender model을 개발하기 힘든 점은 입력 공간의 크기가 매우 크다는 것입니다.
Context로 사용되는 유저의 행동에 따라 지수적으로 입력 공간이 증가하게 됩니다.

기존의 sequential recommender를 간략하게 살펴봅시다.
-
Markov Chains (MCs)
유저의 다음 행동이 바로 이전의 과거 혹은 몇 개 이전의 행동에 영향을 받을 것이라는 가정을 합니다.
이러한 가정은 너무 over-simplfy하고 매우 희소한(sparse) 데이터에만 잘 작동한다는 단점을 가지고 있습니다. 따라서, 복잡한 관계를 학습하는 것은 힘듭니다. -
Recurrent Neural Networks (RNN)
RNN 기반의 모델, 대표적으로 GRU recommender 같은 경우는, 과거의 모든 행동을 모델의 입력값으로 넣어, 이를 요약한 정보를 가지고 다음 행동을 예측합니다.
상대적으로 복잡한 모델을 학습하기 위해 많은 양의 데이터를 요구하기 때문에, 희소한 데이터에서는 좋은 성능을 보여주기 힘들다고 합니다.
저자는 이 둘의 단점을 보완하고자 새로운 모델을 추천 시스템에 적용하게 됩니다.
 이미지: (left) Factorizing personalized Markov chains for next-basket recommendation / (center, right) BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
이미지: (left) Factorizing personalized Markov chains for next-basket recommendation / (center, right) BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
기존의 딥러닝에서 빈번하게 사용되는 CNN, RNN 계열 모델과는 다르게 Transformer는 self-attention이라는 새로운 메커니즘을 사용합니다. Self-attention은 문장을 구성하는 단어들 간 의미적, 구조적 패턴을 기존의 모델들보다 더 잘 파악하는 결과를 보여주었고, 이에 따라 기계 번역과 같은 어려운 태스크에서 매우 좋은 성능을 보여주었습니다.
저자는 self attention을 사용하는 Transformer로 MCs, RNN 모델의 한계를 극복하고자 하였습니다.
위의 이미지(page 6)에서 그림을 보시면 MCs, RNN, Transformer의 접근 방식의 차이를 확인할 수 있습니다. 앞서 설명했듯 MCs, RNN 계열 모델의 가정이 그림에서 드러나며, Transformer(Self-attention)와 어떤 차이가 있는지 확인할 수 있습니다. (Parallelization 관점에서도 생각해볼 필요가 있습니다.)
Transformer
2017년, Vaswari, et al. 의 "Attention is all you need"에서 발표된 Transformer에 대해 간략하게 살펴보겠습니다.
Transformer의 설명에 사용된 이미지는 Jay Alarmmar의 블로그에서 가져왔으며, 이곳에 Transformer의 자세한 설명이 있으니 참고하시면 좋을 것 같습니다.
Overview
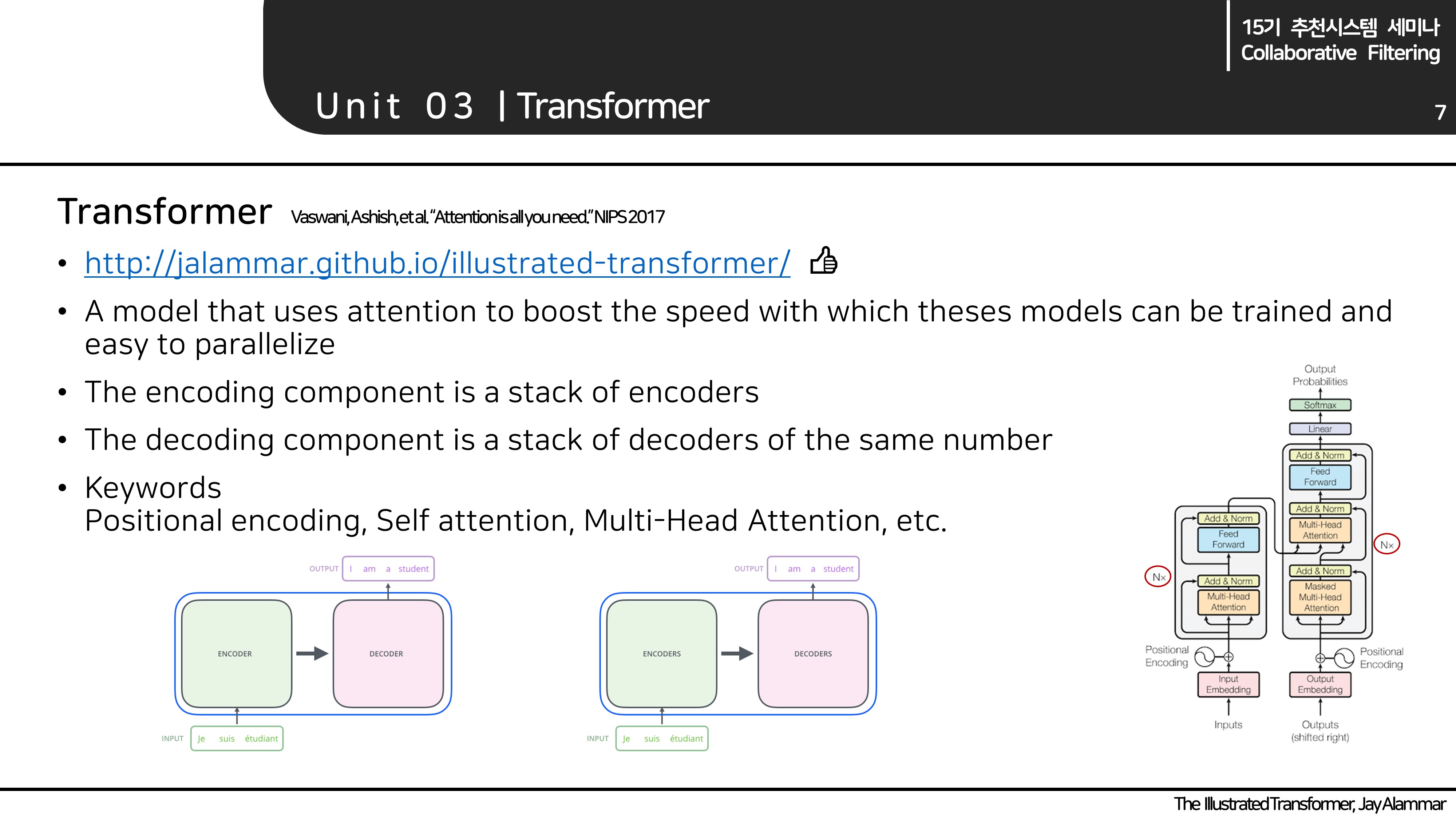
- Transformer는 크게 encoder blocks(stacking)과 decoder blocks(stacking)으로 구성되어 있습니다.
- Encoder block은 Multi-head attention, decoder block은 Masked Multi-head attention, encoder-decoder attention을 사용합니다.
이 3가지 self-attention과 positional encoding을 간단하게 살펴보겠습니다!
Encoder block vs. Decoder block
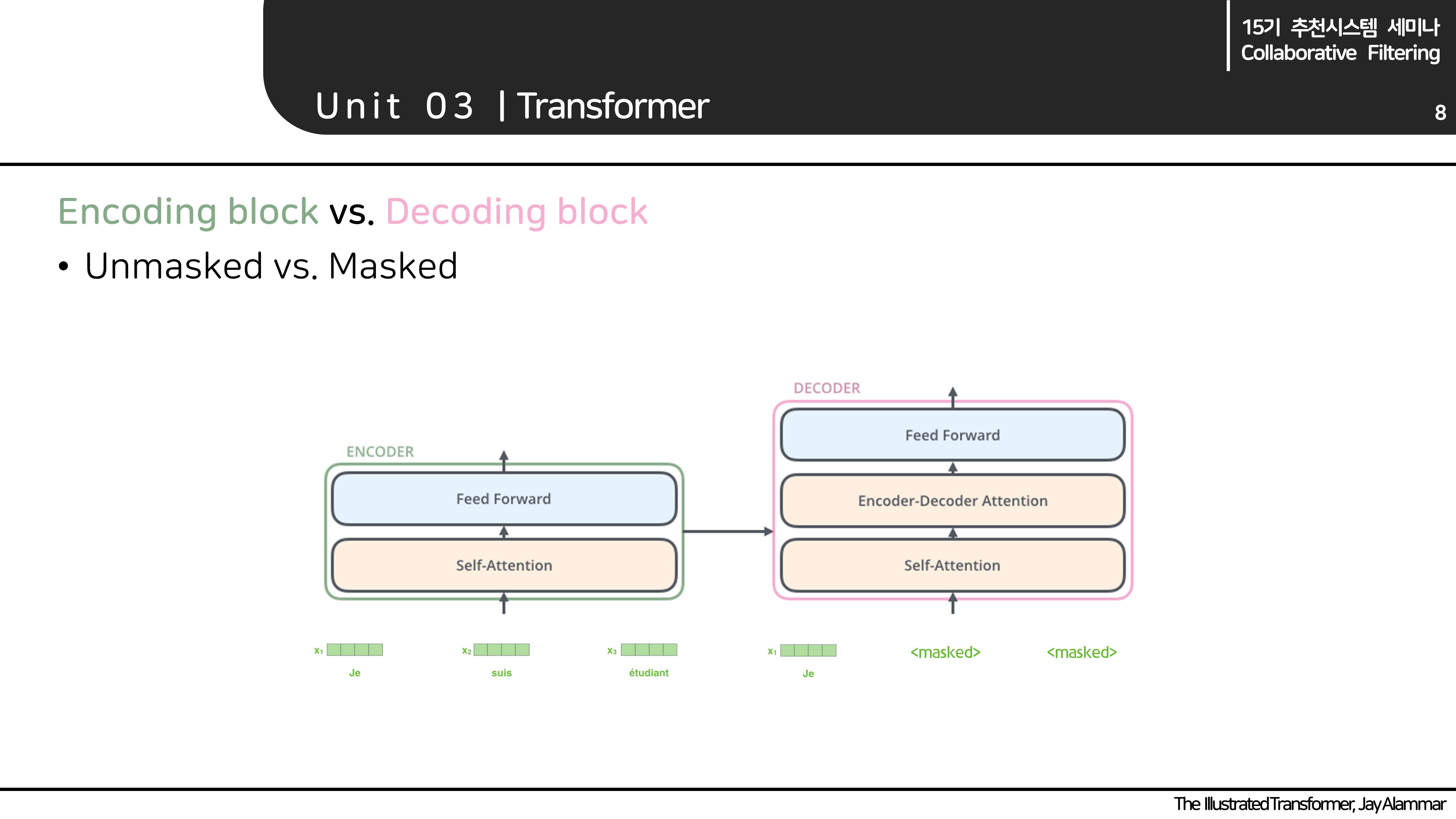
- Encoder, decoder block의 가장 큰 차이는 unmasked attention을 사용하였는지, masked attention을 사용하였는지 입니다.
