

작성자 : 투빅스 13기 정주원
Contents
- RNN, CNN, and Self-Attention
- Transformer
- Image Transformer
- Music Transformer
1. RNN, CNN, and Self-Attention
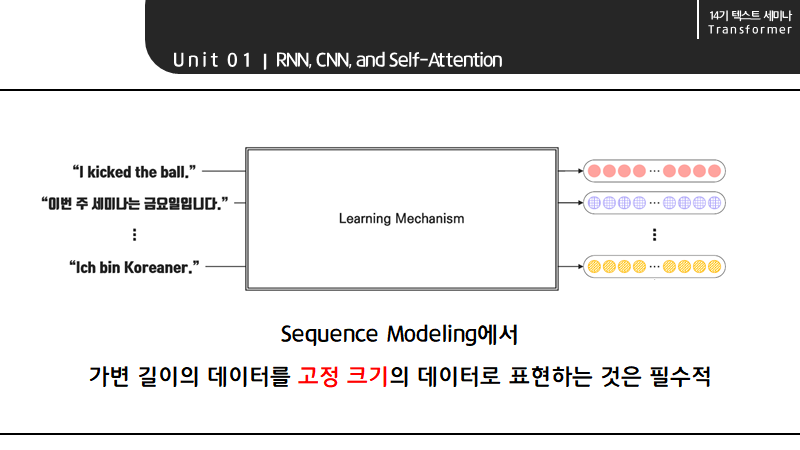
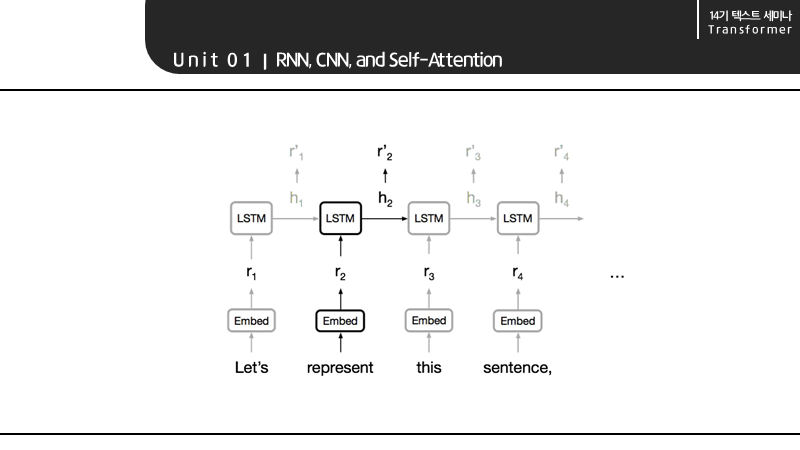
RNN 계열의 LSTM을 생각해보면 데이터 즉, 시퀀스의 길이를 맞춰야 매 단계마다 빠르게 계산할 수 있기 때문입니다.
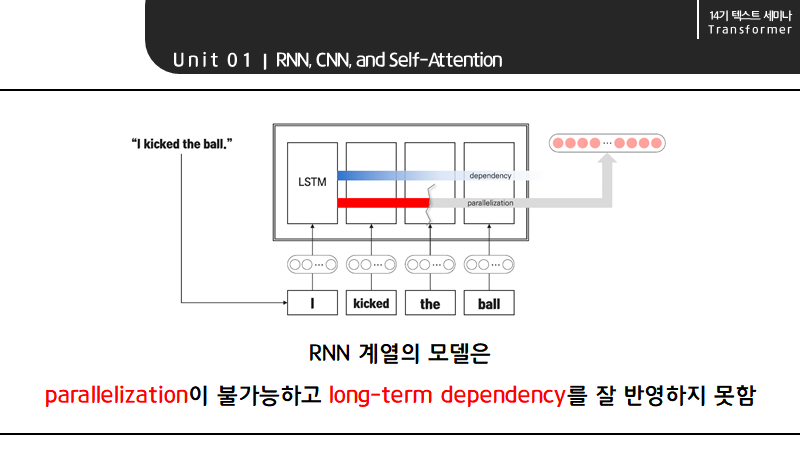
하지만 RNN 계열의 모델은 parallelization이 불가능하고 long-term dependency를 잘 반영하지 못한다는 단점이 있습니다. 이때 Parallelization이 불가능한 이유는 the 이전에 kicked가 계산되어 hidden state로 kicked에 대한 값이 넘어가야지만 the에 대한 계산이 가능하기 때문입니다.
또한 RNN 모델은 Vanilla RNN보다 dependency에 강한 편이지만 I의 영향력이 ball에 가서는 옅어진다는 long-term dependency 문제를 여전히 안고 있습니다.
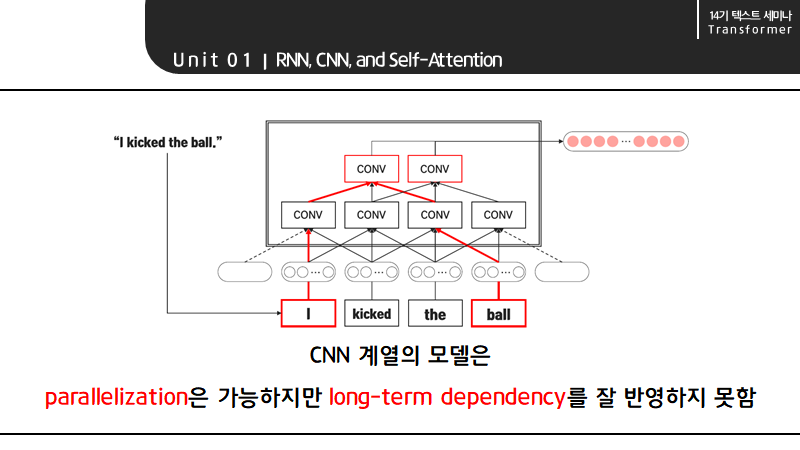
또한 CNN 모델은 병렬 처리가 가능하지만 long-term dependency를 위해 다수의 layer가 필요하다는 단점이 있습니다. 예를 들어 kernel size가 3인 경우 1개의 convolution layer로는 I와 ball을 연결할 수 없기 때문에 I와 ball을 연결하기 위해서는 그림과 같이 convolution layer를 더 쌓아야만 합니다.
