
object detection을 이해하기 위해선, object localization의 이해가 선행되어야 합니다.
Object localization
What is localization and detection?
- lmage classification은 알고리즘이 주어진 사진을 보고 무엇인지 라벨링
- object localization은 라벨링뿐만 아니라 그 물체의 위치 주변에 경계 상자(bounding box)를 집어넣거나, 빨간 직사각형을 그리는 것까지 포함
- detection은 사진 속에 존재하는 여러 물체들을 모두 감지하고 위치를 알아내는 것이라고 할 수 있습니다.

Classfication with localization
localization은 결과값으로 image label + 경계 상자를 표현하는 4가지 값을 산출합니다.
경계 상자는 다음과 같이 4개의 값으로 표현됩니다.
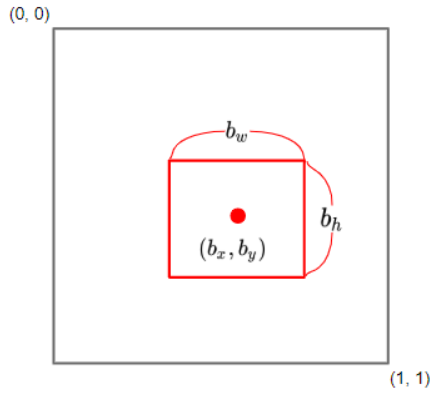
- b_x : 박스의 중심 위치, x 좌표
- b_y : 박스의 중심 위치, y 좌표
- b_h : 전체 이미지에서의 높이의 비중
- b_w : 전체 이미지에서의 길이의 비중
Example)
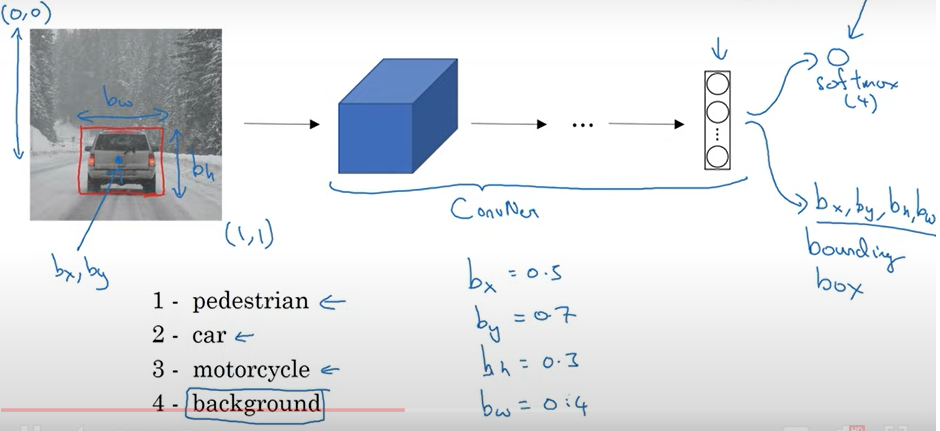
- 현재 사진 속 물체가 자동차이므로, 라벨링 값으로 2 산출.
- 사진의 왼쪽 상단을 (0,0), 오른쪽 하단을 (1,1)이라고 한다면, 자동차가 대략 가운데, 하단 부분에 위치하므로 b_x = 0.3, b_y = 0.7을, 전체 이미지에서 너비가 대략 30%, 폭이 40%를 차지한다고 하면, b_h와 b_w값으로 0.3, 0.4를 산출.
classfication with localization에선 output이 다음과 같은 형식을 지닙니다.

- object probablity(P_c) : 물체의 존재 여부의 확률. 물체가 배경으로 분류될 경우 감지하고자 하는 물체가 없는 것이므로 0으로 표현.
- bouncding box : 경계 상자의 위치
- classes : 0과 1로 구성된 해당하는 object class의 라벨
손실 함수는 물체가 있는지 없는지에 따라서 나뉩니다. 예를 들어 3개의 클래스를 분류하는 문제에서, 제곱오차를 손실 함수로 사용한다면 다음과 같습니다.
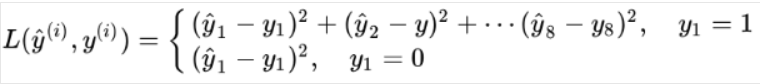
즉, 물체가 있을 경우 모든 요소에 대한 제곱 오차를 더해 손실을 계산하지만, 물체가 없을 경우 p_c항 외의 다른 요소는 무관하므로 p_c에 대한 손실만 계산합니다.