위 그림의 입력 벡터를 보시면 좋을 것 같습니다.
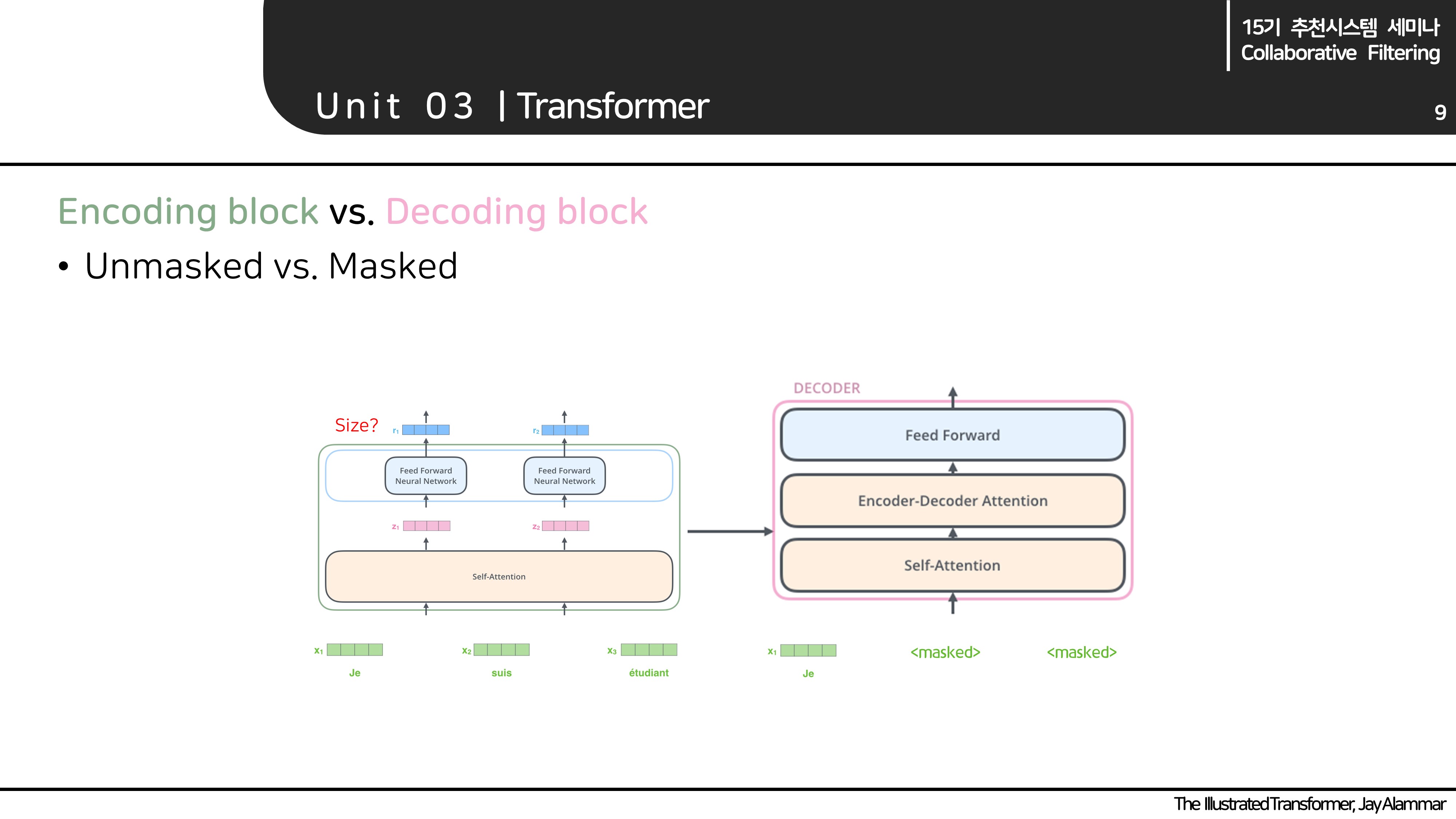
(참고로, encoder, decoder block의 입력 벡터와 이를 통과한 벡터의 사이즈는 동일하게 유지됩니다. 그림에서도 사이즈가 4로 유지되는 것을 확인할 수 있습니다. 이러한 사이즈를 유지하기 위해, multi-head attention의 파라미터 사이즈 설정에 주의해야 합니다.)
Encoder block
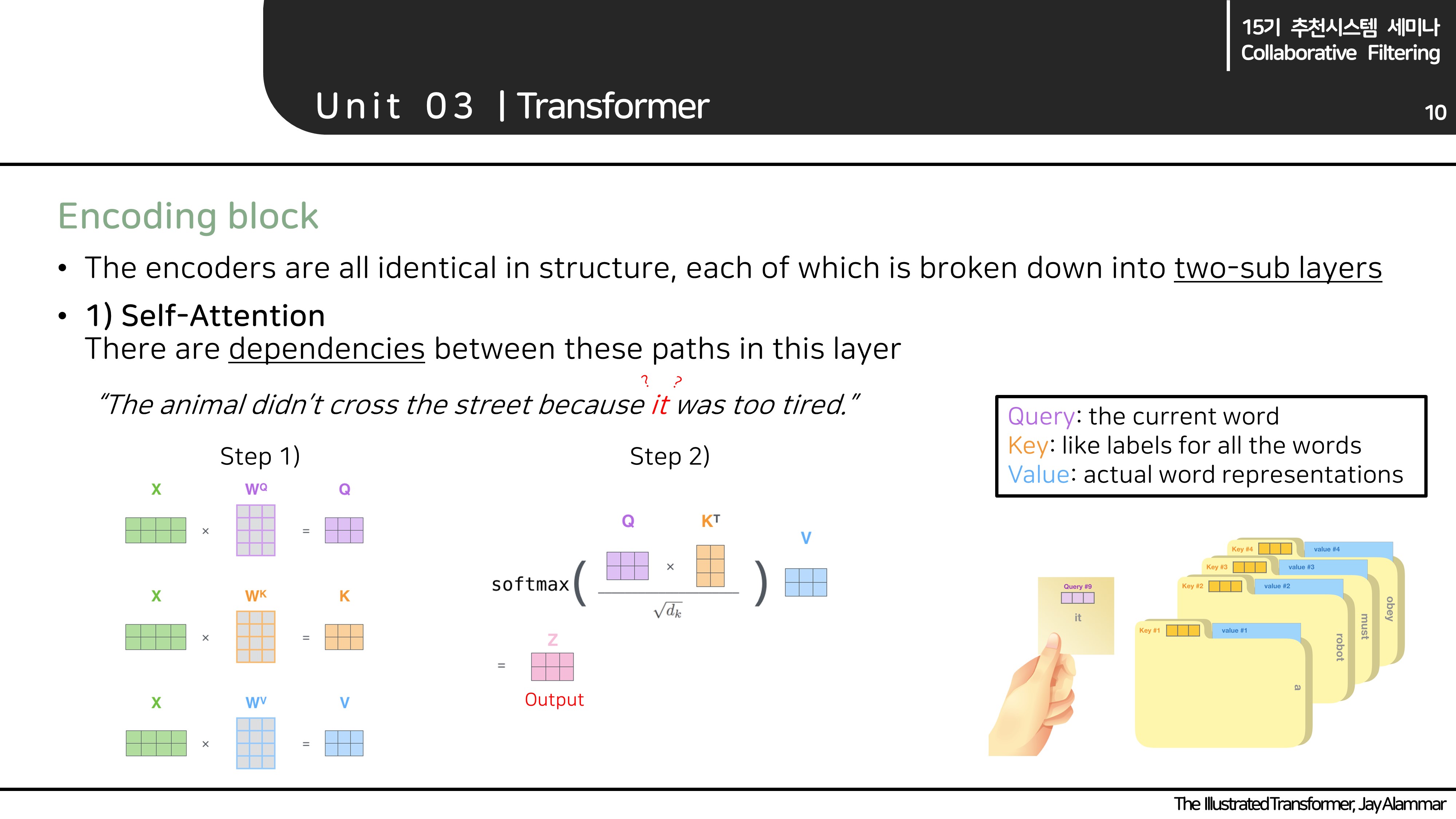
- Encoder block은 크게 두 개의 레이어(Multi-headed attention, Feed Forward Neural Network)로 구성됩니다.
- MH attention과 FFNN에서 중요하게 살펴볼 차이점은 input들의 dependency의 유무입니다.
(이 부분을 잘 기억해주세요.)
Multi-headed attention
"The animal didn't cross the street because it was too tired."
- 이 문장에서 it의 가리키는 혹은 내포하는 의미가 무엇일까요? 아마 'because', 'was'처럼 바로 주변 단어들은 아닐 것입니다. 여기서 중요한 것은 'it'이 의미하는 단어는 충분히 멀리 떨어져있을 수 있으며, 가리키는 혹은 내포한다라는 의미는 가장 유사한 단어(연관성이 높은)를 찾는 문제일 수 있습니다. 이를 모델에 반영하고자 self-attention이 등장합니다.
- Self-attention을 계산하는 것은 복잡하지 않습니다. Step1, step2 그림을 참고하시면 됩니다. 여기서 중요한 것은 Q,K,V 각각의 의미를 이해하는 것입니다. (Q,K,V는 마치 파이썬의 dictionary 객체와 같은 역할을 하고 있는데, Q: 내가 찾고하는 key value, K: dict에 저장된 keys, V: 각 key에 해당하는 value 라고 이해할 수 있습니다. 내가 어떤 key의 값을 찾기 위해, dict에서 key를 기준으로 찾아, 값을 가져오는 느낌입니다.)
- 만약 사람들에게 문장 안에서 'it'이 가리키는 단어를 고르라고 한다면, 모두가 같은 답변을 하지 않을 수 있습니다. 특히 더 복잡한 문장에서는 더더욱 그럴 것입니다. 이를 모델에 반영하고자 multi-headed attention을 사용합니다. (여기서 "multi-headed"는 서로 다른 사람의 시선을 앙상블하는 느낌으로 볼 수 있을 것 같습니다.)
