
작성자 : 투빅스 16기 이승주
Contents
1. Reflections on word representations
2. Pre-ELMo and ELMO
3. ULMFit and onward
4. Transformer architectures
5. BERT
Reflections on word representations
pretrained model를 사용하면 더 많은 단어와 더 많은 데이터에 대해 학습이 가능해지기 때문에 보다 풍부한 의미의 워드 임베딩을 얻을 수 있고 실제로 성능도 더 높은 것으로 보인다.
단어를 표현한다라는 것은 Word Embedding을 통해 단어를 벡터로 표현하고 컴퓨터가 이해할 수 있도록 자연어를 적절히 변환한다라는 의미이다. word vector 모델로는 Word2vec, GloVe, fastText 등이있다. Pre-trained word vector model 이 배운 Voabulary 에 대해서 각 단어마다 매칭되는 word vector 가 있고, index를 사용해서 필요한 단어의 word vector 를 불러올 수 있다.
Usefulness of Pre-trained word vector
Pre-trained word vector은 성능 향상에 도움이 되며 Unknown word vector(UNK Token) 처리 시에도 효과적이다. 학습 시, 잘 등장하지 않는 (일반적으로 5회 이하 등장) 단어는 UNK 토큰 처리한다. Test 시, Out-Of-Vocabulary(OOV) 단어를 UNK로 매칭한다.
문제는 UNK로 매칭된 단어가 중요한 뜻을 지닐 수 있는데 놓칠 수 있다는 점이다.
UNK 토큰 처리 솔루션
1. Char level embedding model을 이용하여 word vector 생성
2. Pre-trained word vector 사용 (대부분 사용하는 효과적 방법)
3. Random vector을 부여하여 vocabulary에 추가 -> 각 단어가 고유한 정체성을 가지는 효과
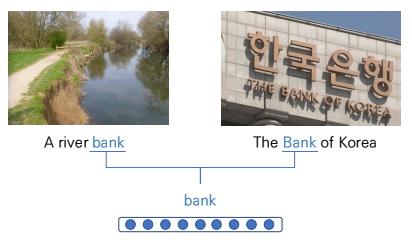
Problem of having one representation of words
Same Representation, but diffenrent context
하나의 단어를 하나의 word vector로 표현하는 경우 한 문맥의 word vector로 매칭되므로 동음이의어를 고려하지 못한다.
Solution : LSTM Language Model
Contextual Word Vector의 필요성이 커진다. Context(문맥)을 고려하여 word vector를 생성할 수 있는 방법으로 Neural Language Model을 제시한다. LSTM 구조가 적용되어 문장의 sequence를 고려하여 다음 단어를 예측하는 모델로 sequence의 학습을 통해 문맥 일정 유지 가능하다. 대표적인 사례로는 ELMo 모델이 있다.
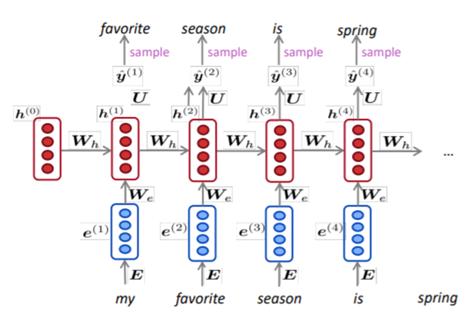
Input : pre trained word
Output : next word
LM : context-specific word representation
Pre-ELMo and ELMO
TagLM -"Pre-ELMo”
Pre-ELMo : Train NLM on large unlabeld corpus for NER
TagLM(Pre-ELMo) 모델은 ELMo 이전에 발표한 모델로 ELMo와 아주 유사한 형태의 구조를 가진다. RNN을 통해 Context 속 의미를 학습하고 싶으나 Pre-ELMo는 small-task labeled data를 학습에 주로 사용한다는 문제점을 Large Unlabeled Corpus로 pre trained하는 Semi-supervised approach이 활용된다.
TagLM은 word meaning 을 represent 할 때, word vector 뿐만이 아니라 LSTM 의 output hidden state 까지 concatenate 해서 함께 사용한다는 특징이 있다. 그러기 위해서는 enormous unlabeled corpus 를 가지고 사전학습한 word embedding model 과 language model 이 필요하다. 따라서 TagLM 모델은 NER task 를 수행하기 위해서 pre-trained word vector + pre-trained language model 두 가지 모두를 사용하는 방법을 제시한다.
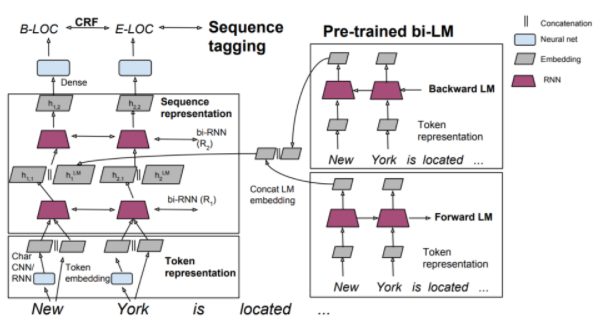
Step 1: Pretrain language model
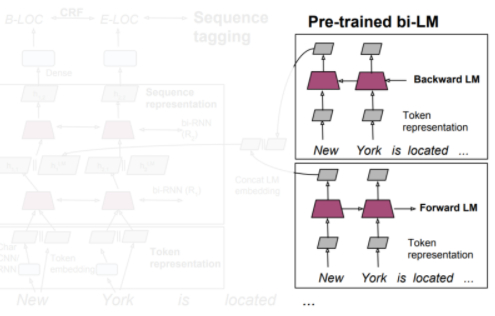
Pre-trained Bi-LM은 Input String을 순방향 LM, 역방향 LM에 별도로 들어온다. 각 LM에서의 output은 concat된다.
