
작성자: 숭실대학교 산업정보시스템공학과 이수민
Linguistics (언어학)
Human language sounds: phonetics and phonology
Phonetics 음성학
사람의 말소리를 연구하는 학문
Phonology 음운론
- 언어학의 첫 번째 단계
- 사람은 입으로 무한의 소리를 만들어낼 수 있지만, 언어로 표현될 때는 이 연속적인 소리가 범주형으로 나눠져서 인식됨.
- ex) caught and cot
※ 범주적 지각 (Categorical perception)
사전적 의미는 연속체를 따라 변수에 점진적인 변화가 있을 경우의 구별 범주에 대한 지각 현상
광범위한 음향 신호를 제한된 수의 소리 범주로 지각되는 결과를 낳을 때, 즉 우리에게 실제로 들리는 말소리는 소리 주파의 연속적인 변화인데도 우리가 이를 '말소리 범주'로 지각하는 것을 말합니다.
- 범주 내의 차이 (differences within the categories) 축소
- 범주 간의 차이 (differences across the categories) 확대
Morphology
Morphology 형태론
- 최소한의 의미를 가지는 구조
voice started time
의미를 갖지 않고 소리만 나는 "pah"나 "bah", 또는 "a"와 "e" 보다는, 다음 level인 형태소(morpheme)가 의미를 갖는 최소 단위라고 여겨집니다. 그래서 많은 단어들이 복잡한 조각들(parts of words)로 구성되지만 하나하나 의미를 가지고 있게 되는 것입니다.
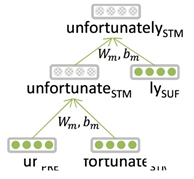
Unfortunately라는 단어를 쪼개서 살펴보면
- "fortune" : 운이 좋은
- "un" : 부정/반대의 의미
- "ly" : 부사 형태
이렇게 단어 조각들과 작은 단위들이 모두 의미를 갖게 되는 것.
하지만 이런 형태소 단위의 단어들을 딥러닝에 사용하는 경우는 거의 없습니다. 단어를 또 의미 있는 단어(형태소)들로 쪼개는 과정 자체가 어렵고, 굳이 이 방법을 사용하지 않고 character n-grams를 사용하더라도 중요한 의미 요소들을 충분히 잘 잡아낼 수 있고, 결과적으로 좋은 결과를 낼 수 있기 때문.
[논문] On learning the past tenses of English verbs
- 영어의 과거형(past tense) 형태를 생성해내는 모델
- "영어 동사의 과거 형태를 학습할 수 있는 시스템을 만들 수 있을까?"에 대한 일종의 인지심리학(psy-cog) 실험
- "-ed"로 끝나는 규칙적인 동사들도 있지만 그만큼 많은 불규칙적인 동사들의 패턴을 학습해야 한다는 것이 어려운 부분
- 당시(sequence model 초기)에는 단어를 정확하게 표현하기 위해서 character trigrams로 표현
- 공학적인 문제 해결 방법으로서는 좋은 평가를 받았지만 언어학자들과 철학자들을 비롯한 많은 사람들 사이에서는 논쟁거리
Words in writing systems
Writing system
사람의 언어 표기 체계 (writing system) 는 나라마다 다르고, 하나로 통일되어 있지 않다.
1) No word segmentation: 단어에 대한 segmentation, 즉 띄어쓰기 없이 붙여 쓰는 경우가 있다는 것
중국어: 美国关岛国际机场及其办公室均接获
프랑스어: Je vous ai apporté des bonbons
아랍어: فقالناھا
2) Compound Nouns
-
영어
합성어를 사용할 때 각 명사 사이에 공백을 두기 때문에 white board, high school같이, 띄어쓰기가 되어 있음에도 불구하고 하나의 명사로 인식됩니다. -
독일어
합성어가 띄어쓰기 없이 한 단어로 표현되기 때문에 만약 여기서 띄어쓰기를 하게 되면 다른 단어로 인식됩니다.
ex) Lebensversicherungsgesellschaftsangestellter = life insurance company employee
Word-Level Models(단어 기반 모델)
word-level models를 만들게 되면 커버해야할 단어가 너무 많기 때문에 무한한 단어 공간이 필요하고 비효율적입니다.
- Rich morphology
(체코어) nejneobhospodařovávatelnějšímu = (영어) to the worst farmable one”) - Transliteration (음역)
Christopher -> Kryštof - Informal spelling: 신조어/축약어
Character-Level Models (문자 기반 모델)
character-level model (문자 기반 모델)은 단어가 가지고 있는 의미 정보를 포기하는 대신 두 가지 이점을 제공합니다.
1) 단어 임베딩은 문자 임베딩으로부터 구성할 수 있다. 즉, 어떤 문자 시퀀스에 대해서도 단어 표현 생성이 가능해집니다.
- OOV 문제 해결
OOV problem: NLP에서 빈번히 발생하는 데이터 문제로 input language가 database 혹은 input of embedding에 없어서 처리를 못 하는 문제
2) sequence of characters 기반으로만 언어를 처리하기 때문에 합성어와 같은 connected language에 대해서도 분석이 가능합니다.
Purely Character-Level NMT Models
Machine Translation
초기에 character 기반으로 구축한 기계번역 시스템은, word 기반 모델 뿐만 아니라 neural network 등장 이전보다도 못한 성능을 보였지만, 발전된 연구가 이루어지기 시작하면서 점차 성공적인 문자 기반 디코더를 만들 수 있게 되었습니다.
English-Czech WMT 2015 Stanford NLP group
- 영어를 체코어로 번역하는 연구에서 우수한 결과 도출
- 실제로 영어를 체코어로 번역하는 연구가 진행되었지만, 제대로 된 훈련에 어려움을 겪으며 학습 시간이 3주가 소요되었습니다. 결과적으로 unknown words 번역에 효과적이었지만 성능이 word-level model에 비해 크게 향상되지 않았습니다 (word-level model BLEU 15.7 -> character-level model BLEU 15.9).
이후 연구 (2017)
Fully Character-Level Neural Machine Translation without Explicit Segmentation
논문
앞선 모델보다 더 나은 성능을 보이는 character-level model이 등장했습니다. 이 모델에서는 character 단위의 input을 받아 convolution layer를 거쳐 max pooling과 single layer GRU를 거치는 구조를 가집니다. 구조 자체는 더 복잡하지만, 앞선 모델보다 나은 성능을 보였습니다.

