Lecture 13 – Contextual Word Embeddings

작성자 : 동국대학교 통계학과 이윤정
Contents
- Reflections on word representations
- Pre-ELMo and ELMO
- ULMFit and onward
- Transformer architectures
- BERT
Contextual Word Embeddings
이번 강의에서는 문맥을 반영한 Word Embedding과 관련 Model에 대해 배웁니다.
Reflections on word representations
1. Representations for a word
컴퓨터는 어떻게 자연어를 이해하고 효율적으로 처리하고 있을까요? 컴퓨터는 Word Embedding을 통해 단어를 벡터로 표현함으로써 자연어를 이해합니다. 우리가 앞선 강의에서 배운 Word2Vec, GloVe, fastText 역시 단어를 벡터로 표현하는 방법들입니다.
2. Pre-trained word vectors
Until 2011
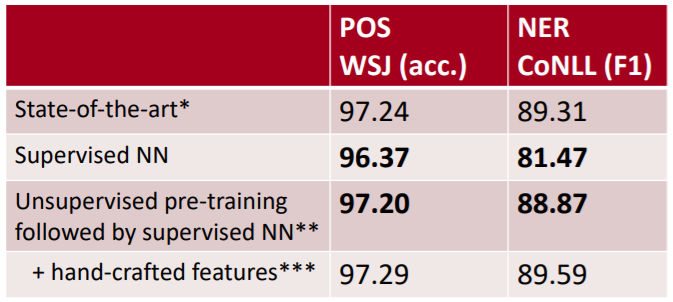 2011년까지 POS tag 및 NER task에 대한 성능 비교표입니다.
2011년까지 POS tag 및 NER task에 대한 성능 비교표입니다.
1번째 방법론인 State-of-the-art은 Rule-based 방법론으로 Word Representation (Word2Vec, GloVe 등)을 사용하지 않습니다. 3번째 방법론인 Unsupervised pre-training followed by supervised NN은 2번째 방법론과 Word Representation를 함께 사용한 방법으로 Rule-based보다 성능은 뒤쳐지지만, 성장 가능성을 확인할 수 있습니다.
After 2014
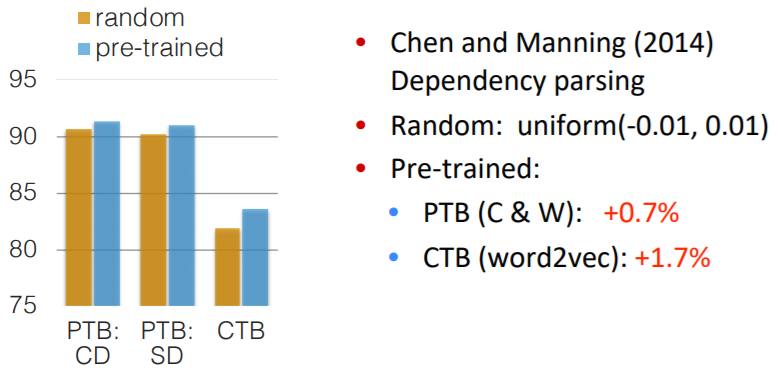 Random initialization word vector와 Pre-trained word vector에 대한 그래프로 pre-trained word vector를 사용하는 것이 성능 향상에 도움이 되는 것을 알 수 있습니다. pre-trained word vector의 경우 task에 쓰이는 labeled 데이터보다 훨씬 더 많은 unlabeled 데이터에 의해 학습되기 때문에 성능 향상에 도움이 됩니다.
Random initialization word vector와 Pre-trained word vector에 대한 그래프로 pre-trained word vector를 사용하는 것이 성능 향상에 도움이 되는 것을 알 수 있습니다. pre-trained word vector의 경우 task에 쓰이는 labeled 데이터보다 훨씬 더 많은 unlabeled 데이터에 의해 학습되기 때문에 성능 향상에 도움이 됩니다.
3. Usefulness of Pre-trained word vector
Pre-trained word vector는 성능 향상 뿐만 아니라 Unknown word vector, 통칭 UNK Token을 처리하는 데에도 효과적입니다.
일반적으로 train 시 약 5회 이하로 등장하는 단어는 UNK로 처리를 하며, test 시 Out-Of-Vocabulary(OOV) 단어를 UNK로 매칭합니다. 그러나, UNK로 매칭된 단어가 중요한 의미를 지니고 있어도 이를 고려하지 못한다는 문제점이 발생합니다. 본 강의에서는 이러한 문제점을 해결하기 위해 다음과 같은 해결책을 제시합니다.
- Character level의 embedding model을 이용하여 word vector 생성
- Pre-trained word vector 사용 → 가장 많이 사용되는 방법
- Random vector을 부여하여 vocabulary에 추가 → 각 단어가 고유한 정체성을 가지는 효과
4. Problem of having one representation of words
Star라는 단어가 하늘에 있는 별을 의미하기도 하지만 할리우드 스타와 같은 연예인을 의미하듯 하나의 단어도 여러 의미가 존재합니다. 하지만, 하나의 단어를 하나의 word vector로 표현하는 경우 한 문맥의 word vector로 매칭되기 때문에 동음이의어 혹은 문맥에 따라 단어의 type이 달라지는 측면을 고려하지 못하게 됩니다. 이러한 문제점을 해결하기 위해 Contextual Word Vector의 필요성이 대두됩니다.
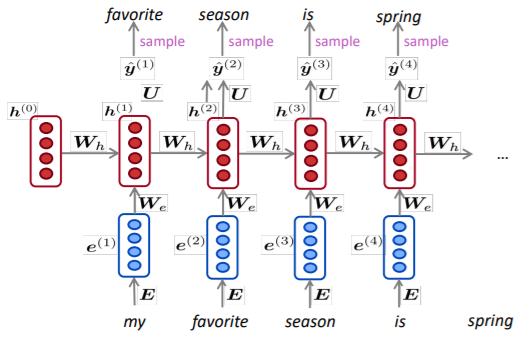 본 강의에서는 Neural Language Model을 통해 contextual word vector를 생성하는 방법을 소개합니다. LSTM layer의 경우 문장의 Sequence를 고려하여 다음 단어를 예측할 수 있으므로 Context-specific word representation 역시 예측할 수 있을 것입니다. 이러한 아이디어를 활용한 대표적인 모델로는 ELMo가 있습니다.
본 강의에서는 Neural Language Model을 통해 contextual word vector를 생성하는 방법을 소개합니다. LSTM layer의 경우 문장의 Sequence를 고려하여 다음 단어를 예측할 수 있으므로 Context-specific word representation 역시 예측할 수 있을 것입니다. 이러한 아이디어를 활용한 대표적인 모델로는 ELMo가 있습니다.
Pre-ELMo and ELMo
1. TagLM -"Pre-ELMo"
본 강의에서 TagLM 혹은 Pre-ELMo라고 지칭되는 해당 모델은 ELMo 발표 저자가 ELMo 이전에 발표한 모델로 ELMo와 아주 유사한 형태의 구조를 지닙니다. Pre-ELMo는 small-task labeled data를 학습에 주로 사용하기 때문에 RNN을 통해 Context 속 의미를 학습하기 어렵다는 문제점을 Large Unlabeled Corpus로 먼저 학습을 시키는 Semi-supervised approach를 적용하여 해결하였습니다. 이러한 Pre-ELMo의 구조는 크게 3단계로 구분할 수 있습니다.