Step 2: Word embedding and Char-CNN
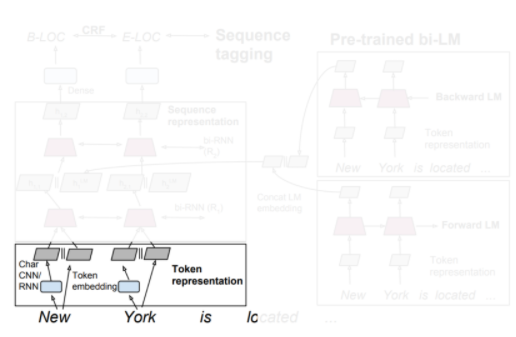
모델은 현재 입력 단어가 주어지면 다음 단어를 예측한다.
Input String은 Token embedding(word2Vec)과 Char CNN으로 표현하고 해당 단계에서의 output은 concat되어 2-layer Bi-LSTM의 1st layer의 input으로 들어간다.
Step 3: Use both word embeddings and LM for NER
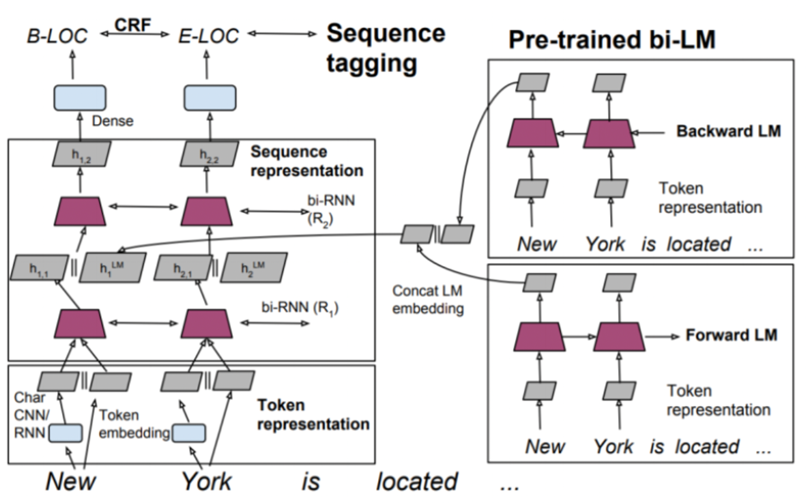
RNN의 1st layer의 output과 LM을 concat한다.
Bi-LSTM의 1st layer의 output은 Pre-trained LM에서의 최종 output와 concat되어 2nd layer로 공급된다.
전체적인 구조는 우측에 존재하는 pre-trained model로 학습한 word vector와 char-CNN model로 학습한 word vector를 concat하는 과정으로 context가 아닌 특징 자체를 고려한 word vector와 데이터의 문맥(context)를 고려한 word vector를 모두 사용함을 통해 의미를 반영하는 모델이다.
ELMo
Embeddings from Language models
Pre-ElMo를 일반화하여 새롭게 제시한 모델로 모든 문장을 이용해서 contextualized word vector를 학습하는 모델이다. 기존의 word embedding이 보통 window를 이용해서 주변 단어를 통해서 문맥만을 이용하는 것과의 차이가 있다.
단어 임베딩은 char-CNN과 같은 모델로 단어의 특징을 고려한 word vector를 구하고 해당 vector를 LSTM의 Input으로 사용해서 최종 word embedding 결과를 도출하는 과정이다.
따라서 'present'라는 동일한 단어는 문장에 따라 '선물'과 '현재'라는 다른 word vector로 표현 가능하다.
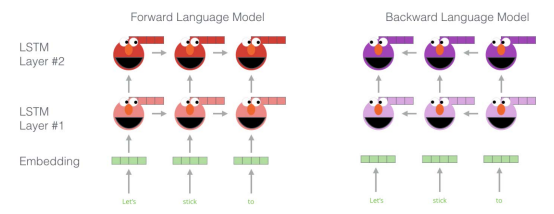
기존 모델과 차별점
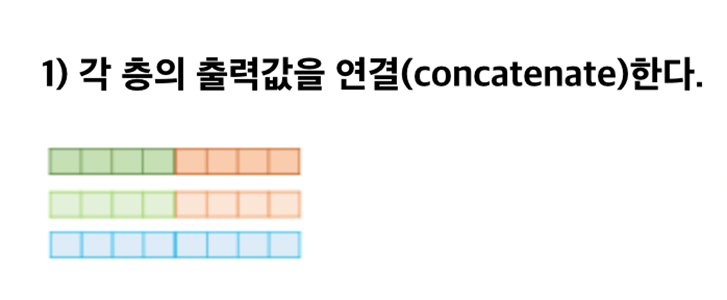
1. 기존 embedding 방법과 달리 모든 문장을 사용하여 Contextualized word vector을 학습.
