[CS224n] Lecture 3 - Word Window Classification, Neural Networks, and Matrix Calculus
CS224n Review

작성자 : 투빅스 14기 고경태
Contents
- Classification review/introduction
- Neural Networks introduction
- Neural Networks in NLP!
- Matrix calculus!
1. Classification review/introduction
Classification setup and notation

Classification을 하기위해선 보통 x input에 따른 labeling된 값 y를 하나의 표본으로 가진 데이터셋을 여러 개 학습을 시킵니다.
NLP에서는 INPUT인 XI는 단어나 문장, 문서들을 의미하며 목표값인 yi는 class일 수도 단어일수도 있지만 공통적으로 분류된 값들을 의미합니다.
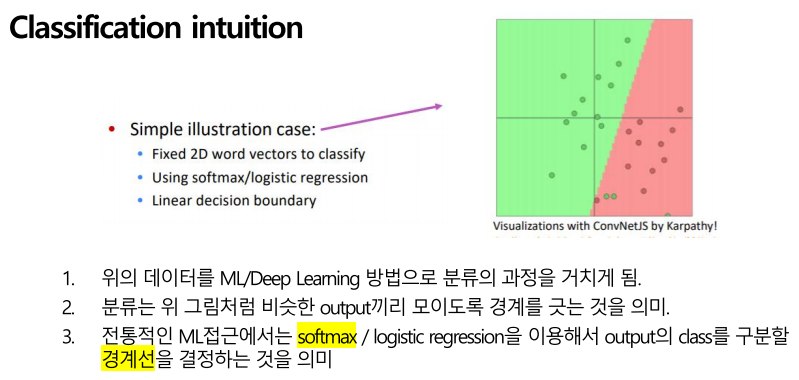
Classification에 대한 대략적인 설명을 드리면, 우리는 항상 어떤 데이터가 주어지면 이를 올바르게 분류하는 방법을 머신러닝이든지 딥러닝이든지 방법들로 찾게 됩니다.
분류는 위 그림처럼 같은 output끼리 모이도록 경계를 긋는 것을 의미하며 nlp에서 classification또한 고유명사끼리 또는 동사끼리 아니면 같은 의미의 단어끼리 모이도록 할 수가 있겠습니다.
Softmax logistic regression을 이용해서 output의 class를 구분할 경계선을 찾는 과정을 의미한다는 말 또한 같은 의미가 될 것입니다.

Softmax란, Xi가 들어오면 이를 pi 확률로 바꾸는 것을 의미합니다. 그리고 분류하고 싶은 클래스의 수만큼 확률값을 구성하며, 모든 클래스의 확률값을 더하면 1이 된다는 특징을 가지고 있습니다.
다음 그림을 보시면 두 가지 step으로 구성되어 있습니다. 첫 번째 식은, 모든 클래스 c에 대해서 선형결합으로 이루어진 fy를 만들고 두번째 식에서 각각의 클래스에 대해 이를 계산하고 0에서 1로 정규화 하면 됩니다.

Softmax활성화를 통해 구한 확률값에 log 씌우고 –부호를 붙이면 negative한 값이 되고, 이를 최소화하도록 학습을 진행하는 것입니다.