STEP1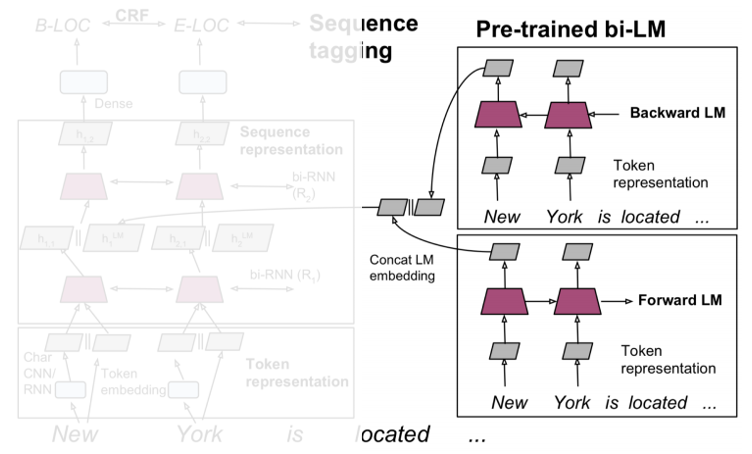
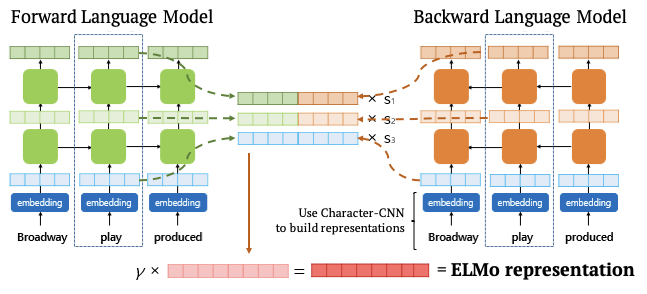
Pre-trained Bi-LM은 Input String을 순방향 LM, 역방향 LM에 별도로 들어오게 됩니다. 이때, 각 LM에서의 output은 concat되며 수식으로 표현 시 다음과 같습니다.
STEP2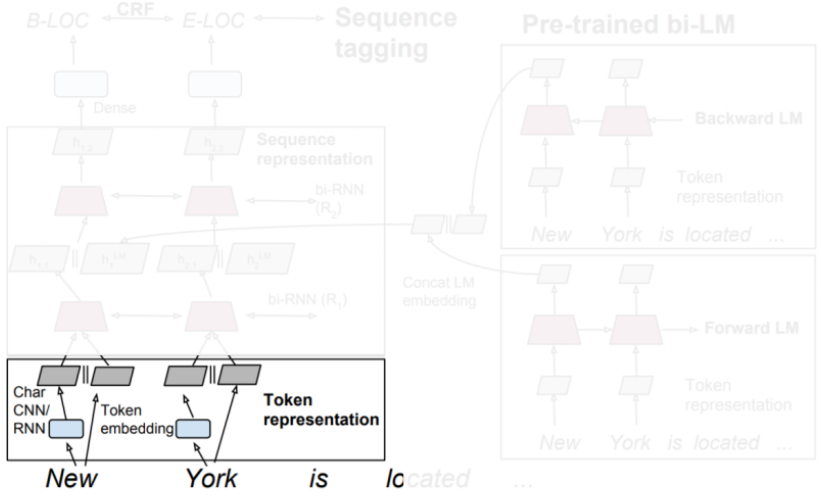
Pre-trained model이 훈련하는 동안 모델은 현재 입력 단어가 주어지면 다음 단어를 예측합니다. 이때, Input String은 Token embedding(word2Vec)과 Char CNN으로 표현할 수 있습니다. 이후 해당 단계에서의 output은 concat되어 2-layer Bi-LSTM의 1st layer의 input으로 들어갑니다.
STEP3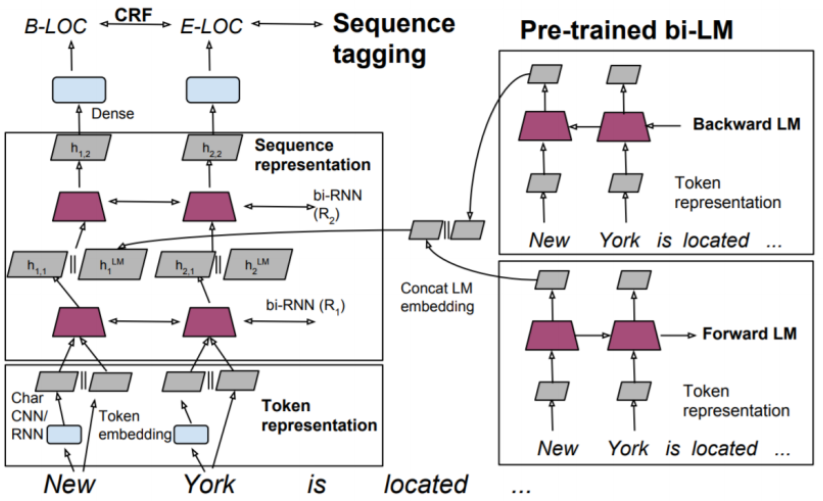
Bi-LSTM의 1st layer의 output은 Pre-trained LM에서의 최종 output 와 concat되어 2nd layer로 공급되며 수식으로 표현 시 다음과 같습니다.
2. ELMo
ELMo는 Pre-ELMo를 일반화한 모델로 기존 방법들과 2가지 차이점이 존재합니다. 첫번째로 window를 통해 주변 context만 사용하는 기존 embedding 방법과 달리 모든 문장을 사용하여 Contextualized word vector를 학습합니다. 두번째는 최종 layer의 값들로 word vector를 사용한 이전 모델과 달리 2-layer 양방향 언어모델인 ELMo는 순방향과 역방향 layer를 통해 특정 단어 및 해당 단어의 앞쪽/뒷쪽 정보를 포함한 단어에 대한 각 layer 별 출력 값이 존재하며 모든 layer의 출력값을 활용하여 최종 word vector를 embedding합니다.
