
작성자 : 투빅스 13기 김민정
Contents
- Decoding Algorithm
- Neural Summarization
- Copy Mechanisms
- NLG Using Unpaired Corpus
1. Decoding Algorithm
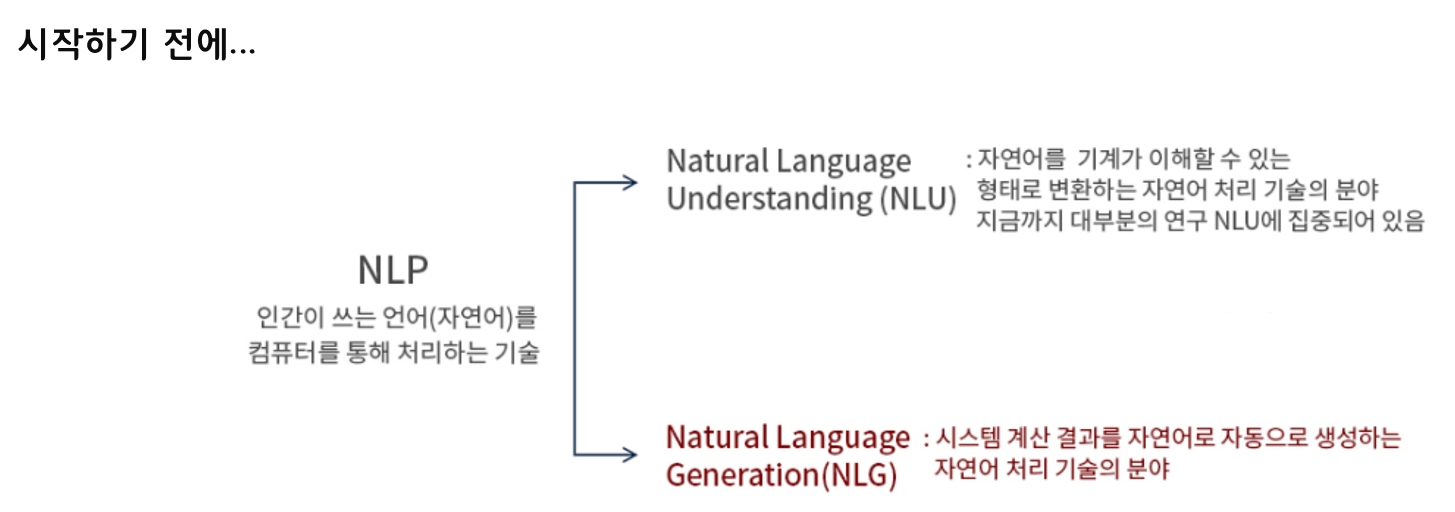
시작하기 전에 NLG가 무엇인지 살펴보겠습니다.
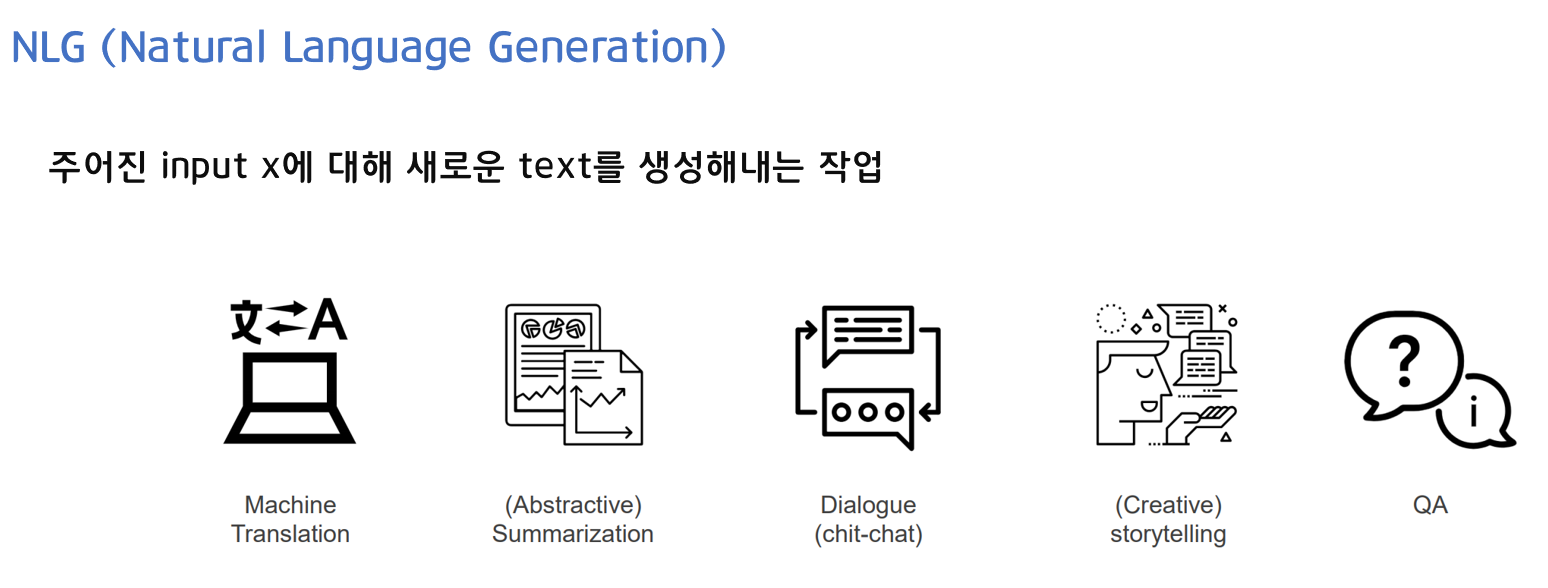
NLG란 주어진 input x에 대해 새로운 text를 생성해내는 작업입니다.
기계 번역, 요약, 채팅, 스토리텔링, QA 등이 있습니다.

적절성, 유창성, 가독성, 다양성을 골고루 만족하는 경우 자연어를 잘 생성한다고 말할 수 있습니다.
- 적절성
생성된 문장이 모호하지 않고 원래의 input text의 의미와 일치 - 유창성
문법이 정확하며 어휘를 적절하게 사용해야 함
사람이 하는 것처럼 유창하게 말해야 한다는 것 - 가독성
적절한 지시어, 접속사 등을 사용하여 문장의 논리 관계를 고려하여 생성해야 함
자연어를 생성할 때 대표적으로 어려운 부분 중 하나 - 다양성
상황에 따라 혹은 대상에 따라 표현을 다르게 생성해야 함

지금까지 공부했던 LM을 학습한 후에 어떻게 NLG에 적용할 수 있냐는 질문의 답변으로 Decoding Algorithm을 제시할 수 있습니다.