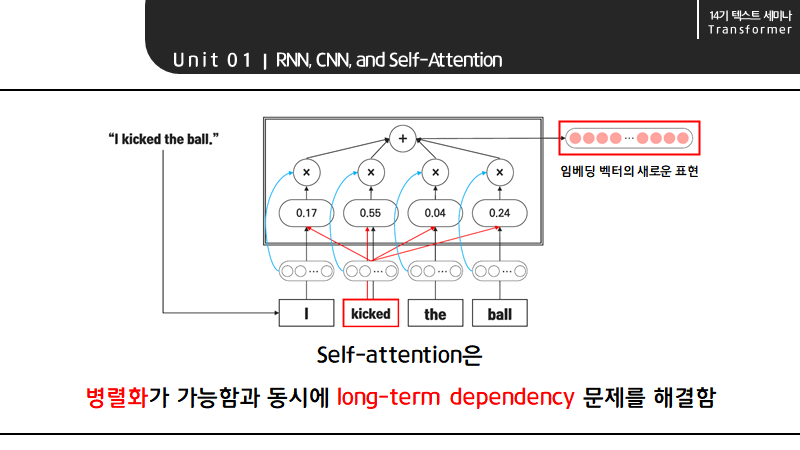
하지만 self-attention은 병렬화가 가능하면서 동시에 long-term dependency의 문제를 해결해 RNN와 CNN을 대체할 수 있는 learning mechanism으로 등장하게 되었습니다.
self-attention에서 예를 들어 kicked의 경우 모든 시퀀스의 임베딩 벡터와 dot product, softmax 과정을 거쳐 구한 attention score에 weighted sum을 하여 문맥을 고려한 새로운 임베딩 벡터를 만들 수 있습니다. 즉,self-attention은 각 token을 sequence 내 모든 token과의 연관성을 기반으로 재표현하는 과정으로 이해할 수 있습니다.
2. Transformer
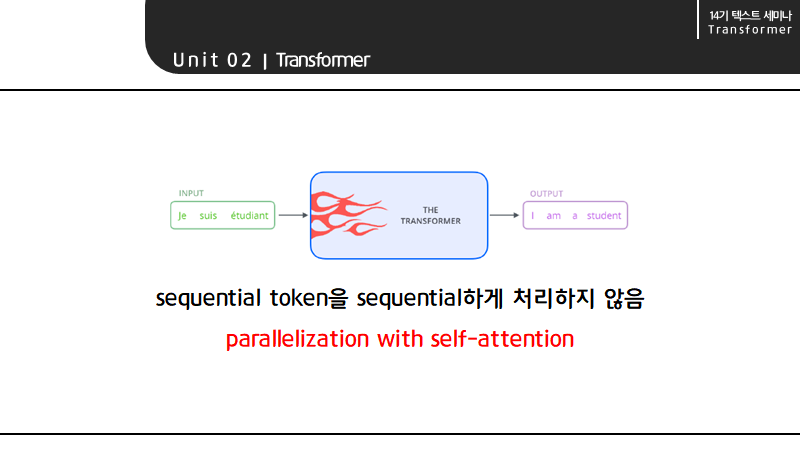
이러한 self-attention 메커니즘을 극대화한 모델이 바로 transformer라고 할 수 있습니다. transformer의 가장 큰 특징은 self-attention을 사용해 sequential한 토큰을 sequential하게 처리하지 않아 병렬처리를 가능하게 한 점입니다.
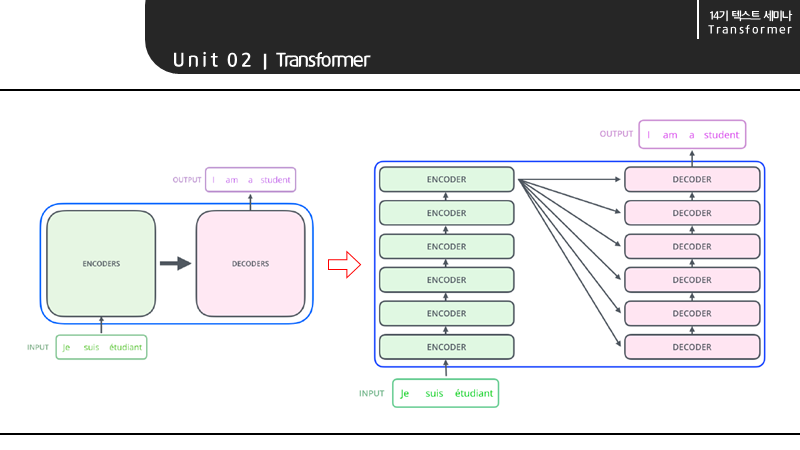
machine translation task를 처리할 수 있는 transformer는 자세히 보면 인코더 블록과 디코더 블록으로 구성되어 있습니다. 인코더 블록에는 6개의 인코더가 스택처럼 쌓여 있으며 논문에 의하면 그 개수는 6개라고 합니다. 참고로, 6이라는 값이 최적값은 아니라고 합니다. 또한 디코더 블록에도 마찬가지로 인코더와 같은 개수의 디코더가 쌓여 있습니다.