구조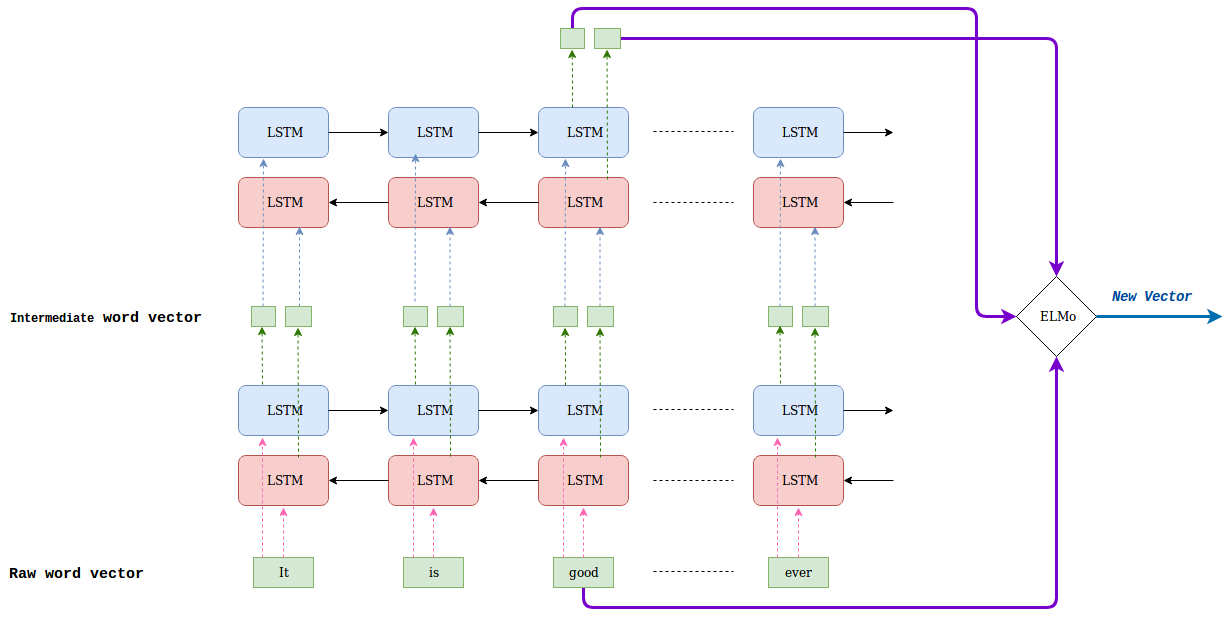
우선, Input String은 Char-CNN에 의해 word vector로 변환되어 Bi-LM의 1st layer에 공급됩니다. 이때, 1st layer는 residual connection을 통해 Char-CNN으로 반영된 단어의 특징을 유지합니다. 1st layer의 output인 중간 word vector는 Bi-LM의 2nd layer에 공급됩니다. 이후, 2nd layer 역시 output으로 중간 word vector를 출력합니다.
 2nd layer의 중간 word vector까지 출력되면, 각 layer로부터 출력된 중간 word vector와 raw word vector를 각각 concat한 후 가중치를 통해 선형 결합하여 ELMo Representation 도출합니다. 일종의 가중합 과정으로 볼 수 있으며, LSTM의 top layer만 사용하던 이전 모델들과 달리 각 layer의 결과를 선형 결합하여 모두 사용하게 됩니다. 해당 과정을 수식으로 나타내면 다음과 같습니다.
2nd layer의 중간 word vector까지 출력되면, 각 layer로부터 출력된 중간 word vector와 raw word vector를 각각 concat한 후 가중치를 통해 선형 결합하여 ELMo Representation 도출합니다. 일종의 가중합 과정으로 볼 수 있으며, LSTM의 top layer만 사용하던 이전 모델들과 달리 각 layer의 결과를 선형 결합하여 모두 사용하게 됩니다. 해당 과정을 수식으로 나타내면 다음과 같습니다.
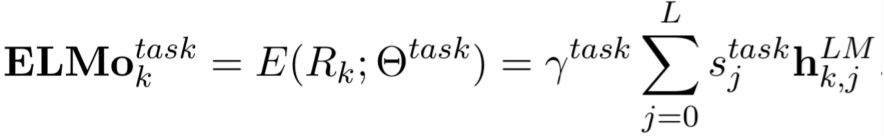 최종적으로 모든 layer의 벡터를 더해 하나의 임베딩 벡터라는 word vector를 생성하므로써 단어 자체가 가지고 있는 특징인 Syntax 정보와 문맥이 고려된 특징인 Semantics 정보를 모두 활용할 수 있습니다.
최종적으로 모든 layer의 벡터를 더해 하나의 임베딩 벡터라는 word vector를 생성하므로써 단어 자체가 가지고 있는 특징인 Syntax 정보와 문맥이 고려된 특징인 Semantics 정보를 모두 활용할 수 있습니다.
- 1st layer : Better for lower-level Syntax
- 2nd layer : Better for higher-level Semantics
ELMo의 트릭
Fine-Tuning 단계에서는 양방향 LSTM 레이어가 동일한 단어 시퀀스를 입력받지만, Pre-Training 단계에서는 순방향, 역방향 네트워크를 별개의 모델로 보고 서로 다른 학습 데이터를 입력하게 된다. 즉, 손실 레이어에서는 순방향, 역방향 LSTM 출력 히든 벡터를 더하거나 합치지 않고 각각의 히든 벡터로 각각의 레이블 (순방향, 역방향 단어 시퀀스)를 맞추는 것을 독립적으로 학습한다.
-이기창 저. 한국어 임베딩
Performance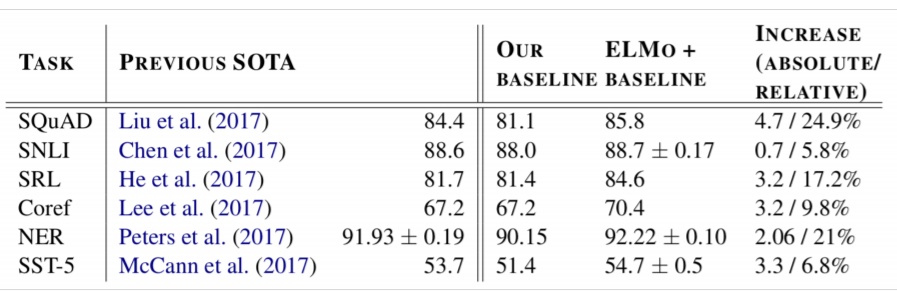
NER 뿐만 아니라 다른 Task에서도 모두 SOTA를 기록하였습니다. 이를 통해 ELMo가 모든 Task에서 우수한 성능을 지녔음을 알 수 있습니다.
ULMFit and onward
ULMFit 모델은 NLP에서 본격적으로 Transfer Learning을 도입한 첫 사례입니다.
Transfer Learning이란?
큰 Dataset으로 학습 후 특정 Task에 대한 fine-tuning을 통해 성능을 개선하는 일
1개의 GPU로 학습할 수 있을 정도의 사이즈이며, 언어 모델을 통해 Text Classification을 목적으로 한다는 특징을 지닙니다. ULMFit 모델의 구조는 크게 3단계로 나눌 수 있습니다.
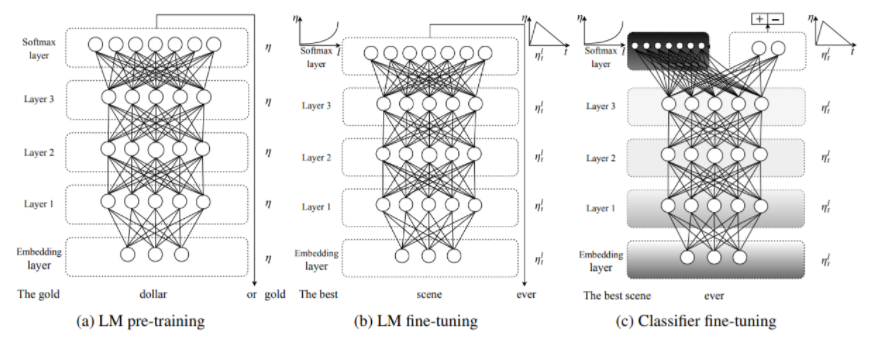
STEP1. 일반 언어 모델 학습 (A)
첫번째 단계는 Transfer Learning에 해당하는 부분입니다. 논문에서 사용된 일반 언어 모델은 LSTM 언어 모델에 다양한 정규화(regularization) 방법을 적용한 AWD-LSTM 모델입니다. 3-layer Bi-LSTM 언어 모델이며, 논문에서는 Wekipedia 영어 버전 전체에 대해 Pre-trained했습니다.