Encoder: 단어에서 시작하는 게 아닌 문장 전체에서 바로 character-level 임베딩을 진행하는 방식으로, 필터 사이즈를 다르게 해서 convolution 연산을 진행하게 됩니다. Max pooling을 stride 5로 주고 진행하게 되고, 각각의 컨볼루션에 대해서 max-pulled representation을 얻게 됩니다. 해당하는 각각의 임베딩에 대해서 highway network를 통과하고, bidirectional GRU를 통해 source representation을 얻을 수 있게 됩니다.
Decoder: 일반적인 character level sequence model

결과적으로 앞선 모델보다 BLEU score가 더 높은 것을 확인할 수 있습니다.
highway network
깊이가 증가할수록 최적화가 어려워지기 때문에 모델을 깊게 만들면서도 정보의 흐름을 통제하고 학습 가능성을 극대화할 수 있도록 해주는 역할
이후 연구 (2018)
Stronger character results with depth in LSTM seq2seq model
논문
Bi-LSTM Sequence-to-sequence 모델을 적용한 결과
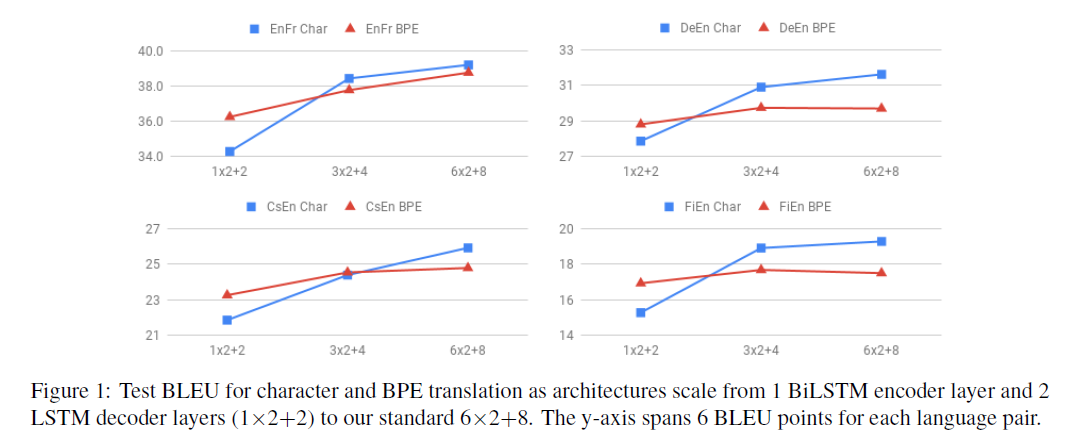
- 영어 → 프랑스어 번역: layer를 깊에 쌓을수록 word-level 모델의 성능을 character-level model이 능가
- 체코어 → 영어 번역: 마찬가지로 가장 깊게 layer를 쌓은 경우에는 character-level model이 BPE의 성능을 능가. character-level model을 깊게 쌓을수록 성능이 급격하게 증가.
- 언어의 특성에 따라 모델 type 별 성능과 효과가 다르다는 것을 알 수 있습니다.