이때, 가장 가능성이 높은 출력 시퀀스를 디코딩하는 것이 아니라, 최대한 가능성이 높은 출력 시퀀스를 디코딩하는 것입니다. vocab의 크기가 어마어마하게 큰 경우에는 완전 탐색을 하는 것이 어렵기 때문에 휴리스틱한 탐색 방법인 Decoding Algorithm을 사용하자는 것입니다.
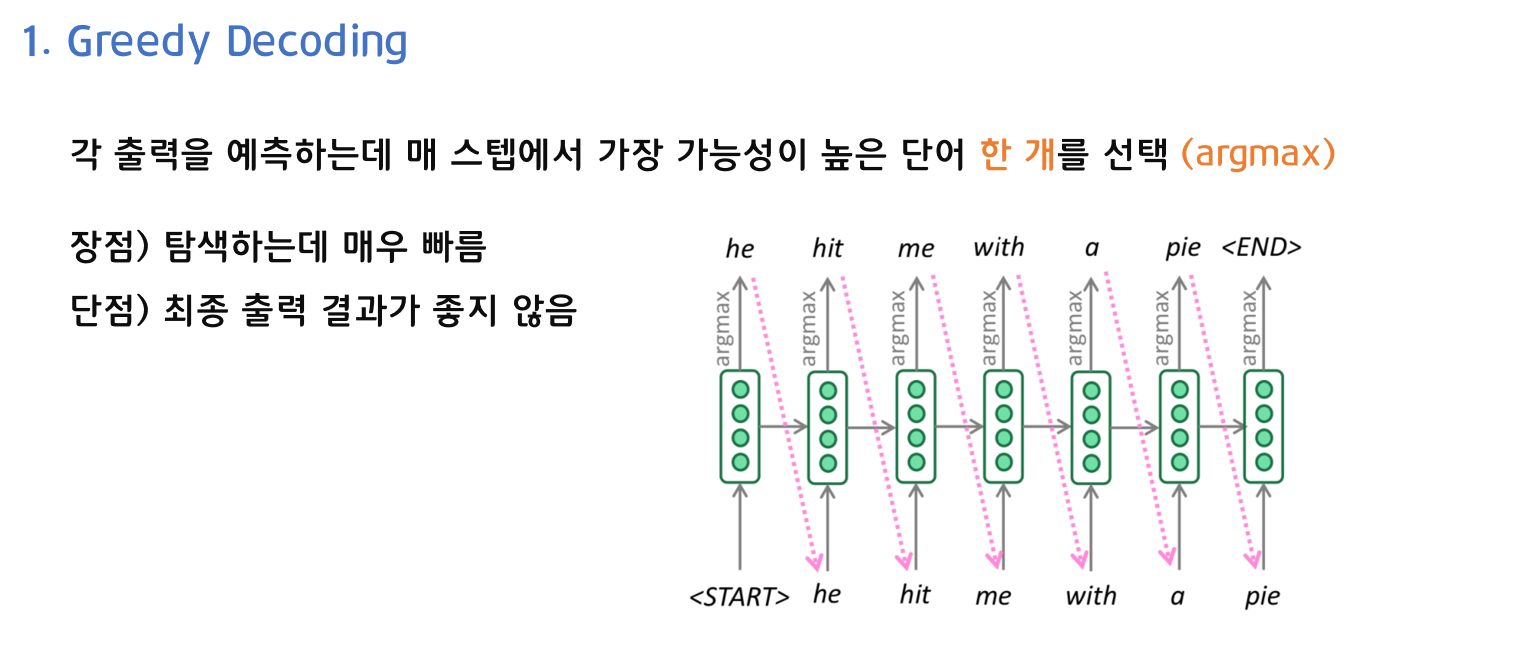
1) Greedy Decoding
첫 번째로, Greedy Decoding입니다. Greedy Decoding은 각 출력을 예측하는데 매 스텝에서 가장 가능성이 높은 단어 한 개를 선택합니다. 이때, argmax를 사용합니다. 매 스탭마다 한 개만 선택하면 되기 때문에 탐색하는데 매우 빠릅니다. 하지만 어떤 스텝에서 실수를 하는 경우에 그 실수가 해당 스텝 이후의 단어를 선택하는데 까지 영향을 미치기 때문에 최종 출력 결과가 좋지 않을 수 있다는 단점이 있습니다.
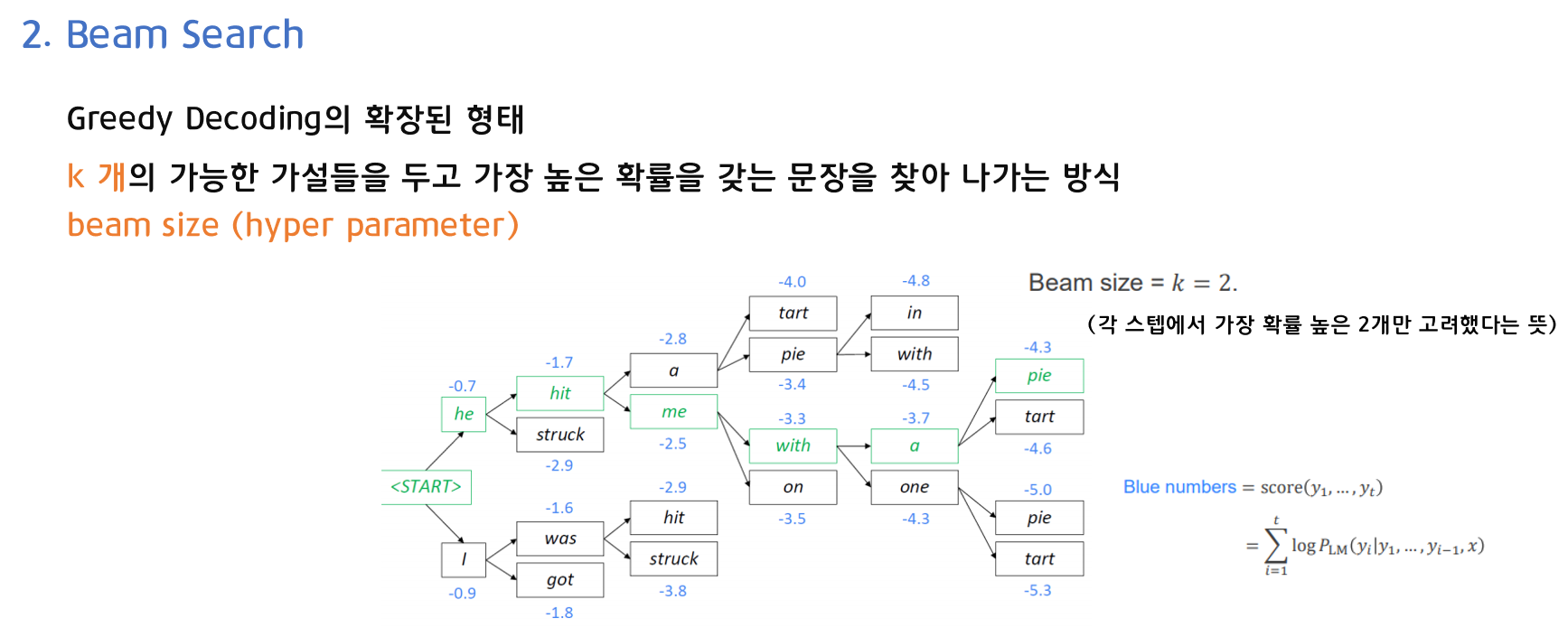
2) Beam Search
두 번째로, Beam Search입니다. Beam Search는 k개의 가능한 가설들을 두고 가장 높은 확률을 갖는 문장을 찾아 나가는 방식입니다. 이때 k는 beam size를 의미하는 하이퍼 파라미터이며, k=1인 경우 Greedy Decoding과 동일하기 때문에 Greedy Decoding의 확장된 형태라고 볼 수 있습니다.