Landmark detection
앞선 예시에서는 자동차의 위치 정보를 표현하기 위해 4가지 값으로 사용했습니다. 하지만 단순히 직사각형으로 물체의 위치를 표현하는 것이 아니라, 사람의 눈꼬리, 입 모양 등과 같이 위치를 좀 더 자세히 인식하고 싶다면 어떻게 할까요?

다음과 같이 핵심이 되는 위치, 특징점의 좌표를 포함하는 라벨링 훈련 세트를 만들어서 모델을 학습시킬 수 있습니다.
- 여러개의 특징점을 포함하는 레이블 훈련 세트를 만들어 신경망으로 하여금 어디에 특징점들이 있는지 말할 수 있게 학습 시킬수 있습니다.
- 다만 훈련 시키려고 하는 모든 이미지에서 사람이 지정한 특징점의 정의는 같아야합니다.(특징점1은 왼쪽 눈꼬리 위치, 특징점2는 오른쪽 눈꼬리 위치, ...)
Object Detection
자동차 인식 알고리즘을 개발한다고 하면 먼저 레이블 훈련 세트를 만들어야 합니다. 이미지 x는 긍정 샘플로, 모두 자동차입니다. 이 훈련 세트로 학습해, 이미지의 대부분이 자동차인지 아닌지에 따라 0 또는 1의 값이 나오게 됩니다. 이 합성공 신경망을 훈련한 후에 이를 슬라이딩 윈도 검출에 사용할 수 있습니다.

Sliding windows detection
- 특정 윈도 크기 설정
- 윈도 사이즈로 잘려진 이미지를 입력값으로 분류 시행
- 윈도를 슬라이드하며 이미지 전체에 대해 시행
- 윈도 크기를 바꿔 1-3의 과정을 반복
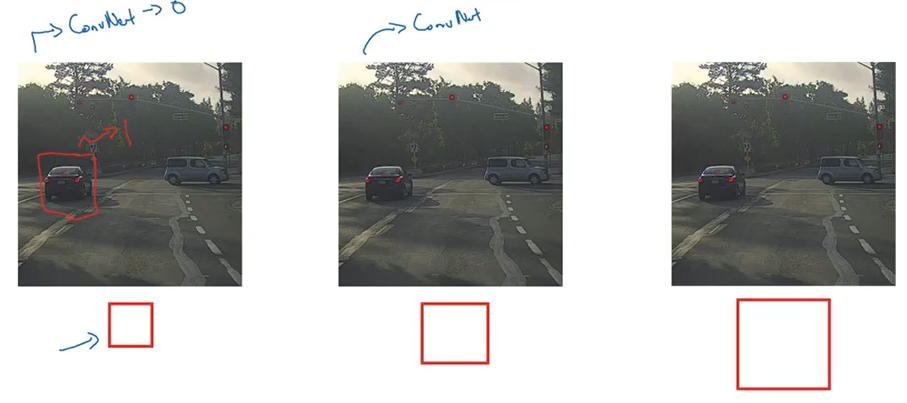
- 이 방법의 단점은 많은 영역을 잘라내어, 이미지의 모든 곳을 한번씩 훑어야하기 때문에 아주 큰 계산 비용이 듭니다.
- 또한, 윈도 크기를 너무 작게하거나, 스트라이드를 늘리게 되면 성능 저하, 즉 정확하게 물체를 못잡아 낼 수도 있습니다.
합성곱을 사용하면 이 방법을 효율적으로 구현해낼 수 있습니다.