2. BiLM의 2-layer 양방향 언어 모델로 순방향과 역방향 layer을 통해 해당 단어의 앞, 뒤 정보를 포함한 단어에 대한 각 layer 별 출력 값이 존재하고 모든 layer의 출력값을 통해 최종 word vector을 embedding함.
학습한 LM들의 레이어들을 concat한 후 task에 맞게 linear combination해서 이용한다. 이는 기존에 비슷한 방법론들이 LSTM의 top layer만 이용했던 것과 대조된다.
Concatenation and Linear combination : 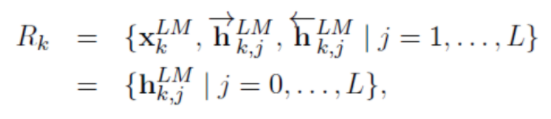
Weights are freezed : 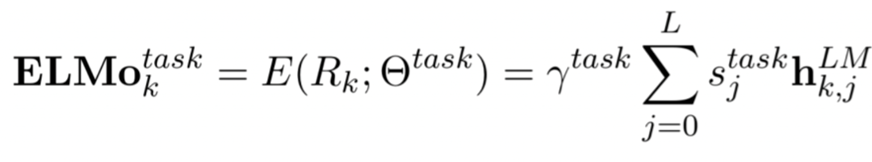
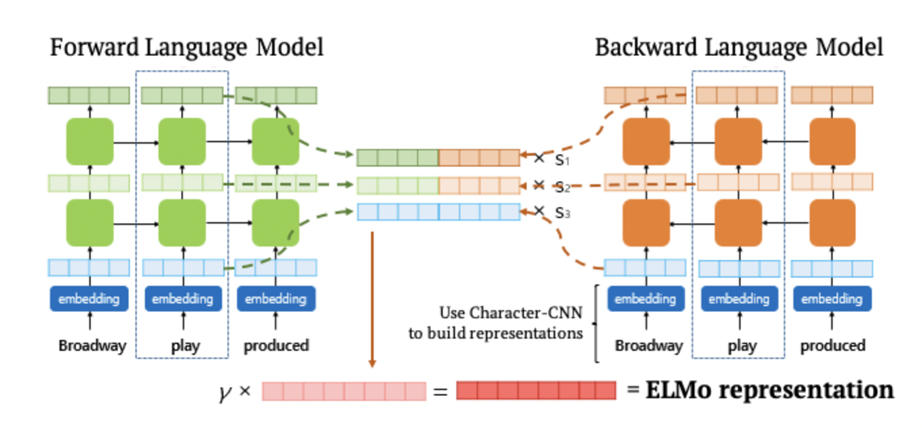
ELMO
1. Input String은 Char-CNN에 의해 word vector로 변환되어 Bi-LM의 1st layer에 공급.
2. 첫번째 layer는 Char-CNN 의 결과에 residual connection을 적용. Char-CNN으로 반영된 단어의 특징을 반영 가능.
3. 첫번째 layer의 output인 중간 word vector는 Bi-LM의 2nd layer에 공급.
4. 두번째 layer output으로 중간 word vector를 출력.
5. 두번째 layer의 중간 word vector까지 출력 되면, 각 layer로부터 출력된 중간 word vector와 raw word vector를 각각 concat하고 가중치를 통해 선형 결합하여 ELMo Representation을 도출. 각 layer의 결과를 선형 결합하여 모두 사용.
6. 최종적으로 모든 layer의 벡터를 더해 하나의 임베딩 벡터라는 word vector를 생성. 이는 단어 자체의 특징인 Syntax 정보와 문맥의 Semantics 정보를 모두 활용.
- 1st layer : Better for lower-level Syntax
- 2nd layer : Better for higher-level Semantics
ELMo Representation 도출하는 과정은 다음과 같다.
ELMo representation



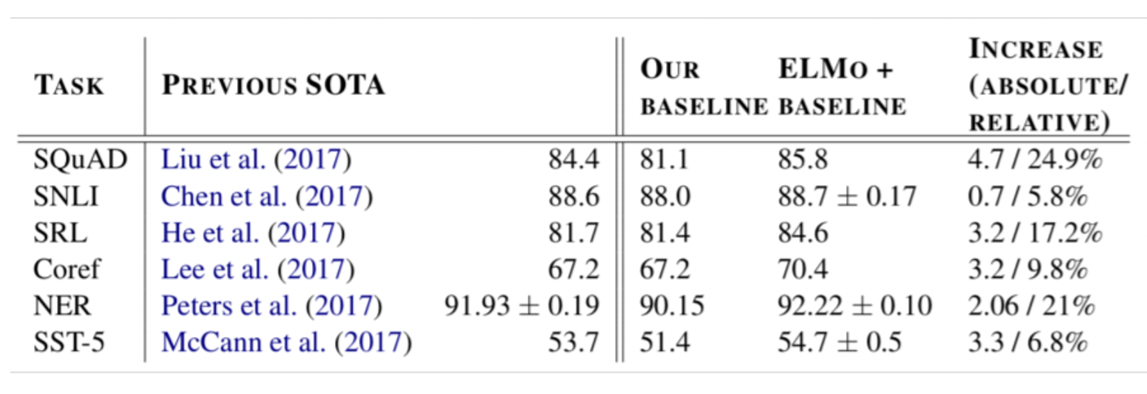
Performance
NER뿐만 아니라 다른 task도 모두 SOTA 기록하였다.