위의 예시에서는 k=2인 경우로, 각 스텝에서 가장 확률이 높은 2개씩만 고려했습니다. 누적 확률을 크게 하는 단어들을 따라서 문장이 생성됩니다. 파란색 숫자는 확률(0과 1 사이)에 로그 값을 취한 형태이기 때문에 음수 값을 가지며, 절댓값이 작은 단어를 따라서 문장이 생성됩니다.

그렇다면 Beam Search에서는 k(beam size)를 어떻게 고를까요? k(beam size)에 따른 결과를 살펴봅시다.
- Low beam size
beam size가 너무 작으면 주제에 더 가깝지만 말이 안되는 답변을 뱉음 - High beam size
beam size가 너무 크면 너무 일반적이고 짧은 답변을 뱉음
BLEU score를 떻어뜨릴 수 있음

3) Sampling-based decoding
세 번째로, Sampling-based decoding입니다. Beam Search에서 큰 k(beam size)를 가지더라도 너무 일반적인 답변을 얻지 않기 위한 방법입니다.
Pure Sampling과 Top-n Sampling이 있습니다.
Pure Sampling은 Greedy Decoding과 비슷하지만, argmax 대신 sampling을 사용합니다.

Top-n Sampling은 Pure Sampling처럼 완전하게 랜덤 샘플링을 하는 것이 아니라 확률이 가장 큰 n개의 단어들 중에서 랜덤 샘플링을 하는 것입니다.
2. Neural Summarization
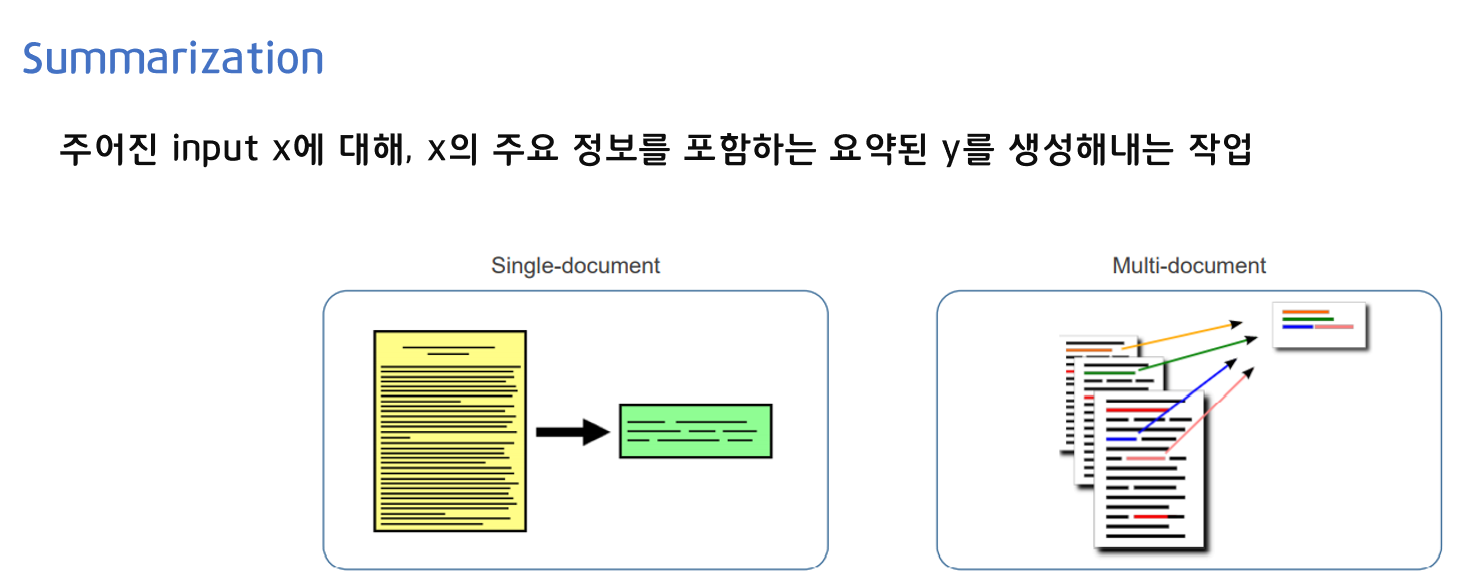
요약(Summarization)이란 주어진 input x에 대해, x의 주요 정보를 포함하는 요약된 y를 생성해내는 작업입니다.

크게 Extractive Summarization과 Abstractive Summarization이 있습니다.
Extractive Summarization이란 문서 내에서 핵심이 되는 문장을 추출하는 것으로, 비교적 쉽지만 제한적인 요약 결과를 얻게 됩니다.
Abstractive Summarization이란 문서의 중요한 내용을 담은 새로운 문장을 생성하는 것으로, 보다 유연한 결과를 얻을 수 있지만 비교적 어렵습니다.