Softmax 뒤에 cross entropy loss를 붙여서 사용하므로 참고로 cross entropy loss/error에 대해서 알아보겠습니다. 강의에서는 cross_entropy loss를 사용하지 않고 설명하지만 우선을 알아보고 넘어가겠습니다. 우선 cross entropy는 정보이론으로부터 나온 개념입니다. 실제 확률 분포를 p라고 하고, 예측한 확률 분포를 q라고 하였을 때, cross entropy는 위와 같이 계산됩니다.
p = [0,...,0,1,0,...,0] 의 값을 가지고 q = [ 0.01,...,0.02, 0.8,0.01...,0]의 값을 가지면, 잘못 분류한 확률들은 0으로 사라지고 실제 클래스의 음의 로그 확률값만을 가지게 됩니다.
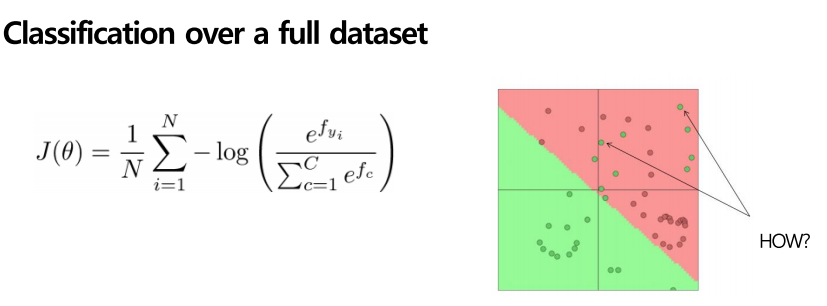
전체 데이터 셋으로 확장하면 아래의 공식과 같습니다. I = 1 부터 N까지의 평균으로 loss부분을 업데이트 해주었습니다.
하지만, 단순한 Softmax ( logistic regression ) 하나만으로는 좋은 성능을 낼 수 없습니다. 그 이유는 위의 그림처럼 class를 구분하는 경계선이 선형의 형태이기 때문입니다. 빨간색 동그라미를 구분 지어야 하는 면에 초록색이 bias처럼 섞여 있는 것을 알 수 있습니다.
이를 통해 단순한 선형 분류기가 아닌 새로운 방법이 필요했고 그 해결책이 바로 Neural Network가 됩니다.
2. Neural Networks introduction
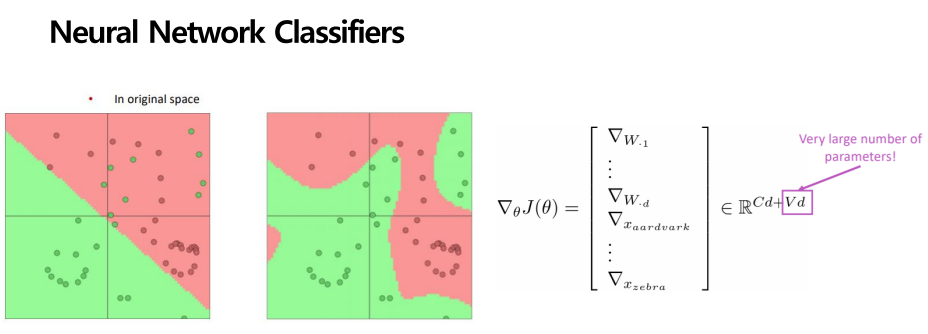
아까와 같은 단순 선형 분류기로 분류를 하였을 때 bias가 나타나는 문제점이 있었습니다.
이를 해결하기 위해서 비 선형적인 방법을 도입하는데 그게 바로 Neural Network입니다. NLP에서 딥러닝은 오른쪽 그림과 같이 가중치 W와 word vectors X에 대해 학습을 진행합니다.
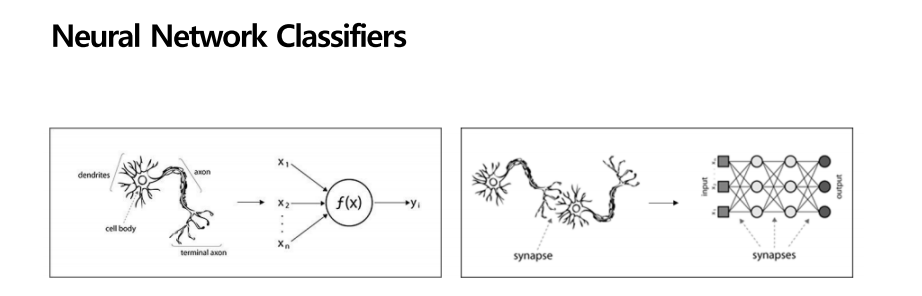
뉴럴 네크워크는 생물학의 신경망에서 영감을 얻은 통계학적 기계학습 알고리즘입니다. 원래 심리학에서 많이 연구되었고 오래전부터 연구되었습니다. 뉴럴 네트워크가 어떻게 발전하게 되었고, 어떤 방식으로 한계점을 극복하며 발전하게 되었는지 배웠던 내용이므로 빠르게 알아보겠습니다.
Neural Network history
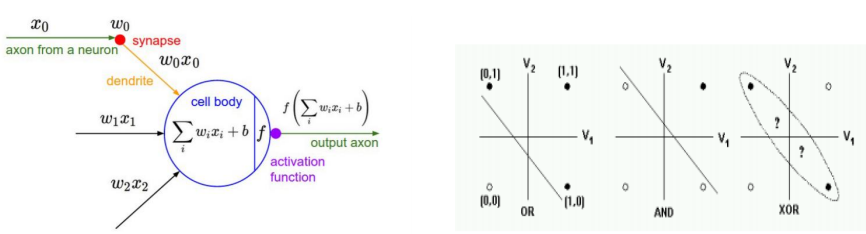
첫 번째는 퍼셉트론입니다. Input이 x1부터 xn까지 있고, 가중치를 곱한 후 바이어스를 더하여 선형 결합을 한 후 activation function 거쳐서 값을 뽑아냅니다. 주어진 정보에 따라 단층 신경망의 가중치를 갱신하는 규칙으로 만듭니다. 하지만, 선형 분류기인 퍼셉트론 한계가 나타납니다.
바로 선형으로 분류할 수 없는 문제들이 생겨난 것인데, 그중 가장 대표적인 문제가 xor문제를 해결할 수 없다는 문제입니다. XOR 문제는 둘 중 하나만 1일 때 1일 출력되는 형태인데요, 이는 다층 퍼셉트론과 오차 역전파 개념으로 해결되었습니다.
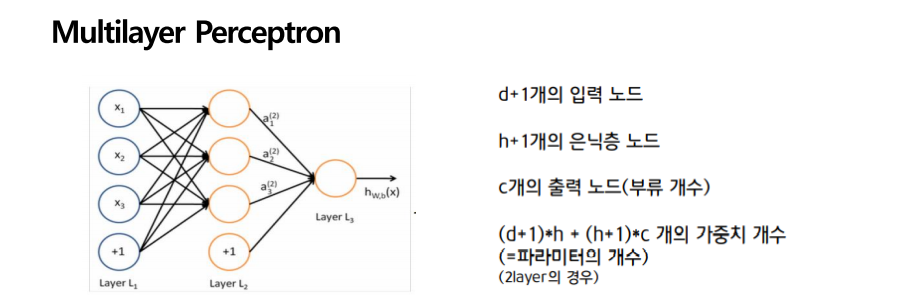
다층 퍼셉트론이 많이 얘기가 됐지만, WEIGTH를 어떻게 계산하는가가 문제였습니다. 이를 해결한 방법이 은닉층을 추가시켜 오류 역전파라는 방법을 통해서 WEIGHT를 계산을 쉽게 할 수 있는 방법을 고안해 냅니다.
다층 퍼셉트론은 히든 레이어가 추가되었다는 것입니다. 이 그림에서 input에서는 3개의 x 값이 있고 거기에 bias 항 역할을 하는 +1이 추가됩니다. 각각의 노드들이 input에서 weight를 받고 값을 갖게 되고 hidden layer에 있는 노드들을 가지고 다시 계산을 해서 output이 나오게 됩니다. X input에 d 개의 노드가 있으면 d+1개의 입력 노드가 되고 은닉충도 h+1 c 개의 출력 노드가 나오게 됩니다. 이를 모두 곱하면 가중치의 개수 즉 파라미터의 개수가 나오게 됩니다.
각각의 파라미터들의 값들을 모두 업데이트해주는 것이 이 다층 퍼셉트론의 핵심입니다.
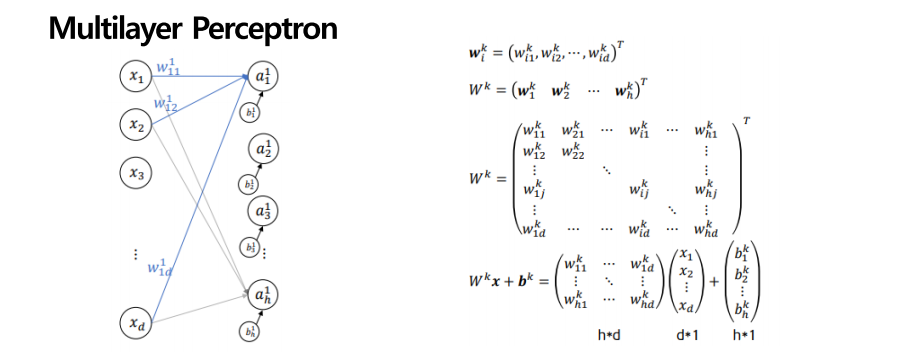
Multilayer Perceptron을 행렬로 표현하면 다음과 같습니다. 첫 번째 wi는 행벡터가 전치되어 열벡터로 나타나 있는 것을 알 수 있습니다. 그 열벡터들의 모임을 다시 전치시킨 것이 바로 Wk입니다. 이를 x 벡터와 곱하고 bias를 더해주면 맨 아래와 같이 한 줄의 식으로 나타낼 수 있습니다. 이 그림이 중요한데 후에 window classifier에서 내용을 설명할 때 이 그림과 연관되므로 그때 nlp와 연관 지어 다시 설명을 드리겠습니다.