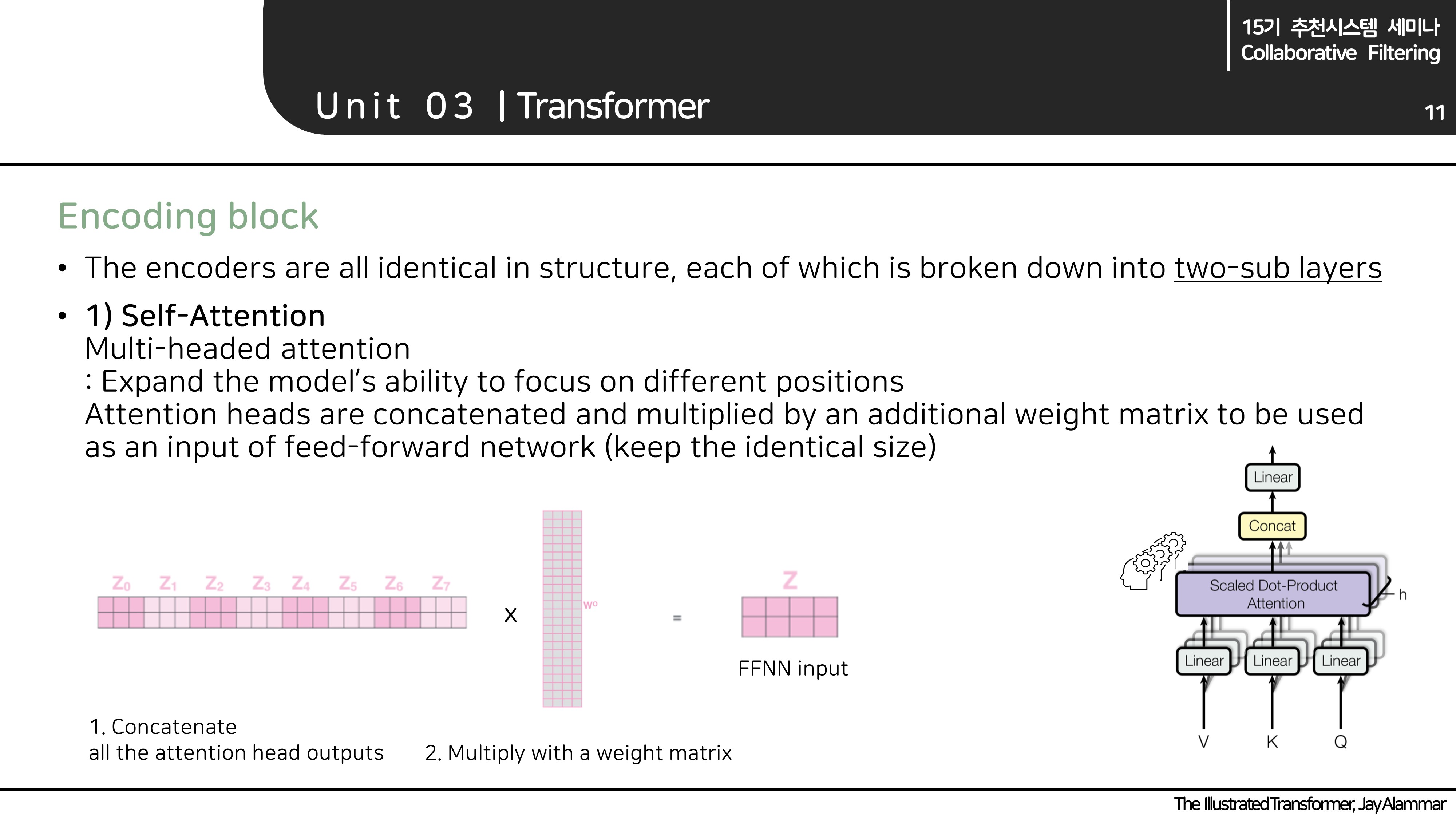
Multi-headed attention 연산도 그림처럼 간단합니다. 여기서 주목할 만한 것은 출력 벡터의 사이즈입니다.
(위에서 잠깐 언급했듯이, 사이즈를 유지하기 위해 head의 개수 등을 고려해줘야 합니다.)
Feed Forward Neural Network
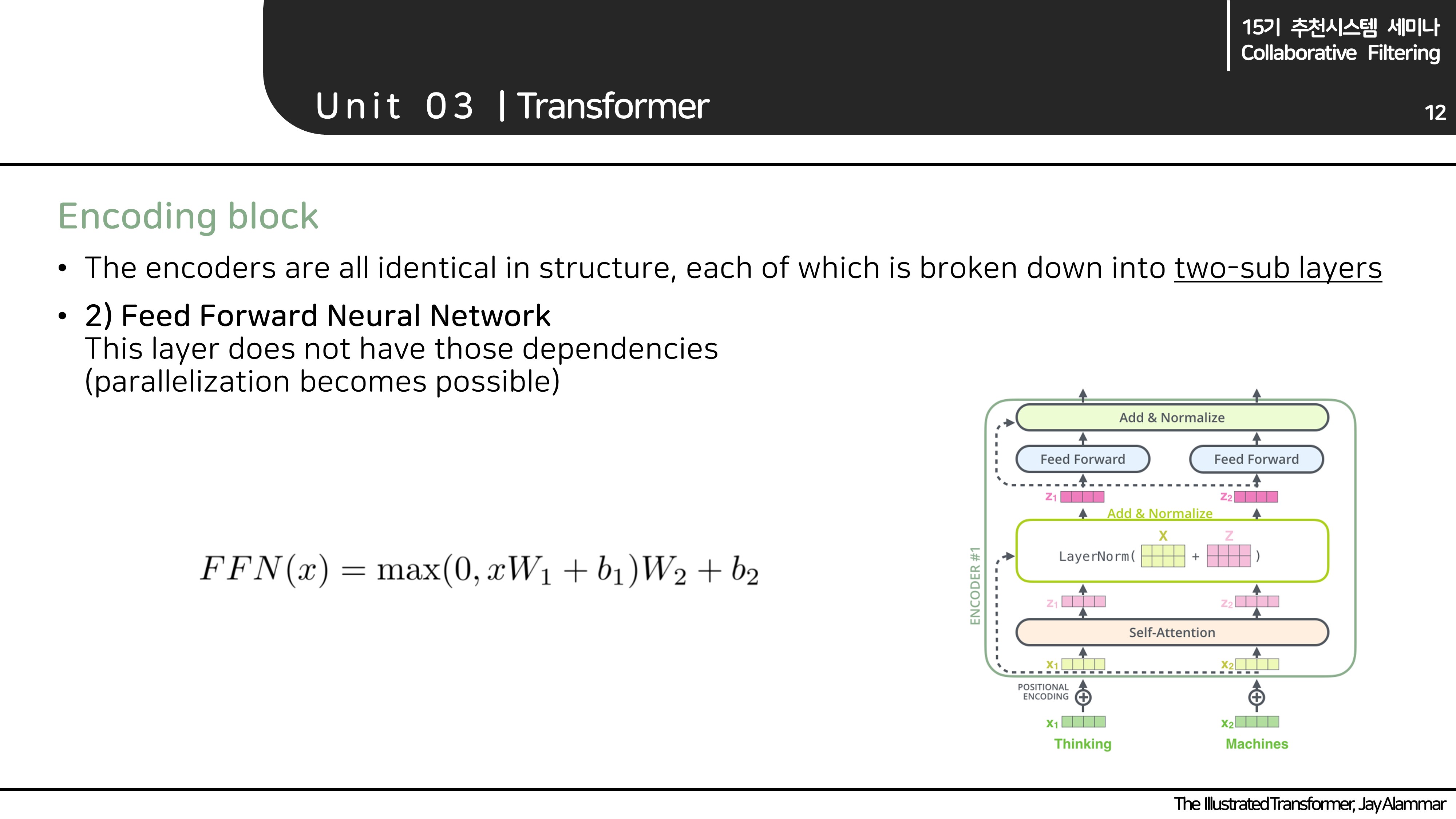
(위에서 말했듯이 MH attention과 FFNN에서 중요하게 살펴볼 차이점은 input들의 dependency의 유무입니다.)
같이 논의해봅시다 :)
Decoder block
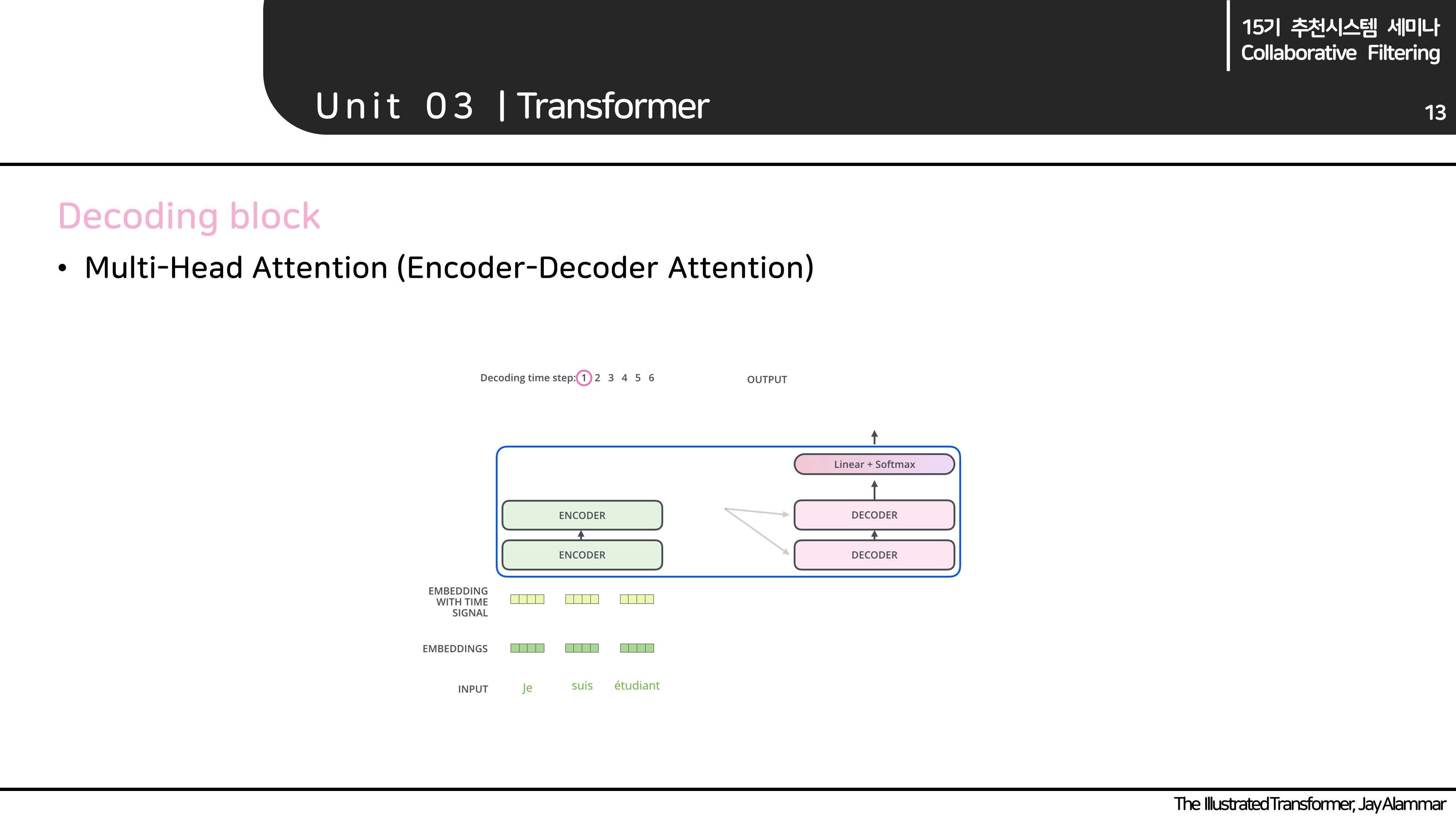
- Decoder block은 살펴볼 두 가지는 masked multi-head attention과 encoder-decoder attention 입니다.
