OPGAN, MatchGAN
(OP-GAN) Self-Supervised CycleGAN for Object-Preserving Image-to-Image Domain Adaptation
1. introduction
기존 I2I translation에서 GAN기반 방법은 image의 contents의 손상이 자주 관찰된다는 문제점이 있다.

이미지의 도메인을 translate할 때, 털/눈코입 등의 detail한 특징이 보존되지 않는다.
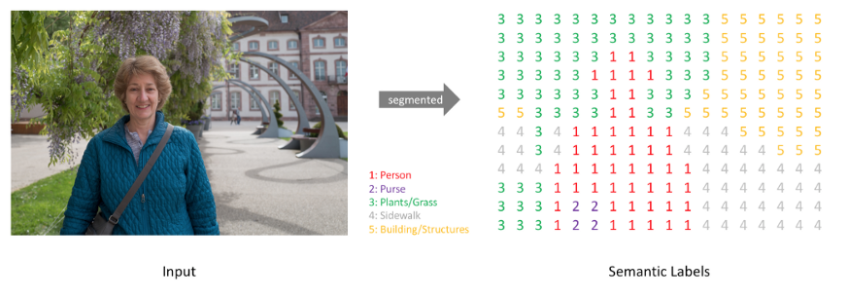
이러한 콘텐츠의 왜곡을 해결하기 위해서 generator에 semantic information을 임베딩하는 segmentation 네트워크의 추가가 제안되어왔다. (content를 인식하는 translation을 강제)
그러나 이러한 방식은 픽셀 단위의 annotation을 필요로 한다는 단점이 존재한다.
따라서 저자는 픽셀 단위의 annotation없이 CycleGAN의 이미지 contents 보존을 가능케하는 self-supervised learning 기법을 적용했다. (OPGAN)
2. Revisiting the Problem of CycleGAN
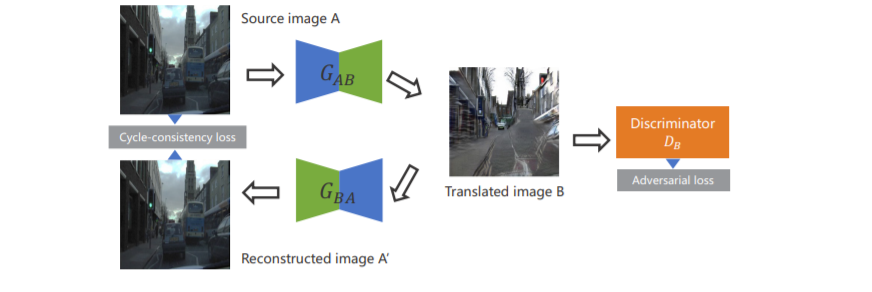
-
example for to domain B
adverserial loss
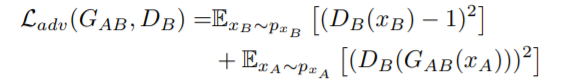
cycle loss
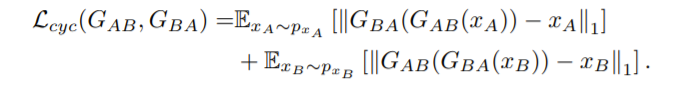
loss를 살펴보면, 결국 translated된 이미지 B와 source image A간 penalty는 존재하지 않는다. -> domain 변환 시 content의 보존이 어렵다.
(해결책으로 pixel 단위의 annotation이 적용된 segmentation 제안, 그러나 비용이 크다.)
3.OPGAN
- OPGAN은 CycleGAN과 유사하게 adv loss와 cyc loss를 포함한다.
- 이미지 content의 보존을 위해서 multi-task self-supervised 샴 네트워크(S)를 추가했다.
- 샴 네트워크는 input으로 translated된 이미지와 source 이미지를 받는다.
multi-task self-supervised learning task
- content registration
- domain classification
이미지 콘텐츠의 특징과 도메인 정보를 disentangle하기 위함.
1) Self-supervised learning
(1) 먼저 원래 이미지와 생성된 이미지를 3 × 3 격자로 나눈다. (하나의 칸을 patch라고 한다.)

(2) training 동안 샴 네트워크의 input으로 할 2개의 patch 쌍을 random으로 선택한다.
self supervised learning task의 달성을 위해서 이 논문에서는 2가지 가정을 한다.(content registration, domain classification)
- C1 같이 원래 이미지와 생성된 이미지의 같은 위치에서 나온 patch는 consistent(일관된) content를 가져야 한다.
