Neural Style Transfer

What is neural Style Transfer?

- 원본 이미지에 특정 스타일을 입혀 새로운 형태의 이미지를 생성하는 것
- 대표적으로 Pix2pix, CycleGAN 등의 논문들이 있다
What are deep ConvNets learning?

신경망에서 학습하는게 대체 무엇인가?
-> 훈련 세트가 신경망을 거칠 때 각 레이어에서 유닛의 활성값을 최대화하는 이미지를 시각화하자

- 위 그림은 첫번째 은닉층에서 유닛들의 활성화를 최대로하는 이미지를 가져온 모습이다.
- (a)는 좌상단에서 우하단을 향하는 대각선을, (b)에서는 좌하단에서 우상단을 향하는 대각선을, (c)는 왼쪽이 초록색인 세로 모서리, (d)는 주황색을 탐지하는 유닛이라고 볼 수 있다.
- 얕은 레이어에서는 선, 코너 등과 같이 단순한 형태의 이미지를 탐지할 수 있다.

- 레이어가 깊어짐에 따라 탐지할 수 있는 이미지의 수준이 고도화된다.
- 두번째 레이어에서는 여러개의 세로선 혹은 눈과 같은 blob 형태의 이미지들을 확인할 수 있으며 세번째 레이어에서는 차의 바퀴와 같은 객체의 일부를, 마지막 레이어에서는 객체 자체를 인식할 수 있게 된다.
Cost function