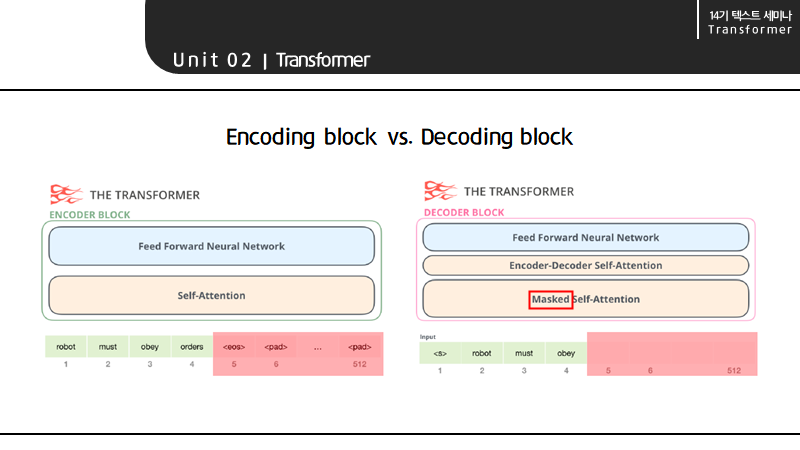
인코딩 블록과 디코딩 블록의 큰 차이점은 구조에 있습니다.
인코딩 블록의 경우 512개의 토큰 중 입력에 해당하지 않아 비어있는 토큰을 패딩으로 두고
시퀀스 단위가 4일 때 4개의 토큰을 self-attention과 feed forward neural network에 한번에 전달해 새롭게 표현된 임베딩 벡터를 출력하는 2단 구조로 구성되어 있습니다.
반면 디코딩 블록의 경우 인코딩 블록의 아웃풋과 masked self-attention의 벡터를 입력으로 받아 self-attention을 진행하기 때문에 2단 구조가 아닌 3단 구조로 구성되어 있습니다. 또한 인코딩 블록과 달리 디코더 블록의 output은 sequential하게 생성되기 때문에 만약 5번째 토큰이 생성되어야 하면 5번째 토큰을 마스킹하는 추가적인 작업이 필요한다는 차이점이 있습니다.
이제 transformer의 구조에 대해 살펴보겠습니다.
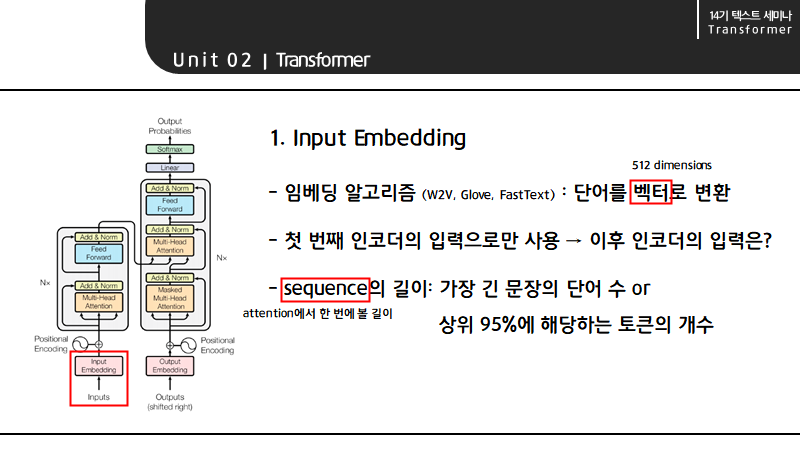
첫 번째 인코더 이후의 입력은 아랫단 인코더의 아웃풋이 되어 입력의 size는 512로 유지됩니다.
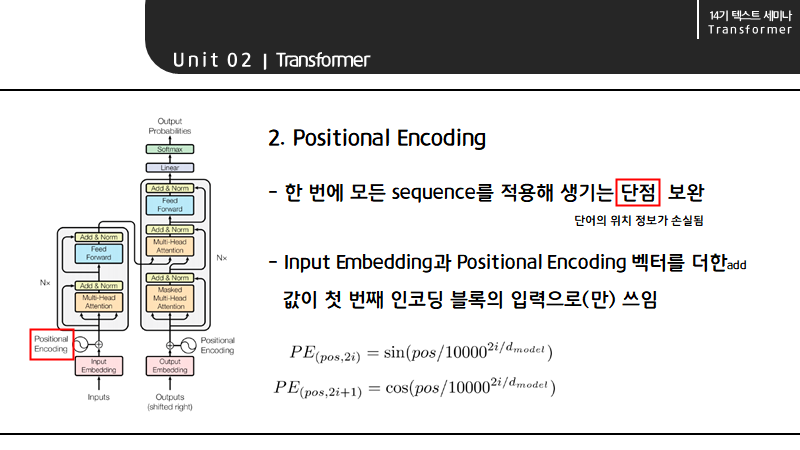
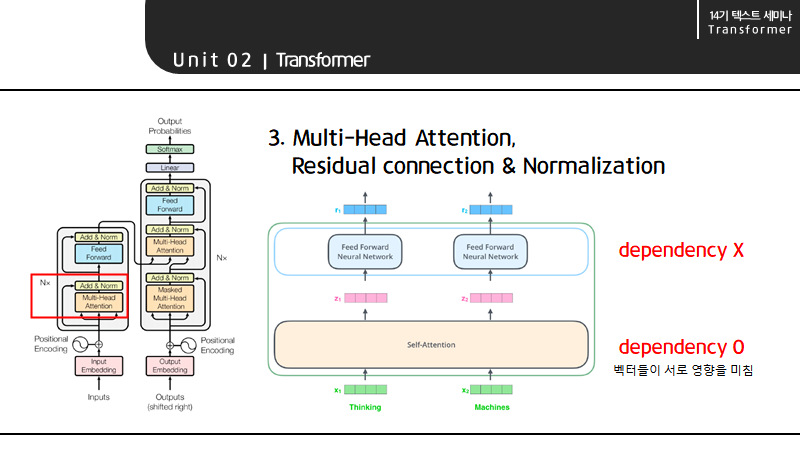
Multi-Head attention을 알아보기 전 self-attention에 대해 먼저 짚고 넘어가겠습니다.