Masked Multi-headed attention
- Decoder 부분부터는 실제 태스크를 풀기 위한 역할을 수행하기 위해서 masking을 해줍니다.
- 예를 들어, "아버지/가/방/에/들어가다"라는 문장이 있고, 순차적으로 다음에 올 단어 예측을 위해 "아버지/", "아버지/가", "아버지/가/방", ... 이런식으로 모델에 입력을 해줘야합니다.
- Transformer에서는 masking을 위해 매우 간단하게 -inf라는 값을 주었는데, 이는 sigmoid 혹은 softmax를 만났을 때 0의 값을 가지기 때문입니다.
Encoder decoder attention
- 해당 attention이 multi-head attention과 다른 점은 K,V를 encoder block에서 가져오는 것입니다.
- 즉 내가 찾고 싶어하는 Query는 decoder에서 생성하고 dictionary는 encoder에서 생성된 것을 쓰는 것입니다.
Positional encoding
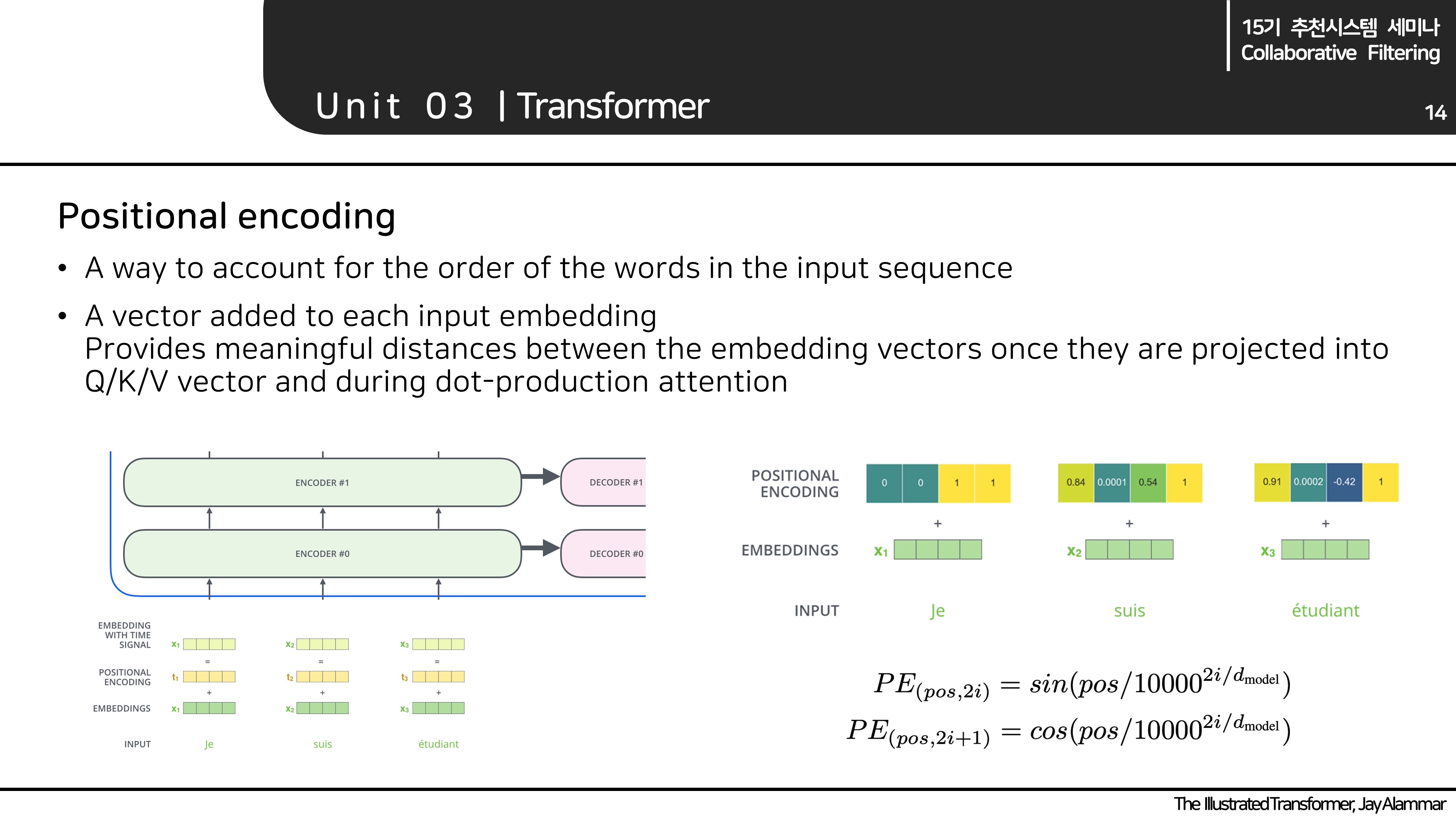
- Self-attention을 살펴보았을 때, 내가 알고싶은 Q값과 유사한 쌍을 찾기 위해 모든 key-value를 살펴본 것을 확인할 수 있습니다. 즉, 나랑 얼마나 떨어져있는지에 대한 위치 좌표는 무시됩니다. 하지만 문장에서는 locality가 어느 정도 중요할 수 있고, 이를 입력 벡터에 어느 정도 반영하고자 positional encoding을 해주게 됩니다.
- 모델의 입력 시퀀스를 그대로 넣어주고 self-attention을 진행하는 것 대신, 간단하게 입력 시퀀스에 positional 값을 더해주면 됩니다.
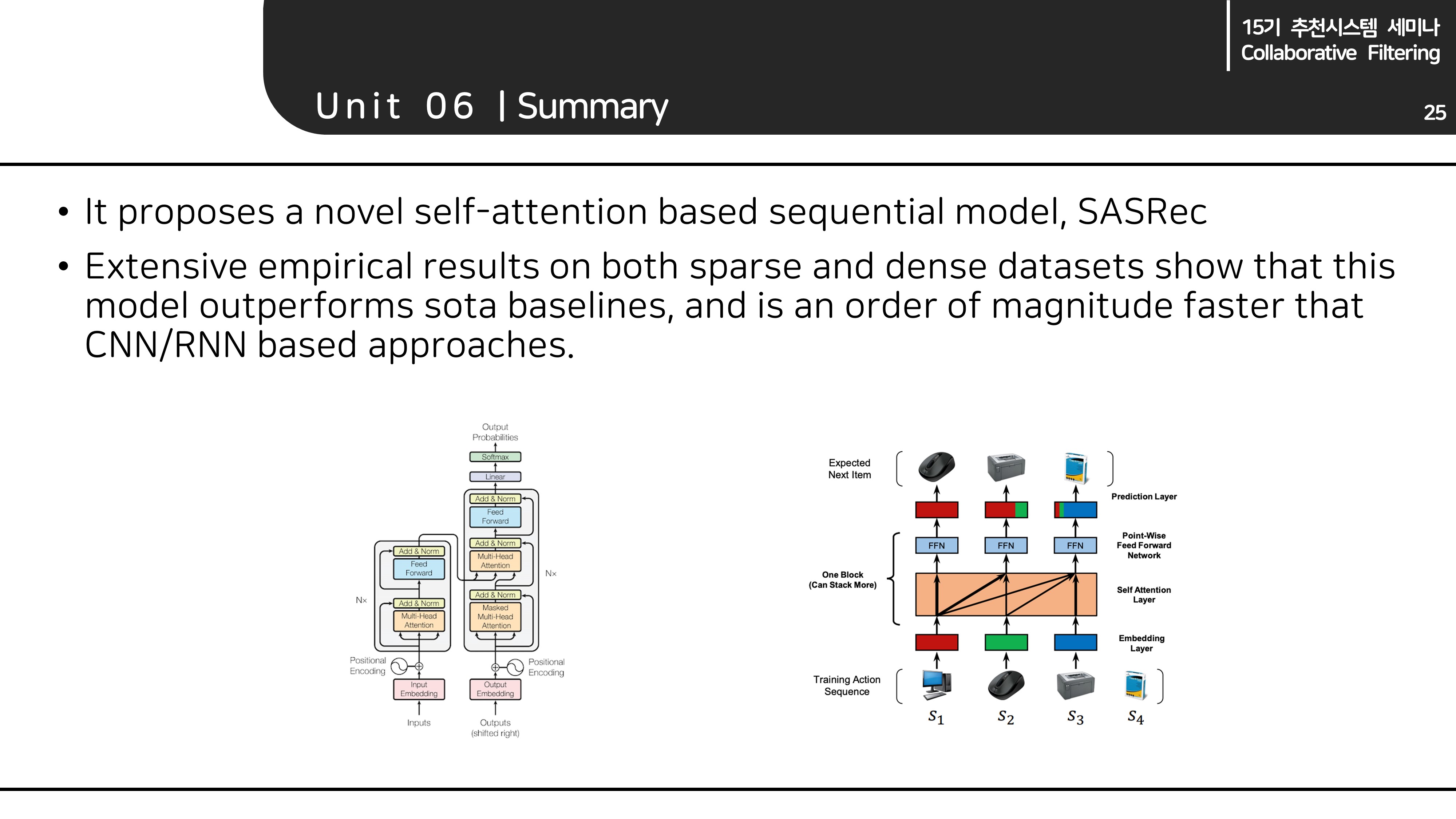
Summary
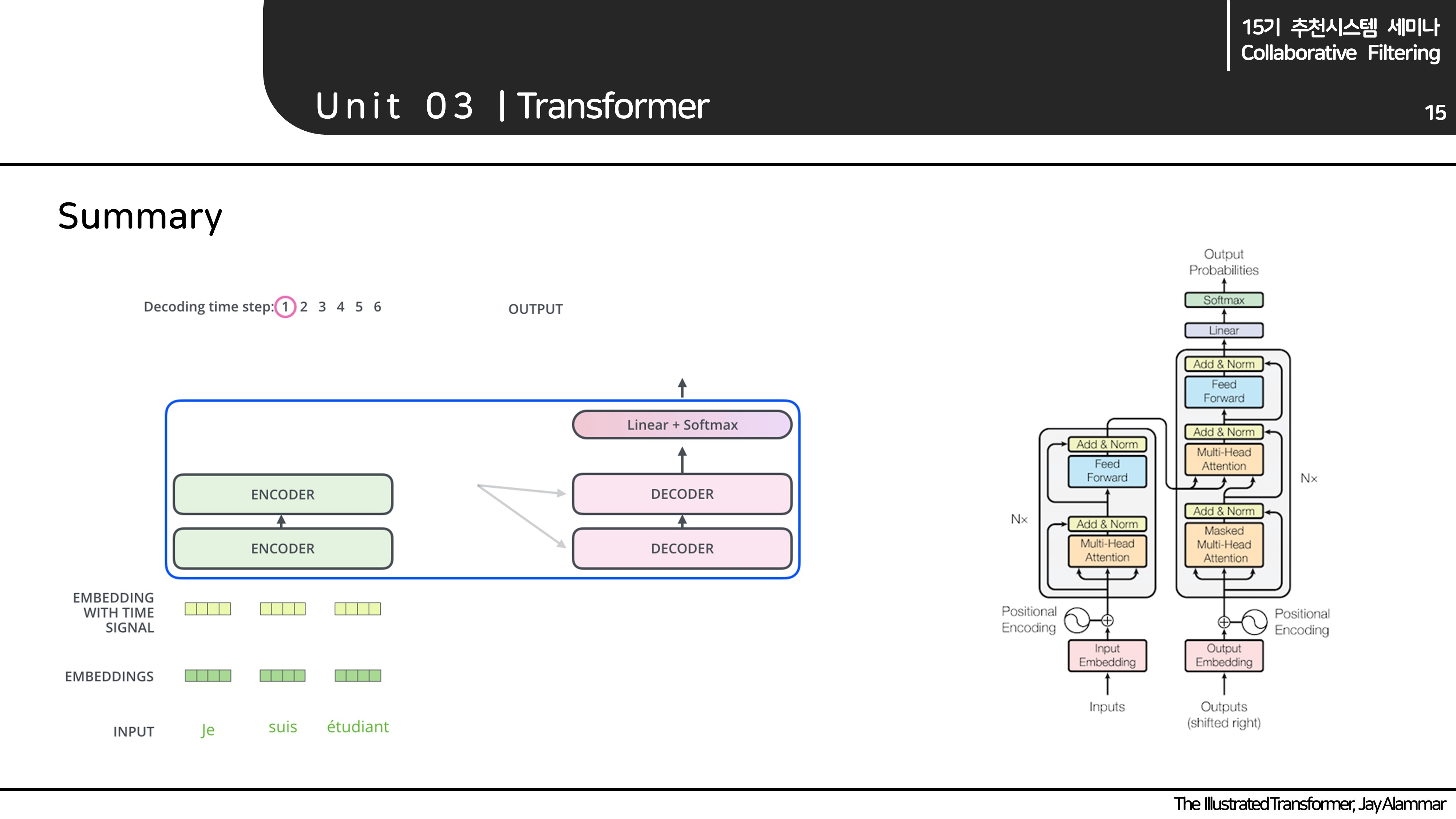
Methodology

SASRec이 Transformer를 어떻게 추천 시스템에 적용하였는지 살펴보겠습니다.