STEP2. 과제 맞춤형 언어 모델 튜닝 (B)
두번째 단계는 Task에 맞추어 일반 언어 모델을 추가 학습하는 부분입니다. 이때, 튜닝 시 사용하는 2가지 기법으로 Discriminative Fine-tuning과 Slanted triangular learning rates가 있습니다.
- Discriminative Fine-tuning : 언어 모델 튜닝 시 각 layer별 학습율(learning rate)을 서로 다르게 조정하는 방법입니다. 깊은 layer에 대해서는 상위 layer에 비해 더 작은 학습율을 부여합니다.
- Slanted triangular learning rates : 튜닝 횟수에 따라 학습율을 적용하는 방법입니다. 초반에 작은 학습율로 시작해서 점점 학습율을 증가하다가 약 200번의 학습 후 다시 학습율을 점진적으로 감소시킵니다.
STEP3. 과제 분류기 튜닝 (C)
classifier를 학습하기 위해 언어 모델 과제에서 사용된 다음 단어 예측을 위한 레이어(softmax)를 제거하고, 주어진 텍스트가 어떤 클래스에 속할 지 확률을 계산하는 새로운 분류 레이어(softmax)를 추가합니다. 즉, 기존 언어 모델에서 마지막 레이어만 제거하고 나머지는 그대로 둔 후 새로운 분류 레이어 하나만을 추가하여 학습합니다.
Performance
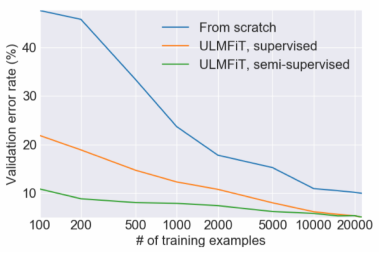 ULMFit을 사용한 경우 에러율이 현저히 낮은 것을 확인할 수 있습니다. 이처럼 ULMFit을 사용하면 더 적은 양의 데이터만으로 자연어 처리를 효과적으로 수행할 수 있음을 알 수 있습니다.
ULMFit을 사용한 경우 에러율이 현저히 낮은 것을 확인할 수 있습니다. 이처럼 ULMFit을 사용하면 더 적은 양의 데이터만으로 자연어 처리를 효과적으로 수행할 수 있음을 알 수 있습니다.
Let's scale it up!
 ULMFit 이후 모델의 파라미터를 늘려 pre-trained LM이 많이 등장하였으나, GPU 1개로 학습이 가능했던 ULMFit과 달리 필요한 리소스가 급증하였습니다. 추가적으로 표에 등장한 모델 중 ULMFit을 제외한 모든 모델은 Transformer 기반의 모델입니다.
ULMFit 이후 모델의 파라미터를 늘려 pre-trained LM이 많이 등장하였으나, GPU 1개로 학습이 가능했던 ULMFit과 달리 필요한 리소스가 급증하였습니다. 추가적으로 표에 등장한 모델 중 ULMFit을 제외한 모든 모델은 Transformer 기반의 모델입니다.
Transformer architectures
Transformer와 Self-Attention의 경우 CS224n Lecture 14강에서 배우기 때문에 간단하게 언급하겠습니다.
1. The Motivation for Transformer
RNN은 병렬적 계산이 불가능하며 매우 느린 속도를 보입니다. 이러한 한계점을 해결하기 위해 LSTM과 GRU가 등장하였으나 완벽하게 해결할 수 없었습니다. Transformer 기반의 모델은 Attention을 통해 time stamp를 참조할 수 있다면 RNN의 한계점을 극복할 수 있다는 아이디어에서 출발하였습니다.
2. Transformer Overview
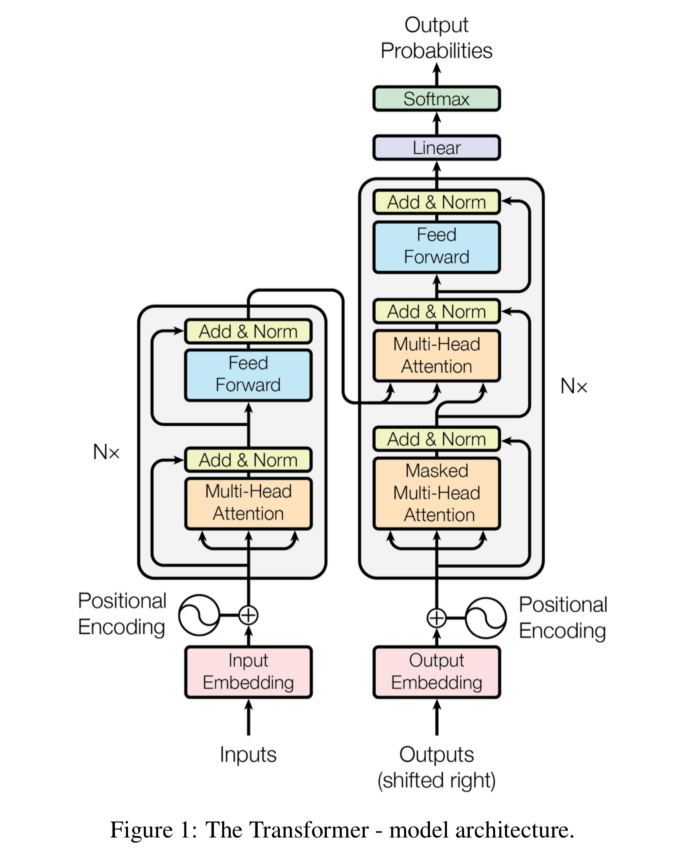 Transformer는 RNN을 사용하지 않지만 Attention을 통해 Seq2Seq 모델처럼 encoder에서 token sequence를 입력받아 임베딩을 하고, decoder에서 출력할 token sequence를 예측하는 encoder-decoder 구조를 유지하고 있습니다.
Transformer는 RNN을 사용하지 않지만 Attention을 통해 Seq2Seq 모델처럼 encoder에서 token sequence를 입력받아 임베딩을 하고, decoder에서 출력할 token sequence를 예측하는 encoder-decoder 구조를 유지하고 있습니다.
3. Dot-Product Attention
Transformer 구조를 알기 전에 Attention 매커니즘을 살펴보겠습니다. Attention의 Input으로는 Query, Key, Value가 존재합니다.
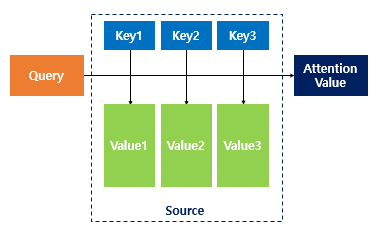
Query, Key, Value를 input으로 갖는 Attention 함수는 다음과 같은 구조로 표현할 수 있습니다. Attention 함수는 주어진 'Query'에 대해서 내적을 통해 모든 'Key'와의 유사도를 각각 구합니다. 그리고 구해낸 이 유사도를 키와 맵핑되어있는 각각의 'Value'에 반영한 다음 모두 더해서 출력합니다. 여기서 이를 Attention Value이라고 합니다. 즉, 유사도가 일종의 가중치 역할을 한다고 볼 수 있으며, 결국 Query와 비슷할 수록 높은 가중치를 주어 출력을 주는 것입니다.