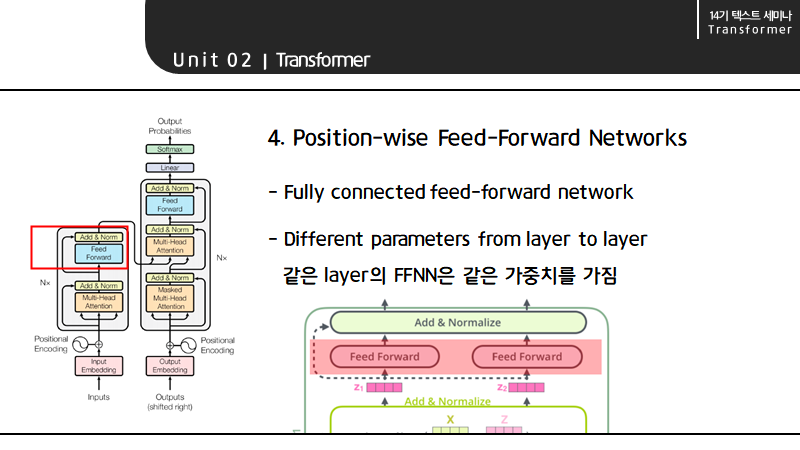
self-attention까지는 NXN 형태로 벡터들이 서로 영향을 끼치지만 Feed Forward Neural Network는 각 벡터마다 하나씩 존재해서 하나의 입력을 받아 하나의 아웃풋을 내놓습니다.
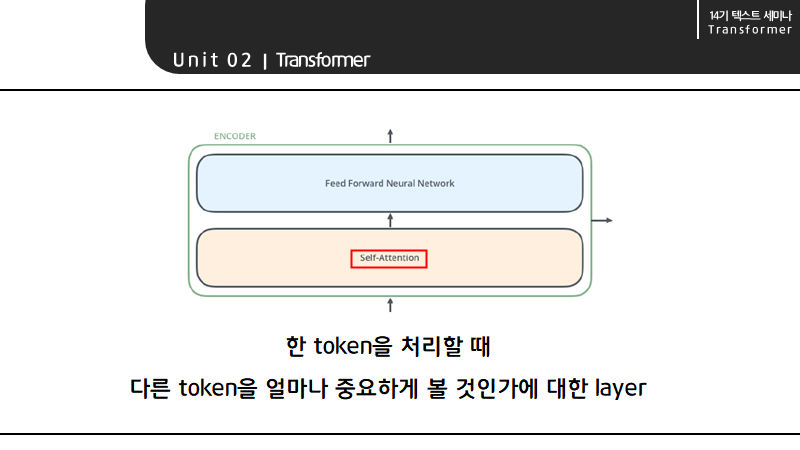
self-attention이란 정확히, 한 토큰을 처리할 때 그 토큰을 제외한 나머지 다른 토큰을 얼마나 중요하게 볼 것인가를 정하는 레이어를 가리킵니다.
즉, self-attention는 dependency를 가지기 때문에 "The animal didn't cross the street because it was too tired."에서 it과 연관된 단어를 찾기 위해 The부터 시작해서 because, was, too, tired까지 모든 단어를 이해할 수 있습니다.
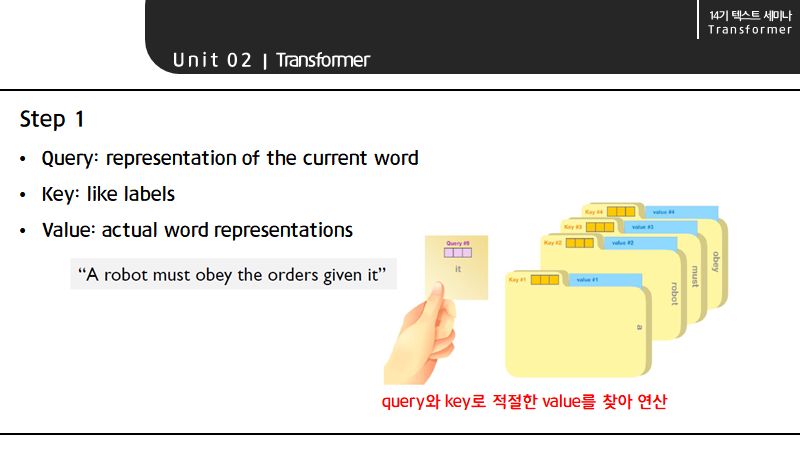
가장 먼저, self-attention은 인코더의 입력 벡터로부터 세 개의 벡터를 만듭니다. 그 벡터는 각각 query, key, value를 말합니다.