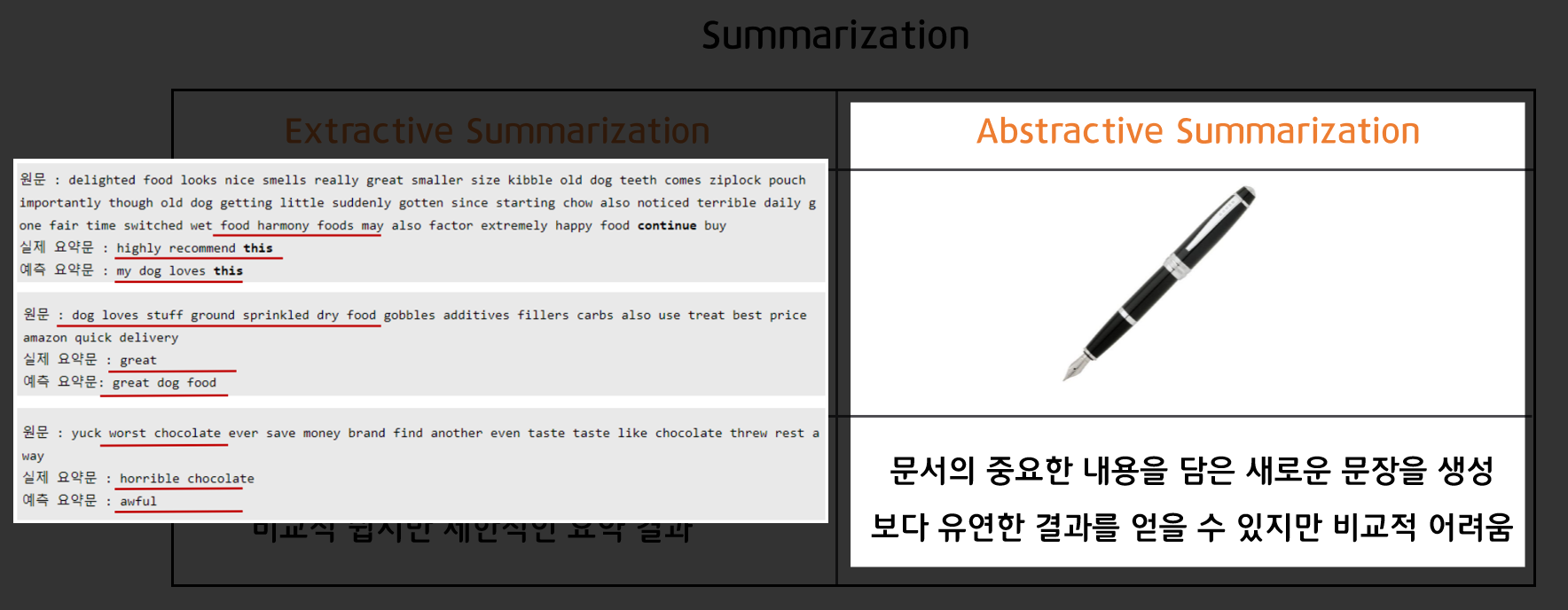
이후에 다룰 Neural을 적용한 요약(Summarization)은 Abstractive Summarization입니다.
왼쪽 예시를 보면 원문에서 요약된 결과가 문장 그대로를 추출하는 것이 아닌, 새로운 문장을 생성해냄을 확인할 수 있습니다.
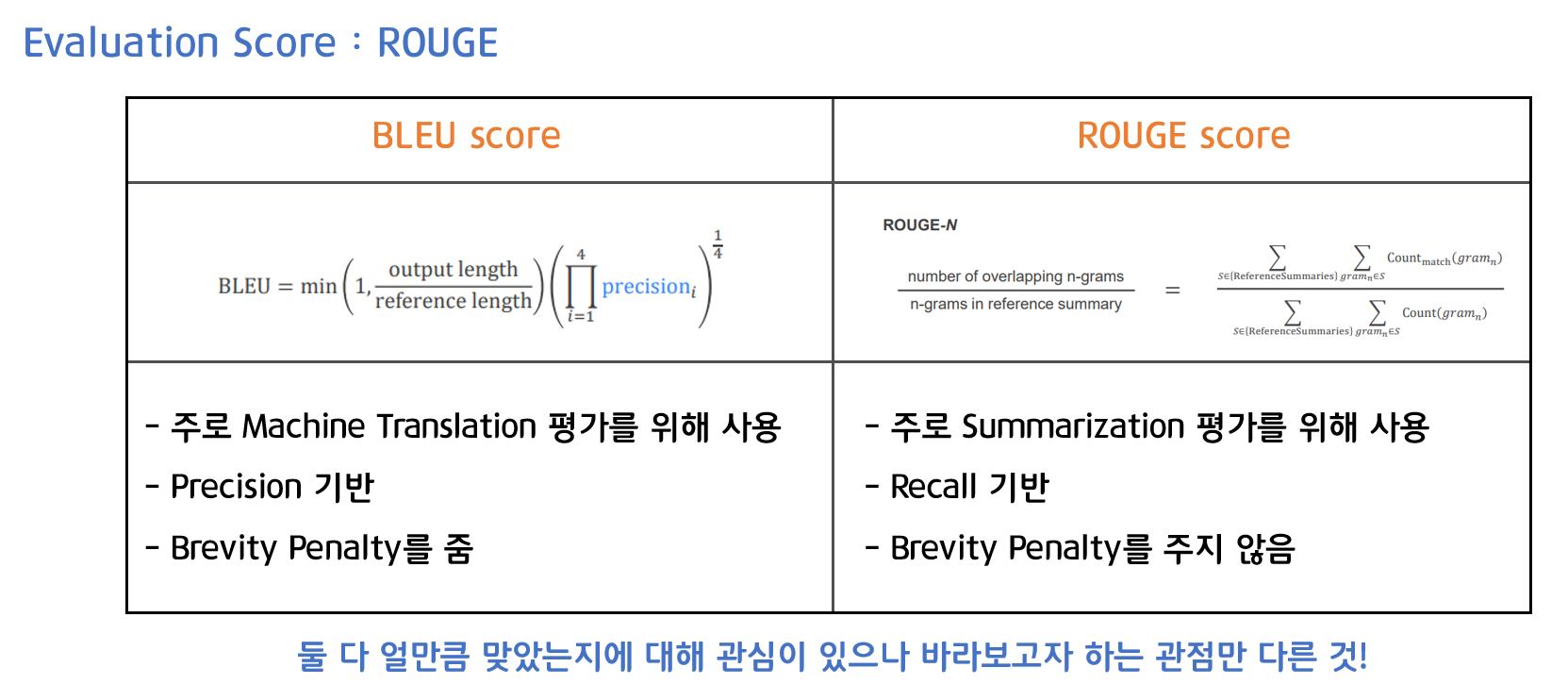
평가 지표인 ROUGE를 BLEU score와 비교하여 살펴보겠습니다.
