CycleGAN: Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks

기존의 GAN
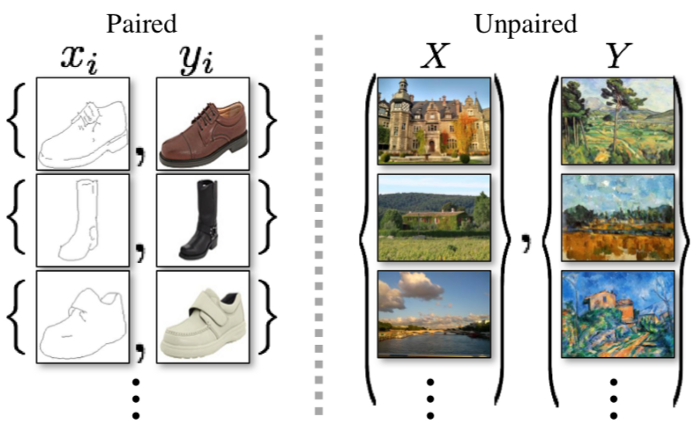
기존의 GAN의 경우 완벽히 한 쌍을 이루는 데이터만을 이용해 학습이 가능하였다. 하지만, 완벽히 같은 조건을 지니는 데이터를 구하기에는 어려운 부분이 존재한다. 이러한 점을 해결한 논문이 바로 CycleGAN이다. 말 그림을 얼룩말 그림으로 바꾸기 위해서는 똑같은 배경의 얼룩말 사진을 학습시켜야 했다면 CycleGAN의 경우 어떤 이미지든 얼룩말이 있는 이미지가 있다면 학습을 시킬 수 있다.
Abstract
Image-To-Image Translation은 pair image를 활용해 input과 output을 매핑하는 것이 목표인 task이다. 하지만 앞서 설명했듯이 완벽히 한 쌍을 이루는 train 이미지를 구하는 일은 쉽지 않기 때문에, CycleGAN은 pair 없이 X라는 도메인으로부터 얻은 이미지를 타깃 도메인 Y로 바꾸는 방법을 활용한다. 즉, 한 이미지 집합의 고유한 특징들을 포착하고 이 특성을 다른 이미지 집합으로 전이시키는 것이다.
해당 논문의 목표는 Adversarial loss를 활용하여, G(X)로부터의 이미지 데이터 분포와 Y로부터의 이미지 데이터 분포를 구분할 수 없도록, G : X → Y를 학습시키는 것이다. 이러한 매핑은 제약이 적으므로 F : Y → X와 같은 역방향 매핑도 동시에 진행했으며, F(G(X))가 X와 유사해지도록 강제하는 cycle consistency loss를 도입했다.
이러한 방법을 적용하여 Cycle GAN을 활용하였을 때, 다음과 같은 결과물을 얻을 수 있었다.

Introduction
CycleGAN은 unpair한 이미지로 학습을 하기 위해, 도메인 간 모종의 관계가 존재한다고 가정하였다. y_hat과 y를 구분하도록 적대적으로 학습된 모델을 사용하여 이미지 y와 구분되지 않는 아웃풋 y hat = G(X)를 산출하는 G : X → Y를 학습시켰다.
다만, 해당 방식의 translation은 각각의 input x와 y가 의미있는 방식으로 짝지어지는 것을 보장하지 않으며, 종종 mode-collapse (어떤 input 이미지든 모두 같은 output 이미지로 매핑하면서 최적화에 실패하는 것)로 이끌곤 한다.
이러한 이슈를 해결하기 위해 tranlsation이 cycle consistent (주기적 일관성)이어야 한다는 속성을 이용하였다. 여기서, 주기적인 일관성은 영어로 된 문장을 불어로 번역했다면 해당 불어 문장을 영어로 번역 시 본래의 영어 문장이 도출되어야 함을 의미한다.
따라서, G와 F를 동시에 학습하고, F(G(X)) ≈ x, G(F(y)) ≈ y이게 만드는 cycle consistency loss를 추가함으로써, cycle consistency loss와 adversarial losses를 X와 Y에 적용된 전체 목적함수가 완성됐다.
Formulation
앞서 언급했듯이 본 논문의 목표는 주어진 도메인 X와 Y를 매핑하는 함수를 학습하는 것이다.
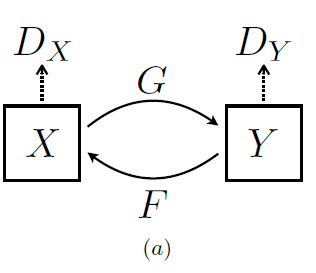
기본적으로 CycleGAN은 2개의 GAN을 필요로 한다. X에서 Y의 이미지를 만들어주는 Generator와 이 이미지가 진짜인지 판단하는 Discriminator, 그리고 반대의 경우까지 고려하기 때문이다.
해당 논문에서 제안하는 모델을 구축하기 위한 Component는 다음과 같다.
- Generator G : X → Y mapping
- Generator F : Y → X mapping
- Discriminator Dy : 실제 도메인 Y의 이미지 y와 G가 생성한 y_hat=G(x)을 구분
- Discriminator Dx : 실제 도메인 X의 이미지 x와 F가 생성한 x_hat=F(y)을 구분
Adversarial Loss
함수 G : X → Y와 Dy에 대해서는 아래와 같은 목적함수를 적용한다.
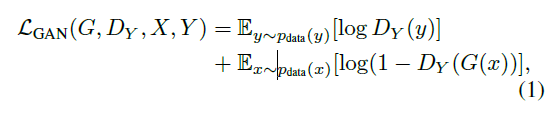
여기서, G는 위의 함수를 최소화를, Dy는 최대화시키고자 하며 이는 다음과 같이 나타낼 수 있다.