- Style Transfer에서의 생성이미지는 Content 와 Style 이 둘 모두와 유사해야 하기 때문에 비용함수도 두 개로 구성된다.
- 가중치 로 두 개의 비용함수의 비중을 조절할 수 있다.
- 생성이미지는 처음에는 랜덤하게 픽셀을 부여하여 노이즈 형태로 나타나지만 와 유사해지도록 학습함으로써 점점 그럴듯한 모양의 이미지를 생성해낸다.
Content cost function
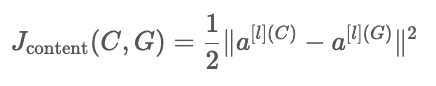
- VGG 등과 같은 사전학습된 ConvNet을 사용하여 생성이미지와 content 이미지의 차이를 최소화하도록 만든다.
- layer 을 이용하여 비용함수를 계산하며, 이 때 은 너무 깊지도 얕지도 않은 layer가 되어야 한다.
- 얕은 레이어에서의 비교로 학습하면 생성 이미지가 content image와 거의 일치하는 픽셀값들을 가질 것이며, 깊은 레이어에서의 비교로 학습하면 생성이미지가 content image와 크게 다를 것이다.
Style cost function
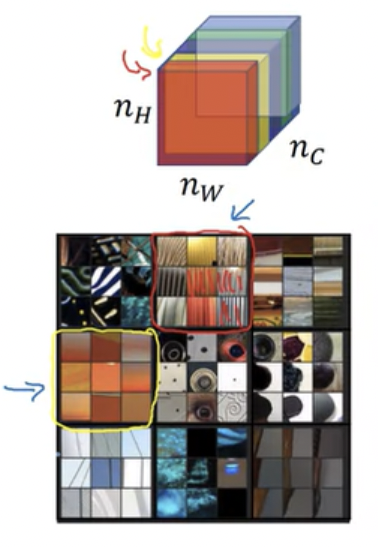
- style이란 각 채널들 사이에 분포하는 활성값들의 상관관계를 의미한다
- 위 그림에서 수직선을 나타내는 채널과 주황색을 나타내는 채널을 비교할 때 상관관계가 높다면 수직선이 있을 때 주황색을 나타냄을 의미하고 상관관계가 낮다면 두 특징은 함께 나타날 필요가 없음을 의미한다.