- BLEU score
주로 기계 번역(Machine Translation) 평가에 사용
Precision 기반
Brevity Penalty를 줌 - ROUGE score
주로 요약(Summarization) 평가에 사용
Recall 기반
Brevity Penalty를 주지 않음
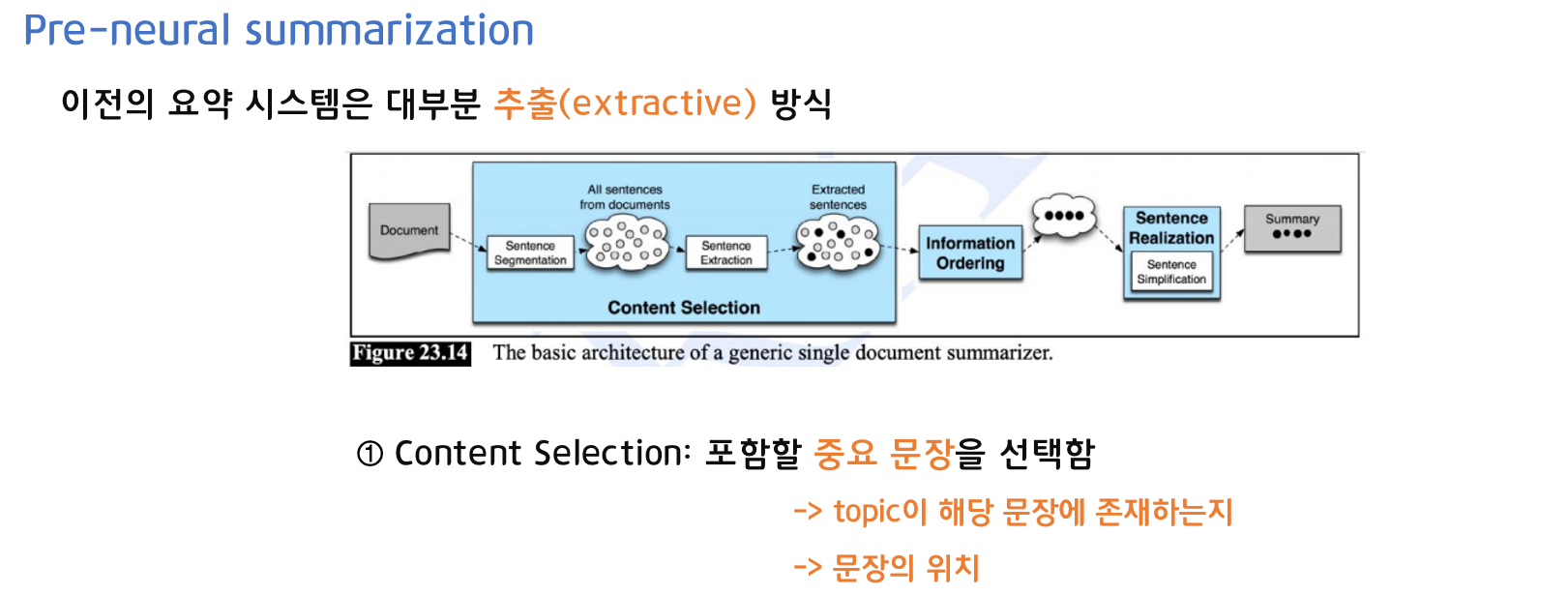
Neural 이전의 요약 시스템은 대부분 추출(extractive)방식입니다.
- 1. Content Selection
포함할 중요 문장을 선택합니다. 중요 문장은 topic이 해당 문장에 존재하는지, 문장의 위치는 어디에 있는지 등으로 선택합니다.
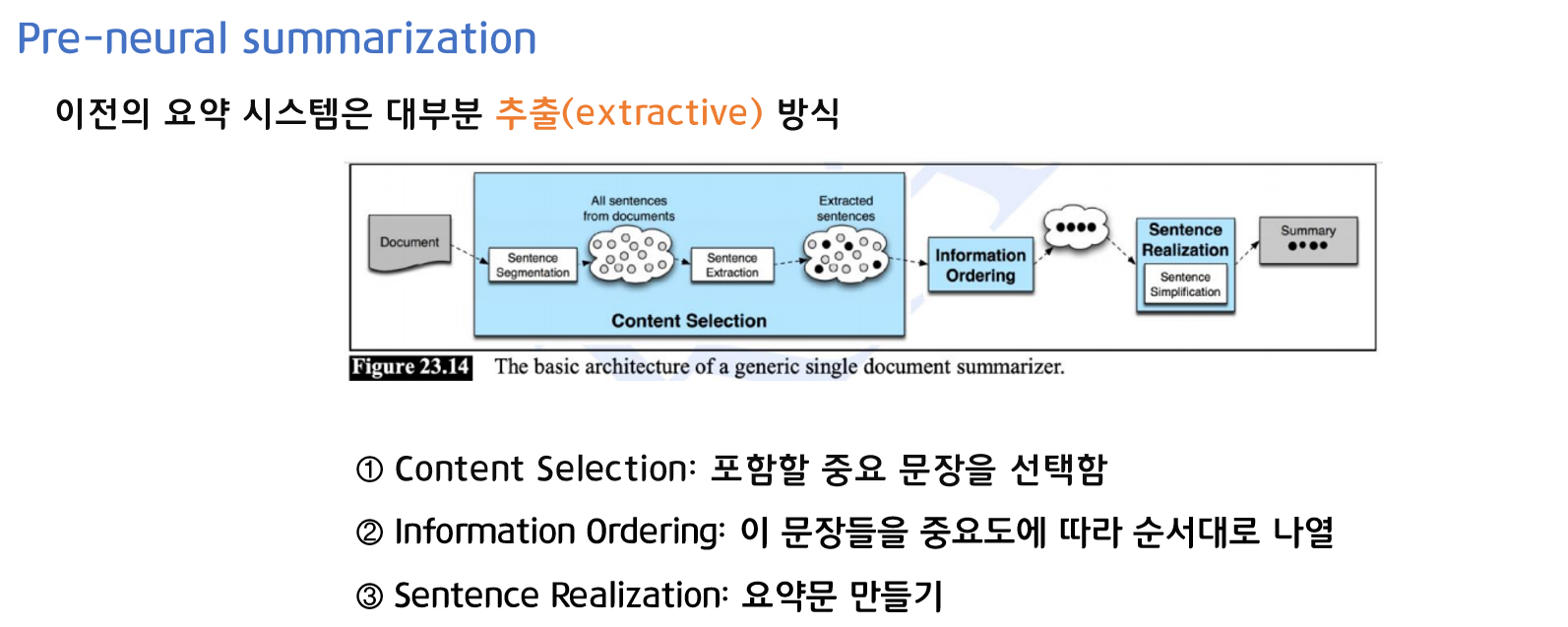
- 2. Information Ordering
1 에서 선택한 문장들을 중요도에 따라 순서대로 나열합니다. - 3. Content Selection
요약문을 생성합니다.