Convolutional Implementation Sliding Windows
Turning FC layers convolutional layer
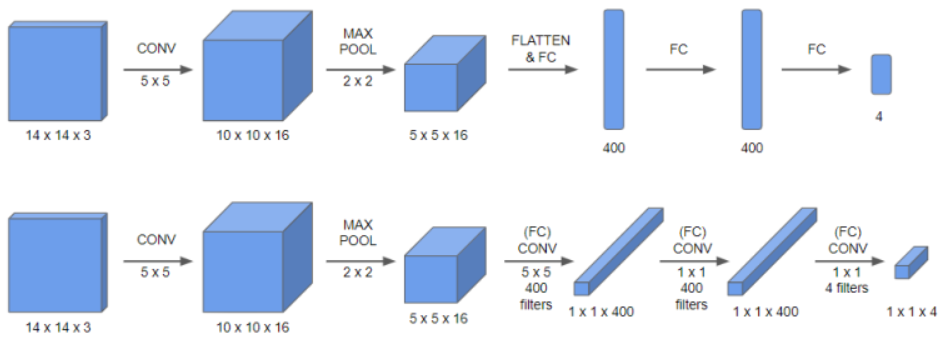 (위가 기존 완전 연결층이고, 아래가 합성곱 완전 연결층)
(위가 기존 완전 연결층이고, 아래가 합성곱 완전 연결층)
- 기존(위) 에 것과 비교하면 합성곱층(아래)은 최대 풀링 이후 모든 차원을 1차원으로 만드는 대신, 합성곱 연산을 하게 됩니다.
- 5 x 5 x 16크기의 feature map에 5 x 5 x 16크기의 필터를 400개 사용하면, 1 x 1 x 400이 됩니다.
- 이는 수학적으로 완전 연결층 연산과 동일합니다. 결과값으로 도출된 400개의 각 값이 5 x 5 x 16 크기의 필터에 대한 임의의 선형함수를 구성하고 활성화함수를 통과하기 때문입니다.
즉, FC layer부분을 convolution을 통해 구현할 수 있습니다.
슬라이딩 윈도 검출에서는 아래와 같이 활용합니다.
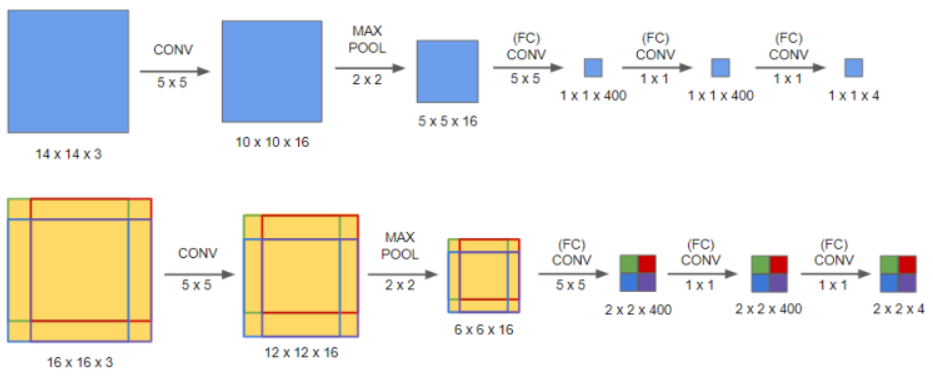
- 4 개의 윈도를 슬라이딩 하면서 검출하게 된다고 예시를 들어봅시다.(단, 1 x 1에서 입체 부분은 생략)
- 합성곱 신경망의 input이 14 x 14 x 3 크기의 이미지라면, 테스트 세트 이미지는 16 x 16 x 3이 됨.
- 마지막을 완전 연결층이 아닌 합성곱층을 사용하면 아래처럼 4개의 윈도에 해당하는 구역이 생깁니다.
- 이는 합성곱층을 4번 통과하지 않고 한 번에 4개의 윈도에 대한 분류를 할 수 있어 계산 비용이 많이 줄어듭니다. 따라서 효율적인 계산을 할 수 있게 됩니다.
하지만, 이 방법도 픽셀 상의 문제로 경계 상자가 물체와 정확하지 일치하지 않는다는 단점이 존재합니다. 이를 해결하기 위해 YOLO(you Onle Look Once)알고리즘을 사용합니다.
Predict Bounding Boxes
우선 훈련 셋을 만들기 위해 output 레이블 y를 정의합니다. YOLO 알고리즘은 두 객체의 중간 점을 취한 다음, 중간 점을 포함하는 영역에 이 객체를 해당하는 것입니다. 그렇게 되면 아래와 같은 사진의 결과 레이블이 나온다. 보라색 레이블은 object가 없는 영역의 결과 행렬이고 초록색 레이블은 object가 있는 영역의 결과 행렬이다.