- D1, D2 같이 같은 이미지에서 나온 patch는 비슷한 도메인 정보(ex> 빛의 밝기)를 가져야 한다.
따라서 두 patch의 상대적인 위치는 content 정보로 특징을 추출해내는 task를 supervision하는데 사용하고 (content registration)
두 patch의 출처 정보는 도메인 분류에 사용한다. (domain classification)
2) Network Architecture
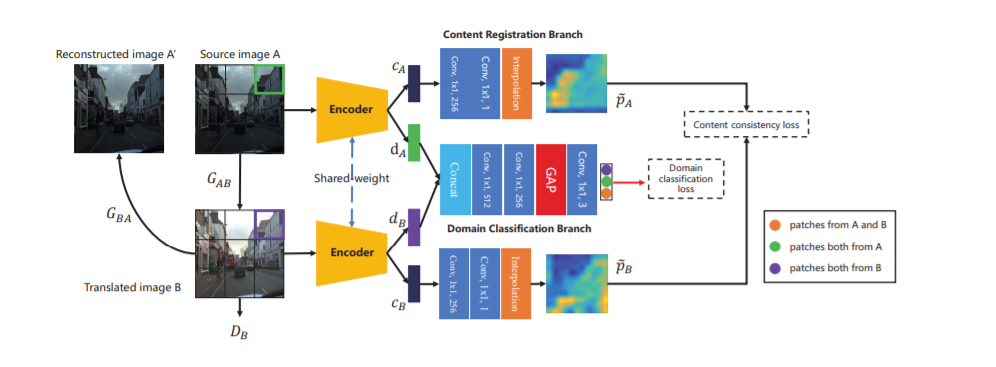
- 샴네트워크 : 가중치를 공유함으로써 같은 잠재공간에 임베딩 되도록 한다.
- content 정보가 있는 disentangled features
- (11×11×512) feature map
- (1 × 1) conv layer를 거치고 content consistency loss 계산을 위해 input patch의 원래 크기로 보간된다.
- 도메인 정보가 있는 disentangled features
- (11×11×512) feature map
- concat되어 (11×11×1024) discriminative feature map이 생성되고 도메인 정보를 추출한다.
앞선 두 가정에 맞추어 domain classification loss와 content consistency loss를 최적화 한다.
3) content registration
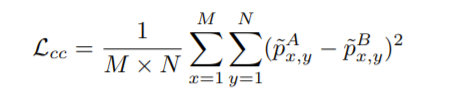
input patch의 원래 크기로 보간된 를 attention map으로 processing하고 픽셀별로 mse를 계산하는 형태
비슷한 위치의 patch끼리 동일 content를 담도록 constraint
즉, 동일 위치의 patch가 들어왔을 때만 optimization을 진행한다.
이외의 경우 0으로 설정
4) domain classification
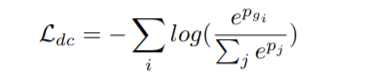

3개의 class(D1, D2, C)로 구성된 1-K classification를 공식화 했다. cross-entropy 사용
5) 최종 loss
기존의 CycleGAN loss + self-supervised loss() 추가
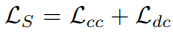
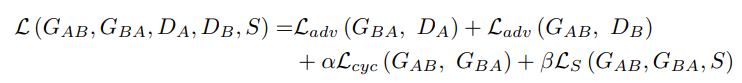
Ls의 최적화는 Ladv와 같은 방식에서 이루어진다.
-> 샴네트워크와 discriminator 고정 후, generator 학습
-> generator 고정 후, 샴네트워크와 discirminator 학습
그러므로 discriminator와 유사하게 샴 네트워크는 이미지 objects에 대한 정보를 generators에 직접 전달할 수 있다. 이는 변환된 이미지의 object 보존이 잘 되게 한다.
MatchGAN: A Self-Supervised Semi-Supervised Conditional Generative Adversarial Network
1. introduction
CGAN은 이미지의 생성과 조작에 매우 유용하지만 많은 양의 annotation을 필요로한다는 단점이 있다. (high cost)
cGAN을 training하는데 많은 양의 annotated dataset 요구를 줄이기 위해 많은 연구에서는 pretext task를 설계할 때 self-supervised 방법을 도입했다.