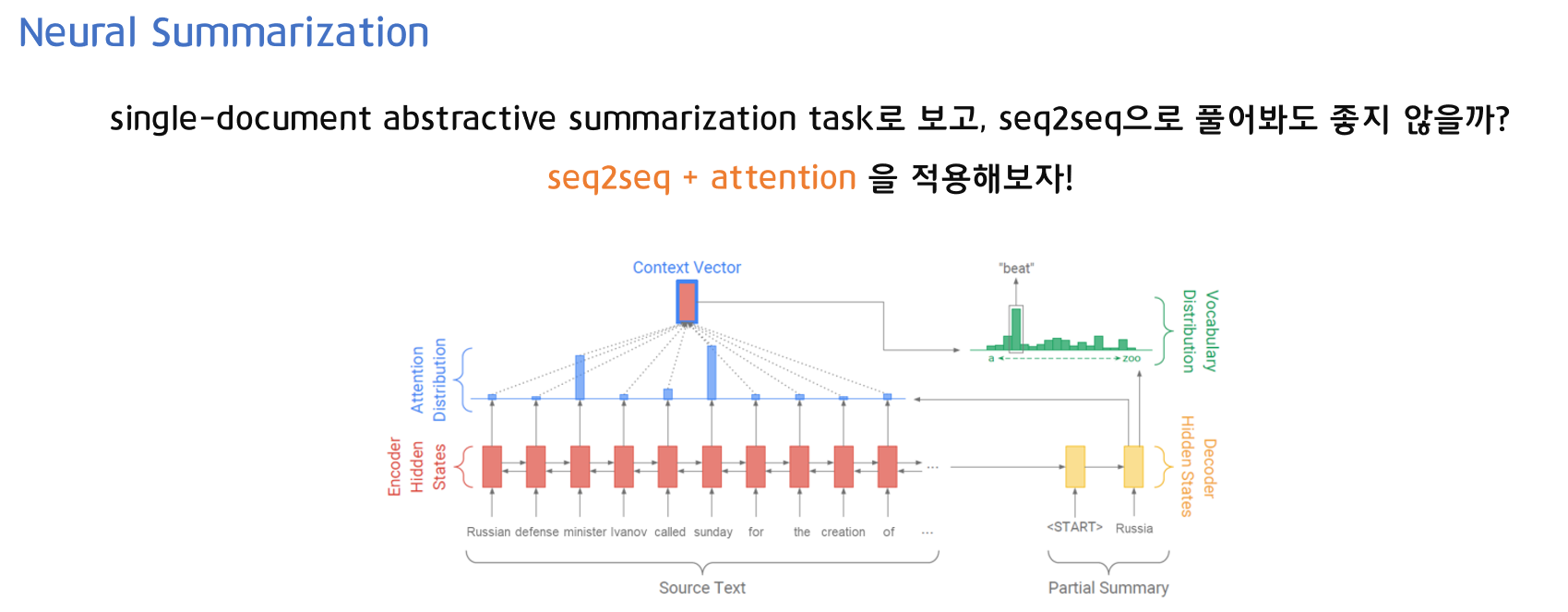
신경망(Neural)을 이용한 요약(Summarization)은 Seq2seq과 Attention을 사용해 요약문을 생성하고자 했습니다.
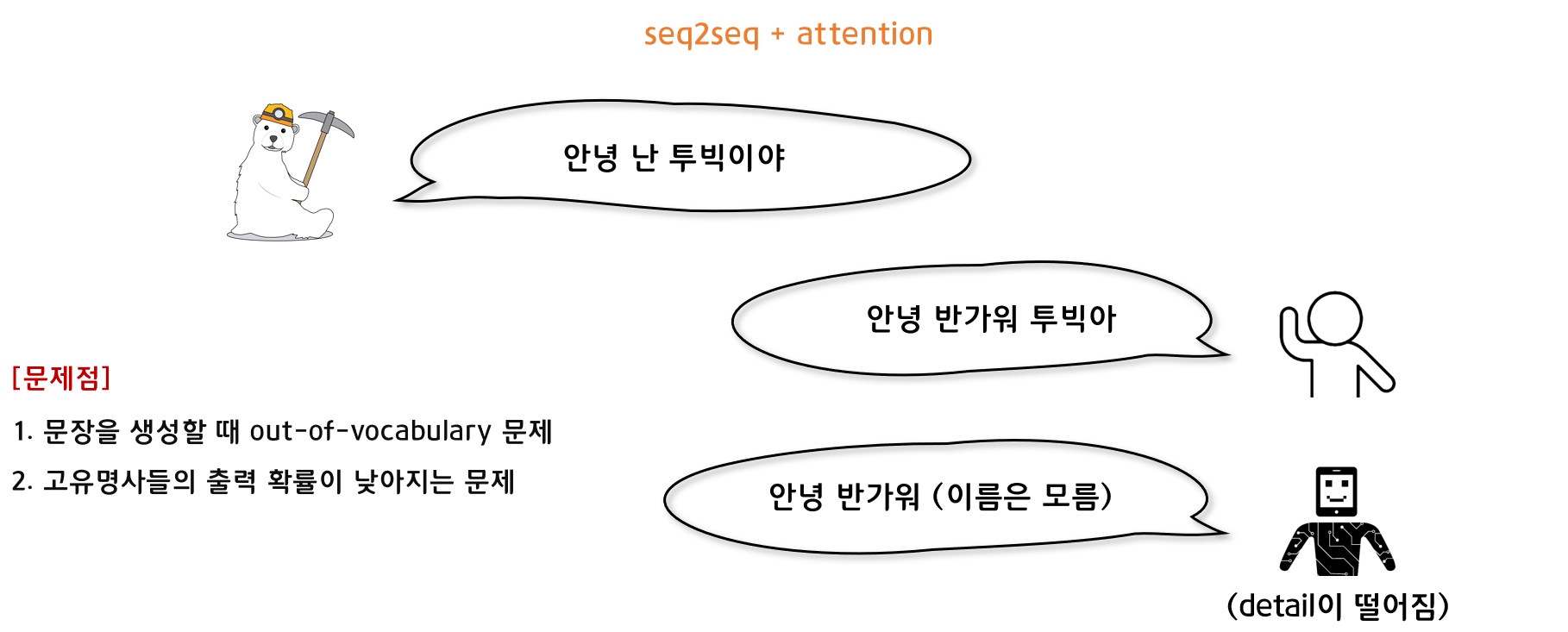
하지만 Seq2seq과 Attention만을 적용한 모델은 디테일을 잡아내기에 한계점이 있습니다.