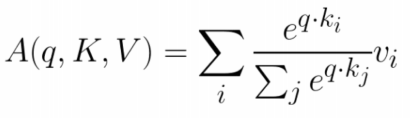
4. Scaled Dot-Product Attention
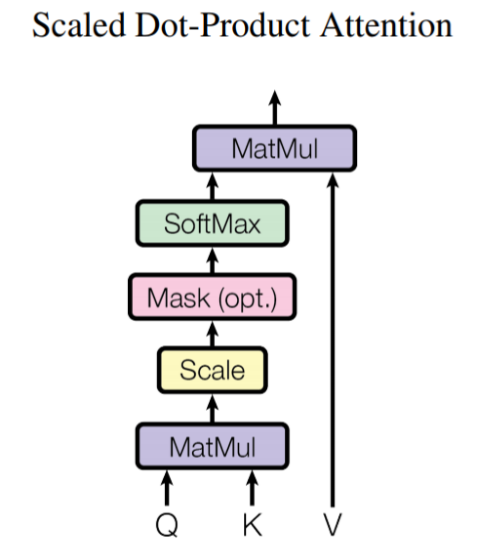 Transformer 구조에서 이러한 Attention 매커니즘을 Scaled Dot-Product Attention이라고 합니다. 벡터 차원 수가 클수록 Query와 Key의 내적 값의 차이가 증가하고 이는 softmax 값의 증가로 이어져 학습에 악영향을 초래할 수 있습니다. 그러므로, 학습 시 그래디언트를 최적화하기 위해서 모든 Query와 Key에 대해 Dot-Product를 계산 후 벡터 차원 수의 제곱근 로 scaling 해주는 방식입니다.
Transformer 구조에서 이러한 Attention 매커니즘을 Scaled Dot-Product Attention이라고 합니다. 벡터 차원 수가 클수록 Query와 Key의 내적 값의 차이가 증가하고 이는 softmax 값의 증가로 이어져 학습에 악영향을 초래할 수 있습니다. 그러므로, 학습 시 그래디언트를 최적화하기 위해서 모든 Query와 Key에 대해 Dot-Product를 계산 후 벡터 차원 수의 제곱근 로 scaling 해주는 방식입니다.
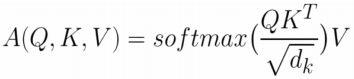
5. Self-Attention
Self-Attention은 입력 데이터 Query가 있을 때, 검색 대상이 되는 Key-Value pair 데이터 테이블이 입력 데이터 Query 자기 자신인 경우를 의미합니다. 즉, 자기 자신의 Query로 Attention Value를 구하는 것으로 Self-Attention을 통해 문장 안에서 단어들 간의 관계를 파악할 수 있게 됩니다.
6. Multi-head attention
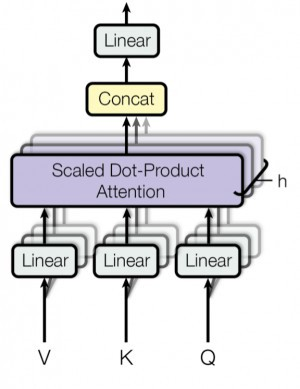
Multi-head-attention은 Scaled Dot-Product Attention을 여러 개 만들어 다양한 특징에 대한 어텐션을 볼 수 있게 한 방법입니다. 즉, 입력받은 Query, Key, Value를 헤드 수만큼 나누어 병렬적으로 계산해주는 것이 핵심입니다. 각 Head에서는 Scaled Dot-Product Attention 과정이 발생하며, 그렇게 발생한 Head별 Attention Value는 concat되어 다음 layer로 전달됩니다.
7. Full Architecture
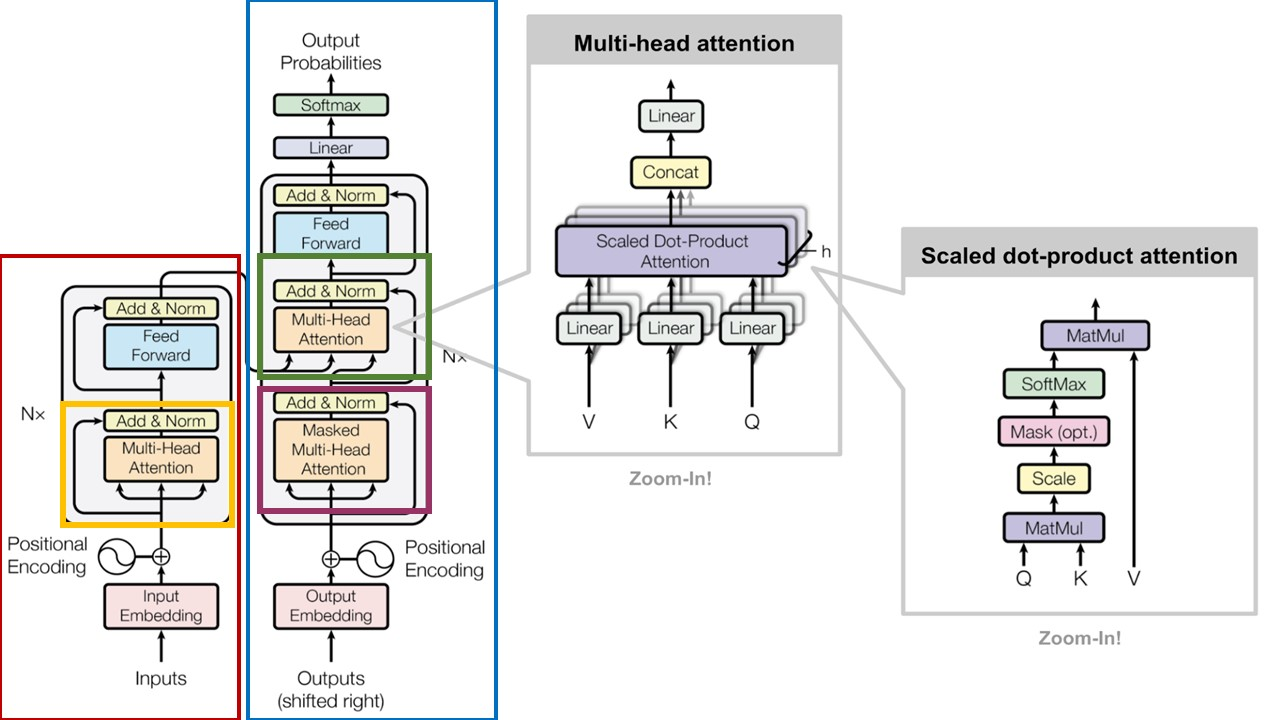
위 그림에서 빨간색 블록은 Encoder, 파란색 블록은 Decoder이며 자세한 내용은 다음과 같습니다. 노란색 블록은 Encoder에서 Self-Attention이 발생하는 부분, 자주색 블록은 Decoder에서 Self-Attention이 발생하는 부분, 초록색 블록은 Encoder와 Decoder에서 Attention이 일어나는 부분입니다.
문장이 Encoder로 들어오면 임베딩을 거친 후 Multi-Head Attention 과정을 거칩니다. Decoder 부분에서도 번역된 문장이 Self-Attention 과정을 거칩니다. 다음으로 Self-Attention을 거친 두 문장은 Multi-Head Attention 과정을 거치게 됩니다.