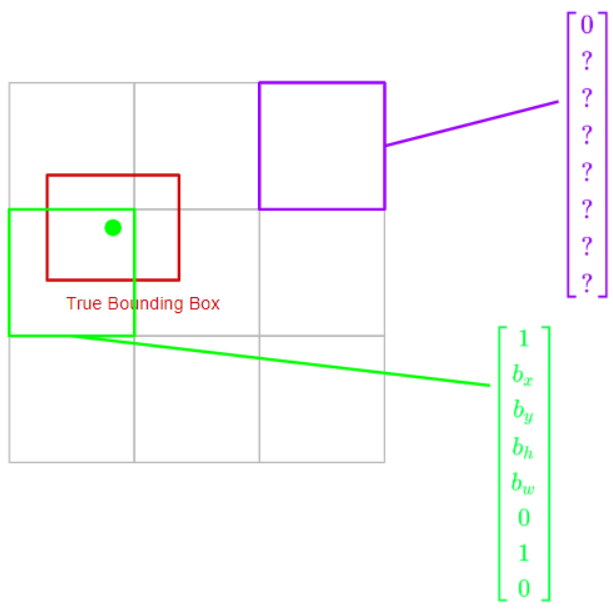
- 각 격자셀에 대해 해당하는 라벨값이 있습니다. 만약에 물체가 격자 셀 내에 존재 하게 된다면 격자 셀 내에서 해당하는 물체의 위치 중심값을 b_x, b_y로 설정하게 됩니다. 만약에 물체가 격자 셀 내에 없다면, 물체의 존재 여부는 0이 되고, 나머지 경계상자 값은 관심이 없으니 임의의 값으로 설정하게 됩니다.
- 따라서 최종적으로 출력은 3 x 3 x 8 크기의 형태입니다. 각 8 차원의 벡터가 격자셀에 맞게 쌓여 있는 모습입니다. 이를 라벨링 된 볼륨과 오차를 구한뒤 역전파를 통해 학습 시키게 됩니다.
- 테스트시 이미지를 넣으면 3 x 3 x 8 형태의 출력을 얻고, 물체 존재 여부가 1인 벡터의 경계상자 값만 불러와서 그리게 됩니다.
- 실제로는 더 큰 격자 셀들을 활용하게 됩니다.
- 경계 상자 값 중 중심값 b_x, b_y은 0과 1사이의 값을 가집니다. 하지만 경계상자의 높이와 넓이 비중은 1보다 클 수도 있습니다.
간단하게 말하자면 객체의 중간 점을 포함하는 그리드 셀 하나에 해당 객체를 할당하는 방법으로 라벨링하면 정확한 object의 bounding box를 얻어낼 수 있다는 것입니다.
이 알고리즘은 그리드 셀 하나에 하나 이하의 객체가 할당될 경우엔 문제가 생기지 않습니다.
Intersection Over Union(IOU)
합집합 위의 교집합(이하 IOU)를 통해서 물체 감지 알고리즘의 평가에 사용 할 수 있습니다.
보라색이 알고리즘이 도출한 경계 상자이고, 빨간색이 참 값의 경계 상자라고 하면, 이는 좋은 결과일까요 나쁜 결과일까요?

IOU는 참 값인 경계 상자(True Bounding Box)와 알고리즘이 도출한 경계 상자(Predicted Bounding Box) 간의 교집합의 크기를 합집합의 크기로 나눈 값입니다. 즉, IOU가 클 수록 우리는 알고리즘이 도출한 경계 상자가 옳다고 판단하게 됩니다.