예를 들어 '안녕 난 투빅이야'라는 문장에 대한 대답으로 사람은 '안녕 반가워 투빅아'라고 대답을 할 수 있습니다. 그러나 모델(Seq2seq+Attention)은 '안녕 반가워'와 같은 대답은 할 수 있지만, '투빅아'와 같은 고유 명사를 사용하지는 못하는 문제가 있습니다.
3. Copy Mechanisms
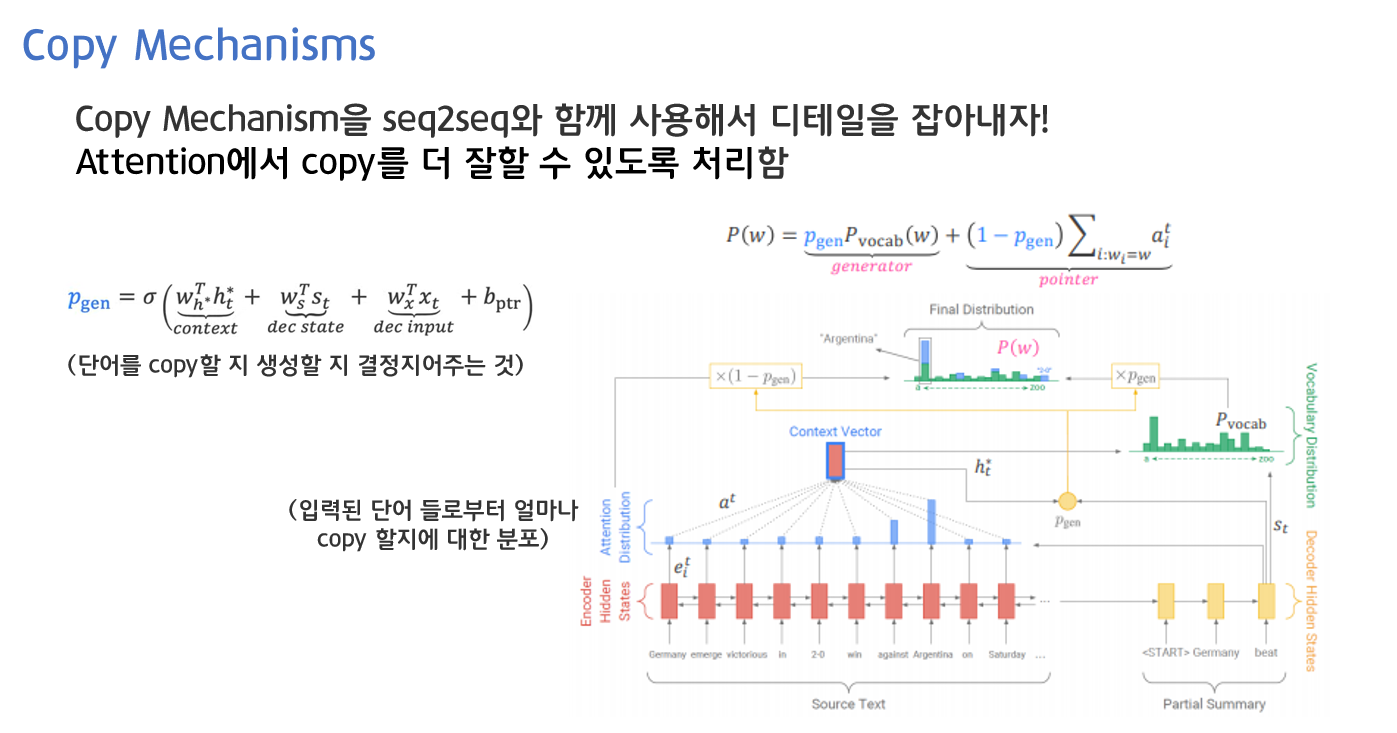
Copy Mechanisms을 seq2seq과 함께 사용해서 디테일을 잡아내고자 했습니다. Attention에서 copy를 더 잘할 수 있도록 처리한 것입니다.
- P_gen은 단어를 copy할지 생성할지 결정지어주는 것이 generation probability입니다. Context vector와 디코더 상에서의 타임 스텝의 히든 스테이트를 입력 받고 디코더 상에서의 input을 입력 받아서 시그모이드를 통해 계산할 수 있습니다.
- P_vocab은 Context vector와 디코더 상에서의 타임 스텝의 히든 스테이트를 가지고 소프트 맥스를 취해 계산할 수 있습니다.
- attention 분포는 입력된 단어들로부터 얼마나 copy할건지에 대한 분포를 가지고 있는 것입니다.

기존의 pre-neural summarization은 중요 문장을 선택하는 부분인 content selection과 요약을 하는 부분인 surface realization으로 나누어 동작합니다. 하지만 neural approach는 그런 것 없이 하나로 묶어져 나오기 때문에 전체적인 것을 보지 못하는 문제가 발생합니다.

이러한 점을 보완하기 위해 등장한 방법이 Bottom-up summarization입니다. word가 포함되었는지, 포함되지 않았는지에 따라 0과 1을 태깅하며 모델은 word가 포함되지 않은 부분에는 집중하지 않습니다. 간단하지만 매우 효과적인 방법이라고 합니다.
4. NLG Using Unpaired Corpus

지금까지는 input에 대응하는 output을 미리 준비한 후에 학습시키는 지도 학습에 기반하고 있습니다. 예를 들어 '오늘 날씨 알려줘'에 대응한 출력 문장인 '오늘 비가 올 것 같아요'와 같은 쌍을 준비하여 학습합니다.