하지만 이 또한 문제가 있었는데, 다층 퍼셉트론을 이제 업데이트하는 방법을 고안해냈지만, 기울기 소실 문제가 발생합니다. 층이 깊어질수록 기울기 소실 문제가 발생하며, 과적합 문제도 발생합니다.
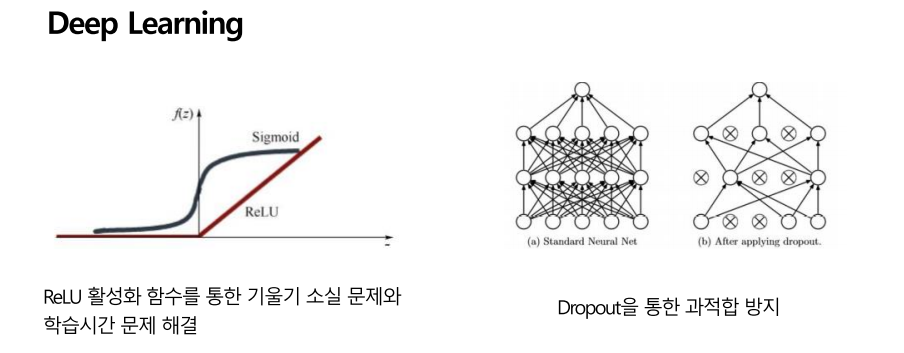
레이어가 많아질수록 기울기가 소실 문제가 발생합니다. 하지만 relu 함수를 사용하면 이를 해결할 수 있어서, 아주 깊은 신경망을 사용하더라도 gradient vanishing 문제를 해결하였습니다. 또한 dropout기능을 통해 과적합을 방지하여 깊은 신경망인 딥러닝으로 발전할 수 있었습니다.
이제 다시 뉴럴넷에 대한 설명으로 넘어와서, 자연어 처리에 대한 뉴럴 넷에 대한 설명으로 넘어오겠습니다.
3.Neural Networks in NLP