그리고 대부분의 연구는 input image space의 geometric augmentations(기하학적 증강)에 집중했다. 그러나 이는 각 class label의 새로운 data들을 만들어낼 수 없다는 한계가 있다.
(data를 rotation한다고 해서 새로운 class로 바뀌진 않는다.)
- MatchGAN 제안
self-supervised learning pretext task에서 data augmentation 방법으로 image space가 아닌 label space를 활용하자
2. MatchGAN
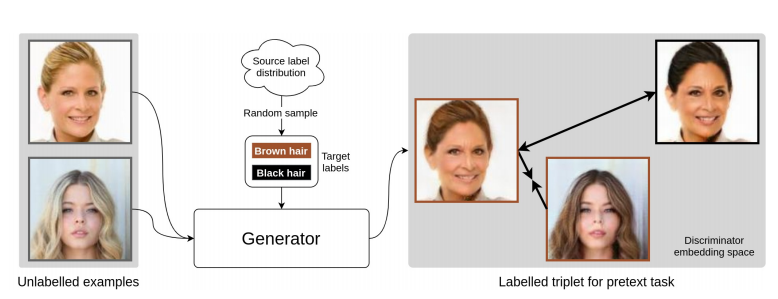
-
labelled data의 label space로부터 분별 있는 label들을 랜덤으로 샘플링해서 brown hair, black hair 같은 target labels를 추출했다.
-
이 target labels와 labelled data의 분포와 동일한 분포로부터 나온 unlabelled data를 generator의 input으로 넣어 (합성된) 새로운 이미지를 생성해낸다.
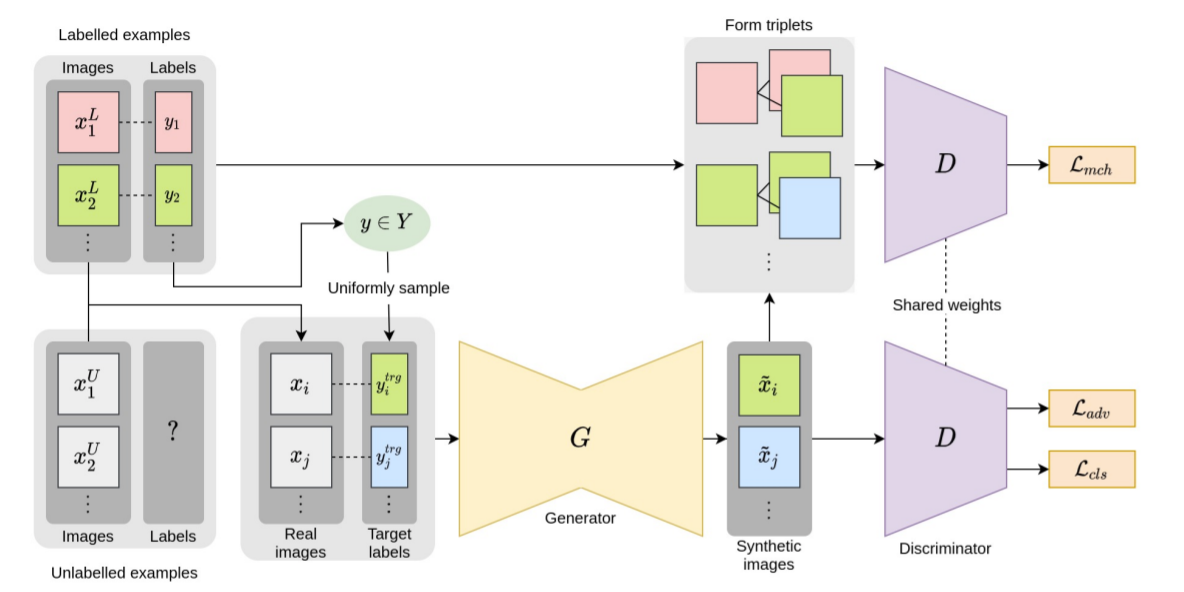
- generator에서 합성된 이미지는 target labels와 비교하여 동일한 label 정보를 공유하는 positive pairs와 다른 label 정보를 공유하는 negative pairs로 그룹화된다.