ELMo가 모든 Task에서 우수한 성능을 지녔음을 알 수 있다.
ULMFit and onward
ULMFit
Universal Language Model Fine-tuning for Text Classification
ELMo와 같은 contextual word representaion의 성장과 함께 ULMfit이 등장했다.
NLP에서 본격적으로 Transfer learning을 도입한 첫 사례이며 ULMfit은 언어 모델을 통해 text classification을 목적으로 함. 1개의 GPU로 학습할 수 있는 정도의 사이즈(Pretraining with small dataset)
ULMFit 모델의 구조는 크게 3단계로 나뉜다.
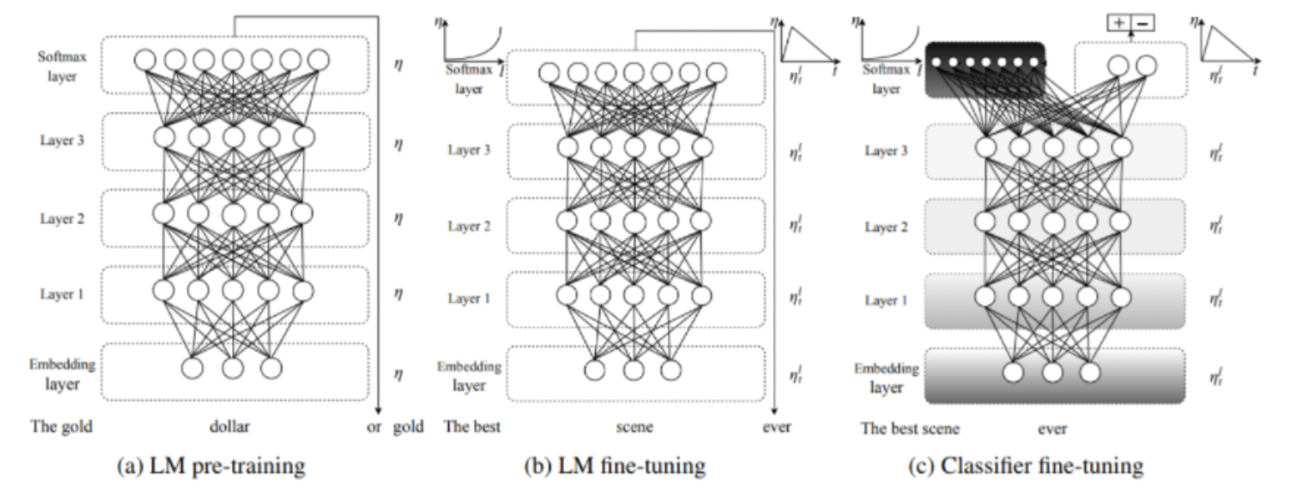
STEP 1: 일반 언어 모델 학습 (a)
3-layer Bi-LSTM Language Model pre-training
첫번째 단계는 Transfer Learning에 해당 부분이며 일반 언어 모델이 학습 되는 부분이다.
LSTM 언어 모델에 다양한 정규화 방법을 적용한 AWD-LSTM 모델로 3-layer Bi-LSTM 언어 모델이며 논문에서는 Wikipedia 영어 버전 전체에 대해 Pre-trained함.
STEP 2: 과제 맞춤형 언어 모델 튜닝 (b)
target task에 맞춰 LM fine-tuining
두번째 단계는 주어진 task에 맞추어 다시 일반 언어 모델을 추가 학습 및 튜닝하는 부분이다.
이때, 튜닝 시 사용하는 2가지 기법은 Discriminative Fine-tuning과 Slanted triangular learning rates이다.
- Discriminative Fine-tuning :
언어 모델 튜닝 시 각 layer별로 서로 다른 learning rate을 적용하며 깊은 layer에 대해서는 상위 layer에 비해 더 작은 학습율을 부여한다.- Slanted triangular learning rates :
튜닝 횟수에 따라 학습율을 적용하는 방법이다. 초반에 작은 학습율로 시작해서 점점 학습율을 증가하다가 약 200번의 학습 후 다시 학습율을 점진적으로 감소하는 방식이다.
STEP 3: 과제 분류기 튜닝 (c)
Target task의 classifier를 fine-tuning
마지막 layer부터 서서히 gradient를 흘려보내는 gradual unfreezing 기법으로 classifier를 학습하기 위해 언어 모델 과제에서 사용된 다음 단어 예측을 위한 레이어(softmax)를 제거한다. 주어진 텍스트가 어떤 클래스에 속할 지 확률을 계산하는 새로운 분류 레이어(softmax)를 추가 한다. 즉, 기존 언어 모델에서 마지막 레이어만 제거하고 나머지는 그대로 둔 후 새로운 분류 레이어 하나만을 추가하여 학습.