마찬가지로, 함수 F : Y → X와 Dx에 대해서도 유사한 adversarial losses를 적용하면 이는 다음과 같이 나타낼 수 있다.

cycle consistency loss
Unpaired data는 각 이미지간의 대응 관계가 너무 많기 때문에 만들어진 이미지가 실제 이미지와 pair라고 확정지을 수 없다. 이는 mapping의 제약이 적다는 것을 의미이며 결국 mode collapse로 이어질 수 있다.
이러한 문제로 인해 Adversarial losses 단독으로는 매핑 함수의 제대로 된 학습을 보장하기 어렵다. 따라서, 가능한 매핑 함수의 공간을 줄이기 위해 아래의 그림 (b), (c)와 같이 매핑 함수는 cycle-consistent 해야 한다.

이러한 행동은 cycle consistency loss를 이용해 유도할 수 있으며, 수식은 다음과 같다. 각각 생성해낸 이미지를 다시 원본으로 복구할때, 원본과 그 복구값과의 거리를 구하는 것이다.

Cycle consistency loss가 유도한 결과는 다음과 같으며, 재건된 이미지 F(G(X))가 input 이미지 x와 유사함을 확인할 수 있다.

Full objective
전체 목적 함수는 다음과 같다.

λ는 두 함수(= 위 식에서의 첫 번째 항과 두 번째 항)의 상대적인 중요도에 따라 결정되며, 본 논문의 풀고자 하는 목표는 다음과 같다.

즉, X → Y GAN의 Adversarial Loss와, Y → X GAN의 Adversarial Loss를 더하고, 각각 다시 원본으로 복구하는 cycle consistency loss 값을 더해준 값이 최종 Loss값이며, 이를 최소화하는 방향으로 G와 F를 학습하는 것이다.
Implementation
Training details
모델 학습 과정을 안정화시키기 위해 두 가지 기술을 적용했다.
-
의 negative log likelihood 함수를 least-squares loss로 대체했다는 점이다. 해당 loss가 학습 과정에서 더욱 안정적이고 좋은 품질의 결과를 도출했다.
-
모델의 진동을 줄이기 위해 discriminator를 최신의 generator가 생성한 하나의 이미지를 이용하기보다는 지금까지 생성된 이미지들을 사용했다는 점이다. 이를 위해 이전에 생성된 이미지 50개를 저장할 수 있는 버퍼를 이용했다.
Result
Evaluation
pix2pix와 같은 데이터 셋과 평가 지표 (metrics)를 사용하여 몇 가지 baseline과 양적, 질적 두 기준 모두로 비교했다. 도시 풍경 데이터셋에서의 semantic label ↔ photo task와 Google map으로부터의 aerial photo(공중사진) ↔ 지도 태스크를 포함하며, loss function에 대한 연구도 진행했다.
Evalution metrics
이때, 사용된 평가 지표는 총 3가지이다.
-
AMT perceptual studies
사람을 대상으로 한 실험으로, 참가자들에게는 실제 사진 혹은 가짜 이미지를 보여준 후 그들이 진짜라고 생각하는 것을 선택하게 했다. -
FCN score
perceptual studies가 얼마나 그래픽이 실제 같은지를 테스트하는 데에 있어서는 매우 좋은 기준이지만, 사람을 대상으로 한 실험이 필요하지 않은 automatic한 양적 기준을 위해 우리는 'FCN score'를 채택했다. -
Semantic segmentation metrics
사진을 라벨링 하는 성능을 평가하기 위해 우리는 per-pixel 정확도(accuracy)와 IOU를 포함하는 기본적인 평가지표를 이용했다.
Comparison against baselines
CoGAN, SimGAN, pix2pix와 같은 다양한 다른 모델과 CycleGAN에게 같은 태스크를 시킨 후, 결과를 비교했을 때의 결과이다.

