
Abstract & Introduction
- 각각의 얼굴 이미지를 128차원으로 임베딩하여 이미지에 대한 feature를 구한 후 유클리드 공간에서 임베딩 간 거리를 구한다.
- 즉, 각 이미지의 임베딩 결과의 거리를 이미지 간 유사도로 사용하여 Face Recognition과 Clustering을 하는 모델이다.
- 기존 얼굴 인식 접근 방법은 CNN을 사용하여 classification layer를 학습한 후 중간 단계 레이어의 출력값을 사용하였는데, FaceNet은 triplet loss를 통해 임베딩 자체를 다이렉트로 최적화하여 CNN을 훈련한다.
- 임베딩을 계산한 후 다이렉트하게 task를 해결하는데, Face Verification(두 사람이 같냐 다르냐?)은 두 임베딩 사이의 거리에 threshold를 주어 해결하며, Face Recognition(새로 들어온 이 사람이 누구냐?)은 K-NN Classification을, Clustering은 K-means 또는 Agglomerative clustering을 사용하여 해결한다.
Triplet Loss를 이용한 Metric Learning
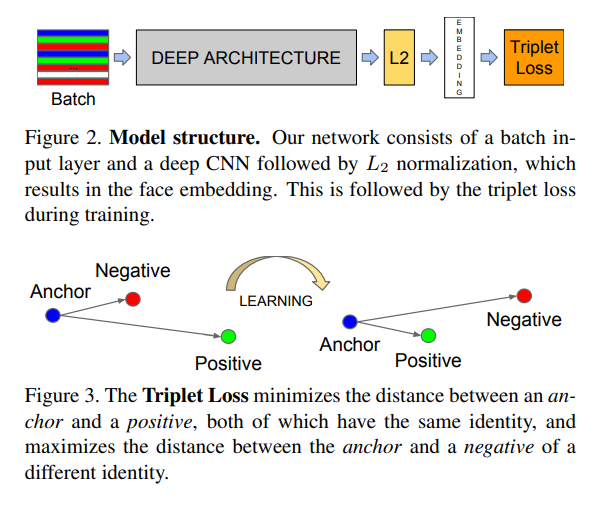
- Anchor(기준 이미지), Positive(기준과 같은 사람 이미지), Negative(기준과 다른 사람 이미지)를 한 쌍의 데이터로 입력 받는다.
- 동일한 네트워크에 위의 3개의 이미지를 인풋으로 받아 각 이미지의 임베딩을 구한다. 여기서 임베딩의 이미지는 이미지의 특징을 잘 담고 있는 임베딩이다.
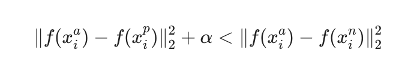
- 위의 식에서 앞의 항은 같은 사람의 두 이미지에 대한 임베딩의 거리를 구한 것이며, 뒤의 항은 다른 두 사람의 이미지의 임베딩의 거리를 구한 것이다.
- 여기서 핵심은 같은 사람의 이미지의 임베딩은 가깝게, 다른 사람의 이미지의 임베딩은 멀게 학습시키는 것이다.
- α는 positive와 negative사이의 margin을 의미한다.
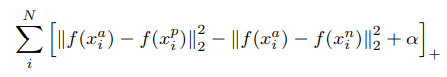
- Loss는 위의 식과 같다. 즉 위의 Loss를 최소화하는 방식으로 네트워크를 훈련시킨다.
Triplet Selection
- Triplet 데이터를 잘 뽑는 것은 매우 중요한데, 많은 triplets가 위의 식을 쉽게 만족할 것이며 이는 학습이 제대로 진행되지 않는다는 문제가 발생한다.
- 이를 해결하기 위해 거리가 최대한 먼 positive (hard positive), 거리가 최대한 가까운 negative (hard negative)를 골라 위의 식을 만족하지 않는 triplet을 만들어야 한다.
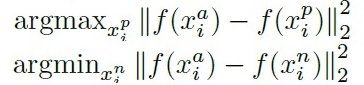
- 전체 데이터셋에서 argmin과 argmax를 계산하는 것은 불가능하다. 또한, 이런 방식은 hard positive, hard negative로 잘못 라벨링된 이미지나 poor한 이미지가 선택될 가능성이 많기 때문에 좋지 않은 학습 과정이 될 수 있다.
- 이를 해결하기 위해 각 사람마다 40개의 이미지를 수집하여 하나의 mini batch에 담는다. Hard postive는 mini batch내의 모든 anchor-positive을 사용하며, hard negative는 아래의 식을 만족시키는 이미지를 선택한다.
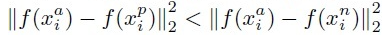
- 위의 식을 만족하여 얻은 negative를 semi-hard라고 부르며, margin α 보다 크지 않은 negative를 선택하는 것이다.
Deep Convolutional Networks
- SGD, AdaGrad, margin α는 0.2를 사용하여 CNN을 학습한다.
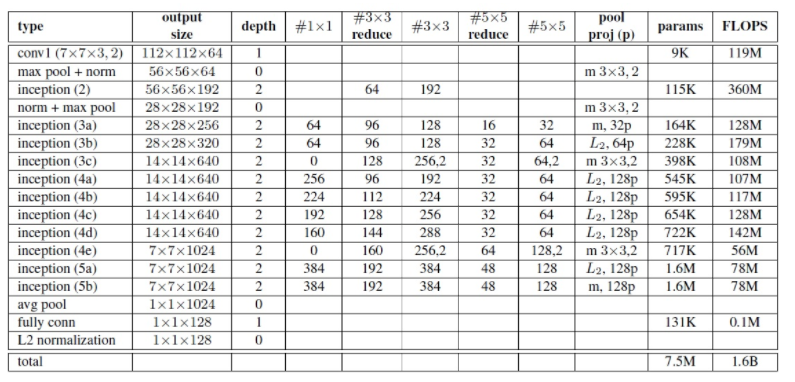
- 두 종류의 네트워크를 사용하였는데, 가장 성능이 잘 나온 네트워크(NN2, Inception 224x224)의 구조는 다음과 같다.
Performance on LFW
- 이미지를 얼굴 크기에 맞게 잘라주는 과정만 했을 때 98.87%의 정확도를 보였고, 추가적인 alignment를 했을 때 99.63%의 정확도를 보였다.
- 다음 이미지는 FaceNet이 잘못 맞춘 이미지이다.