Transformer와 일치하는 부분은 생략하였습니다.
A. Embedding Layer
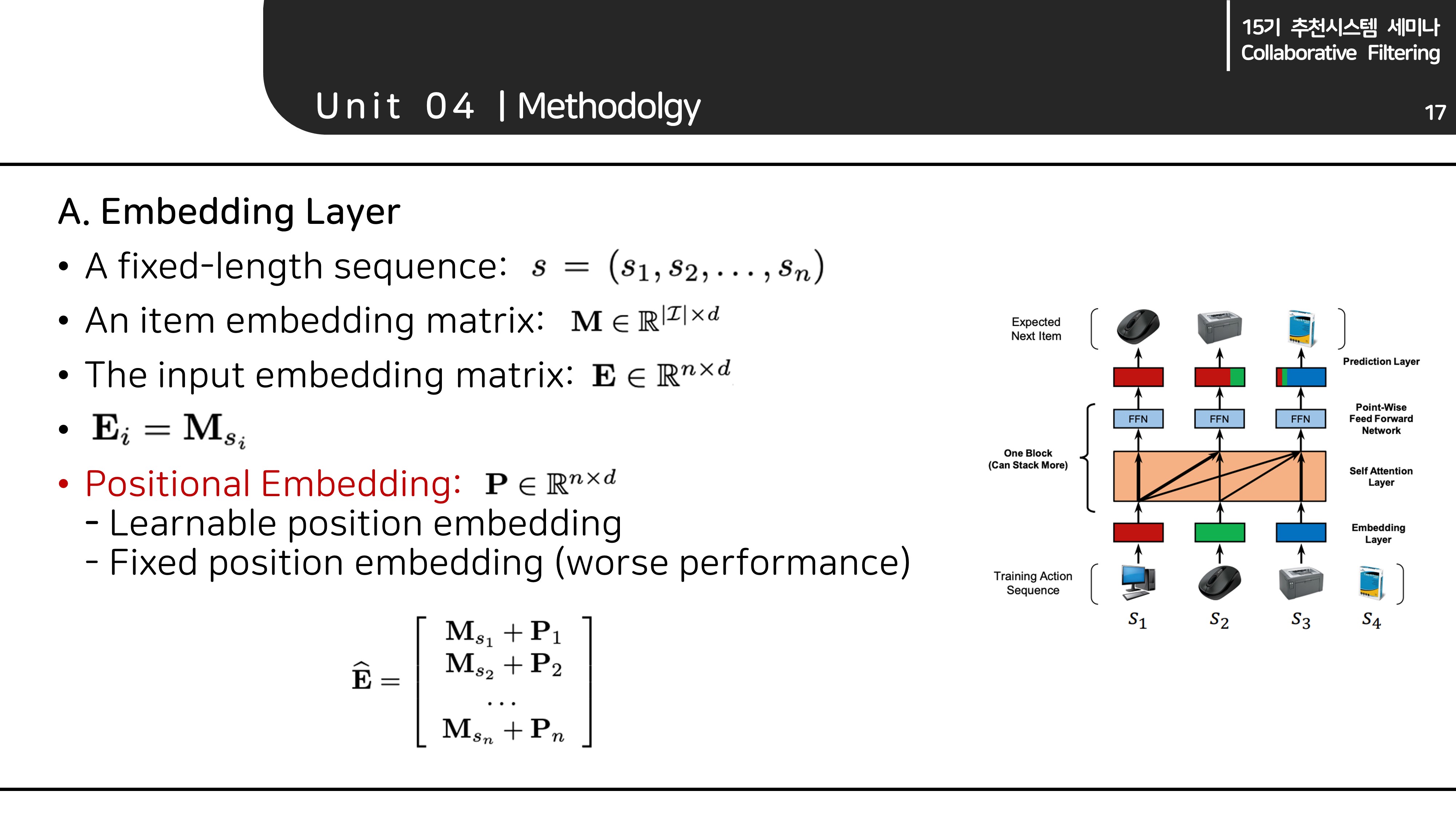
- 학습을 위해 action set의 사이즈는 으로 고정하였습니다.
- 따라서 전체 아이템 임베딩 행렬의 사이즈는 , 입력 임베딩 행렬의 크기는 입니다.
- 앞서 언급한 positional encoding은 입력 벡터에 더해주는 형태이기 때문에 사이즈는 입력 임베딩 행렬과 동일합니다.
- 기존 Transformer와 차이가 있다면, 여기서는 Positional encoding을 고정된 값이 아닌, 학습 파라미터로 설정했다는 점입니다.
(고정 positional encoding은 성능이 안 좋았다고 합니다.)
B. Self-Attention Block/C. Stacking Self-Attention Block/D. Prediction Layer
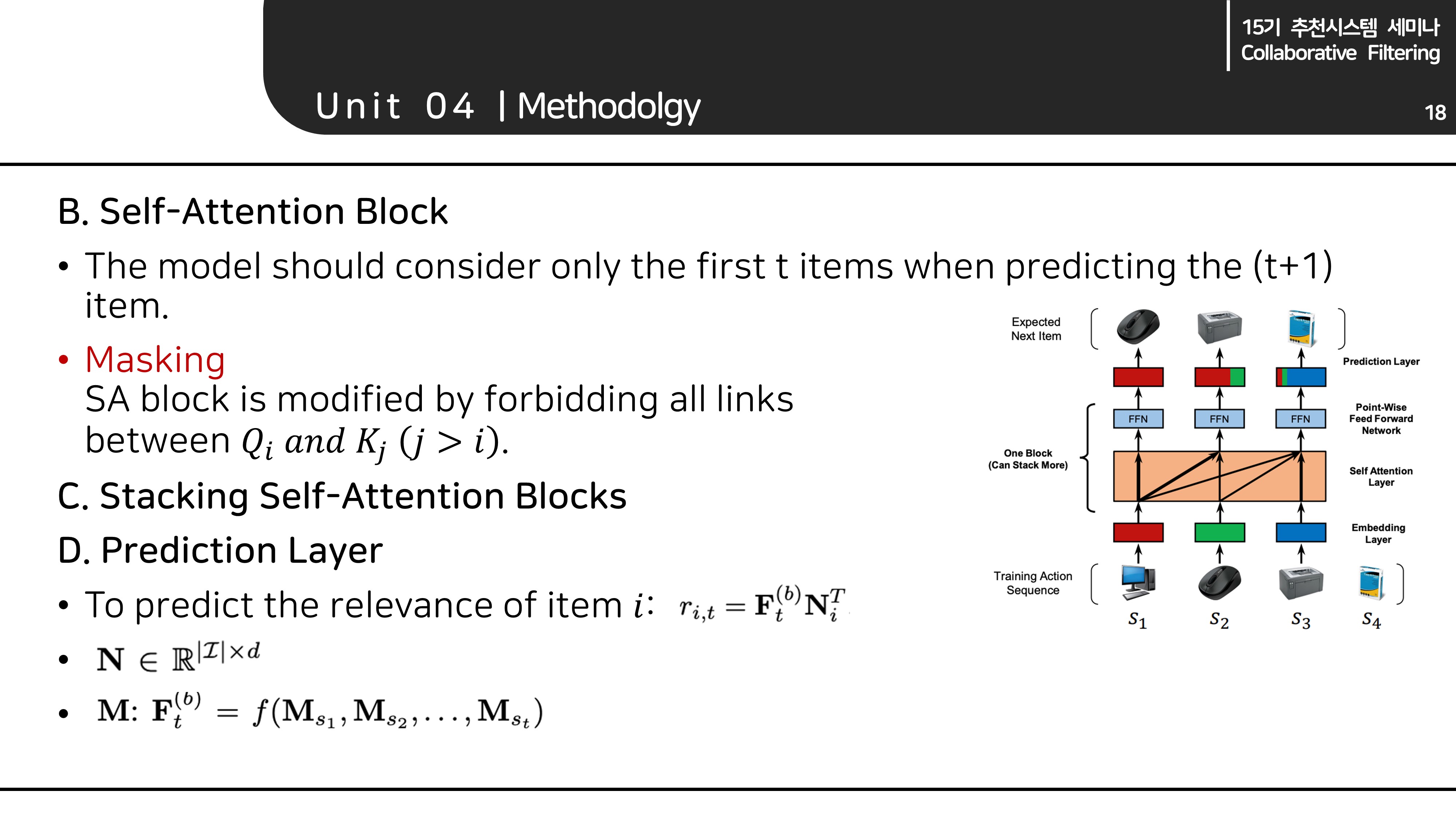
B.Self-Attention Block
- Encoder, Decoder block을 따로 구분하는 것 대신, 새로운 self-attention block을 제안함.