관련 연구가 계속해서 발전해왔지만, 2015년부터 겪었던 문제점은 여전히 남아있습니다. Word-level model은 속도가 빠르기 때문에 짧은 시간 내에 번역 태스크를 해낼 수 있는 반면, characeter-level model은 word pieces를 이용하기 때문에 연산량이 word-level model보다 시간과 비용이 훨씬 많이 들게 됩니다.
Subword Models
두 가지 방법
- Same architecture as for word-level model: word-level model과 동일한 구조, 하지만 word가 아닌 word-pieces
- Hybrid architectures: main model은 word로 나타나지만 unknown word를 다른 표현 방법으로 나타내는 방법 (characters는 다르게 표현됨)
Byte Pair Encoding (BPE)
딥러닝과는 거리가 먼 간단한 아이디어임에도 성공적인 방법론
compression algorithm
- Data compression 관련 연구 선행 [논문] A New Algorithm for Data Compression:
- looking for the most frequent sequence of two bytes
해당 아이디어를 기반으로 BPE 알고리즘 등장
[논문] Neural Machine Translation of Rare Words with Subword Units
- bytes가 아닌 character ngrams를 사용. 즉, 가장 빈번하게 발생되는 pair를 byte가 아닌 character 단위로
- 데이터에 대해서 다 적용할 수 있고, multi-lingual
작동 방식
- A word segmentation algorithm: 짧은 시퀀스의 bottom-up clustering
- unigram 어휘에서 시작
"what's the most frequent ngram? " -> bigram pair -> add it to our "Vocabulary" (a new ngram)




