SSD: Single Shot MultiBox Detector

Introduction
- 기존 연구들은 bouding box들을 뽑아내고 특징을 추출한 뒤 classifier를 거치는 과정을 거쳤다.
- 하지만 이러한 과정들은 연산량이 매우 크며, 실시간으로 응용하기에는 느리다는 단점이 있다.
- 본 논문에서는 속도를 크게 개선하며 정확도 또한 유지하는 네트워크를 제안한다.
<SSD의 특징>
- classification과 localization을 위해 작은 컨볼루션 필터를 사용한다.
- 각기 다른 비율을 가진 객체들을 검출하기 위해 구별된 필터를 사용한다.
- 다양한 크기의 객체들을 검출하기 위해 여러 feature map으로부터 위의 필터를 이용하여 output을 도출한다.
(VOC2007 데이터셋으로 test한 결과 59FPS/74.3% mAP로 7FPS/74.3% mAP인 Faster-RCNN과 45FPS/63.4% mAP인 YOLO에 비해 높은 성능)
Model

Base network로 VGG16을 활용하였다. 3개의 FC layer 중 2개만 Convolution layer로 대체하여 사용하였으며 뒤에 auxiliary structure를 덧붙였다. 추가된 레이어를 살펴보면 개의 채널을 가진 m x n feature map에 의 필터를 적용하여 class score와 좌표값을 예측할 수 있다.
자세히 보면 다음과 같다.

Pascal 데이터셋을 예로 설명하면,
3x3x(bouding box의 개수x(Class의 개수+좌표값(x,y,w,h))) = 3x3x(6x(21+4))가 Classifier가 된다. 결과는 그림의 우측과 같이 각 bounding box별로 좌표값과 class score가 나오는 것을 볼 수 있다.
SSD에서는 클래스 별로 8732개의 bounding box가 나오게 되는데 도출 과정은 다음과 같다.
- conv4_3로부터 38x38x(4x(Classes+4)) = 5776x(Classes+4)
- conv7로부터 19x19x(6x(Classes+4)) = 2166x(Classes+4)
- conv8_2로부터 10x10x(6x(Classes+4)) = 600x(Classes+4)
- conv9_2로부터 5x5x(6x(Classes+4)) = 150x(Classes+4)
- conv10_2로부터 3x3x(4x(Classes+4)) = 36x(Classes+4)
- conv11_2로부터 1x1x(4x(Classes+4)) = 4x(Classes+4)
-> 8732x(Classes+4)
Default boxes & Aspect ratio
모델에서 볼 수 있듯이 Default boxes는 feature map에 따라 4개 혹은 6개가 만들어진다. 이 때 생성되는 박스들은 각각 다른 비율을 가지며 Default box라고 부른다. Fater-RCNN의 anchor box와 유사한 개념이지만 서로 다른 feature map에 적용한다는 점에서 다르다.

-
, , (feature map의 개수)으로 에 따라 1~6이 대입되어(일 때 일 때 ) 각 feature map마다 다른 scale()을 가지게 된다.
-
비율은 에 의해 정해진다. 예를 들어 인 경우 는 2:1의 비율을 가진다.
-
6개의 bounding boxes를 뽑을 때는 의 5개 원소를 모두 사용하며, 추가적으로 더 작은 크기의 1:1 비율인 가 사용된다. 4개를 뽑을 때는 3과 1/3이 제외된다.

위 그림이 Default boxes에 대한 설명을 직관적으로 보여준다.
- 작은 객체(고양이)는 resolution이 큰 feature map(8x8)에 의해 인식이 되며 큰 객체(강아지)는 resolution이 작은 feature map(4x4)에 의해 인식이 됨을 알 수 있다.
- 1부터 6까지의 k의 값을 대입했을 때 = [0.2, 0.34, 0.48, 0.62, 0.76, 0.9]가 되는데 이 값이 default box의 크기를 결정하는 input image와의 비율임을 생각하면 그림과 맞아떨어짐을 다시 한 번 이해할 수 있다.
- 300픽셀 이미지의 0.2는 60픽셀로 작은 default box이므로 세밀한 정보를 잡아내는 큰 feature map에서 사용되며 반대로 0.9일 경우에는 default box의 크기가 270이므로 작은 feature map에서 사용된다.
Matching strategy
학습을 하기 위해서는 수많은 default box들이 각각 어떤 Ground Truth box에 대응되는지 매칭해주는 과정이 필요하다. 이 때 GT와의 IOU를 활용하며 0.5 이상인 박스들을 전부 positive로 분류한다. 반대로 IOU가 0.5 미만인 박스들은 배경이라고 생각을 하여 negative로 분류한다.
Loss function