강의에서 Neural network을 이용한 NLP 방법으로는 3가지 단계로 나누어서 설명하였습니다. 먼저 NER 즉 개체명 인식이라는 방법론입니다. 인명, 지명 등 고유명사를 분류하는 방법론입니다. Named Entity Recognition 을 위하여 Conditional Random Field (CRF) 나 Recurrent Neural Network (RNN) 과 같은 연속적인 모델이 이용될 수 있습니다. 하지만 본 강의에서는 winddow classification 강의를 진행하였고, softmax를 이용하여 window classification을 하는 알고리즘을 설멍하였습니다. 저도 이에 맞추어 설명을 드리겠습니다.
우선 NER이 자연어 처리에서 어떤 목적으로 필요한지를 알아야 합니다. NER은 아까 설명드렸다시피 문장에서 인명, 지명 등 고유명사를 파악하기 위해 사용됩니다. 문장 내에서 고유명사를 파악하는 것이 중요한 이유는, 문맥들이 모두 고유명사를 기준으로 동사와 기타 단어들이 관계를 맺는 구조이기 때문입니다. 예를 들어 어떤 하나의 글이 있고 문맥에 따라 글이 전개될 때, 한 사람의 이름이 나오면 그의 성격, 그의 묘사들이 일정하게 진행되고 사건 또한 그 인물을 중심으로 전개되게 됩니다.
따라서 자연어처리에 있어 그 문맥을 파악하고 글을 해석하는 데 있어 고유명사 즉 인명을 파악하는 것이 중요하게 됩니다.

분류기를 실행하고 클래스를 할당하는 모습을 볼 수 있습니다. 첫 번째 단어가 조직 두 번째 단어도 조직 세 번째는 고유명사가 아니며, 네 번째 단어는 사람으로 다섯 번째 단어는 사람으로 계속 아래로 내려가서 단어 분류를 실행합니다. 주위에 단어가 표시되도록 텍스트에 위치를 지정하여 분류합니다.

하지만 NER은 한계가 있는 기술입니다. 그 이유는,
첫 번째, Entity(개체)의 경계를 정하기 어렵습니다. 왼쪽 문장에서 첫 번째 고유명사를 First National Bank로 or National Bank로 잡을지부터 이슈가 생깁니다.
두 번째, 개체인지 아닌지 알기가 어렵습니다. 위에서 Future School이 의미하는 게 school을 "Future School" 이라고 부르는지 혹은 미래의 학교라는 의미인지 알 수 없습니다.
세 번째, 개체 분류가 모호하며 문맥에 의존합니다. 오른쪽 문장에서 charles로 시작하는 저 단어가 사람인지 조직인지 문맥에 따라 다르며 절대적인 기준은 존재하지 않습니다.