결과적으로 이 vocabulary 안에는 모든 single letter들과, 'ES'와 'EST'같은 문자 시퀀스, 그리고 'THAT','TO'와 'WITH'와 같은 평범한 단어들도 우리의 vocabulary에 들어오게 됩니다.
Wordpiece/Sentencepiece model
Google's neural machine translation (GNMT)
- BPE의 variants: wordpiece model과 sentencepiece model
- 앞선 알고리즘은 frequency를 순수하게 등장 횟수로 따졌다면, 여기서는 clumping (군집화)를 통해 perpelexity 감소
1) wordpiece model
pre-segmentation을 통해서 단어의 출현 빈도수를 기반으로 단어를 추가해준 뒤 BPE를 적용하는 기법. Transformer, ELMo, BERT, GPT-2가 모두 word piece model에 해당됩니다.
BERT
- WordPiece Tokenizer 사용
- 자주 등장하는 단어는 그대로 단어 집합에 추가
- unknown word 등장 시 다음과 같이 word pieces로 분할
BERT에서는 non-initial word pieces가 ##로 표현되면서 hypatia = h ##yp #ati #a 로 분리해서 hypatia라는 단어를 표현합니다.
2) sentencepiece model
Google (2018)
[논문] Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates
github 코드
단어로 구분이 어려운 언어가 있기 때문에 (ex. 중국어), 이 모델의 경우에는 raw text에서 바로 character-level로 나눠집니다. 공백에 대해서 token을 따로 지정해줘서 (_) BPE와 유사한 방식을 수행하게 됩니다. 다만 완전히 같은 방식으로 진행되지는 않고 BPE 방식이 변형되어 진행됩니다.
- BPE: frequency 기반으로 가장 빈번하게 등장하는 것 추가
- sentence piece model: bigram 각각에 대해서 co-occurence 확률을 계산 후 가장 높은 값을 가지는 것 추가
Hybrid Models
Character-level Representations
[논문] Learning Character-level Representations for Part-of-Speech Tagging
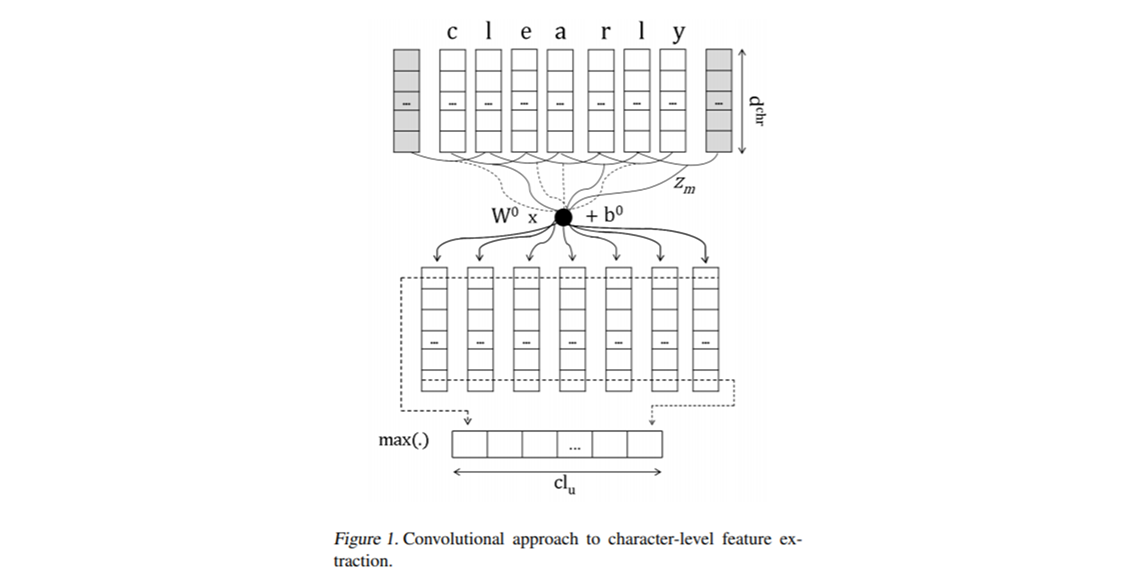
Character-based LSTM
Bi-LSTM builds word representations
Purely character-level NMT models
2015년도에 순수하게 character 단위로 NMT task를 진행한 모델을 살펴보겠습니다. 논문
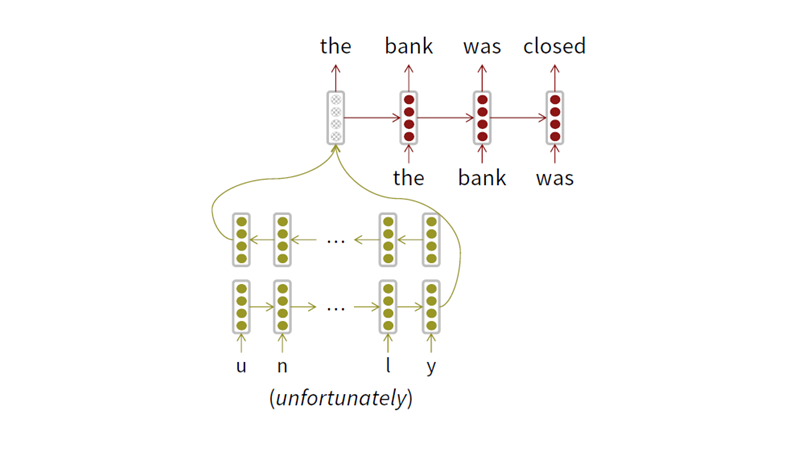
- Bi-LSTM을 통해 word embedding
- final state를 concat해서 임베딩된 단어의 벡터로 사용
- 임베딩된 단어 벡터들을 그 윗 단계의 LSTM에 최종적인 task를 진행하게 되고,
- language model과 pos tagging을 사용
Character-Aware Neural Language Models [논문]
Can we build a good language model by starting out from characters?
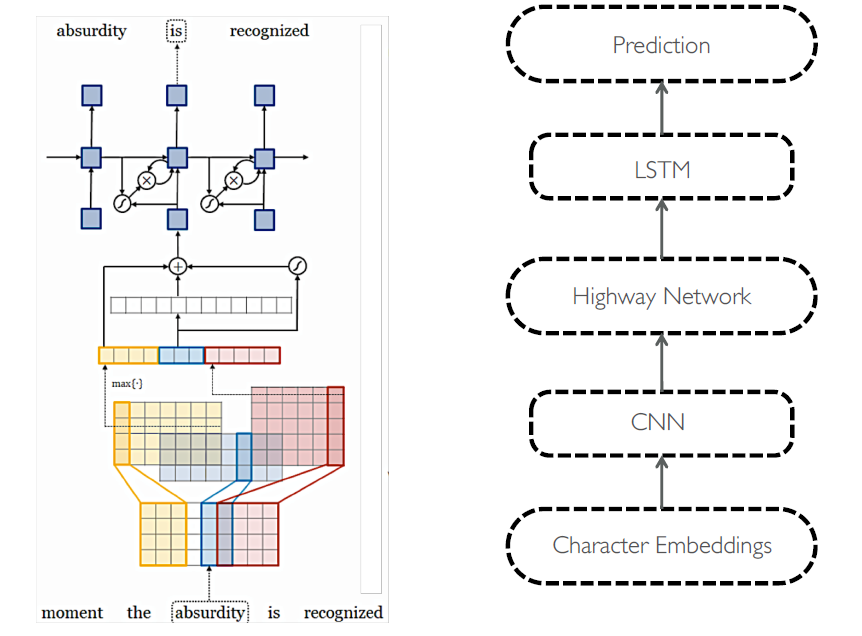
가장 먼저 input 단어에 대해서 character embedding을 진행합니다. 이후 filter size 여러 개를 사용해서 convolution을 진행하고 각각에 대해 max pooling을 진행해서 feature를 뽑습니다. 즉, 어떤 ngram들이 단어의 뜻을 가장 잘 나타내는지 고르는 과정이며, 이 과정이 끝나면 output representation을 얻게 됩니다. Output representation은 highway network를 거치게 되고, 최종적으로 임베딩 벡터 값이 나오면 word-level LSTM network를 통해 예측 task를 수행하게 됩니다. 결과적으로 앞서 살펴본 모델들보다도 perplexity를 최소화하면서 비슷한 성능을 낼 수 있게 됩니다.
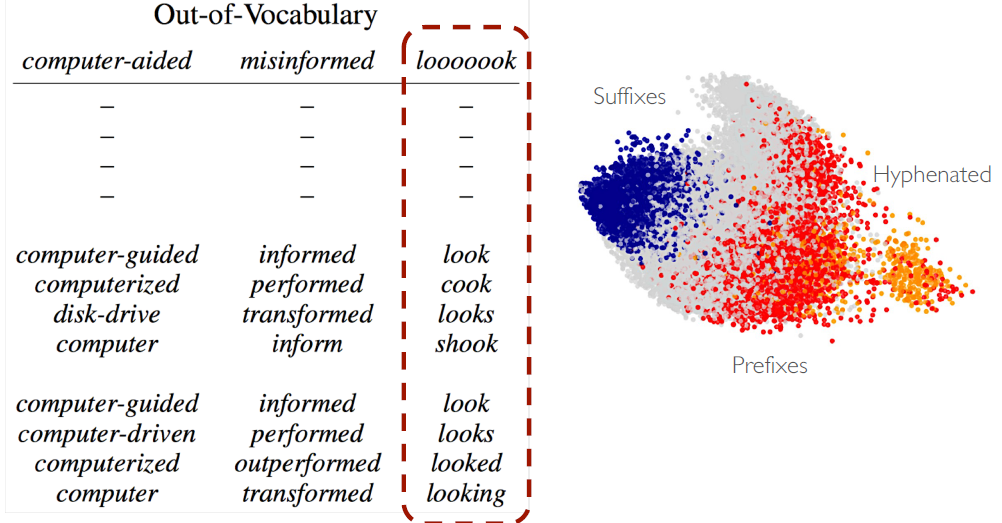
Quantitative Results