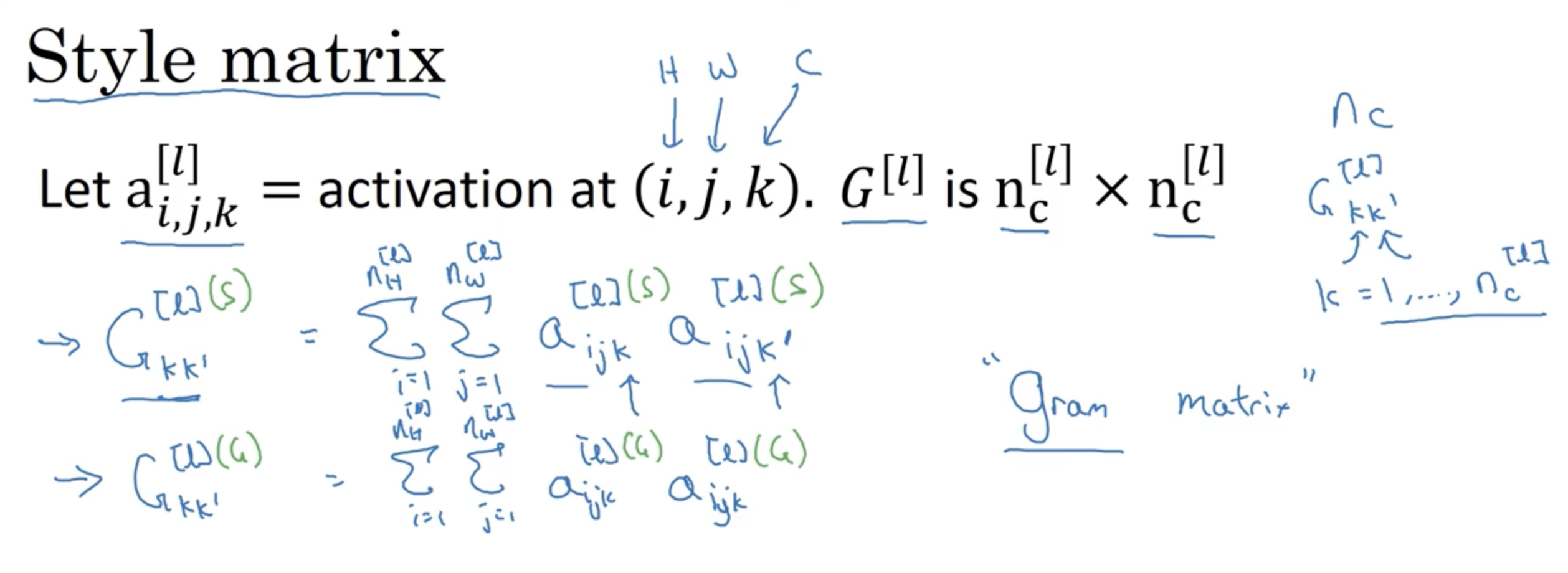
- 위 식은 채널 와 의 상관관계를 의미하며 Gram matrix라고 부른다.
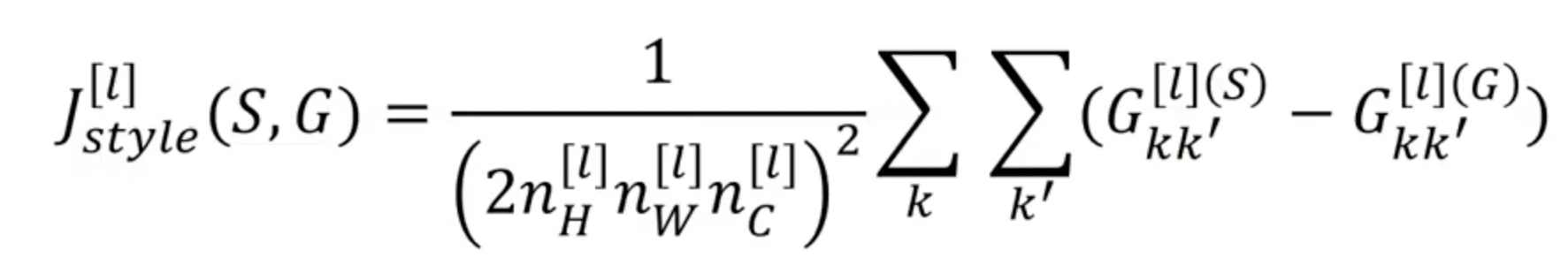
- 최종적인 Style cost function은 위와 같으며 생성이미지와 Style image의 스타일(각 채널 간의 상관관계)의 차이값을 최소화하도록 만든다.
- 이 때, 앞에 붙는 정규화 상수는 Cost function에서 가 곱해지기 때문에 중요하지 않다.
1D and 3D generalization
1D
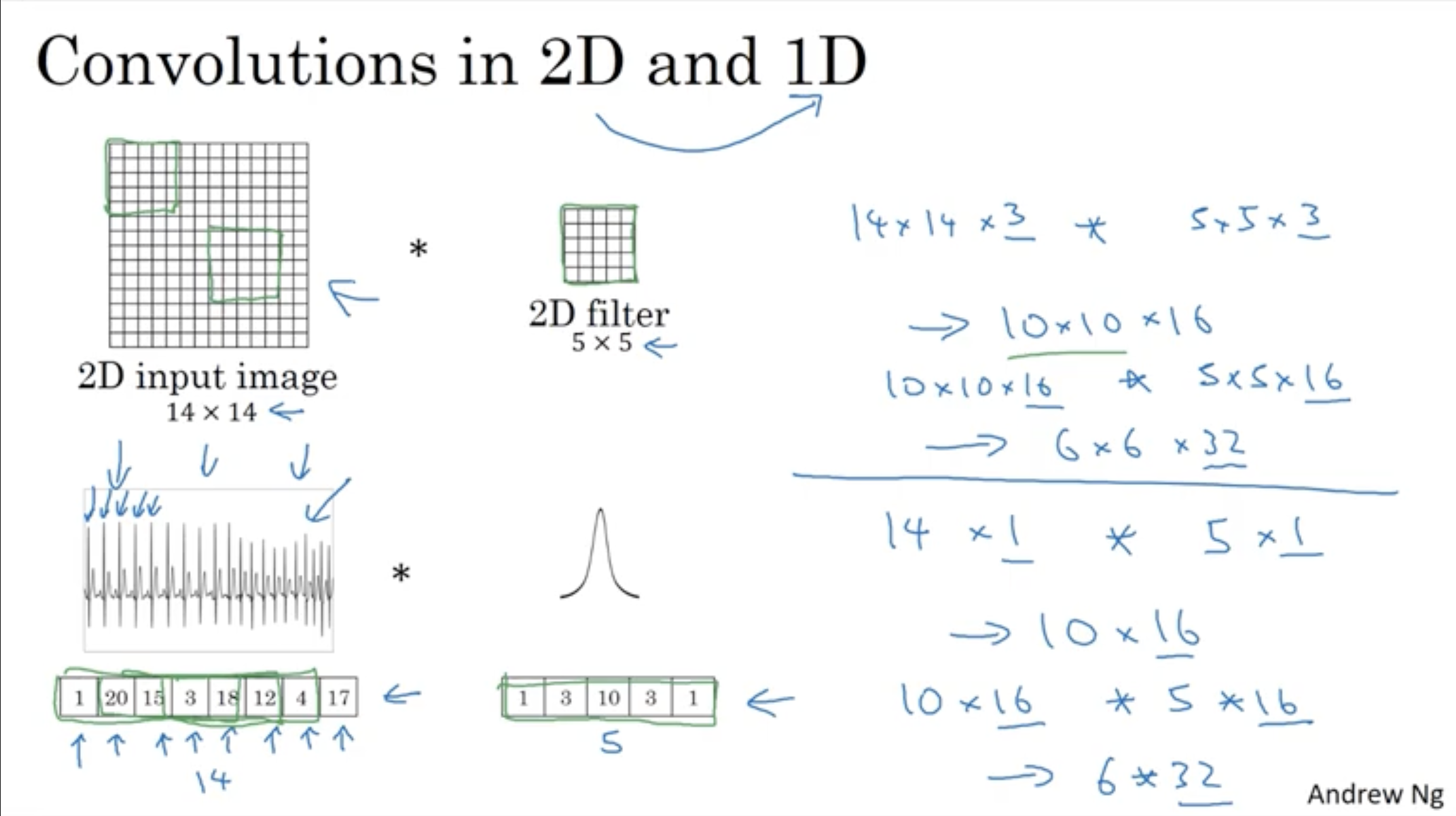
- 1D로의 변환은 단지 너비와 높이가 없이 일렬로 값들이 나열된다는 차이점 뿐이다.
- (14x14x3)의 2D 이미지가 (5x5x3)의 필터를 거쳐 (10x10x16)의 output으로 나오는 연산은 (14x1)의 1D 정보가 (5x1)의 필터를 거쳐 (10x16)의 output으로 나오는 연산과 동일하다.
3D
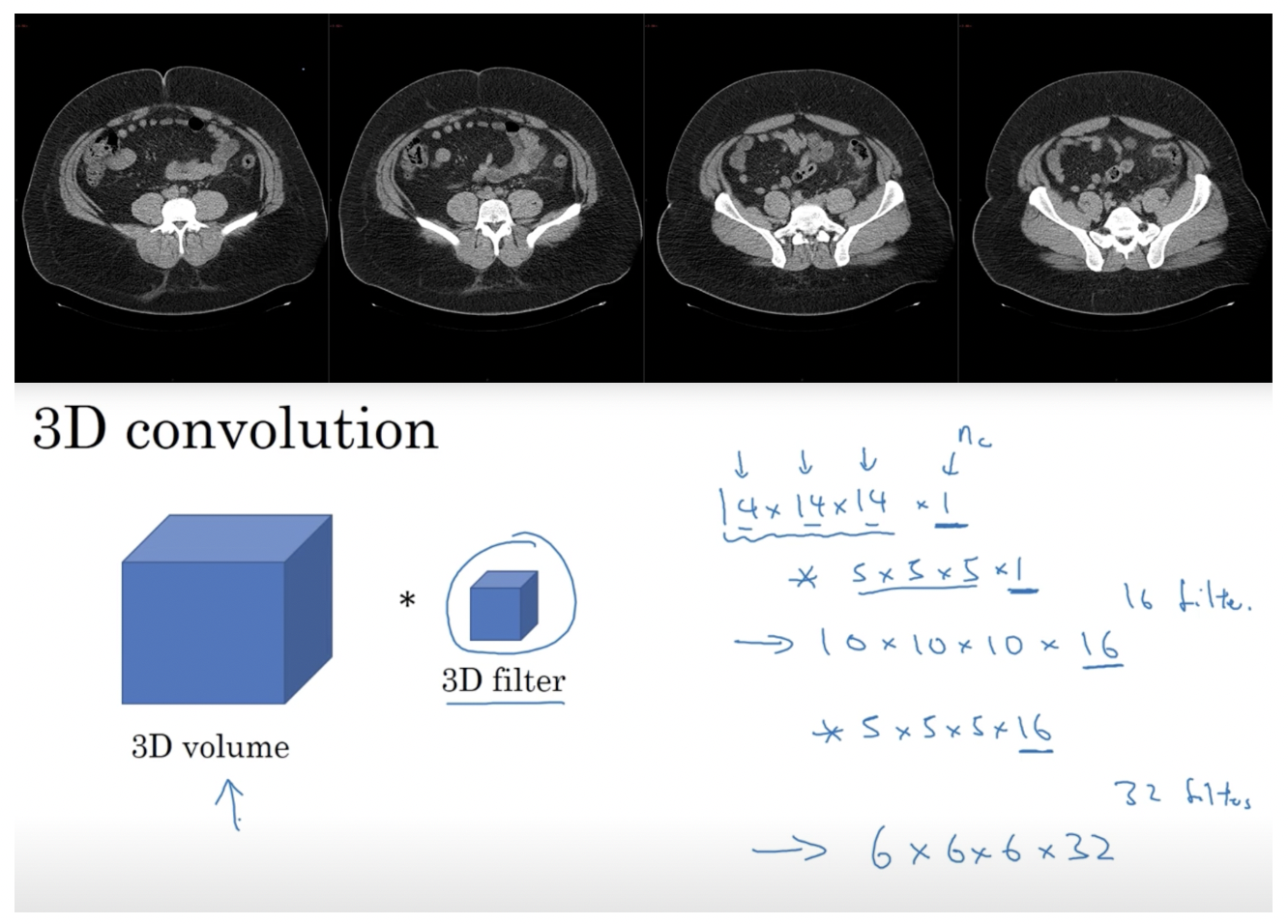
- 3D의 예시로 CT 촬영을 들 수 있다.
- CT는 몸의 각 단면을 스캔하는 것으로 너비, 높이 외에 깊이에 대한 정보가 추가된다.
- 따라서, 필터도 3차원으로 구성되며 (14x14x14x1)의 이미지가 (5x5x5x1)의 필터를 거쳐 (10x10x10x16)의 output을 출력하는 예를 들 수 있다.
Reference