우리가 해결해야 하는 것은 문맥상 사람이 될 수도 있고, 조직이 될 수도 있는, 그 분류가 애매모호한 단어들이며 이를 해결하기 위해서는 문맥을 고려해야 합니다.
그래서 문맥까지 고려하는 window classification 방법론이 나오게 됩니다. Window classification은 문맥상에서 애매모호하게 일어나는 것들에 대한 분류를 도와주는 방법론입니다. 예를 들어, 반의어 관계에 있는 다음과 같은 단어들이 있습니다. 제재하다 라는 단어가 무언가를 허락하는 경계선을 주는 건지 아니면 벌을 주는 건지 문맥에 맞게 둘 중 하나를 선택해야 하는 문제들이 생기며 이를 window classification이 도와줄 수 있습니다.

window classification의 기본적인 생각은 중심 단어와 주변 단어들 (context)를 함께 분류 문제에 활용하는 방법입니다.
예를 들어, 다음과 같은 문장에서 중심 단어인 파리가 이름인지 지명인지 분류해내기 위해서 파리 주변의 주변 단어를 사용하는 것입니다. 파리를 window 길이를 2로 분류하기 위해서, 먼저 주변 단어와 중심 단어를 합쳐 벡터로 만들어야 합니다. 파리의 +-2 총 다섯 개의 word vectors을 합쳐서(concatenation) 5d 크기의 vector를 형성합니다. 그리고 이 vector를 활용해 classifer를 제작합니다.
문장을 보면 앞에 전치사가 있는 것을 보니 여기서 파리는 지명일 확률이 높아 보입니다.
이를 가능하게 하는 가장 간단한 방법으로는 contex t내 단어를 분류하기 위해 window안의 word vectors를 평균 내고, 이 평균 vector를 분류하는 방법이 있습니다. (하지만 이럴 경우, 단순 평균이며 많은 word vector 중에 어떤 word vector를 분류하려 했는지 잊어버리기 때문에 위치정보를 잃어버리는 단점이 있습니다.)

이를 해결하기 위해 방법이 아까 설명드렸던 다층퍼 셉트론과 Softmax함수를 사용하는 방법입니다.
아까 다층 퍼셉트론을 설명할 때 사용했던 그림을 가져와보면 x window 벡터를 저렇게 5개의 행으로 만들어 이를 전치시키면 5*1의 열벡터가 나옵니다. 저 열벡터가 오른쪽 그림 네모에 해당되는 부분 즉 input이라고 생각하면 쉬울 것 같습니다. 그리고 가중치를 곱한 후 bias를 더해 값을 뽑고 거기에 softmax 활성화 함수를 입히면 우리가 찾고 싶은 output 확률이 나올 것입니다.

다시 말해서, x 대신에 x window 를 input으로 줬다고 생각하면 쉽게 이해할 수 있을 것 같습니다. word2vec에서는 corpus내 모든 위치에 대해서 학습을 진행하였지만, 이번에는 높은 score를 가지는 위치에 대해서만 집중적으로 학습을 진행한다고 생각하시면 쉬울 것 같습니다.
그 후 과정은 뉴럴넷 기본에서 배웠던 방식으로 똑같이 계산해 주면 output 확률 값과 cross entropy error을 이용하여 loss 부분을 업데이트하는 과정까지 이해할 수 있을 것 같습니다.
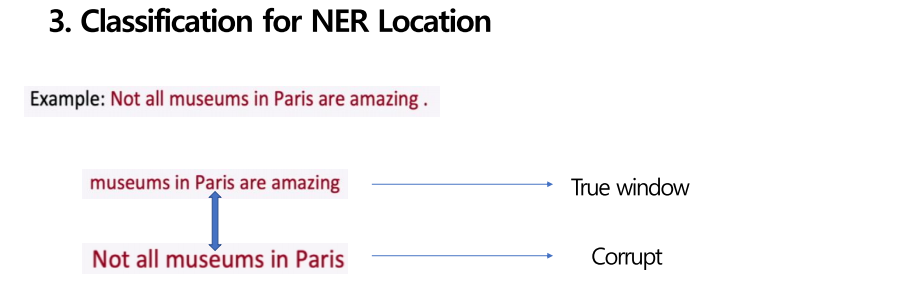
좀 더 구체적으로 살펴보겠습니다. 'Not all museums in Paris'는 location entity를 중앙에 가지고 있지 않고, 그에 반해 'museums in Paris are amazing' location entity를 중앙에 가지고 있습니다. 이때 장소 고유명사인 Paris가 중앙에 오는 window는 true window로 표현하고, 그 이외의 다른 window는 부정으로 표현합니다.

지금까지 내용을 토대로, 이제 이 과정을 3개의 층을 가진 multilayer perceptron으로 이해하면 쉬울 것입니다. 먼저 가장 아래 20x1벡터를 가진 x가 input이 되며 8x20을 가진 가중치 w를 곱하고 bias를 더하여 활성화 함수(소프트맥스)를 거치면 8x1벡터가 나옵니다. 이제 이 벡터에 u를 곱하면 전치가 되니까 1x8 과 8x1 내적 하면 1x1 스칼라 값이 나오게 되고 score 값을 뽑게 됩니다.