BERT
BERT는 2018년 11월 구글이 공개한 언어모델로 Transformer에서 encoder만 사용한 모델입니다. BERT 모델의 구조는 크게 2단계로 나눌 수 있습니다. 첫 번째 단계는 대량의 텍스트 데이터에 대한 semi-supervised 과정인 Pre-Training이며, 두 번째 단계는 target task에 대한 supervised 과정인 Fine-Tuning입니다.
첫 번째 단계는 BookCorpus와 영문 위키피디아에 대하여 semi-supervised를 통해 언어의 패턴을 학습하는 과정입니다. 이때, Pre-training을 위한 Objective Function은 2가지입니다.

- Masked Language Modeling (MLM)
위 그림과 같이 [MASK]된 부분의 단어를 예측하는 것을 MLM이라 합니다. 전체 단어의 15%를 선택한 후 그 중 80%는 [MASK], 10%는 현재 단어 유지, 10%는 임의의 단어로 대체 합니다.- Next Sentence Prediction (NSP)
위 그림과 같이 첫 번째([CLS]) Token으로 문장 A와 문장 B의 관계를 예측하는 것을 NSP라 합니다. A 다음문장이 B가 맞을 경우는 True, A 다음문장이 B가 아닐 경우 False로 예측하도록 합니다.
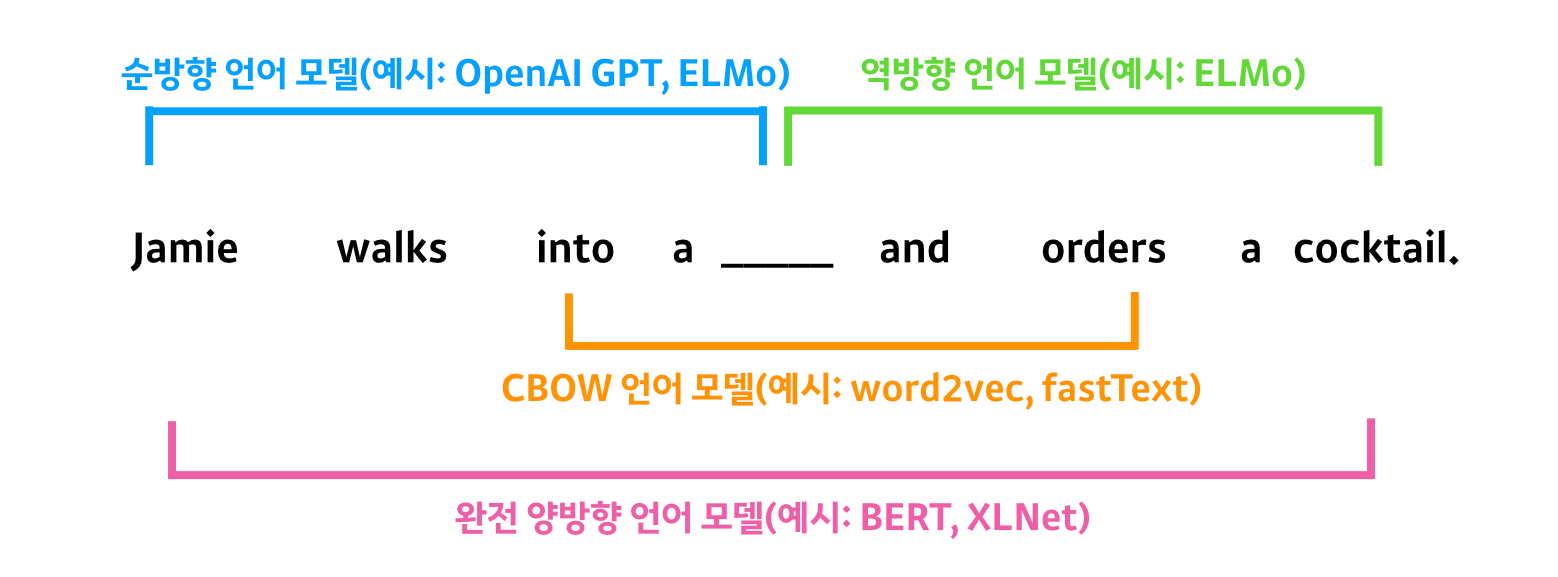 기존 양방향 모델의 경우 순방향과 역방향이 독립적으로 사용되어 각각 순방향과 역방향 시퀀스를 가지게 됩니다. 이는 단어를 예측할 때 그때까지 존재한 단어를 기반으로 예측에 사용한다는 의미입니다. 즉, 순방향 모델의 경우 target을 예측하기 위해 앞에 오는 시퀀스(Jamie walks into a)만 보고, 역방향 모델은 뒤에 오는 시퀀스(and orders a cocktail)만 보고 예측하게 됩니다. 결국 순방향과 역방향 모델을 모두 사용하여도 전체 단어를 모두 활용하여 단어를 예측할 수 없음을 의미합니다.
기존 양방향 모델의 경우 순방향과 역방향이 독립적으로 사용되어 각각 순방향과 역방향 시퀀스를 가지게 됩니다. 이는 단어를 예측할 때 그때까지 존재한 단어를 기반으로 예측에 사용한다는 의미입니다. 즉, 순방향 모델의 경우 target을 예측하기 위해 앞에 오는 시퀀스(Jamie walks into a)만 보고, 역방향 모델은 뒤에 오는 시퀀스(and orders a cocktail)만 보고 예측하게 됩니다. 결국 순방향과 역방향 모델을 모두 사용하여도 전체 단어를 모두 활용하여 단어를 예측할 수 없음을 의미합니다.
BERT는 MLM을 적용하여 단어 앞뒤 시퀀스를 동시에 보는 완벽한 양방향 모델을 구축하였습니다. 주어진 시퀀스 다음 단어를 맞추는 것에서 벗어나 문장 전체를 모델에 알려주고, MLM 과정을 통해 학습하게 됩니다. 이러한 경우 Mask Token을 제외한 모든 단어를 활용할 수 있게 되면서 순방향과 역방향의 모든 문맥을 한번에 고려할 수 있게 됩니다. 동시에 NSP를 학습하는데, 이는 모델에 두 개의 문장을 입력하여 두 번째로 입력된 문장이 첫 번째 문장 다음에 오는 문장인지 판별하는 과정으로 모델은 문장 간의 관계를 학습하게 됩니다.
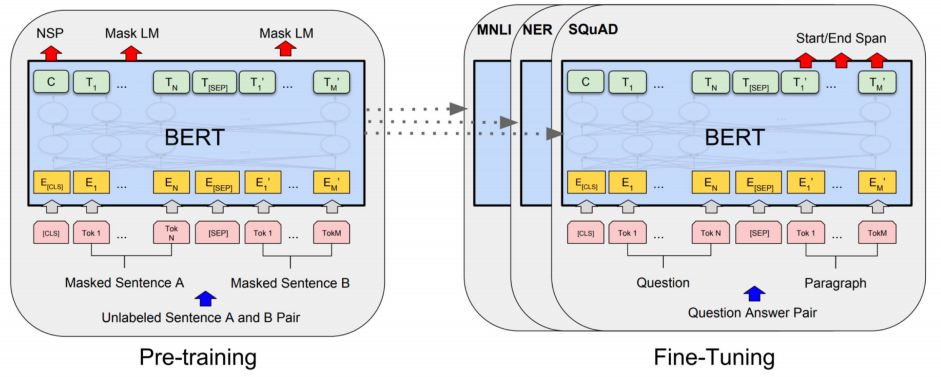 두 번째 단계는 첫 번째 단계에서 사전학습을 마친 모델을 Target Task에 대해 Fine-tuning하는 단계로 Pre-trained model 위에 task에 맞는 classifier를 붙여 학습하게 됩니다.