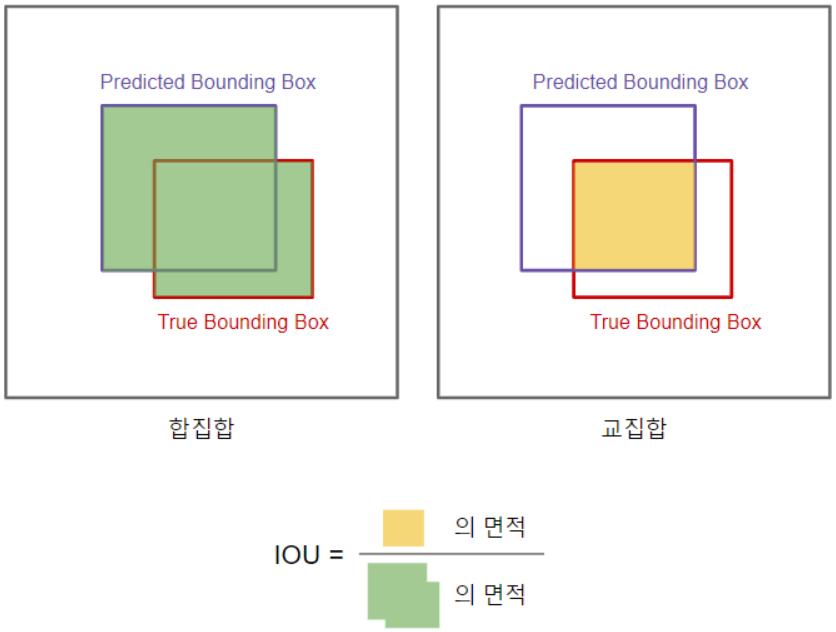
- IOU는 0과 1사이의 값을 가집니다. 즉, 1이 되면 완전 겹치고, 0이 되면 겹치지 않는 것입니다. 이론적 이유는 없지만 보통 관습으로 0.5 보다 크면 맞다고 판단 할 것입니다. IOU가 높을 수록 더 엄격한 기준이라고 할 수 있습니다.
- 이는 localization와 accuracy를 매핑하는 한 가지 방법입니다. 알고리즘이 물체를 올바르게 탐지하고 localization한 횟수를 세면 됩니다. 물체가 맞게 localization 되었는지는 IOU를 사용하면 됩니다.
Non-max Suppression
- 알고리즘이 같은 물체를 여러번 감지하는 경우도 있을 것입니다. 하지만 우리는 하나의 물체는 한번 감지하기를 원합니다. 이를 Non-max Suppression를 통해서 해결할 수 있습니다.
- Non-max Suppression는 알고리즘이 각 물체를 한 번씩만 감지하게 보장합니다.
물체를 감지한 경계상자들 중에서 감지 확률(p_c)이 최대인 상자를 고른 후, 해당 경계 상자와의 IOU를 구해서 높은 IOU를 가진 상자들을 제거(같은 물체를 탐지한 근처 경계 상자들을 제거)하는 방법이 Non-max Suppression입니다.
구체적으로 하나의 물체를 감지하는 예시를 살펴봅시다.
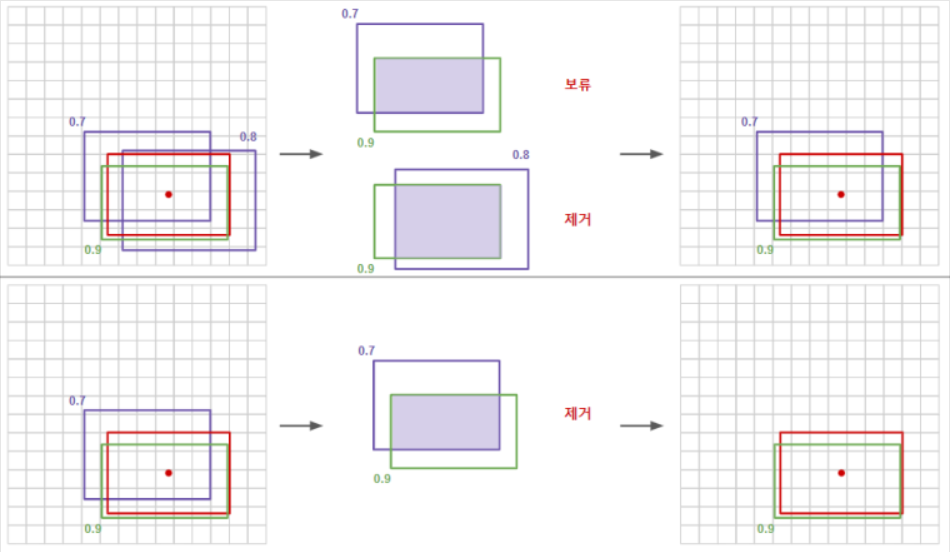
- 감지된 모든 경계 상자중, 감지 확률이 0.6 이하인 경계 상자를 버립니다.
- 감지 확률이 제일 높은 경계상자를 기준으로 잡습니다.
- 해당 상자와 높은 IOU를 가지는 경계 상자를 버립니다.
- 1개가 남을때 까지 2~3 과정을 계속 반복합니다.