Neural networ의 손실 함수는 일반적으로 softmax를 사용할 경우 값을 확률 비율로 변경했기 때문에 비율 간의 차이를 계산하는 cross-entropy 를 사용하는 것이 일반적입니다. 하지만 위에서 score 함수를 우리가 직접 정의했으므로 여기에서는 이에 걸맞은 max-margin loss를 사용합니다. 강의에서는 설명하지 않고 넘어가셨지만 이해를 돕기 위해 설명을 진행하고 넘어가겠습니다.
Max margin loss는 우리가 예전에 배웠던 svm에서 많이 사용되는 개념입니다. 여기서 margin 이란 개념은 이진 분류에서 그 결정 경계와 서포트 벡터 즉 결정 경계와 가장 가까이에 있는 데이터 포인트 사이의 거리를 의미한다고 배웠었습니다. 그림으로 다시 확인해보면,
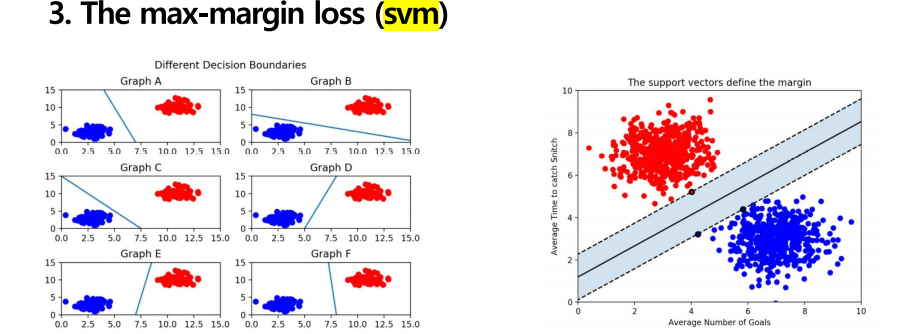
다음 여섯 가지 그래프에서 어떤 결정 경계가 가장 적절해 보이는지는 당연히 F라고 말할 수 있습니다. 결정 경계를 기준으로 파란색 점들과 빨간색 점들이 가장 멀리 떨어져 있기 때문입니다. 오른쪽 그림을 보시면, 가운데 실선이 하나 그어져있는데, 이게 바로 ‘결정 경계’가 됩니다. 그리고 그 실선으로부터 검은 테두리가 있는 빨간 점 1개, 파란 점 2개까지 영역을 두고 점선을 그어놓았습니다 점선으로부터 결정 경계까지의 거리가 바로 ‘마진(margin)’이며 이 마진을 최대화하는 것이 svm의 목적입니다.

여기서도 똑같이 적용된다고 보시면 됩니다. 보시면 s가 정답, s(c)가 부정입니다. 그 차이를 최대화하는 margin을 찾는 것이 바로 svm에서 사용된 개념과 같습니다. 주어진 input x에 대하여 정답 class와 오답 class간의 차이를 max로 만들어 주는 손실 함수입니다.

우리는 앞서 작성한 max-margin 손실 함수를 통해 손실 값을 구했습니다. 이제 이 손실값 에 각 파라미터 W, U, b, X가 손실 값에 얼마나 많은 기여를 했는지 알아보고 해당 기여도에 따라 각 parameter 값을 조정해는 것이 그다음 단계일 것입니다.
4. Matrix calculus

왼쪽 상단은 하나의 함수를 미분 한 것인데, x1부터 x(n)까지 n 개의 input을 짚어 넣으면 한 개의 outpu을 줍니다. 이를 미분하면 아래 그림과 같이 n 개의 각각의 input으로 미분을 하여 하나의 벡터로 만들어 주게 됩니다.
이를 응용해보면, matrix에서도 미분이 쉽고 빠르게 진행됩니다. F(x)가 왼쪽 상단과 오른쪽 상단을 비교해보면 input은 n으로 같지만, outpu이 m으로 드러났습니다. 그렇다면 당연히 미분을 한 matrixs도 이렇게 한 행은 왼쪽과 같겠지만, m으로 outpu이 늘어났기 때문에 행으로 이렇게 f1부터 fm까지 쌓이게 되겠죠? 이게 바로 matrix에서 미분을 한 값입니다.