두 번째 단계는 첫 번째 단계에서 사전학습을 마친 모델을 Target Task에 대해 Fine-tuning하는 단계로 Pre-trained model 위에 task에 맞는 classifier를 붙여 학습하게 됩니다.
Performance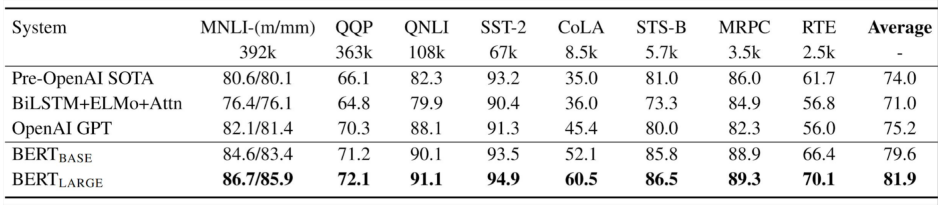
NLP와 관련된 모든 분야에서 SOTA를 기록한 만큼 매우 우수한 성능을 지녔음을 알 수 있습니다.
참고문헌
https://medium.com/analytics-vidhya/contextual-word-embeddings-part1-20d84787c65
http://dsba.korea.ac.kr/seminar/?mod=document&uid=42
https://mhmdsmdi.github.io/posts/2019/07/elmo/
https://omicro03.medium.com/%EC%9E%90%EC%97%B0%EC%96%B4%EC%B2%98%EB%A6%AC-nlp-16%EC%9D%BC%EC%B0%A8-elmo-a22ca5c287c2
https://misconstructed.tistory.com/42
https://brunch.co.kr/@learning/13
http://jalammar.github.io/illustrated-bert/
https://medium.com/@abhisht85/elmo-embedding-3c7bd0df20d2
https://www.kakaobrain.com/blog/118
https://paul-hyun.github.io/bert-01/
이기창 저. 한국어 임베딩

10개의 댓글

투빅스 14기 한유진
- Pre-ELMO는 ELMO와 매우 유사한 구조이고, context 속 의미를 학습하기 어렵다는 문제점을 semi-supervised방법을 적용하여 해결하였습니다. 여기에 모든 문장을 사용하여 contextualized word 벡터학습, 2-layer 양방향 모델이라는 장점이 포함된 ELMO가 등장합니다. 모든 layer의 벡터를 더해 하나의 임베딩 word vector를 생성하여 Syntax, Semantics 정보를 활용합니다.
- NLP에 Transfer Learning이 처음으로 도입된 ULMFit은 3가지 step으로 이루어져 언어 모델을 통해 text classification을 목적으로 합니다.
- Transformer는 Attention을 통해 encoder에서 token sequence를 입력받아 임베딩하고, decoder에서는 출력할 token sequence를 예측하는 구조입니다.
- BERT는 Transformer에서 encoder만 사용한 모델로 MLM을 적용하여 단어 앞뒤 sequence를 동시에 볼 수 있어 전체 단어를 모두 활용하여 단어를 예측할 수 있습니다. 또한, 동시에 문장 간의 관계를 학습하는 NSP도 동시에 학습하게 됩니다.
context를 반영한 다양한 워드임베딩 모델들에 대해서 배울 수 있었던 강의였습니다. 좋은 강의 감사합니다!

투빅스 15기 조준혁
- 컴퓨터는 Word Embedding을 통해 단어를 벡터로 표현함으로써 자연어를 이해합니다.
- Pre-trained word vector는 성능 향상 뿐만 아니라 Unknown word vector, 통칭 UNK Token을 처리하는 데에도 효과적입니다. 일반적으로 train 시 약 5회 이하로 등장하는 단어는 UNK로 처리하며 test시 Out-Of-Vocabulary(OOV) 단어를 UNK로 매칭합니다. 그러나, UNK로 매칭된 단어가 중요한 의미를 지니고 있어도 이를 고려하지 못한다는 문제점이 발생합니다. 이를 해결하기 위해 Character level의 embedding model을 이용한 word vector 생성, 가장 많이 사용되는 Pretrained word vector, 단어가 고유한 정체성을 가지는 효과가 있는 Random vector를 부여하여 vocabulary에 추가하는 방법이 있습니다.
- BERT는 Transformer에서 encoder만 사용한 모델로 크게 2단계가 존재합니다. 첫 번째는 대량의 텍스트 데이터에 대한 semi-supervised 과정인 Pre-training 이고 두 번째 단계는 target task에 대한 supervised 과정인 Fine-Tuning입니다.
문맥을 반영한 Word Embedding과 관련된 Model에 대해 배울 수 있었던 강의였습니다.

투빅스 14기 강재영
맥락을 고려하는 임베딩에 대해 배울 수 있었던 시간이었습니다.
- 컴퓨터는 Word Embedding을 통해 단어를 벡터로 표현함으로써 자연어를 이해합니다. 일반적으로 Pre-trained Word Vector가 task에 쓰이는 labeled 데이터보다 훨씬 더 많은 unlabeled 데이터에 의해 학습되기 때문에 성능향상에 도움이 됩니다.
- Pre-trained Word Vector는 Unknown Word Vector(UNK)를 처리하는데 효과적입니다. 이외에도 UNK를 처리하기 위한 Character level의 Embedding Model을 이용/ Random Vector를 부여 등의 방법이 있습니다.
- RNN은 병렬적 계산이 불가하며 매우 느린 속도를 보이는 한계를 가지고 있었습니다. 이를 해결하기위해 LSTM, GRU가 고안되었지만 완벽하게 해결할 수 없었씁니다. Transformer 기반의 모델은 Attention을 통해 RNN의 한계점을 극복할 수 있도록 고안되었습니다.
- BERT는 구글이 공개한 언어모델로 Transformer에서 Encoder만 사용한 모델입니다. MLM을 통해 단어 앞 뒤 시퀀스를 동시에 고려하는 양방향 모델을 구축할 수 있게 되었습니다. 이는 NLP와 관련한 모든 분야에서 SOTA를 기록할 만큼 우수한 성능을 지녔습니다.

투빅스 15기 조효원
- ELMo의 가장 큰 특징은 모든 문장을 사용하여 Contextualized word vector를 학습한다는 것이다. 또한 Bidirctional 하다는 특징이 있는데, 이는 순방향과 역방향 layer를 각각 추가하는 것으로 구현한다. 즉 Forward LM과 Backward LM의 결과가 합쳐진 것이 ELMo의 결과라고 할 수 있다. 이때 residual connection을 이용하여 input 정보의 특성을 유지한다.
- Transformer는 seq2seq의 구조를 가지는 모델로, rnn 셀들이 아닌 self-attention만으로 구현되었다. self-attention을 사용하여 병렬화가 가능해졌으므로, 8개의 head을 이용해 병렬적으로 어텐션을 계산한다.
- BERT는 Transformer의 Encoder부분을 사용한 모델이다. 크게 두 가지 학습 objective를 가지는데, 하나는 Masking된 단어를 Denoising하는 task이고, 나머지 하나는 Next sentence prediction으로 주어진 두개의 문장이 연속된 문장이 맞는지를 확인하는 task이다.