즉, Non-max Suppression은 확률의 최댓값을 도출하고, 최댓값의 아닌 것들은 억제한다는 의미입니다.
만약에 2개 이상의 클래스가 있을 경우, 각 클래스에 대해 독립적으로 Non-max Suppression를 해야합니다.
Anchor Boxes
- 현재까지 배운 물체 감지 알고리즘의 최대 단점은 각각의 격자 셀이 오직 하나의 물체만 감지 할 수밖에 없다는 것입니다(예를 들어, 구름과 해가 겹쳐져 있는 경우, 해당 격자 셀은 둘 중 하나만 예측 했을 것). 이를 해결하기 위해 앵커 박스를 사용합니다.
- 경계 박스를 직접적으로 예측 하는 대신 미리 크기가 정해진 앵커 박스를 여러 개 만들어 사용합니다.
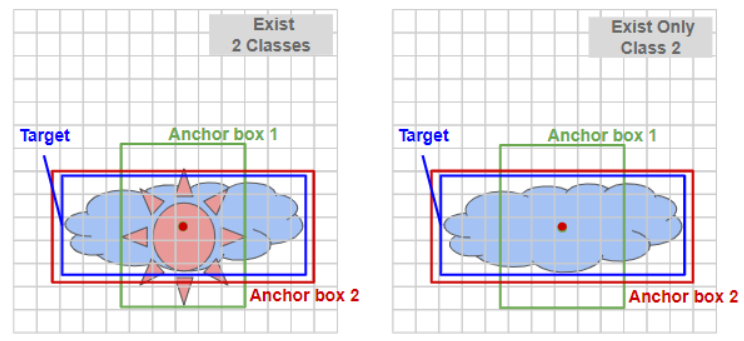
- 이전에는 각 격자셀에서 해당 물체에 대한 결과값(물체의 존재 여부, 중심점, 경계 상자 값 그리고 클래스)이 존재했지만, 앵커 박스를 사용하게 되면 앵커 박스의 개수만큼 결과값이 늘어나야 합니다.
- 아래 두 가지 예시를 보겠습니다. 물체가 겹쳐있는 경우(좌측)와 하나만 있는 경우(우측) 을 살펴보면, 결과값이 이전에 비해 늘어난걸 알 수 있습니다.
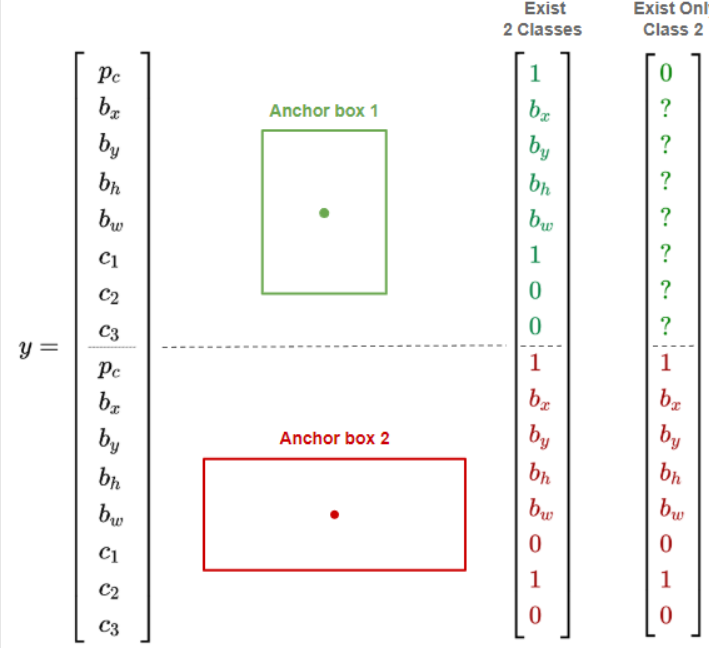
- 위쪽 8개 요소가 앵커 박스 1에 대한 것이고, 아래쪽 8개 요소가 앵커 박스 2에 대한 것입니다.
- 두 물체 다 존재하는 경우 (좌측) 두 앵커박스에 해당물체의 존재여부 값은 1이 되며, 각각의 중심값, 경계 상자값, 클래스 값이 존재하게 됩니다.