Chain Rule 도 다시 살펴보면, 왼쪽 그림은 우리가 자주 봤었던 한 변수에 대한 chain rule입니다. 이를 오른쪽 그림에서 복수의 변수에 대한 식에서도 chain rule이 적용됨을 알 수 있습니다. H 식을 x에 대해 미분하면 우선 매개변수인 z로 미분을 하고 z 식을 다시 x로 미분하면 되겠습니다.
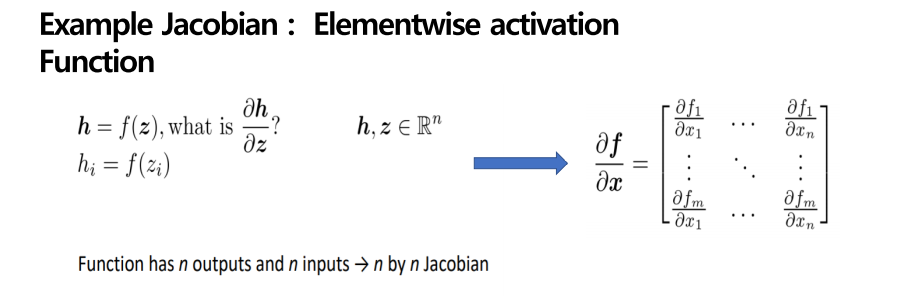
지금까지의 개념들로, 이제 아까 봤었던, 역전파를 이용하여 손실 함수를 최소화하는 방법을 설명드리려 합니다. H는 z를 input으로 집어넣어 활성화함수를 적용해 나온 식입니다. 이를 z로 미분한다면 우리가 아까 봤던 매트릭스와 비슷한 형태로 nxn의 매트릭스 형태로 나오게 됩니다. 아까 봤었던 매트릭스에서의 미분과 비교해보면 이해가 쉬울 것 같습니다.

이제 미분한 식을 알아보면 hi는 f(zi)로 나타낼 수 있고, zi 와 zj가 I = j 가 같을 때 즉, 변수가 같을 때 미분했을 때 값이 나오게 되고, 다른 경우는 0으로 값이 나오게 됩니다. 이를 행렬로 표현하면 다음 그림과 같이 대각 행렬이 나오게 됩니다. 이 계산은 우리가 window classification에서 손실 함수를 최소화하기 위한 미분 과정에 부분으로 들어가게 됩니다. 지금 나온 값을 후의 계산 과정에 대입해보겠습니다.

첫 번째는 wx + b를 x로 미분한 값 가중치가 나옵니다. 두 번째는 b로 미분한 값 항등행렬이 나옵니다. 세 번째는 u로 미분한 값 h를 전치한 값이 나옵니다. 이 세 가지 식과 전에서 봤던 식 모두 우리가 아까 보았던 window classification의 손실 함수를 최소화하기 위해 미분하는 과정에서 사용되는 식들입니다.
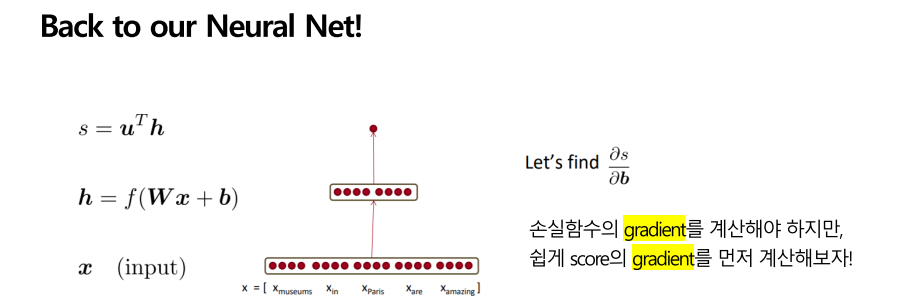
이제 다시 우리의 뉴럴넷으로 돌아와서 손실함수의 gradient를 계산하려 합니다. 원래는 우리의 손실 함수였던 max-margin loss를 계산해야 하지만, 이해를 쉽게 돕기 위해 원래 강의에서도 우리가 구했던 scor e함수의 gradient를 계산하였습니다.
이 score 함수의 gradient를 계산하는 설명을 진행해보겠습니다. 지금까지의 chain rule과 우리가 계산했던 4가지 식들을 단순하게 조합하면 끝이 납니다.

Chain rule을 수행하기 전에 우선 h 식에서 wx+b를 z로 치환하여 매개변수를 하나 만듭니다.
s를 b로 미분하기 위해서는 h에 해당하는 식을 매개변수를 이용하여 미분해주어야 하기 때문에 wx+b = z로 치환하게 됩니다. 그리고 s를 최종적으로 h,z, 그리고 b 세 개의 변수로 미분을 하게 됩니다.
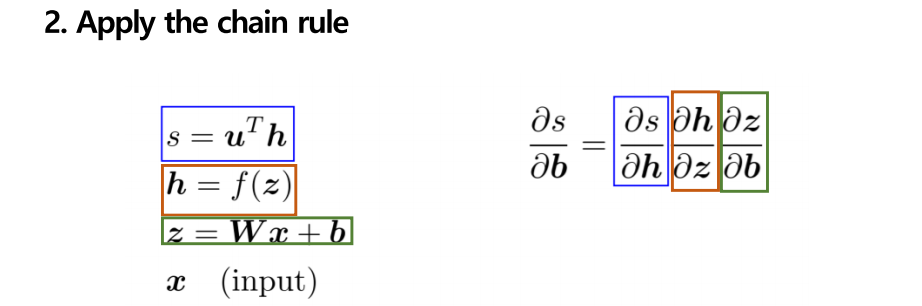
미분 과정을 한꺼번에 살펴보면 우선 첫 번째 s를 h로 미분합니다. 두 번째, h를 z로 미분합니다. 세 번째 z를 b로 미분합니다 이 미분 값들을 모두 곱하면 최종적으로 s를 b로 미분한 값이 나오게 됩니다.