투빅스 14기 정재윤
-
컴퓨터는 단어를 처리할 때, 단어 그 자체로는 이해할 수 없다. 따라서 word embedding을 통해 단어를 벡터로 표현하여 자연어를 이해한다. 일반적으로는 Pre-trained word vector가 그렇지 않은 vector들보다 훨씬 성능향상에 도움이 된다.
-
대표적인 모델로 ELMo가 있다. ELMo는 이전에 window내의 단어들만 임베딩을 진행했던 것과는 달리 모든 문장을 임베딩하여 context를 보는 방식을 취하는 모델이다.
-
이 후, Transformer가 고안되면서 NLP는 큰 발전을 경험한다. Transformer는 Attention기법을 적용한 방식으로 encoder에서 임베딩하고, decoder에서는 출력할 token sequence를 예측하는 구조이다. 이 Transformer를 적용한 대표적인 모델이 BERT이다. BERT는 Transformer의 Encoder부분만을 사용한 모델로 추후 세미나에서 더 자세한 내용을 다룬다.

투빅스 15기 김동현
- 단어의 의미를 보다 정확하게 표현하기 위해서는 문장의 문맥을 고려하고 반영해야함의 중요성을 언급하고 있으며, pre-trained Model을 사용함으로써 보다 풍부한 의미의 워드 임베딩을 얻을 수 있다.
- pre-trained된 word vector를 사용하는 것은 또한 unk 토큰을 처리할 때 보다 효과적이다. unk 토큰은 보통 데이터 셋에서 잘 나타나지 않는 단어를 일컫거나, test 데이터 셋에만 존재하는 단어를 unk 토큰으로 분류하게 된다.
- Pre-ELMo는 ELMo의 기본적인 구조가 굉장히 유사하며 RNN을 통해 context가 유지되는 word vector를 찾기 위한 가정이 적용되어 있다. 또한 Neural Language Model로 word vector를 pre-trained한 뒤에 추가로 학습이 진행되는 Semi-supervied 접근법이 활용되었다.
- transfer learning이란 대량의 다른 데이터로 일반적인 학습을 진행한 뒤에, 목적에 맞게 다시 튜닝을 통해 성능을 개선해 나가는 것을 의미한다. 여기서 ULMfit은 text classification이라는 목적을 가지게 된다.
- Transformer는 기계 번역을 위해 존재하는 input과 output이 encoder와 decoder로 구분되어 진행되는 seq2seq 모델이다. 이 때, decoder의 어떤 step과 encoder의 전체 step 중 가장 연관성 있는 한 step을 찾아가면서 보다 효과적인 seq2seq 과정을 거치게 된다.
- BERT는 Transformer의 encoder부분을 차용하여 Bi-directional Language Model을 구축한 모델이다.
- 문장에 존재하는 단어 중 일부를 masked 처리한 뒤에, maksed 처리된 단어를 나머지 모든 단어로 예측하는 과정을 말한다. 이렇게 되면 masked된 단어를 제외한 모든 단어를 활용할 수 있게 되면서 순방향과 역방향의 모든 문맥을 한번에 고려할 수 있다.

14기 박준영
- word embedding을 통해 단어를 벡터로 표현한다. (Word2vec, Glove, fastText 등)이 있다.
- train 시 약 5회 이하로 등장하는 단어는 UNK로 처리를 하는데 중요한 의미를 가진 단어를 고려하지 못하는 문제가 있다. 이 문제를 해결하기 위해 character level의 embedding 고려, pre-trained word vector 사용, random vector를 부여하여 vocabulary에 추가 방법이 고려된다.
- 동음이의어를 고려하지 못하는 문제도 있어 contextual word vector가 필요하다.
- contextual를 고려하는 모델로는 Elmo가 있다. ELMO는 모든 문장을 사용하여 contextual word vector를 학습한다.
- raw word vector로 변환되여 bi-lm에 전달되고 residual connection을 통해 단어의 특징을 유지하는 layer별 word vector를 출력하고 raw word vector와 결합하여 Elmo representation을 도출한다.
맥락을 고려한 임베딩 모델들에 대해 배울 수 있었던 강의였습니다. 좋은 강의 갑사합니다!!

투빅스 15기 김재희
기존에는 문맥과 관련이 없이 이미 학습된 임베딩 벡터를 사용했지만, 이번 시간에 배우는 모델들은 맥락에 따른 임베딩 벡터를 생성하는 모델들과 거대 모델을 만들어 다양한 태스크에 transfer learning할 수 있는 모델들이 나왔습니다.
- 도메인마다 단어들은 다른 맥락에서 사용되고, 이를 고려할 필요가 있습니다.
- 이를 위해 문장을 처리하는 모델을 만들고 이를 통해 문장 내 단어들의 벡터를 얻는 TagLM이 나왔습니다. Elmo는 3개 레이어로 되어있고, 낮은 레이어에서는 문법적 정보를, 상위 레이어에서는 문맥적 정보를 가지고 있습니다. 그리고 최종 임베딩 벡터는 3개의 레이어를 가중합하여 구합니다.
- ULMFit은 위키피디아 데이터를 3개 층의 BiLSTM 구조에 학습시켜 만들었습니다. 이러한 사전학습을 통해 적은 수의 도메인 데이터를 가지고도 준수한 성능을 끌어낼 수 있는 transfer learning을 보여줬습니다.
- 이후 모델의 크기를 키운 GPT와 BERT 등의 모델이 개발되었으며, 이 모델들은 모두 트랜스포머의 일부 구조를 가져와 변형한 모델들입니다.
- 트랜스포머는 인코더와 디코더 구조로 내부에 self attention 구조를 통해 효과적으로 병렬 처리를 할 수 있게 되었고, 이를 통해 빠르게 학습합니다.
- bert는 트랜스포머의 인코더만 가져온 모델입니다. MLM과 NSP를 통해 사전학습 시킨 모델입니다.
내용이 정말 많은데 잘 설명해주시고 자료를 잘 정리해두셔서 한눈에 잘 들어왔던 것 같습니다. 감사합니다.

15기 이수민
- word embedding 방법을 통해 단어를 표현합니다.
- unsupervised NN과 supervised NN 방법론과 결합한 방법론은 rule-based보다 성능은 떨어지지만 성장 가능성을 확인할 수 있습니다.
- 동음이의어 혹은 문맥에 따라 단어의 type이 달라지는 측면을 고려하지 못하게 되기 때문에 문제점을 해결하기 위해 Contextual Word Vector의 필요성이 대두됩니다.
- TagLM(Pre-ELMo): Pre-ELMo는 RNN을 통해 Context 속 의미를 학습하기 어렵다는 문제점을 Semi-supervised approach를 적용하여 해결합니다.
- ULMFit 모델은 언어 모델을 통해 Text Classification을 하는 것을 목적으로 합니다.
- Multi-head-attention은 Scaled Dot-Product Attention을 여러 개 만들어 사용하는 방법입니다.
- BERT는 Transformer에서 encoder만 사용한 모델입니다.
투빅스 14기 정세영
단순 단어 임베딩이 아닌 맥락을 고려하는 임베딩 모델이라는 카테고리 안에서 모델들을 바라볼 수 있는 좋은 기회였습니다.