Performance
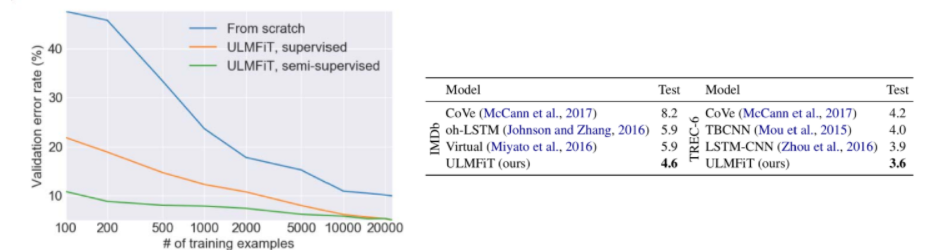
- from scratch : pre-training 없이 분류기 학습
- supervised ULMFit : label이 존재하는 데이터로 pre-training
- semi-supervised ULMFit : 모든 데이터로 pre-training
ULMFit을 사용한 경우 에러율이 현저히 낮다. 이처럼 ULMFit을 사용하면 더 적은 양의 데이터만으로 자연어 처리를 효과적으로 수행할 수 있다.
Transformer architectures
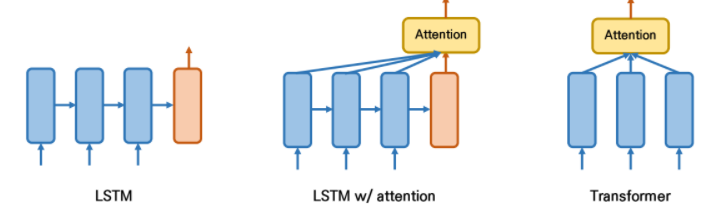
The Motivation for Transformer
RNN 계열 알고리즘의 태생적 한계는 sequential한 특징을 고려하기 때문에 병렬적 계산이 불가능하여 매우 느린 속도를 보인다는 점이다. 또한 Long-term Dependency 라는 문제점도 존재한다. 이를 해결하기 위해 LSTM과 GRU가 등장하였지만 여전히 이를 해결하기 위해 Attention이 필요하다. Attention은 어떤 state(time step)로도 이동할 수 있게 도와준다. 따라서 Transformer 기반의 모델은 Attention 매커니즘을 통해 모든 time stamp를 참조할 수 있다면 RNN의 한계점을 극복할 수 있다는 아이디어에서 시작된다.
Transformer Overview
None-recurrent Seq2Seq encoder-decoder model
Purpose: Machine translation with parallel corpus
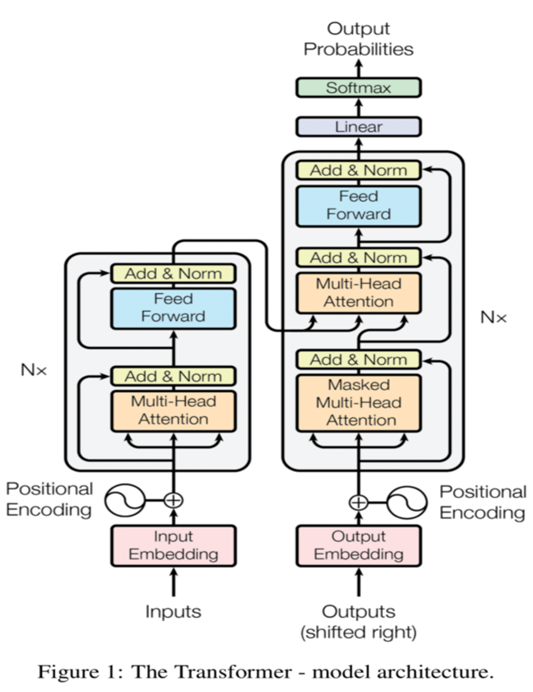
Transformer는 input과 output이 encoder와 decoder로 구분되어 진행되는 seq2seq 모델이다. RNN을 사용하지 않지만 Attention을 통해 Seq2Seq 모델처럼 encoder에서 token sequence을 입력 받아 임베딩을 하고, decoder에서 출력할 token sequence을 예측하는 encoder-decoder 구조이다.
Dot-Product Attention
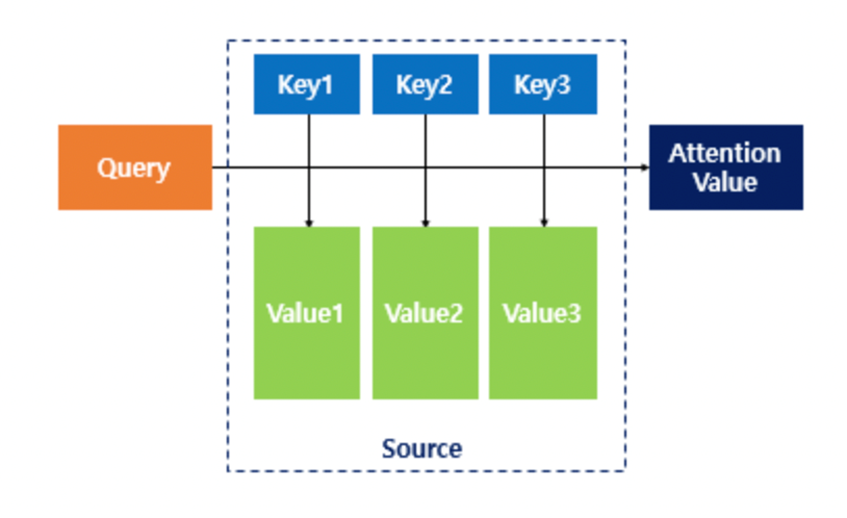
-
Input : Query, Key, Value
Query와 key-value pair의 유사성을 비교한다. 처음 word vector input에서는 Q = K = V으로 문장이 자기 자신을 보며 단어간의 유사성을 파악한다. byte-pair encoding으로 tokenize를 하고 시간 순서를 고려하기 위해 positional encoding 이용한다. -
Output: weighted sum of values
weight: 각 query와 key간의 유사성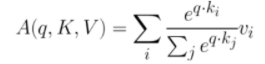
Attention 함수
1. 주어진 'Query'에 대해서 내적을 통해 모든 'Key'와의 유사도를 각각 구함.