Application
 다음은 CycleGAN을 통해 pair가 없는 task에 대해 모델을 적용한 결과이다. 이때, 등장한 란 인풋과 아웃풋의 색 구성을 보존하기 위해 추가된 loss로, 그림이 아닌 사진이 인풋으로 들어왔을 때는 사진 자기 자신을 아웃풋으로 산출하도록 generator를 regularize한다. 이를 통해 generator가 종종 낮의 그림을 해질녘의 사진으로 바꾸는 것과 같은 문제를 해결할 수 있다.
다음은 CycleGAN을 통해 pair가 없는 task에 대해 모델을 적용한 결과이다. 이때, 등장한 란 인풋과 아웃풋의 색 구성을 보존하기 위해 추가된 loss로, 그림이 아닌 사진이 인풋으로 들어왔을 때는 사진 자기 자신을 아웃풋으로 산출하도록 generator를 regularize한다. 이를 통해 generator가 종종 낮의 그림을 해질녘의 사진으로 바꾸는 것과 같은 문제를 해결할 수 있다.
Limitations and Discussion
다만, CycleGAN 역시 모든 task에서 긍정적인 결과만을 도출한 것은 아니다.
CycleGAN은 주로 분위기나 색상을 바꾸는 것으로 스타일을 학습하여 다른 이미지를 생성한다. 따라서, 기하학적인 모양을 변경하는 데는 어려움이 있다. 또한, 데이터셋의 분포가 불안정하면 이미지를 제대로 생성할 수 없다.
 다음 그림을 보면, 사과를 오렌지로 바꿀 때 단순히 색상만 변경됨을 확인할 수 있다. 또한, 사람을 태운 말을 얼룩말로 바꿀 때 사람까지 얼룩말로 바뀌었는 데 이는 학습한 데이터에서 사람이 얼룩말을 탄 이미지가 단 1장이었기 때문이다.
다음 그림을 보면, 사과를 오렌지로 바꿀 때 단순히 색상만 변경됨을 확인할 수 있다. 또한, 사람을 태운 말을 얼룩말로 바꿀 때 사람까지 얼룩말로 바뀌었는 데 이는 학습한 데이터에서 사람이 얼룩말을 탄 이미지가 단 1장이었기 때문이다.

3개의 댓글

16기 김경준입니다.
- pair 형태의 데이터가 존재할 때만 학습가능한 pix2pix 등의 모델들을 보완하기 위해 만들어졌습니다.
- G:X->Y를 학습시키기 위한 Adversarial loss와 F: Y->X를 학습시키기 위한 Cycle consistency loss로 구성됩니다.
- G만 학습시킬 경우의 문제점은 어떤 input이 들어오든 같은 output으로 매핍하는 mode collapsing으로 다시 원본 데이터로 돌아갈 수도 있도록 F도 학습시킵니다.
- 따라서, 두 개의 생성자와 판별자로 모델이 구성되며 loss function 또한 두 가지가 존재합니다.
- pair 데이터 없이도 도메인을 바꿔줄 수 있는 효과적인 모델이지만 기하학적인 모양을 변경하는데에 있어서는 한계점이 있습니다.

16기 전민진입니다.
- cycleGAM은 쌍을 이루는 데이터로 학습하지 않고 X에서 얻은 이미지를 타깃 도메인 Y로 바꾸는 방법을 활용합니다.
- 이 모델의 핵심은 생성해낸 이미지를 다시 원본으로 복구 할 수 있도록 만드는 것입니다. 이를 구현하기 위해 2개의 GAN을 사용해 이미지를 생성하고 복구합니다.
- 복구한 이미지와 원래 이미지의 유사성을 높이기 위해 cycle consistency loss를 사용합니다.
16기 박한나입니다.