Highway network를 통과하기 전에 character-level로 진행한 모델에서는 character 단위로 진행하다보니까 낸 결과들이 의미가 아닌 철자가 유사한 단어들
Highway network를 통과한 후에는 사람 이름들을 결과값으로 내는 것을 볼 수 있습니다. 즉, semantic을 반영해서 조금 더 의미있는 단어들을 학습하게 되는 것입니다.
Hybrid NMT [논문]
대부분의 경우 word level model을 사용하고, 필요 시에 character level model을 사용합니다.
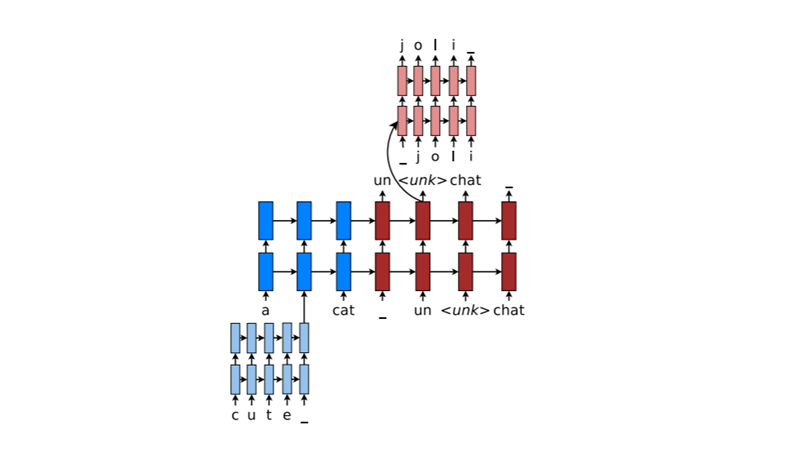
- 16,000개의 vocabulary size를 이용
- 기본적으로 seq2seq으로 word-level model 진행
- unknown word -> character-level model
- 4개의 layer를 사용
2-stage Decoding
- 일반적으로 NMT의 decoder는 beam search 사용
- 이 모델에서는 보다 복잡한 버전의 beam search인 word-level beam search와 character-level beam search 사용
즉, Hybrid NMT의 경우에는 모델의 기본 구조에 따라 decoder에서도 기본적으로 word level beam search를 사용하고 unknown word에 대해서만 character-level beam search를 사용하게 되는 것입니다.