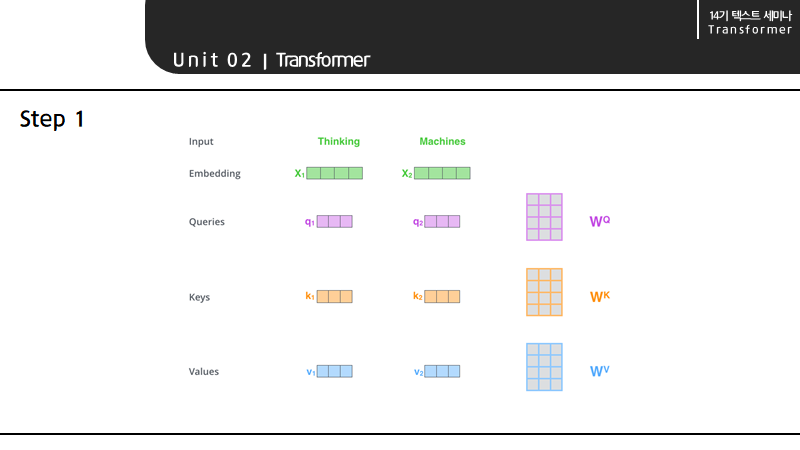
구체적으로 말하자면, input embedding에 query matrix를 곱해 query를 만들고, key matrix를 곱해 key를 만들고, value matrix를 곱해 value를 만들게 됩니다. 이때 각각의 matrix는 미지수로, 학습을 통해 도출된다고 합니다.
특히 인코더의 입출력 벡터가 512 차원인 것에 비해 query, key, value의 dimension은 각 64 밖에 되지 않는데, 이는 후에 multi-head attention을 8개를 사용해 dimension을 concat하여 사이즈를 맞추게 될 것을 의미하기도 합니다.

self-attention의 두 번째 단계는 query와 문장의 어느 부분이 연관성이 높은지를 수치화하는 것입니다. 그림으로 비유하자면, query vector와 key vector를 곱해 각각의 "폴더"에 대해 score를 계산하는 것이 self-attention의 두 번째 단계라고 할 수 있습니다.
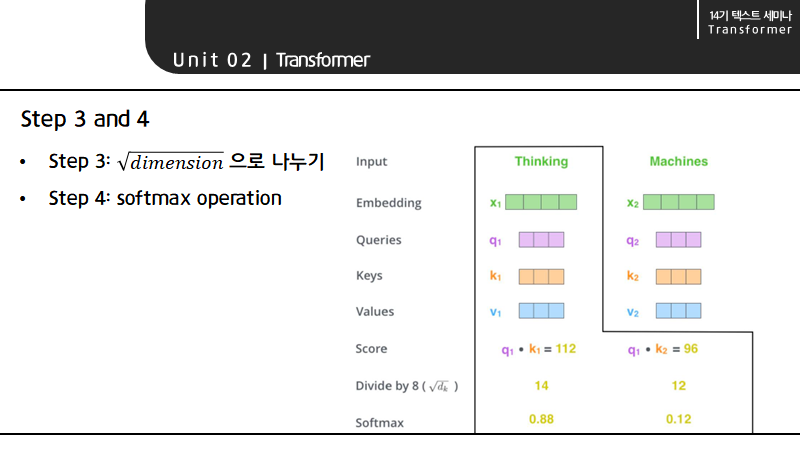
다음으로 각 score를 dimension의 제곱근으로 나누고 softmax operation을 통과시킵니다. 이때 scaling을 하는 이유는 attention score를 다양한 vector에 분산시켜 gradient의 stability에 도움이 되기 때문입니다.

다음으로 각 토큰의 softmax 값과 value를 곱합니다. 이 경우 Thinking의 softmax 값이 커 Thinking의 weighted value가 Machines의 weighted value보다 크게 됩니다. 즉, Thinking이라는 단어에 Thinking이라는 단어의 영향력이 크다는 것을 의미합니다.
이어서 모든 value vector를 더하면 Thinking이 query일 때 self-attention output을 구할 수 있습니다.
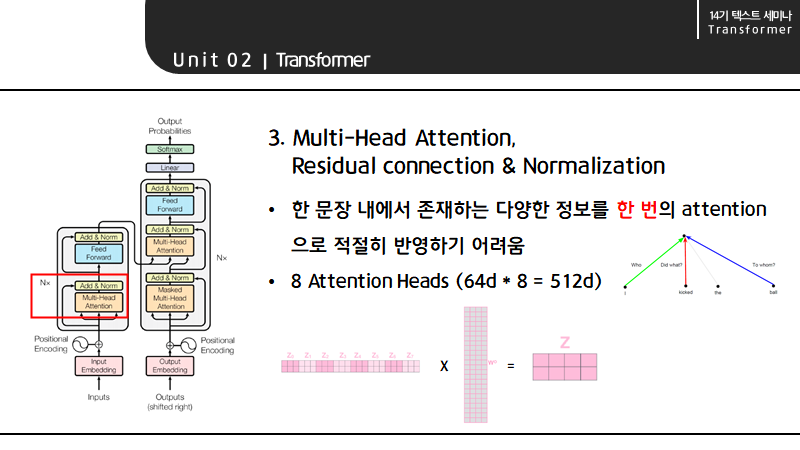
다시 Multi-Head attention으로 돌아와서, 한 문장 내에서는 누가? 무엇을? 누구에게? 등 다양한 정보가 존재하는데 이러한 정보를 한 번의 attention으로 적절히 반영하는 것은 어렵습니다. 하지만, 하나의 어텐션이 문장 내에서 존재하는 한가지 정보에 집중하게 된다면 8개의 head를 가진 attention을 사용해 정보를 적절히 attention score에 반영할 수 있습니다.
더불어 Multi-Head Attention에서 FFNN의 input size(=4)를 맞춰주기 위해 추가적인 작업이 필요합니다. 각각의 attention에서 나온 score를 concat한 attention score의 길이와 같은 column의 수를 가진 matrix를 곱해 (row는 input의 개수인 4) attention score를 FFNN의 input dimension과 일치시켜줘야 합니다. 이때 곱하는 matrix는 모델의 학습 과정에서 학습되는 matrix 입니다.