- 실험을 위해 2개의 self-attention block을 쌓았음.
- Causality) 실제 추천 알고리즘이 작동할 때는 미래의 유저 행동을 볼 수 없기 때문에, 저자는 미래의 유저 행동을 사용하는 것은 모순적이라고 생각하였습니다. 따라서, self-attention block에서 현재 이후 시점에 대해서는 masking을 진행했습니다.
- 즉, and , where 에 해당하는 연산을 masking 했습니다.
D.Prediction Layer
- 다음에 올 유저 행동을 예측하기 위해 적절한 item의 score를 최종적으로 예측하게 됩니다.
- 따라서 block의 출력 값 에 사이즈가 인 과 연산해줍니다.
(임베딩 사이즈가 모두 , 입력 임베딩 벡터 사이즈와 동일) - Shared Item Embedding) 이때, 저자들은 을 새로운 학습 파라미터 임베딩 값 대신, 모델 입력값으로 사용되었던 을 재활용하게 됩니다.
(학습할 파라미터가 줄어, overfitting을 방지했다고 함 -> 실제 실험 결과가 개선됨.)
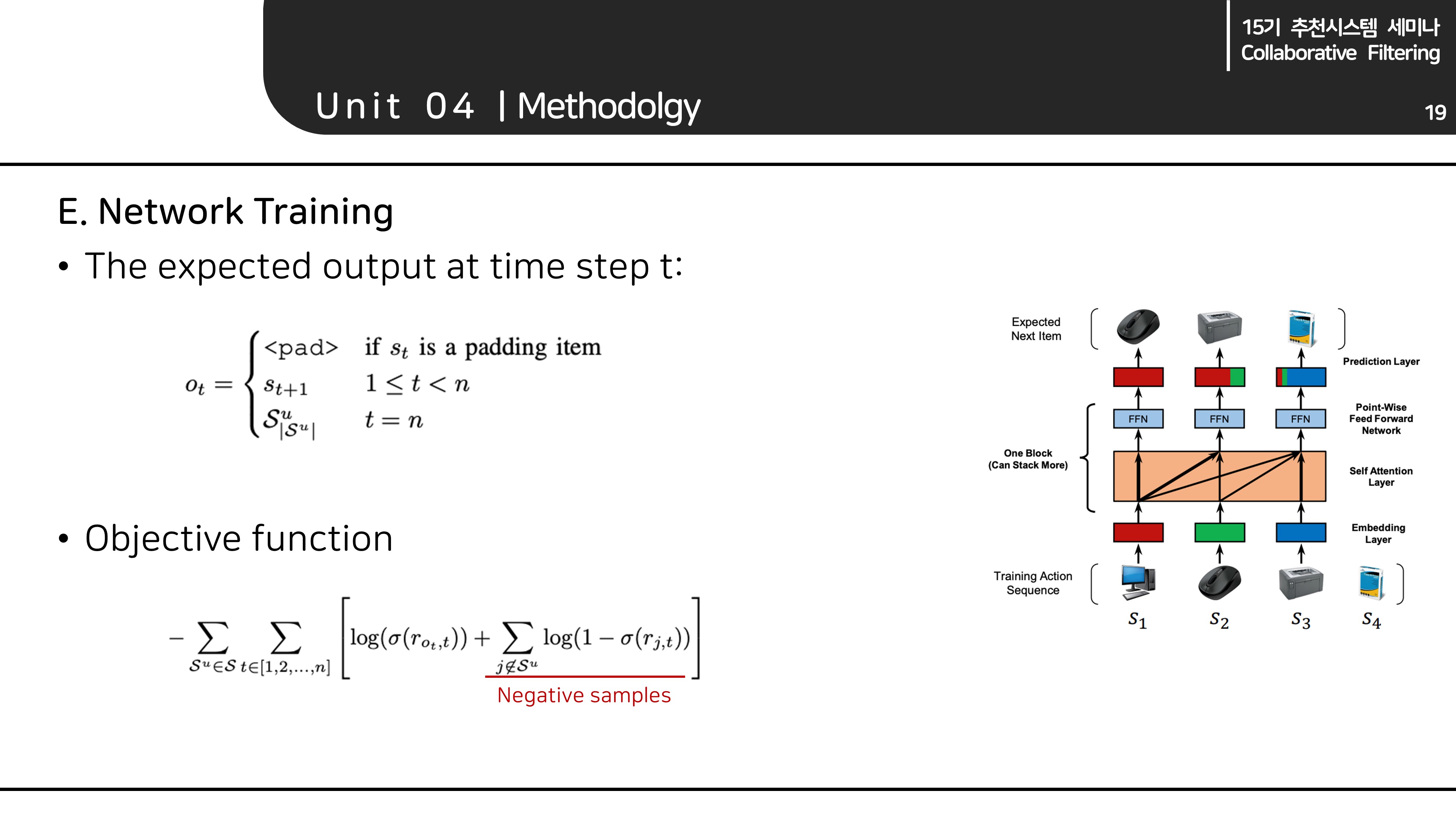
E. Network Training
F. Complexity Anlysis
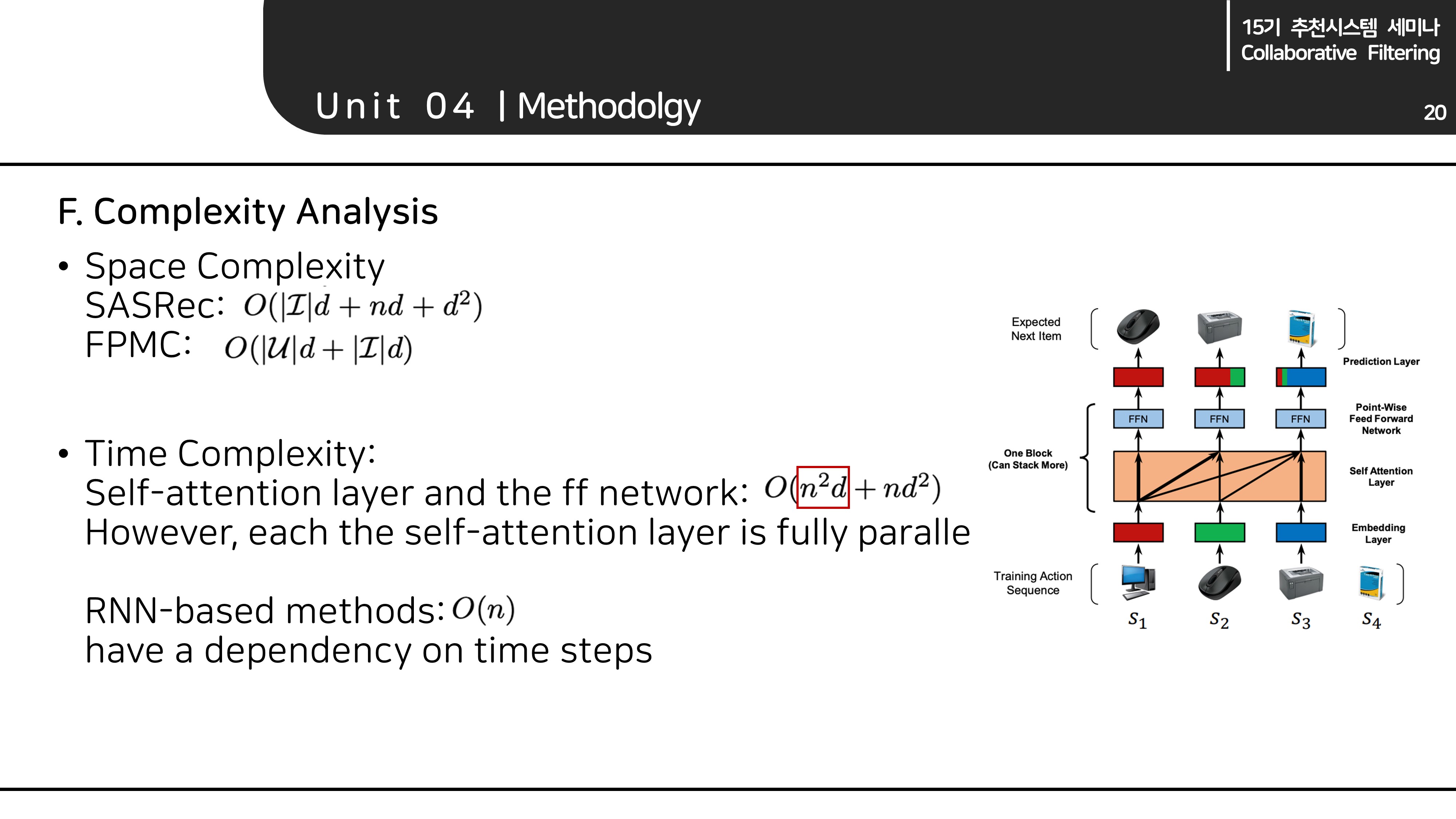
공간복잡도
- 논문에서는 SASRec과 FPMC 모델을 비교하였습니다.
(다른 기존의 모델들의 공간복잡도가 FPMC와 비슷하다고 합니다.) - 여기서 SASRec은 텀이 없는데, 실제로는 이 매우 크기 때문에 SASRec이 비교적 효율적임을 알 수 있습니다.
- 는 임베딩 사이즈로 and 이기 때문에 무시함.
( : Item embedding matrix, : Positional encoding params)
시간복잡도
- SASRec: Self-attention layer와 FFNN layer의 시간복잡도는
- RNN-based:
- 따라서, SASRec이 비교적 효율적이지 않을 수 있지만, 실제로 Transformer의 self attention과 ff layer는 병렬적으로 연산이 가능합니다. (발표자료 6페이지 그림을 살펴봅시다.)
- 반면, RNN-based는 순차적으로 진행할 수 밖에 없습니다.