위 결과를 보면, word-level model 사용 시 unknown word를 copy 기법으로 처리했을 때, 이름은 문제없이 옮기지만 나이 같은 경우 번역이 안 된 상태로 들어가서 제대로 번역이 되지 않은 문장이 만들어진다는 것을 알 수 있습니다.
반면 hybrid에서는 나이는 정확하게 번역을 하지만 이름 번역 과정에서 오류가 생기는 걸 볼 수 있습니다.
Chars for word embeddings
논문 A Joint Model for Word Embedding and Word Morphology
- 문자 시퀀스(character sequence)에서 시작
- Bidirectional LSTM을 통해 복잡한 모델을 효과적으로 훈련
- character embedding과 LSTM parameter를 학습하여 word representation을 제공
FastText Embeddings
논문 Enriching Word Vectors with Subword Information
- a next generation efficient word2vec-like word representation library
- 형태소가 풍부한 언어나 희귀한 단어들을 다룰 때 더 좋은 성능을 보이는 모델
- word2vec skip-gram 모델의 확장: character n-grams 사용
Reference
https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/slides/cs224n-2019-lecture12-subwords.pdf
https://wikidocs.net/22592
https://velog.io/@tobigs-text1314/CS224n-Lecture-12-Subwords
https://youtu.be/64FxDORoHm0

10개의 댓글

투빅스 14기 한유진
- Word-Level Model은 수많은 단어들을 나타낼 공간 부족, 신조어/축약어를 다루기가 어렵다는 단점이 있습니다. 그래서 Character-Level Model은 의미정보를 포기하는 대신 unknown word 표현 가능, 합성어와 같은 connected language에 대한 분석이 가능하다는 장점이 있습니다. 이후로 Character-Level Model을 발전시켜 encoder,decoder를가지는 모델들로 더 나은 성능을 보였습니다.
- Subword model는 word-level model이지만 word-pieces사용, Hybrid 구조 이렇게 두가지 방법으로 나눌 수 있습니다. 이와 관련되어 데이터압축 알고리즘에서 출발한 BPE 알고리즘은 bytes가 아닌 character ngram을 사용하고, 다국어에 대해서도 별도의 처리가 필요하지 않습니다.
- 단어의 출현 빈도수를 기반으로 단어 추가 후 BPE를 적용하는 Wordpiece 모델과 동시발생확률 계산 후 가장 높은 값을 가지는 것을 추가하는 sentencepiece model은 BPE의 변형들입니다.
- Hybrid Model은 main model은 word기반, 필요시에 character기반을 추가한 모델입니다. Hybrid NMT같은 경우 decoder에 word기반을, unknown word에 대해서는 character기반을 사용한다고 합니다.
word, 언어에 집중한 모델을 배울 수 있었던 강의였습니다. 좋은 강의감사합니다!