SSD의 loss function은 classification loss와 localization loss 합으로 이루어져있다. 는 둘의 가중치를 조절하는 값으로 디폴트 값은 1이다.
- : 과 의 IOU가 0.5 이상인 박스의 수
- : default box
- : 클래스
- : bbox의 좌표
- : GT의 좌표
Localization Loss
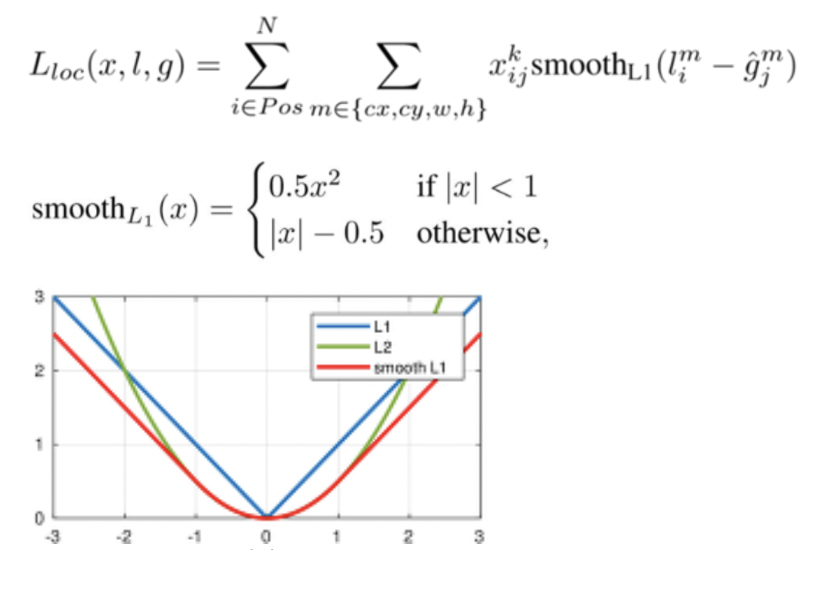
- : 클래스에 대해 번째 default box와 번째 GT가 매칭되면(IOU>=0.5) 1, 아니면 0. 즉, 매칭된 박스에 대해서만 localization loss를 계산한다.
- 은 예측
- Default box에서 좌표(cx,cy,w,h)의 조정값을 빼주어 smooth L1 loss를 구한다.
- 4개의 값에 대해 오차를 구하기 때문에 커질 수 밖에 없는 값을 줄여주는 효과가 있으며 L1 Loss는 미분 불가능한 지점이 있어 역전파할 때 문제가 있어 smooth L1 loss를 사용한다.
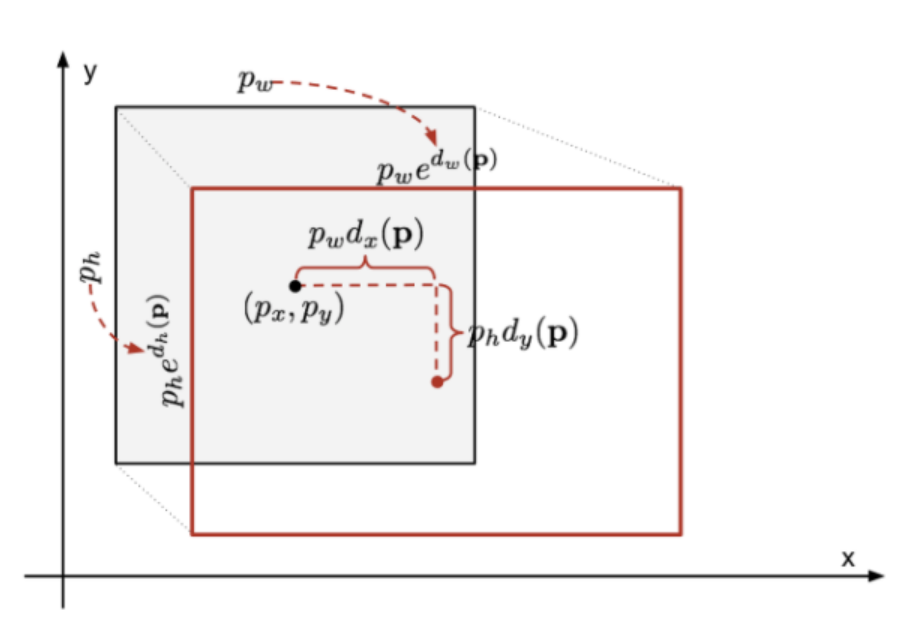
Default box는 localization loss를 통해 좌표값이 세밀하게 조정되며 수식은 다음과 같다.
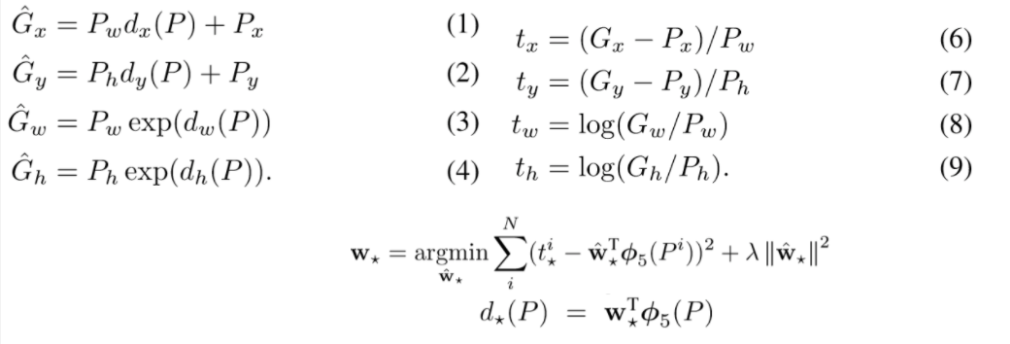
는 각각 좌표(위치), width(너비), height(높이)를 의미하며, 는 Default box, 는 Ground Truth(실제값)이다.
아래의 식에서는
: CNN에서 학습된 에 해당하는 특징 벡터
: 특징벡터를 4차원 벡터로 만들어주는 Linear layer의 학습되는 가중치
: regularization을 위한 상수
를 통해 라는 transformation 함수를 정의할 수 있으면 를 추정할 수 있다.
(1),(2),(3),(4)의 은 와 최대한 가까워질 추정량을 의미하므로 이 식을 변형시킨 (6),(7),(8),(9)의
(의 치환)는 최종적으로 결정되는 함수라고 할 수 있다.
따라서, 와 의 차이를 최소화시켜주는 loss function이 적용되어 Bounding Box의 위치, 크기가 조정된다.
Confidence Loss