(참고자료)
Experiment
Datasets/Evaluation Metrics
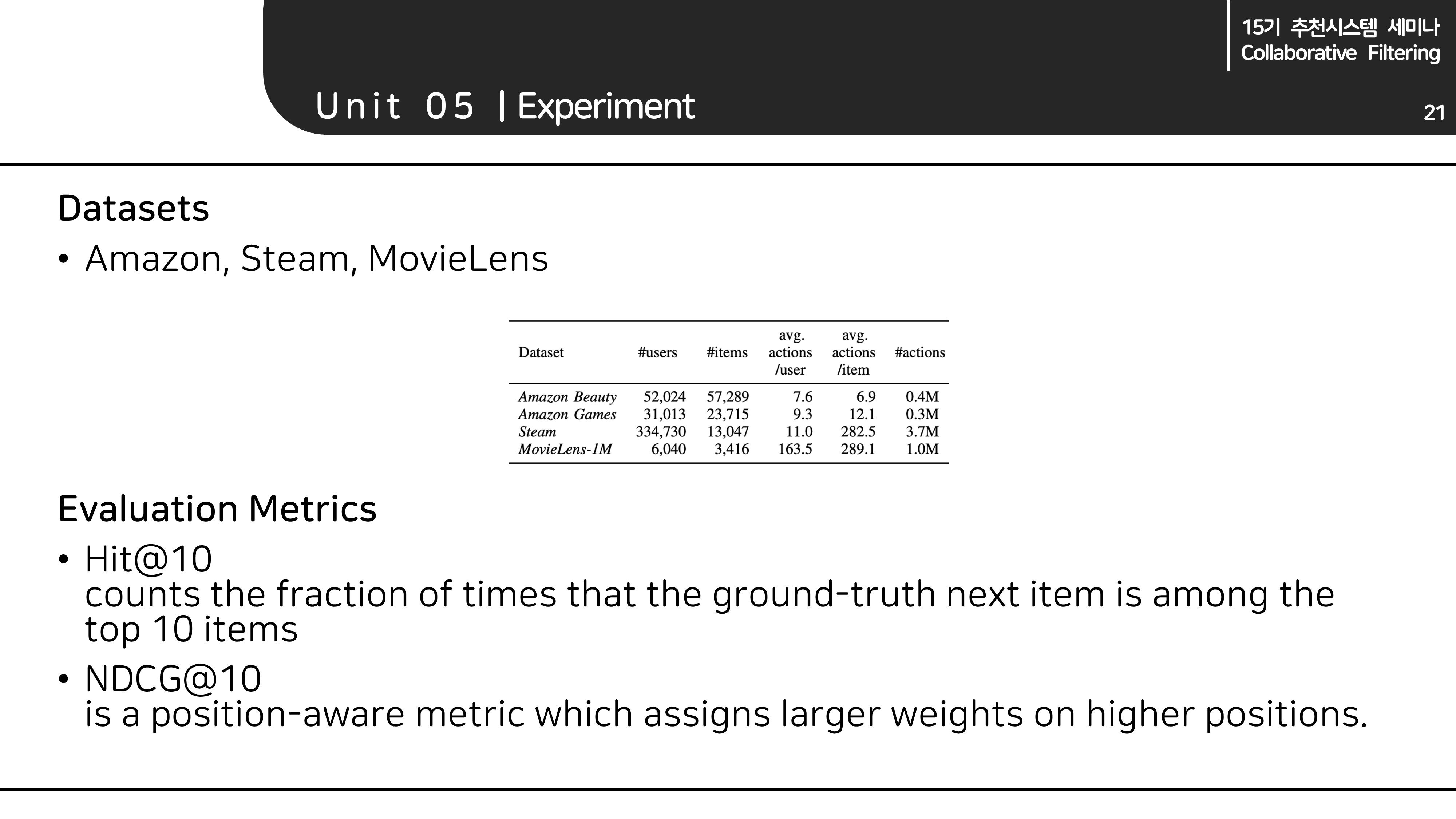
- 실험 데이터셋은 총 4개이며 각각의 통계량은 발표자료를 참고해주세요.
- 평가 메트릭은 지금까지 다룬 페이퍼들과 같습니다.
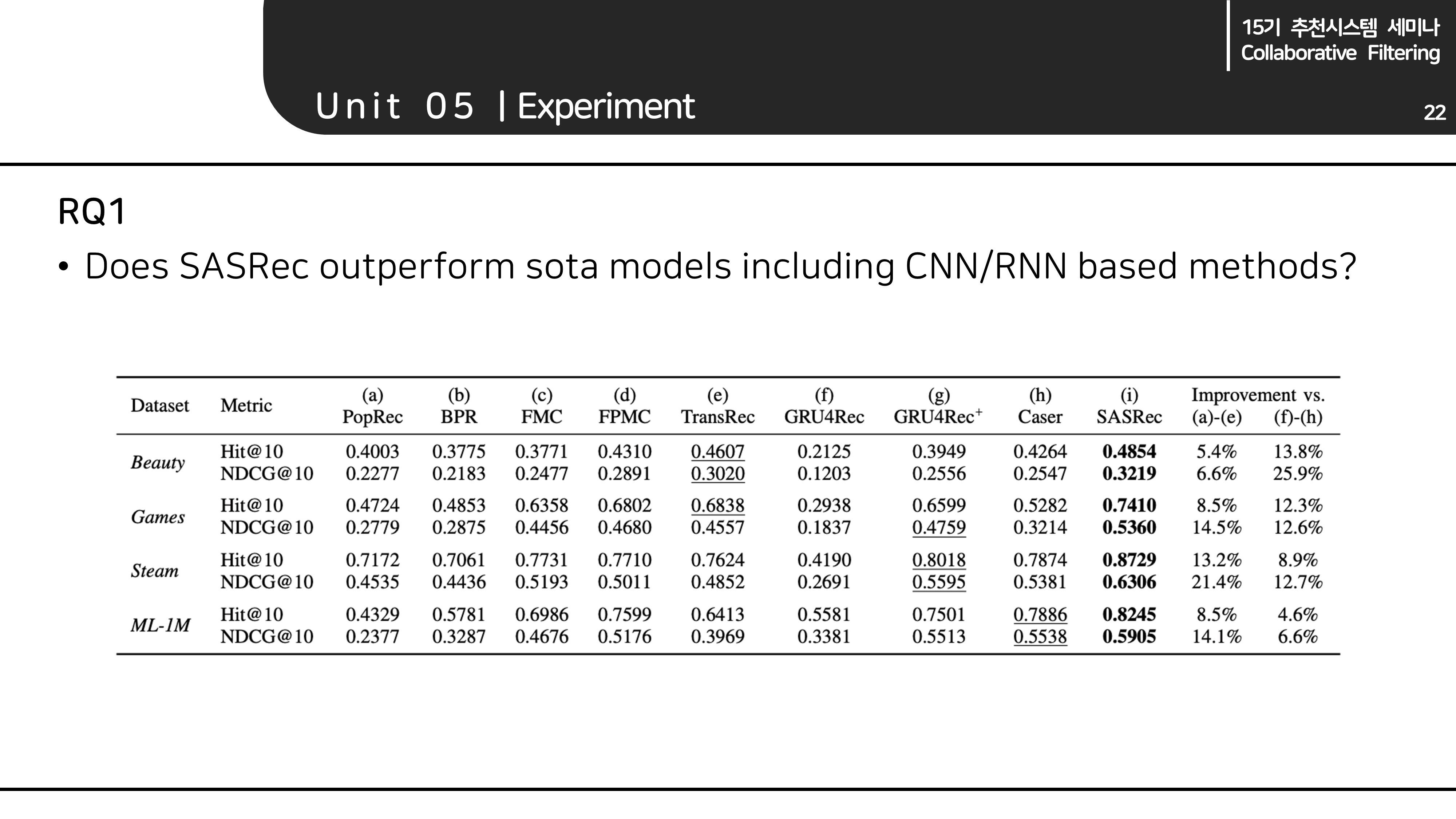
- 저자들은 4가지의 질문을 던지며, 이에 대한 답을 실험결과로 보여주었습니다.