투빅스 15기 강재영
- 사람의 언어 표기 체계 (writing system) 는 나라마다 다르고, 하나로 통일되어 있지 않다.
- 따라서 Word-Level Model의 경우, 커버해야할 단어가 너무 많기 때문에 무한한 단어 공간이 필요하고 비효율적이다.
- 반면에 Character-Level Model의 경우 의미정보가 사라지는 대신 OOV 문제 해결이 가능하고, 어떤 신조어가 와도 임베딩이 가능하다. 이후에는 Encoder, Decoder가 존재하는 모델로 발전시켜서 성능향상을 이뤄냈다.
- 즉 정리하자면, Word-level model은 속도가 빠르기 때문에 짧은 시간 내에 태스크를 해낼 수 있는 반면, characeter-level model은 word pieces를 이용하기 때문에 연산량이 word-level model보다 시간과 비용이 훨씬 많이 든다.
- Byte Pair Encoding (BPE)란 새로운 방법이 제시됐는데, 단어의 의미를 내포하고 있는 어간(?)을 빈도기준으로 제작하여 분리하여 Encoding함
- BERT의 경우 BPE 방법론을 사용한 예시임
-- WordPiece Tokenizer 사용
-- 자주 등장하는 단어는 그대로 단어 집합에 추가
-- unknown word 등장 시 다음과 같이 word pieces로 분할

투빅스 15기 조준혁
- 사람의 언어 표기 체계는 하나로 통일되어 있지 않고 언어 표기 체계는 나라마다 다릅니다.
- 단어 단위의 model은 커버할 단어가 너무 많아 무한한 단어 공간이 필요해져 비효율적입니다.
- 문자 단위의 모델은 단어가 가지고 있은 의미 정보는 포기하고 두 가지 이점을 가지고 있습니다. 단어 임베딩은 문자 임베딩으로부터 구성할 수 있다. 즉, 어떤 문자 시퀀스에 대해서도 단어 표현 생성이 가능해지게 됩니다. sequence of characters 기반으로만 언어를 처리하기 때문에 합성어와 같은 connected language에 대해서도 분석이 가능해지게 됩니다.
- Subword Model의 두 가지 방법 : Same architecture as for word-level model, Hybrid architectures
- Chars for word embeddings는 문자 시퀀스(character sequence)에서 시작, Bidirectional LSTM을 통해 복잡한 모델을 효과적으로 훈련, character embedding과 LSTM parameter를 학습하여 word representation을 제공
- FastText Embeddings는 형태소가 풍부한 언어나 희귀한 단어들을 다룰 때 더 좋은 성능을 보이는 모델입니다.
언어의 특성을 고려한 NLP의 기초를 배울 수 있었던 강의였습니다.

투빅스 15기 조효원
- Word-level model에는 두 가지 문제가 있다. 하나는 수많은 단어들을 모두 다루기에 공간이 부족하다는 것이다. 또한 신조어와 축약어를 다루기도 힘들다([unk]은 성능을 매우 저하함). Character-level을 사용하면 이러한 문제를 해결할 수는 있으나 의미정보가 사라지기에 문제가 있다.
- 생각해보면 언어의 최소 의미 단위는 단어가 아닌 형태소이다. 형태소들이 조합되어 단어가 생성된다. 이것에서 아이디어를 얻어 subword model들이 나온다.
- 대표적인 Subword model은 BPE 방식이다. BPE는 bottom-up 방식으로 단어 딕셔너리를 구축해나가는 방식으로, 빈번하게 함께 등장하는 캐릭터 쌍들이 단어 사전에 추가되는 방식으로 학습된다.
- Wordpiece는 단어의 출현 빈도수를 기반으로 단어 추가를 먼저 한 후에 BPE를 적용한다.
- sentencepiece는 동시발생확률 계산 후 가장 높은 값을 가지는 것을 추가한다.
- Subword를 고려한 임베딩 기법으로는 FastText가 있다. 이는 n-gram 단위를 단어임베딩을 학습할 때 고려한다.

투빅스 15기 이윤정
- 사람의 언어 표기 체계는 나라마다 다르고, 하나로 통일되어 있지 않다.
1. No word segmentation : 띄어쓰기 사용여부
2. Compound Nouns : 합성어에 대한 띄어쓰기 유뮤 - 단어 기반의 모델의 경우 무한한 단어 공간이 필요하므로 비효율적인 반면, 문자 기반 모델의 경우 어떠한 문자 시퀀스에 대해서도 단어 표현 생성이 가능하다는 특징을 지닌다.
- subword model의 경우 word-level model과 hybrid architectures로 구분되어 진다. 이때, word-level model의 경우 word-pieces를 사용한다.
- Byte Pair Encoding (BPE)란 가장 빈번하게 발생하는 pair를 character 단위로 단어 사전에 추가하는 방식이다.
- BPE를 사용한 모델에는 BERT가 존재하며, wordpiece tokenizer를 사용하였다.