자 이제 지금까지 미분한 계산 과정을 대입하면 계산이 끝이 납니다. S를 h로 미분한 값은 u transpose 한 값이므로 대입해 주고,
H 즉 f(z)를 z로 미분한 값은 아까 우리가 했었던 대각행렬이 나오므로 이를 집어넣어 주고, Z 즉 wx+b를 b로 미분한 값은 항등 행렬이므로 이를 집어넣어 주면 최종적으로 다음과 같은 식이 나오게 됩니다.

지금까지는 bias로 미분하여 업데이트를 시켰지만 아까 말했듯 모든 파라미터에 대해서 역전파를 수행하여 파라미터 값들을 업데이트해야 합니다. W에 대해서도 미분을 해줘야겠죠. S를 w로 미분하면 체인룰로 다음과 같이 식을 뽑아낼 수 있을 것입니다

우리가 bias로 미분했던 식과 비교해보면 오른쪽 끝에 z를 w로 미분하거나 b로 미분하거나 둘의 차이만 있지, 그 앞 과정인 s를 h로 미분한 식과 h를 z로 미분한 식은 값이 같은 것을 볼 수 있습니다. 이렇듯 오차 역전파는 계산했던 지난 과정들이 다시 사용됨으로써 다시 계산하여 계산량을 늘리는 문제를 막을 수가 있는 것이 장점입니다.
저 파란색에 해당하는 부분은 델타라고 합니다. 델타는 오류 신호 입니다. 편도함수를 계산하는 매개변수라고 생각하면 쉬울 것 같고, 아까 말했듯 이 델타 값은 한 번만 계산하여 효율성을 늘려야 합니다.
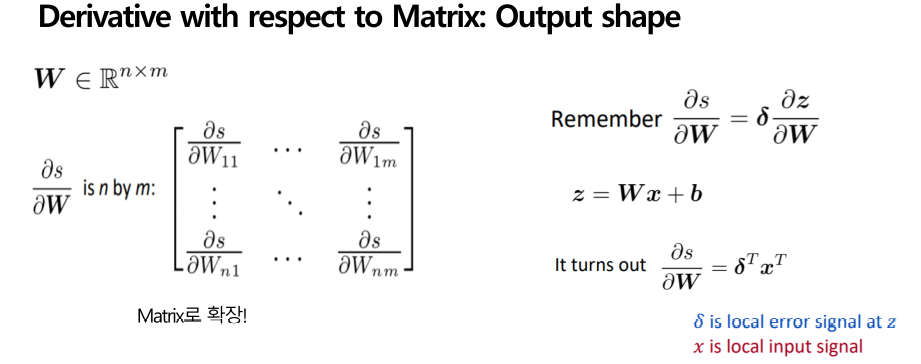
지금까지 했던 계산들을 matrix로 확장하는 것은 어렵지 않을 것입니다. S를 w matrix로 미분을 하게 되면 우리가 앞에서 계속 봐왔던 matrix로 값이 도출되게 됩니다.
아까 계산했던 s를 w로 미분하면 델타 곱하기 z를 w로 미분한 식이 다음과 같고 w로 미분한 과정까지 생각을 하게 되면 결국 델타 곱하기 x로 결괏값이 도출됩니다. 전치는 행렬의 모양을 왼쪽 그림과 같이 matrix로 만들기 위해 수행한 과정이라고 저는 이해를 했습니다. 다음에서 구체적으로 설명드리겠습니다.

델타를 열벡터로 만들고 x를 행벡터로 만들어 계산을 하게 되면, nx1 1xm으로 계산이 되므로 외적이 되게 됩니다. 그래서 nxm matrix로 나오게 되며 가중치를 업데이트할 수 있는 행렬이 되게 됩니다. 이렇게 Neural net이 NLP에서 어떻게 이용되는지 그리고 역전파를 들어가기 전, 기본적인 계산에 대한 내용을 끝으로 3강을 마치겠습니다. 감사합니다.
참고자료