- positive, negative pairs 그룹을 분류하는 auxiliary match loss(triplet matching loss)를 최소화하는 것이 pretext task의 목적이다.
unlabelled data를 target label을 넣어 이미지를 생성한 후, 생성된 이미지가 본래의 이미지 그룹에 포함되도록(triplet) loss 최적화
기존 stargan loss에 추가적인 loss 적용
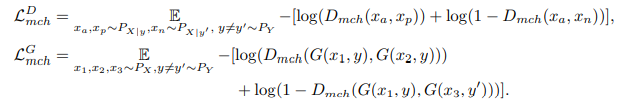
discriminator는 같은 라벨의 그룹과 다른 라벨의 그룹을 잘 구별하도록 학습
generator는 같은 라벨로 부터 생성된 이미지는 같은 그룹으로 구별되도록 하는 이미지를 생성하고, 다른 라벨로 부터 생성된 이미지는 다른 그룹으로 구별되도록 이미지를 생성

2개의 댓글

OPGAN
- 기존 생성모델들은 content가 조금 뭉개지는 상황이 종종 발생하였음.
- pixel-level(그러니 보통의) segmentation mask를 이용해 translation을 적절히 컨트롤할 수는 있었지만, 비용이 비쌌다.
- 이를 위해서 pretext task를 제안했으며, 샴 네트워크를 활용해 가중치를 공유함으로써 네트워크를 학습.
- 이 때, 두 이미지(original image, translated image) 에서 패치를 각각 같은 위치에서 두 개씩 뽑는다.
- 이 때 다른 이미지의 같은 위치 패치 간에는 content가 유지되도록 하는 content loss를,
- 같은 이미지의 다른 패치 간에는 domain(style or concepts)가 유지되도록 하는 domain classification task를 진행
- 이로부터, 도메인 변환 뿐만 아니라 물체(혹은 배경)의 내용(content)가 잘 유지되는 네트워크를 학습할 수 있음.
MatchGAN
- 보통 생성모델을 제대로 활용하기 위한 pretext-task는 Input-level(즉, 이미지)의 태스크에 집중해왔다.
- MatchGAN은 생각을 다소 바꿔, label-level에서의 분포를 활용함으로써 pretext task를 구축.
- 즉, 라벨을 랜덤으로 샘플링 한 후, 이를 제너레이터의 조건으로 넣어줘 해당 라벨과 동일합 집단 내에 속하는 이미지가 만들도록 강제함.
[OPGAN]
기존의 image translation 모델들은 input과 translation 사이에만 비교하여 content가 종종 뭉개지는 현상이 있었다.
이를 개선하고자 generator에 semantic information을 활용하는 방안이 모색되었으나, 근본적으로 semantic information을 만드는 비용이 너무 많이 들었다.
이를 개선하기 위해 OPGAN은 multi task self supervised인 샴 네트워크를 추가하였다.
기본적으로 OPGAN은 이미지에서 content와 domain을 disentangle한다.
self supervised learning을 활용하기 위해 다음과 같은 가정을 한다.
- 같은 이미지에서 나온 패치는 동일한 domain을 가진다.
- 다른 이미지에서 나온 동일 위치의 패치는 동일한 content를 가진다.
위 두 가정을 이용하여 두 패치의 출처 정보로 domain을 추출하고, 상대적 위치로 content를 추출한다.
MatchGAN
기존의 cGAN류 모델은 레이블링을 위해 많은 비용이 소모된다.
MatchGAN은 이를 개선하고자 레이블이 없는 이미지도 활용하는 semi-supervised 방법론을 사용한다.
레이블이 없는 데이터와 기존의 레이블을 generator에 실어서 레이블이 있는 데이터를 생성한다.
이렇게 생성된 이미지와 레이블이 있는 실제 이미지가 discriminator를 통과하여 다음 loss를 계산하게 된다.
1. Ladv : 생성된 이미지인지, 실제 이미지인지
2. Lcls : 이미지의 레이블이 무엇인지
3. Lmch : 입력된 이미지들이 동일 레이블인지, 다른 레이블인지
MatchGAN은 기본적으로 stargan을 기반으로 하고 있으나 다른 cGAN 모델을 사용해도 된다고 한다.
학습된 MatchGAN은 결국 우리가 원하는 레이블을 반영한 이미지를 생성할 수 있게 된다.
이를 다르게 보자면, stargan 등에서 data augmentation을 위해 원본 이미지를 회전, 굴절, 색 왜곡 등을 사용하는 것에 비해, MatchGAN에선 레이블을 사용하고 있다고 볼 수 있다.