투빅스 14기 정재윤
-
초창기 모델들은 word-level model을 사용했으나 이 모델은 단어를 표현할 때 너무 많은 공간을 사용한다는 점에서 굉장히 비효율적이었다. 이 후, 발전된 형태로 나온 모델이 Character-Level model로 OOV 문제를 효과적으로 해결할 수 있었다. 하지만 의미 정보를 포기했기에 완벽하다고는 말할 수 없다.
-
bpe는 byte pair encoding을 의미하며, 단어를 최소 단위로 나눠서 임베딩을 진행하는(?) 방식을 의미한다. BPE 방식으로는 크게 2가지가 있는데, wordpiece 방식과 Sentencepiece 방식이 존재한다. 이 중 wordpiece 방식은 최근 NLP model 들로 유명한 bert, transformer, gpt-2 등에 사용됩니다.
-
Hybrid Model은 main model은 word기반, 필요시에 character기반을 추가한 모델로, 각각의 장점들을 뽑은 모델이긴 하지만 여전히 일부 고유명사들을 잘 번역하지는 못합니다.

투빅스 15기 김동현
- Purely-character level model의 필요성은 두 가지인데, 첫째로, 언어마다 단어 표현 방법이 다르기 때문에 character level로 접근하는 것이 더 효과적인 경우가 있다. 둘째로, 말 그대로 ‘large’하고 ‘open’한 어휘를 다룰 수 있어야 한다.
- 언어의 특성에 따라 word level 모델과 character level 모델의 성능에 차이가 있을 수 있다.
- Subword 모델은 word level 모델과 동일하지만, 더 작은 word인 word pieces를 이용한다. Subword모델의 대표적인 예시인 BPE 모델은 딥러닝과 무관한 간단한 아이디어를 사용하고 있다.
- BERT는 vocab size가 크지만, 엄청 크지는 않기 때문에 word piece를 사용할 필요가 있다. 따라서 상대적으로 등장 빈도가 높은 단어들과 더불어 wordpiece를 사용한다.
- Hybrid NMT 모델은 대부분 word level에서 접근하고, 필요할때만 character level로 접근한다.

14기 박준영
- word-level models(단어 기반모델)은 단어가 많이 필요하기 때문에 무한한 단어 공간이 필요하게 되어 비효율적
- character-level model(문자 기반 모델)은 단어가 가지고 있는 의미 정보를 포기하는 대신 OOV문제(단어 데이터가 없는 것을 처리 못하는 문제)를 해결하였고 sequence of characters 기반으로 언어를 처리하기때문에 합성어에 대해서도 분석이 가능하다
- subword models은 word 대신 word-pieces/sentencepiece를 사용한 same architecture as for word-level model 방법, unknown word를 다른 표현으로 나타내는 hybrid architectures 방법이 있다.
- wordpiece model은 pre-segmentation을 통해서 단어의 출현 빈도수를 기반으로 단어를 추가해준뒤 BPE(byte pair encoding)을 적용하는 기법으로 Transformer, Elmo, Bert, GPT-2가 있다.
- sentencepiece model은 단어로 구분하기 어려운 언어 (중국어와 같은)을 위해 raw text에서 바로 character-level로 나눈후 BPE 기법을 사용하였다.
- hybrid models에는 character-based LSTM, Character-Aware Neural Language Models, Hybrid NMT, 2-stage Decoding 등이 있습니다.
좋은 강의 감사합니다!!

투빅스 15기 김재희
subword model은 처음 접했는데, 생각보다 다양하고 재밌는 분야인 것 같습니다.
- 인간은 단어 단위로 인지하지 않기 때문에 이에 기반하여 subword 모델들이 개발되었습니다.
- 하지만 이 과정에서 기존의 morphology를 활용하는데 한계점이 있었습니다. morphology로는 커버가 되지 않는 OOV문제나, 각 언어마다 가지는 특색의 문제가 있기 때문입니다.
- 그래서 여러 알고리즘들이 나왔는데, 아예 character 단위로 쪼개는 모델들이 대표적입니다.
- character 단위로 쪼갤 시 이를 다시 단어 단위의 벡터로 만들어주기 위해서 cnn이나 rnn의 알고리즘을 사용합니다.
- 이외에도 subword 모델들이 있는데 대부분 BPE에 기초를 두고 있습니다.
- 그 외에도 charcter 단위와 word 단위를 모두 활용한 hybrid 모델들 역시 존재합니다.
투빅스 14기 정세영
심화된 nlp 모델들에 기반이 되는 subword model의 개념을 잘 쌓을 수 있는 강의였습니다.