- 하나의 물체 (우측) 만 존재하는 경우의 이미지는 첫번째 앵커박스에 해당 물체의 존재 여부 값이 0이 되고, 나머지 앵커 1에 해당되는 값들은 임의로 되어도 상관 없습니다.
- 앵커박스는 사람이 정할 수도 있고 자동으로 정하는 알고리즘도 있습니다.
- 다만 사전에 정한 앵커 박스의 수 보다 하나의 셀에 겹치는 물체의 수가 많을 경우 앵커 박스의 수만큼만 물체를 인식할 수 있다는 단점이 존재합니다.
- 또한, 두 물체가 같은 셀에 존재하고, 같은 앵커 박스를 갖는 경우 역시 제대로 인식하지 못합니다.
- 하지만 격자가 작으면 작을수록, 두 물체가 같은 중심점을 가질 확률은 낮습니다.
YOLO algorithm
지금까지 배운 내용으로 YOLO 물체 감지 알고리즘을 구성해봅시다.
3개의 물체를 검출하는 알고리즘을 훈련시킨다고 생각해봅시다.
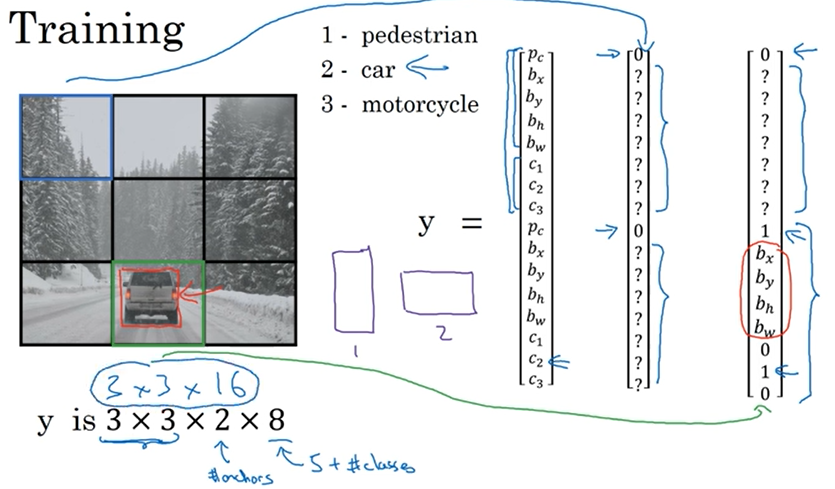
- 우선 y값의 크기는 격자 셀이 3x3, 앵커 박스가 2개, 클래스가 3개이므로 3 x 3 x 2 x 8이 됩니다.
- 파란색 격자의 y값을 보면, 앵커 박스1과 2에서 물체를 인식하지 못했기 때문에 p_c값이 0이 됩니다.
- 초록색 격자의 y값을 보면, 자동차를 인식할 수 있는데 이 자동차는 앵커 박스 2와 좀 더 유사하다고 생각하면 위쪽의 p_c값은 0, 아래의 p_c값은 1이 됩니다.
YOLO 물체 감지 알고리즘은 다음과 같은 순서로 진행됩니다.
- 각각의 격자 셀에 대하여, 경계 상자를 도출합니다.
(앵커 박스의 수만큼 경계 상자가 도출됨.)

- 낮은 확률의 경계 상자를 제거합니다.

- 각각의 class(보행자, 자동차, 오토바이 등)에 대해 non-max suppression을 이용하여 최종 결과를 도출합니다.

Region Proposal : R-CNN
sliding window 아이디어를 생각해보면, 물체가 있든 없든 이미지의 모든 영역에 대해 물체 감지를 실행합니다. 이러한 알고리즘의 하나의 약점은 명확하게 물체가 없는 많은 지역들을 감지한다는 것입니다.
그래서 R-CNN을 사용하여 component classifier를 실행할 몇 개의 지역만을 고른다.

segmentation algorithm을 이용하여 영역을 분할하고, 해당 영역의 경계 상자에 대해서만 분류기를 실행한다.