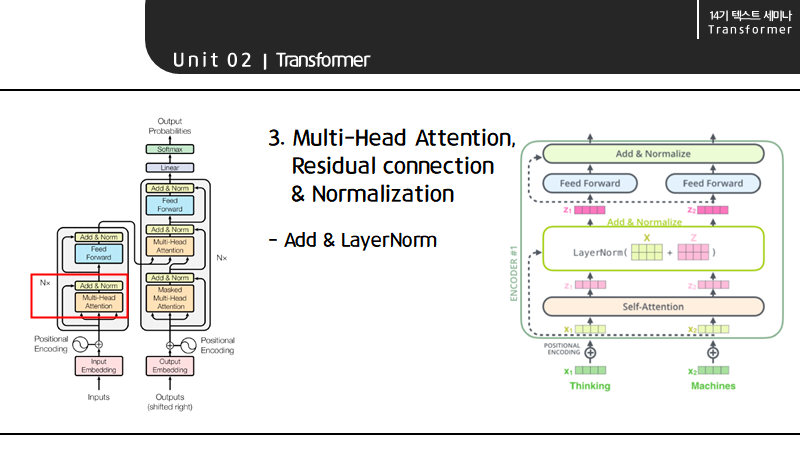
Multi-Head Attention 이후에는 attention output과 vector를 더해 layer normarlization 과정을 거친 후 각각의 row를 feed forward neural network에 전달합니다.
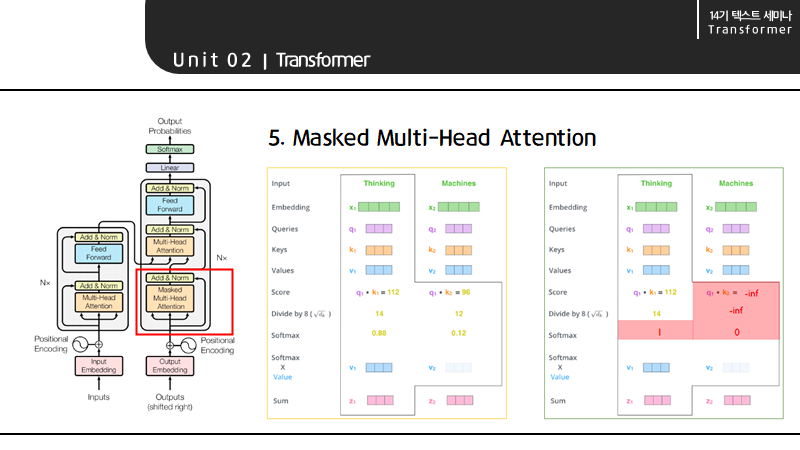
앞서서 언급한 Masked랑 같은 의미인데, 디코더는 현 query 앞 token의 attention score만 볼 수 있기 때문에 만약 현재 query가 Thinking이라면 Machines의 attention score 값은 아주 작은 -inf 값으로 설정 후 계산하게 됩니다.
이를 통해 토큰들 사이에 인과관계를 부여할 수 있습니다.
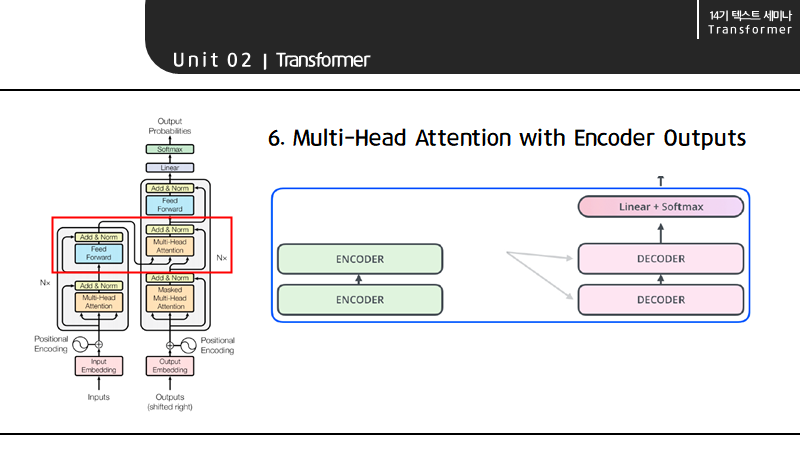
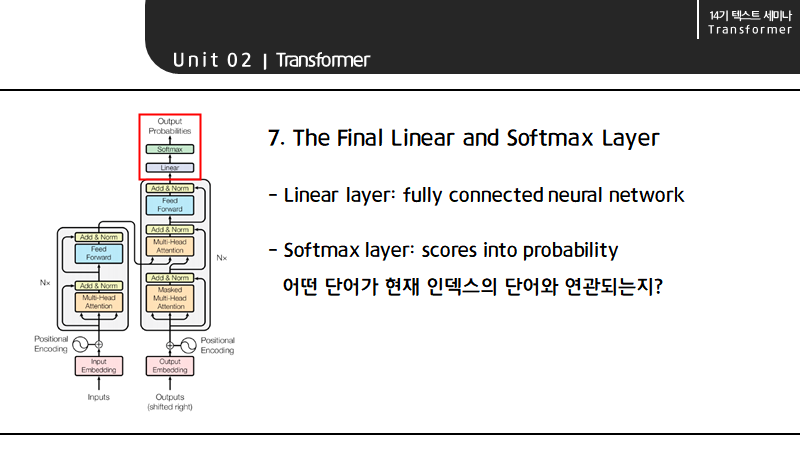
Linear layer는 FFNN의 일종으로 vector를 펼치는 역할을 하며, Softmax layer는 attention score를 probability로 바꿔줘 대응하는 단어를 return합니다.