2021 투빅스 15, 16기 이미지 세미나입니다
3개의 댓글

2021년 11월 23일
16기 전민진입니다.
Neural style transfer은 원본 이미지에 특정 스타일을 입혀 새로운 형태의 이미지를 생성하는 것입니다.
훈련세트가 신경망을 거칠 때, 각 레이어에서 유닛의 활성값을 최대화하는 이미지를 시각화해보면,
- 얕은 레이어에서는 선, 코너 등과 같이 단순한 형태의 이미지를 탐지하고
- 레이어가 깊어짐에 따라 탐지할 수 있는 이미지의 수준을 고도화 됩니다.
이를 이용해서 스타일 트랜스퍼의 비용함수를 설정하면, 비용함수는 크게 2개로 구성됩니다
- Content cost function : 사전학습된 ConvNet을 사용하여 각 레이어마다 생성이미지와 Content이미지의 차이를 계산해, 이를 최소화 합니다.
- Style cost function : style이란 각 채널들 사이에 분포하는 활성값들의 상관관계를 의미하는데, 생성 이미지와 style image의 스타일의 차이값을 최소화하도록 만듭니다.
답글 달기

2021년 11월 23일
16기 박한나입니다.
- Neural Style Transfer는 content 이미지에 style을 더해 새로운 이미지를 생성하는 것입니다.
- 신경망의 학습 과정을 시각화하면 앞단 레이어에서는 선, 코너 같이 단순한 형태의 이미지를 탐지하고 깊은 레이어에서는 고도화된 수준의 이미지를 탐지합니다.
- Style transfer의 loss function는 content의 비용함수와 style 비용함수의 합으로 이루어집니다.
- Content cost function은 적절한 레이어 l을 선택하여 해당 레이어에서의 생성 이미지와 content 이미지의 차이를 최소화하도록 만듭니다.
- Style cost function은 생성이미지와 스타일 이미지의 각 채널간의 상관관계의 차이값을 최소화하도록 만듭니다.
답글 달기
15기 이윤정입니다.