R-CNN에서 "물체가 있을 법한" 영역을 찾는 방법 : Selective search
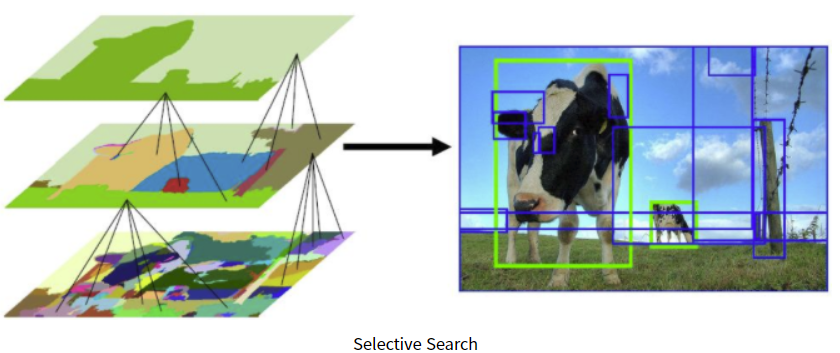
-
색상, 질감, 영역크기 등.. 을 이용해 non-object-based segmentation을 수행한다. 이 작업을 통해 좌측 제일 하단 그림과 같이 많은 small segmented areas들을 얻을 수 있다.
-
Bottom-up 방식으로 small segmented areas들을 합쳐서 더 큰 segmented areas들을 만든다.
-
(2)작업을 반복하여 최종적으로 2000개의 region proposal을 생성한다.
이 과정을 pseudo code로 살펴보면 다음과 같습니다.

R : 선택된 초기 영역들
S : 영역들간의 유사도 집합
각각의 영역들에 대한 유사도 초기화
While(반복)
1. 가장 유사도가 높은 영역 i,와 j 선택
2. 선택된 영역을 t로 병합
3. i와 j가 연관된 다른 유사도 집합들은 제거
4. 병합된 t영역과 나머지 영역들간의 유사도 재정의
5. 새로운 유사도 집합에 합쳐진 영역을 추가 포함
6. 하나의 영역이 될때 까지 반복
** 유사도 측정방법
[0,1] 사이로 정규화된 4가지 요소(색상, 재질, 크기, 채움-Fill)들의 가중합으로 계산합니다.
Faster algorithms
R-CNN은 아직 꽤 느리기 때문에 이 알고리즘의 속도를 높이기 위한 여러 알고리즘이 있습니다.
- R-CNN : 어떤 알고리즘을 통해 지역을 제안하고 분류합니다. 각각의 지역은 결과값으로 label과 bounding box를 도출합니다.
- Fast R-CNN : 기본적인 R-CNN 알고리즘에 합성곱 슬라이딩 윈도 구현을 더한 것. 원래 R-CNN은 한 번에 하나의 지역을 분류하지만, fast R-CNN에서는 합성곱 슬라이딩 윈도를 통해 모든 지역을 한 번에 분류할 수 있습니다. 하지만, 여전히 지역 제안을 위한 클러스터링 단계가 느리다는 단점이 있습니다.
- Faster R-CNN : 지역과 영역들을 제안하는 데에 분할 알고리즘 대신 신경망을 사용해 fast R-CNN보다 조금 더 빠릅니다. 하지만 YOLO보단 느립니다.
Mask-CNN

3개의 댓글

15기 이윤정입니다.
- localization은 라벨링 뿐만 아니라, 바운딩 박스를 표현하는 값까지 산출한다.
- Sliding windows detection의 경우 계산 비용이 많이 들며, window의 크기에 따라 정확도가 달라진다는 단점을 지닌다. 이에 컨볼루션 필터를 슬라이딩하는 방법을 사용하면 효율적인 계산을 할 수 있다. 다만, 해당 방법 역시 바운딩 박스가 물체와 정확히 일치하지 않는다는 한계를 지닌다.
- yolo 알고리즘의 경우 객체의 중간 점을 포함하는 그리드 셀 하나에 해당 객체를 할당하는 방식으로 라벨링하여, 정확한 object의 bounding box를 얻는다.
- IOU는 실제 바운딩 박스와 알고리즘이 도출한 바운딩 박스 간의 교집합의 크기를 합집합의 크기로 나눈 값으로 해당 값이 클 수록 알고리즘의 바운딩 박스가 옳다.
- 앵커 박스의 경우 이전까지 각각의 그리드 셀이 하나의 물체만 감지한 것과 달리 겹쳐있는 물체에 대해서도 감지할 수 있다.
- R-CNN의 경우 segmentation algorithm을 이용하여 영역을 분할하고, 해당 영역의 경계 상자에 대해 분류기를 실행한다.
16기 김경준입니다.