3. Image Transformer
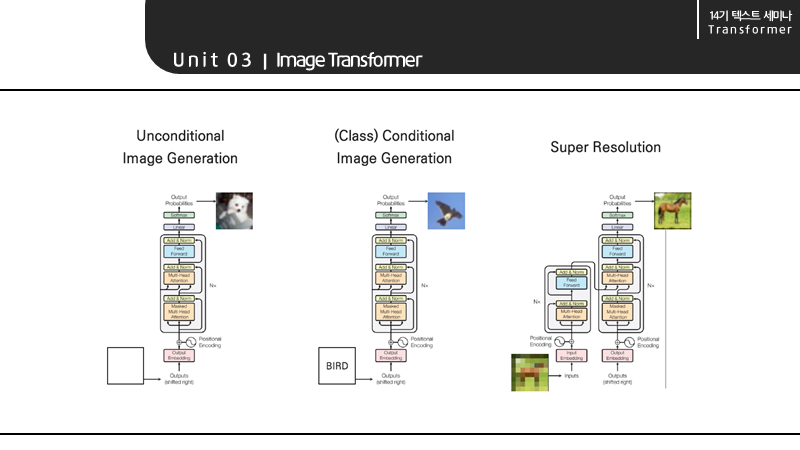
이미지 트랜스포머의 첫 번째 태스크는, Unconditional Image Generation은 대규모의 데이터로 특정한 이미지를 제작하는 태스크를 의미합니다.
두 번째 태스크는, Class Conditional Image Generation은 클래스 각각의 임베딩 벡터를 입력으로 받아 이미지를 제작하는 태스크를 의미합니다.
마지막 태스크는, Super Resolution은 저화질의 이미지를 입력으로 받아 고화질의 이미지를 출력하는 태스크를 의미합니다.
첫 번째 두 번째 태스크는 디코더만을 사용하며, 마지막 태스크는 인코더와 디코더를 모두 사용하는 것을 확인할 수 있습니다.
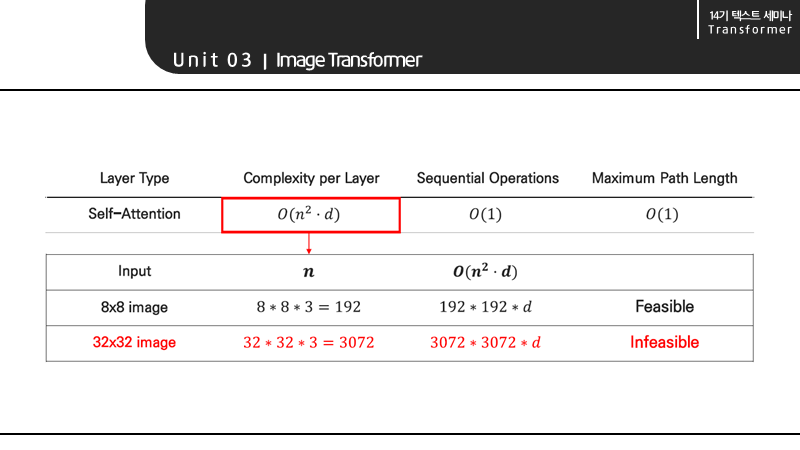
앞서서 self-attention의 장점으로 적은 연산량을 들었습니다. 하지만 이미지의 경우 dimension보다 sequence length 즉 pixel의 길이 n이 커져 self-attention이 비효율적이게 됩니다.
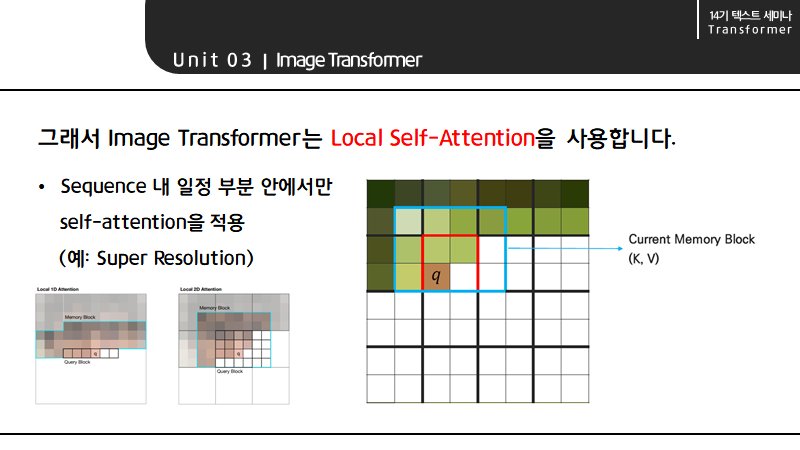
그래서 Image Transformer는 Local Self-attention을 사용합니다. Local self-attention은 sequence 내 일정 부분 안에서만 self-attention을 적용하는 방법을 의미합니다.
Super Resolution Task를 예로 들어보면, input을 겹치지 않은 block으로 구분했을 때 이 사진에서 현재 query는 q이고 target pixel은 그 옆에 있는 칸임을 알 수 있습니다. 그리고 하나의 블록을 둘러싸는 만큼을 memory block이라고 합니다.