Confidence Loss는 매칭된 박스와 매칭되지 않은 박스에 대해 모두 cross entropy loss를 구한다.
Hard Negative Minining
SSD의 default box는 8000여개나 되지만 실질적으로 우리가 인식하고자 하는 객체의 수는 10개도 안 되는 경우가 일반적이므로 대부분의 box들은 배경을 나타낸다. 따라서 배경 클래스에 대한 데이터만 과도하게 많은 imbalance 문제가 발생한다. 이를 해결하기 위해 SSD에서는 loss가 높은(background인데 background class라 판단하는 확률이 작은) 데이터만 sorting하여 positive data의 3배만 사용하는 기법을 쓴다.
Results

결과 중에 눈에 띄었던 것은 작은 물체에 대한 성능이 유독 떨어진다는 것인데 추후에 나온 분석으로는 작은 물체를 첫 feature map에서 detect하기 때문이라고 한다. 이를 보완하기 위해 RetinaNet에서는 왕복하는 방식을 통해 작은 물체에 대한 성능을 높였다.
SSD에서는 augmentation을 통해 이와 같은 문제를 개선하였다. Random crop을 통해 "zoom in"하여 더 큰 객체의 데이터를 만들기도 하고 반대로 "zoom out"한 후 남는 공간은 평균 픽셀값으로 채워 작은 객체의 데이터를 만들기도 하였다. 그 외에도 randomly sample patch, horizontally flipped 등의 방법이 활용된다.
References

3개의 댓글

15기 이윤정입니다.
- SSD는 다른 비율은 지닌 객체를 검출하기 위해 다양한 필터를 사용한다.
- base network로 VGG16을 사용했으며, 추가된 레이어를 통해 m x n feature map에 필터를 적용하여 각 bounding box별로 class score와 좌표 값을 예측할 수 있다.
- default box들은 GT와의 IOU를 활용하여, Ground Truth box와 매칭되는 과정을 거친다. (0.5 이상인 박스는 positive, 0.5 미만인 박스들은 배경이라고 간주하여 negative로 분류)
- SSD의 loss function은 classification loss와 localization loss 합으로 이루어지며, localization loss의 경우 매칭된 박스에 대하여 계산한다.
- default box는 8000여 개인 반면, 인식하고자 하는 object의 수는 소수이다. 따라서, 대부분의 box는 배경을 나타내며 이로 인해 class imbalance 문제가 발생한다. SSD는 loss가 높은 데이터만 sorting하여 positive data의 3배만 사용하는 기법을 적용한다. (loss가 높다면 background인데 background class라 판단하는 확률이 작은 경우이기 때문 = object)
- SSD는 작은 물체를 첫 feature map에서 detect하기 때문에 작은 물체에 대한 성능이 유독 떨어지는 결과를 개선하기 위해 data augmentation을 적용했다.
안녕하세요 16기 전민진입니다.
SSD의 특징
==> 기존 모델 대비 비교적 빠른 속도로, 높은 성능을 보임.
모델 구조
base network로 VGG16을 활용. 3개의 FC layer중 2개만 Conv layer로 대체하여 사용, 뒤에 auxiliary structure를 덧붙임.
추가된 레이어를 살펴보면, mxn의 feature map에 필터를 적용하여, class score와 좌표값을 예측한다.
즉, 6개의 각기 다른 크기의 feature map에서 각각 4 또는 6개의 bounding box를 사용하므로, 클래스 별로 총 8732개의 bounding box가 나오게 된다.
**여기서 사용하는 default box는 feature map에 따라 4 또는 6개가 만들어지는데, anchor박스와 다른 점은 서로 다른 feature map에 적용한다는 점이다.
loss function은 classification loss와 localization loss의 합으로 이뤄져 있는데, localization loss는 매칭된 박스에 대해서만 오차에 대해 학습을 하는 것이고, confidence loss는 매칭된 박스와 매칭되지 않은 박스에 대해 모두 cross entropy loss를 구하는 것이다.