2. 구한 유사도를 ‘Key’와 맵핑 되어있는 각각의 'Value'에 반영한 다음 모두 더해서 출력함. 이를 Attention Value이라고 함.
3. 즉, 유사도가 일종의 가중치 역할을 한다고 볼 수 있으며, 결국 Query와 비슷할 수록 높은 가중치를 주어 출력을 준다.
Scaled Dot-Product Attention
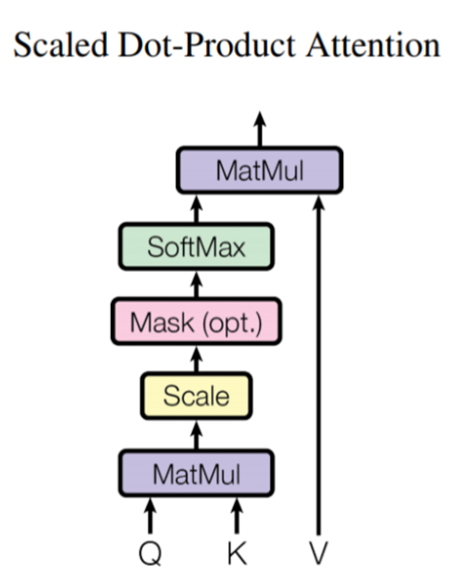
학습 시 그래디언트를 최적화하기 위해서 모든 Query와 Key에 대해 Dot-Product를 계산 후 벡터 차원 수의 제곱근 √(𝑑_𝑘 )로 scaling 해주는 방식이다. Dimension이 클 경우 q와 k의 내적값들의 차이 증가(high variance)한다. 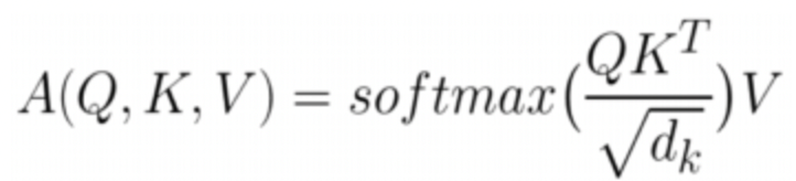
Self-Attention
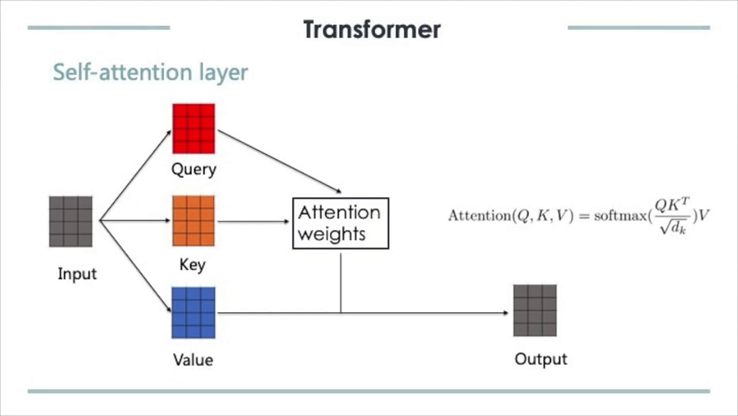
Self-Attention은 입력 데이터 Query가 있을 때, 검색 대상이 되는 Key-Value pair 데이터 테이블이 입력 데이터 Query 자기 자신인 경우를 의미함.
자기 자신의 Query로 Attention Value를 구하는 것으로 Self-Attention을 통해 문장 안에서 단어들 간의 관계를 파악 가능.
Multi-head attention
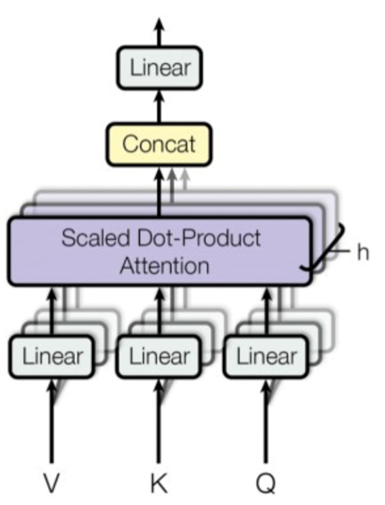
Scaled Dot-Product Attention을 여러 개 만들어 self-attention이 다양한 맥락을 파악할 수 있는 방법으로 head 수(h) 만큼 attention을 진행한 뒤 concat한다. 각 Head에서는 Scaled Dot-Product Attention 과정이 발생하며, 그렇게 발생한 Head별 Attention Value는 concat되어 다음 layer로 전달한다.