그러나 이러한 방법의 문제는 입력-출력 쌍의 데이터를 대량으로 요구한다는 것입니다. 고성능의 자연어 생성 시스템을 만들기 위해 그 훈련에 필요한 말뭉치의 확보부터가 현실적으로 매우 어렵습니다.
따라서 이러한 한계점을 돌파하기 위해 Unpaired corpus를 활용한 비지도 학습이 등장합니다.
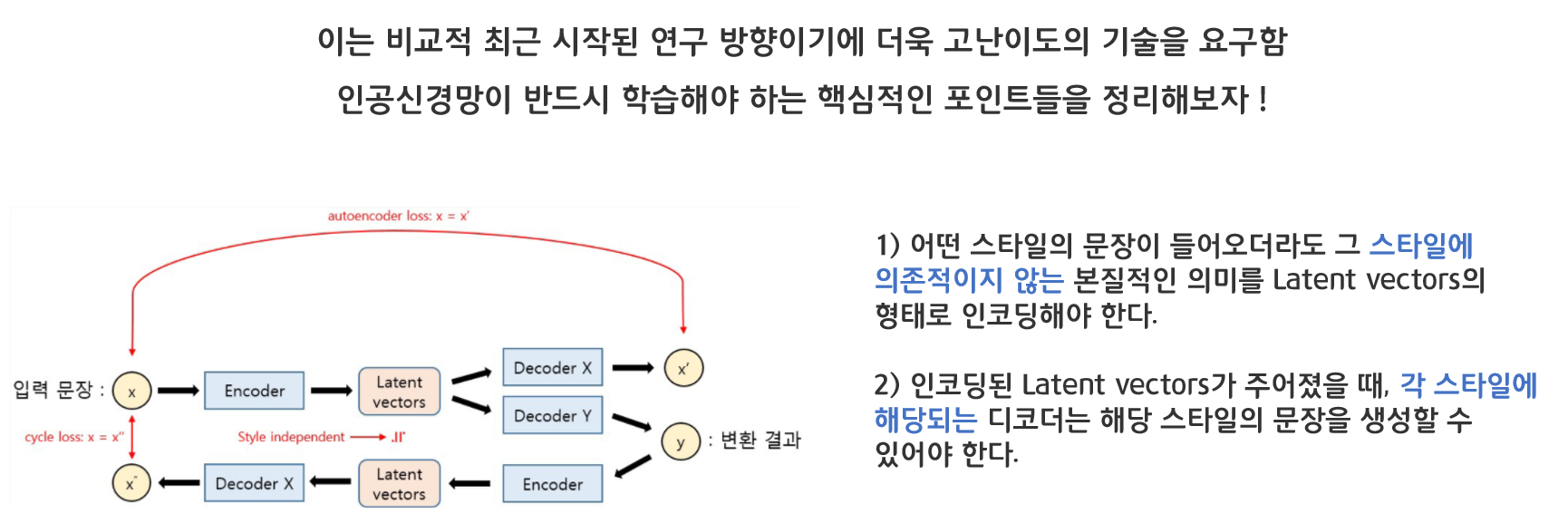
인공신경망이 반드시 학습해야 하는 핵심적인 포인트들을 정리해보겠습니다.
1) 어떤 스타일의 문장이 들어오더라도 그 스타일에 의존적이지 않는 본질적인 의미를 Latent vectors의 형태로 인코딩해야 한다.
2) 인코딩된 Latent vectors가 주어졌을 때, 각 스타일에 해당되는 디코더는 해당 스타일의 문장을 생성할 수 있어야 한다.
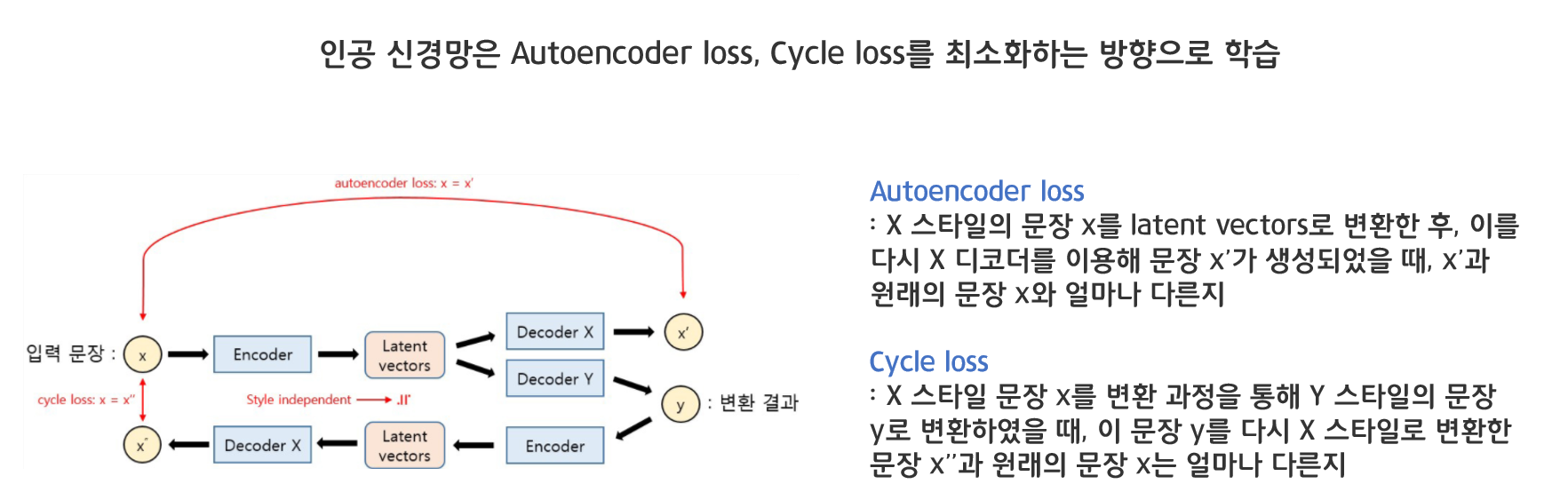
인공 신경망은 Autoencoder loss와 Cycle loss를 최소화하는 방향으로 학습합니다.
- Autoencoder loss
X 스타일의 문장 x를 latent vectors로 변환한 후, 이를 다시 X 디코더를 이용해 문장 x’가 생성되었을 때, x’과 원래의 문장 x와 얼마나 다른지 - Cycle loss
X 스타일 문장 x를 변환 과정을 통해 Y 스타일의 문장 y로 변환하였을 때, 이 문장 y를 다시 X 스타일로 변환한 문장 x’’과 원래의 문장 x는 얼마나 다른지

참고자료