- 사람의 육안으로도 쉽게 구분하기 어려운 이미지이며, 이를 통해 FaceNet의 성능이 꽤나 좋은 것을 확인할 수 있다.
Face Clustering
- FaceNet이 동일 인물을 Clustering한 결과이다.


2021 투빅스 15, 16기 이미지 세미나입니다
3개의 댓글

2021년 11월 23일
16기 전민진입니다.
- FaceNet은 얼굴이미지를 128차원으로 임베딩 한 후, 임베딩 값의 거리를 이미지 간 유사도로 사용해 Face recognition과 Clustering을 하는 모델입니다.
- 기존의 얼굴 인식 모델과 달리 FaceNet은 triplet loss를 통해 임베딩 자체를 다이렉트로 최적화하여 CNN을 훈련합니다.
- 임베딩을 계산한 후 바로 이를 이용해 task를 해결하는데, Face verification은 두 임베딩 사이이 거리에 임계값을 설정해 해결하고, Face recognition은 knn clustering을, clustering은 k-mean 또는 agglomerative clustering을 사용하여 해결합니다.
답글 달기

2021년 11월 30일
16기 김경준입니다.
- 얼굴 이미지로부터 128차원의 특징 벡터를 뽑아 유클리드 공간에서의 거리를 계산하는 모델
- 이 때 3개의 이미지를 받으며 Anchor, Positive, Negative로 구성됩니다.
- Anchor가 기준이 되며 Positive와의 거리는 가깝게 Negative와의 거리는 멀게 학습합니다.
- Positive와의 거리가 Negative와의 거리보다 약간 가까운것보다는 확실하게 차이가 나는 것이 좋으므로 margin 를 더해줍니다.
답글 달기
15기 이윤정입니다.