RQ1
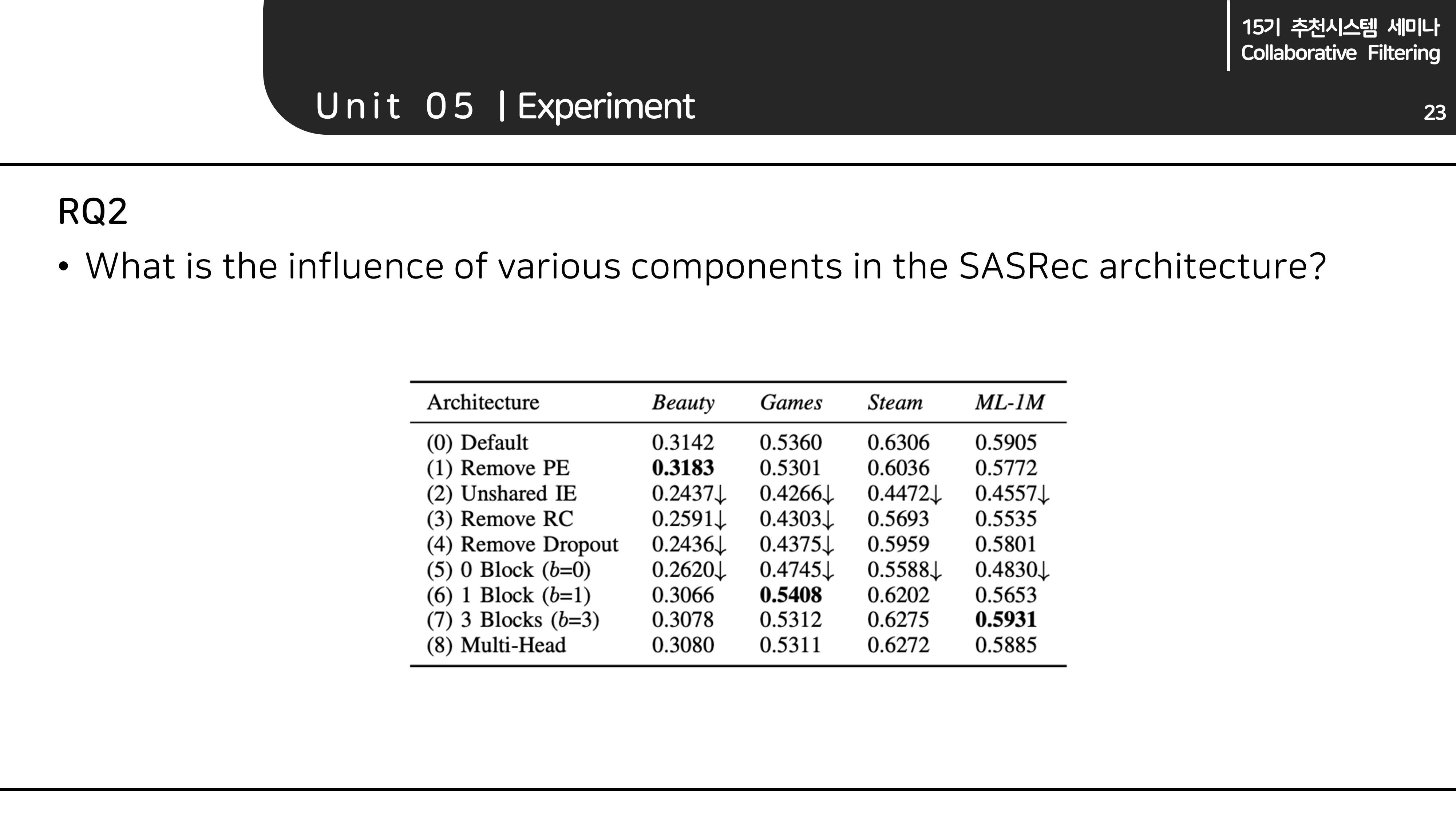
RQ2
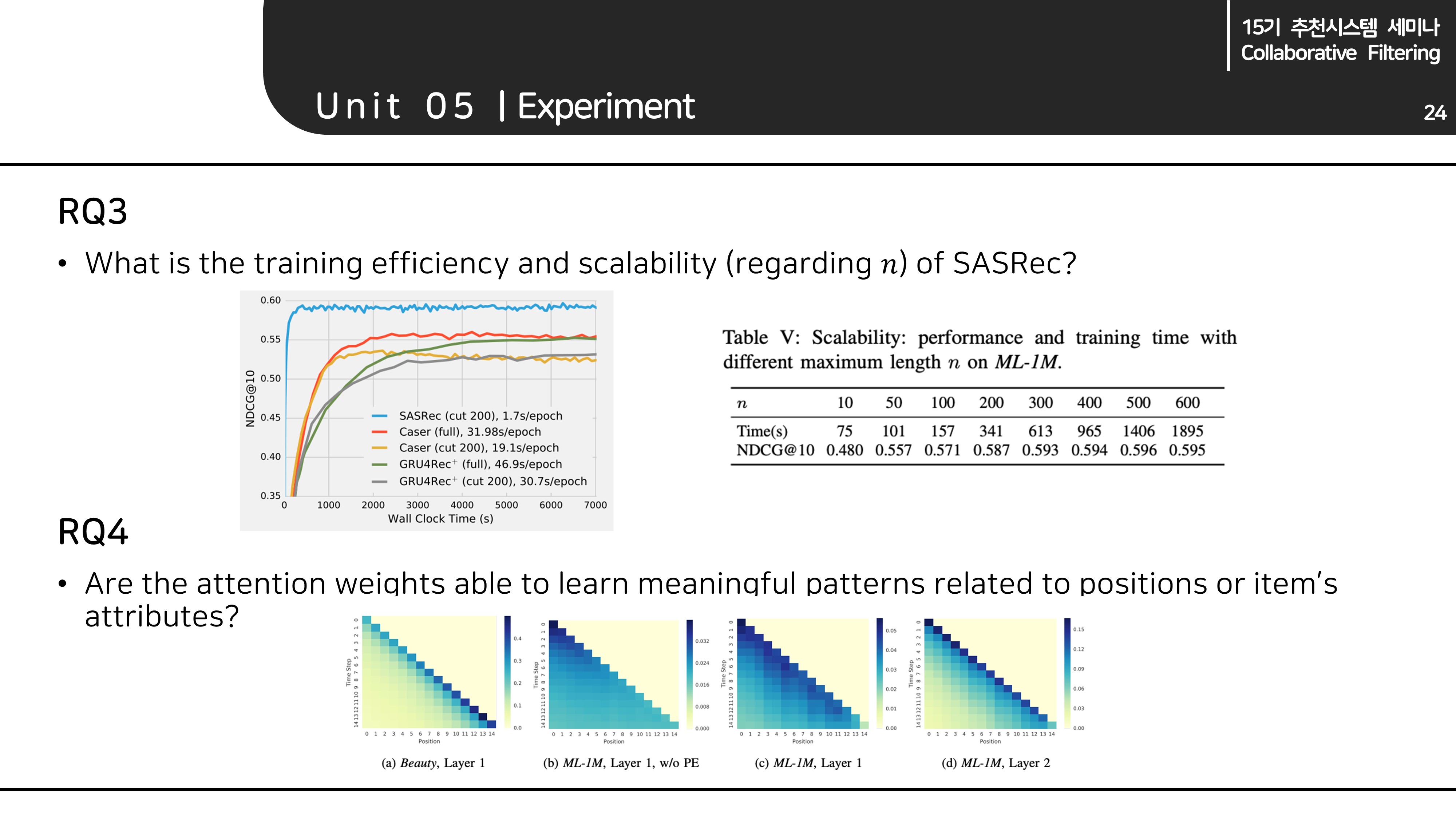
RQ3/RQ4
Summary


5개의 댓글

[15기 이성범]
본 논문에서는 시퀀스 데이터를 사용하는 추천 시스템 알고리즘인 Markov Chains와 RNN 계열의 단점을 동시에 보완하고자 NLP Task에서 SOTA인 Transformer 모델을 추천시스템에 적용한 SASRec Model을 제안했다. 본 논문에서 제안한 모델은 기존의 RNN, MC, CNN based 모델의 성능을 모두 뛰어넘는 실험 결과를 보여주었다.
MC는 유저의 다음 행동이 바로 이전의 과거 혹은 몇 개 이전의 행동에 영향을 받을 것이라는 가정으로 만들어진다. 이러한 가정은 매우 단순하고 희소한 데이터에만 잘 작동한다는 단점을 가지며, 복잡한 관계를 학습하는 것이 어렵다.
RNN는 과거의 모든 행동을 모델의 입력 값으로 넣어, 이를 요약한 정보를 가지고 다음 행동을 예측한다. 복잡한 모델은 학습하기 위해서는 많은 양의 데이터를 요구하기 때문에, 희소한 데이터에서는 좋은 성능을 보여주기 어렵다.
SASRec은 Self-Attention 기법을 적용한 Transformer 모델을 추천 시스템에 적용하여 MC와 RNN의 모델의 한계를 극복했다. Self-Attention을 통해서 시퀀스 내에 존재하는 모든 행동에 연관성을 파악함으로써 행동 간의 복잡한 관계를 학습할 수 있게 만들었다. 그리고 본 모델은 대부분의 모델 구조가 Transformer와 유사하지만 Positional Encoding 부분을 학습 파라미터로 설정했다는 점이 다르다. 또한 현재 이후의 시점에 대해서는 마스킹 처리를 해서 학습을 시켰는데 이는 실제 추천 알고리즘이 작동할 때 미래의 유저 행동을 볼 수 없기 때문이며, 미래의 유저 행동을 사용하는 것은 모순적이기 때문이다. 따라서 본 모델은 기존의 알고리즘보다 조금 더 유저의 행동의 연관성을 잘 파악할 수 있었으며 현실과 유사한 방식으로 추천 시스템 알고리즘을 학습시켜서 성능이 우수하고 일반화된 모델을 얻을 수 있었다고 생각한다.

Self-Attentive Sequential Recommendation (SASRec)
15기 류채은
Markov Chains(MC)과 RNN 계열의 단점을 동시에 보완하기 위해 등장했다.
Sequential recommender system은 유저의 최근 행동의 context를 기반으로 한 추천을 목표로 하며 기존의 recommender로 Markov Chains (MCs)와 Recurrent Neural Networks (RNN)가 있다.
Transformer은 encoder blocks(stacking)과 decoder blocks(stacking)으로 구성되어 있으며 문장을 구성하는 단어들 간 의미적, 구조적 패턴을 기존의 모델들보다 더 잘 파악하는 결과를 가능케 한 self-attention을 사용한다.
Encoder block은 크게 두 개의 레이어(Multi-headed attention, Feed Forward Neural Network)로 구성된다.
Decoder block은 실제 태스크를 풀기 위한 역할을 수행하기 위해서 masking을 해주는 masked multi-head attention과 encoder-decoder attention이 있다.
Self attention에서 고려하지 않은 위치 좌표를 입력 벡터에 반영하기 위해서 입력 시퀀스에 positional 값을 더해주는 positional encoding이 일어난다.
[Embedding Layer]
Positional encoding을 고정된 값이 아닌, 학습 파라미터로 설정했다.
[Self-Attention Block]
Q_i and K_j, where j>i에 해당하는 연산을 masking했다.
[Prediction Layer]
Shared Item embedding에서 모델 입력 값으로 사용되었던 M을 재활용한다.
[15기 장아연]
전통적인 Markov Chains과 RNN 계열의 알고리즘의 단점을 보안하고 Transformer 모델을 적용해 새로운 모델인 SASRec Model을 제시함.
기존의 Sequential Recommender System 중 Markov Chains는 sparse한 경우에만 적절하고 오히려 Recurrent Neural Networks은 대량의 데이터가 있어야 한다는 한계를 보임.
Transformer는 Multi-headed attention과 Feed Forward Neural Network로 구성된 Encoder와 masked multi-head attention과 encoder-decoder attention로 구성된 Decoder를 stacking하고 self attention을 사용해 문장의 복잡한 구조와 의미를 파악함.
SASRec는 Self Attention을 통해 연관성을 파악해 복잡한 관계에 대한 학습이 가능해짐. 또 Positional Encoding에서 Self Attention에서 반영되지 않은 위치 좌표를 반영하기 위해 고정하지 않고 학습 파라미터로 설정함. 그리고 이후 시점에 대해 Masking을 진행함. Shared Item Embedding으로 모델에서 입력 되었던 값을 사용해 M을 재활용함.
14기 박지은
SASRec은 NLP의 Transformer 모델을 추천시스템에 도입하여 기존 RNN 계열 모델과 sequential recommender의 단점을 보완할 수 있습니다. Transformer는 마스크를 씌우지 않은 encoder block과 마스크를 씌운 decoder block으로 이루어져 있는데, SASRec에서는 이를 따로 구분하지 않고 새로운 self-attention block을 제안합니다. 또한 순서 정보가 저장되지 않는 Transformer의 특징을 보완하기 위한 positional encoding이 고정된 값이 아니라 학습되는 파라미터의 형태를 띄고 있습니다. 그리고 미래의 유저 행동을 예측하기 위해 미래 시점에 대한 유저 행동은 마스킹하여 예측합니다. 이후 글에서 등장하는 BERT4Rec를 읽으며 그 전단계라 볼 수 있는 SASRec에 대해서 차근차근 공부할 수 있었고, Transformer 개념을 어려워했었는데 정말 친절하고 자세하게 설명해주셔서 너무너무 유익한 시간이었습니다. 좋은 강의 감사합니다!
[14기 이혜린]