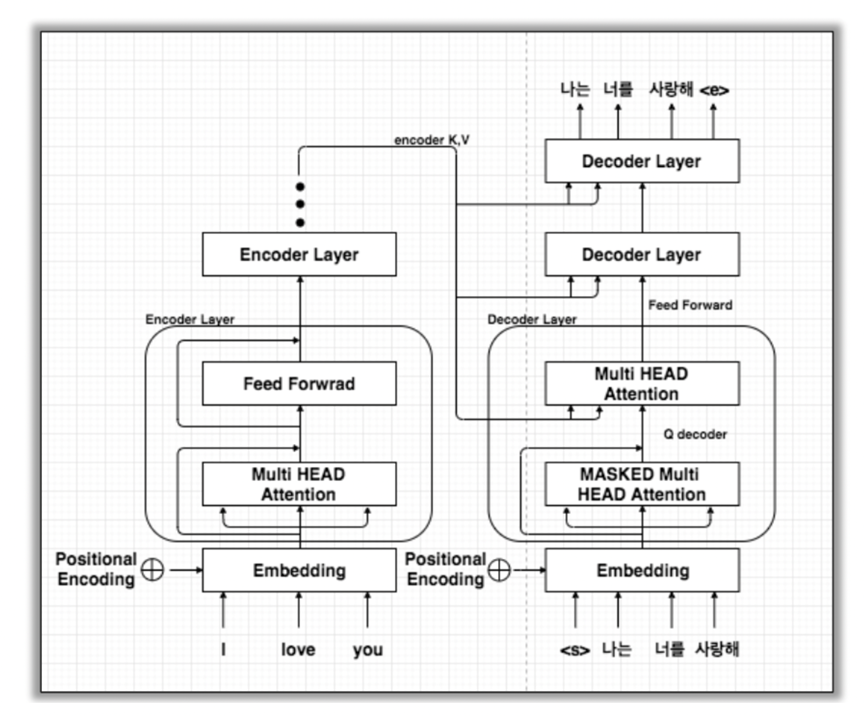
Full Architecture
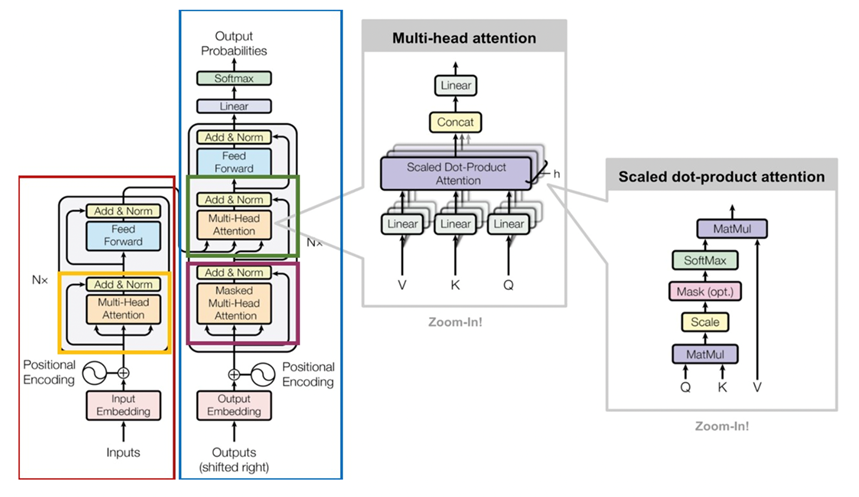
- 빨간색 박스: Encoder
- 파란색 블록: Decoder
- 노란색 블록: Encoder에서 Self-Attention이 발생하는 부분
- 자주색 블록: Decoder에서 Self-Attention이 발생하는 부분
- 초록색 블록: Encoder와 Decoder에서 Attention이 일어나는 부분
- Encoder
- 문장이 Encoder로 들어오면 임베딩을 한 후, Multi-Head Attention 과정을 진행.
- Feed forward with ReLU activation
- Residual connection과 layer normalization 적용
- Decoder
- Target sequence(번역 대상)에 multi-head attention 적용한다.
- Masking을 통해 query 단어가 이전 timestep의 key 단어만
보도록 설정한다.- 두 번째 block에서 Encoder block의 output을 key-value
로 받아 target sequence query와 self attention 진행한다.
BERT
Bi-directional Encoder Representations from Transformers
BERT가 발견한 language model의 한계점 : 기존 Language Model은 항상 왼쪽/오른쪽의 context를 사용 (Unidirectional)한다. Bi-direction의 순방향과 역방향은 각각 독립적으로 적용되기 때문에 순방향 혹은 역방향이라는 sequence를 가진다. Bi-direction임에도 불구하고 단어를 예측함에 있어 전체 단어를 모두 활용할 수는 없다는 문제점을 갖는다.
BERT는 2018년 11월 구글이 공개한 언어 모델로 Transformer의 encoder만 이용해 LM 학습 수행한다. Self-attention의 장점으로 attention으로만 이뤄졌기 때문에 아무리 긴 문장이라도 학습에 동등한 기회를 갖는다. 또한 layer마다 한 번의 계산만 필요하기 때문에 parallelize가 가능해 GPU/TPU에 효율적인 구조이다.