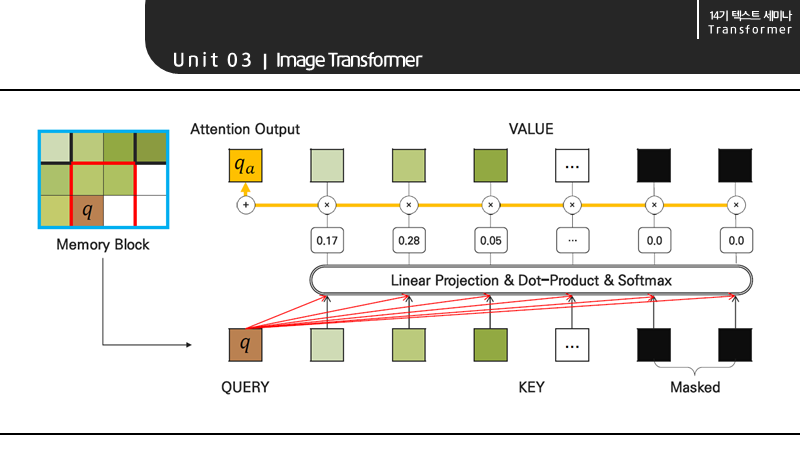
memory block 내 pixel을 key와 value로, query pixel을 query로 하는 self-attention은 Linear Projection, Dot-Product, Softmax 과정을 거쳐 구현할 수 있습니다. 그리고 encoder-decoder의 attention과 FFNN를 거쳐 output이 생성되고 Query block과 memory block을 재지정하고 과정을 반복함으로써 pixel by pixel로 Image를 generation 할 수 있습니다.
4. Music Transformer
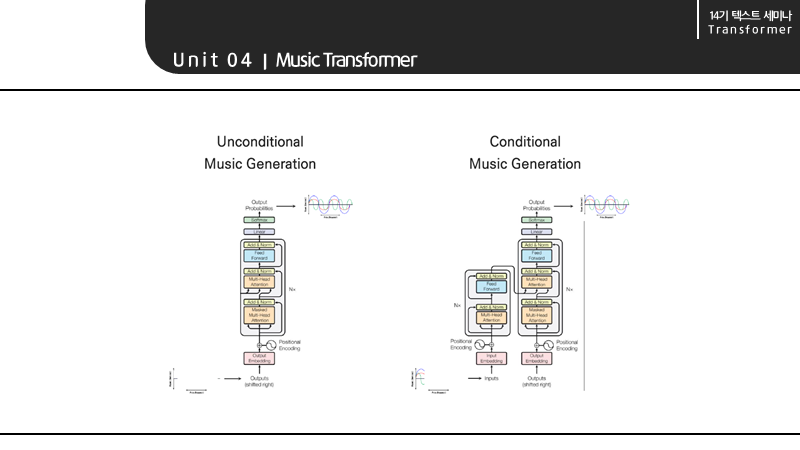
뮤직 트랜스포머의 태스크는 다음과 같습니다.
- input sequence 없이 다양한 데이터를 통해 음악을 생성하는 것
- 음악의 앞 부분을 입력으로 받아 그 뒷부분을 생성하는 것

Music Transformer는 Relative Positional Self-Attention을 사용합니다. 즉, 일반적인 Self-attention에 Relative Positional Vector를 더해 query와 key의 sequence 내 거리를 attention weight에 반영합니다.
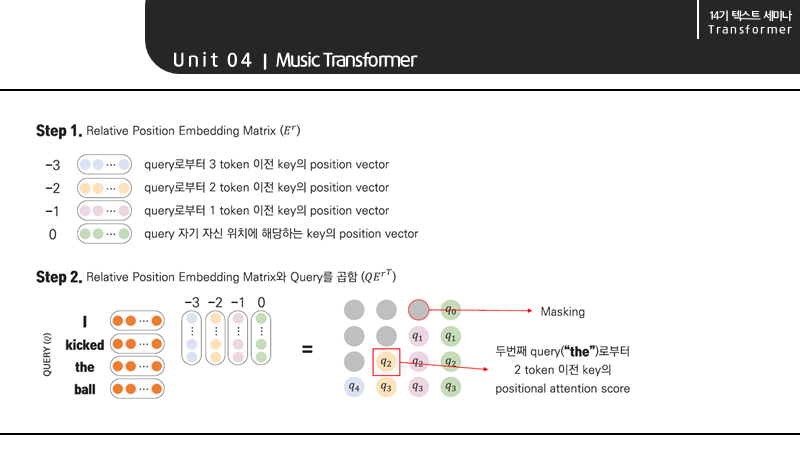
Relative Positional Self-Attention은 가장 먼저 Relative Positional Embedding Matrix를 만들어야 합니다.
다음으로 Query와 Matrix를 곱합니다. 이때 q2는 0, 1, 2번째 query인 the의 2 token 이전의 positional attention score를 의미합니다.
그리고 각 row 기준 값이 없는 것들은 Masking을 해줍니다. I는 이전의 key가 없으므로 다 마스킹 됩니다.
이 방식은 query에 따라 positional attention score가 달라지므로 positional encoding보다 풍부한 표현을 할 수 있다는 장점이 있습니다.

그리고 기존의 attention score와 더할 수 있도록 즉, 마스킹한 모양이 저런 삼각형이 되도록 위와 같은 과정을 거쳐 score를 reshape 해주어야 합니다.

마지막으로 기존 attention score에 relative positional attention score를 더하여 output을 산출합니다.

Relative self-attention이 적용된 music transformer는 다양하고 반복적인 곡을 생성함과 동시에 training data보다 2배나 긴 sequence에 대한 generation 또한 가능하다는 것을 확인할 수 있었습니다.
References
- CS224n: Natural Language Processing with Deep Learning in Stanford / Winter 2019 중
Transformers and Self-Attention For Generative Models (guest lecture by Ashish Vaswani and Anna Huang) - 고려대학교 산업경영공학과 DSBA 연구실 CS224n Winter 2019 세미나 중 14. Transformers and Self-Attention For Generative Models 강의자료와 강의 영상 (노영빈님)
- 고려대학교 산업경영공학과 강필성교수님 2020-1학기 '비정형데이터분석' 수업 (Graduate) 중
08-2_Transformer 강의자료와 강의 영상