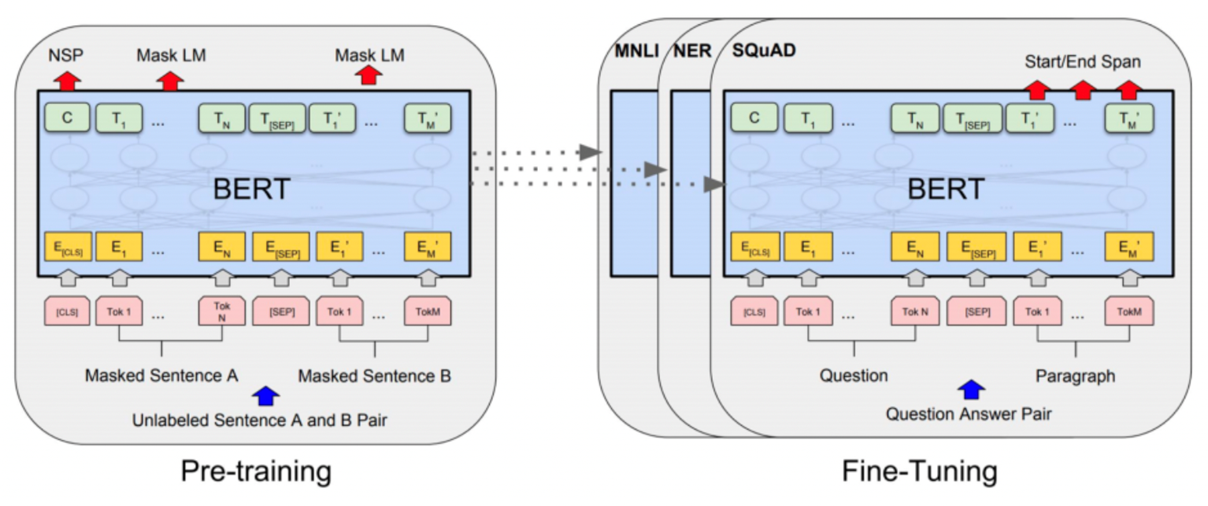
BERT 모델의 구조는 크게 2단계로 나눠진다.
- 첫 번째 단계는 대량의 텍스트 데이터에 대한 semi-supervised 과정인 Pre-Training.
Pre-training을 위한 Objective Function 2가지 : MLM, NSP - 두 번째 단계는 target task에 대한 supervised 과정인 Fine-Tuning.
Pre-trained model 위에 task에 맞는 classifier를 붙여 학습
Pre-training을 위한 Objective Function
- Masked Language Modeling (MLM)
문장 전체 단어의 15%를 [MASK] 토큰으로 변경한 후 원래 단어를 예측하는 것. (Main objective of BERT)
15%를 선택한 후, 그 중 80%는 [MASK], 10%는 현재 단어 유지, 10%는 임의의 단어로 대체함.
- Next Sentence Prediction (NSP)
sentence간의 relationship을 학습하기 위해 두 문장이 이어지는지에 대한 정보를 학습한다. 첫 번째([CLS]) Token으로 문장 A와 문장 B의 관계를 예측하며 A 다음 문장이 B가 맞을 경우는 True, A 다음문장이 B가 아닐 경우 False로 예측하도록 한다.
Performance
Results on GLUE tasks
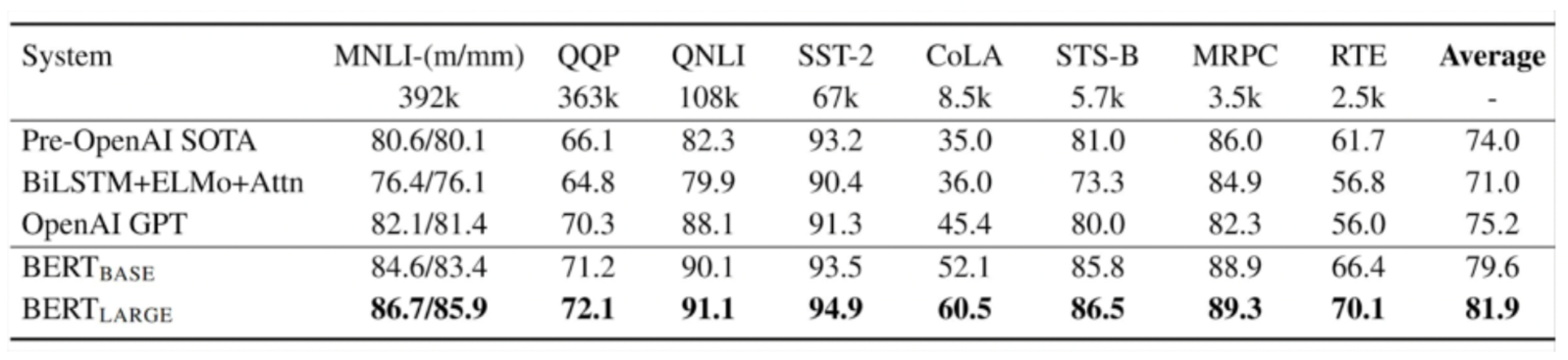
NLP와 관련된 모든 분야에서 SOTA를 기록한 만큼 매우 우수한 성능을 지녔음을 알 수 있다.
References
CS224 Winter 2019: Natural Language Processing with Deep Learning
https://velog.io/@tobigs-text1314/CS224n-Lecture-13-Contextual-Word-Embeddings
https://velog.io/@tobigs-text1415/Lecture-13-Contextual-Word-Embeddings
http://dsba.korea.ac.kr/seminar/?mod=document&uid=42

16기 주지훈
Pre-ElMo and ELMO
ULMFit and onward
BERT