Self-Supervised Learning
0. Intro
아래 글의 전반적인 내용은 2020년에 발표된 Self-supervised Learning: Generative or Contrastive, Xiao Liu의 논문을 따르고 있습니다. 그래서 2020년 이후의 SSL의 내용은 반영되어 있지 않습니다.
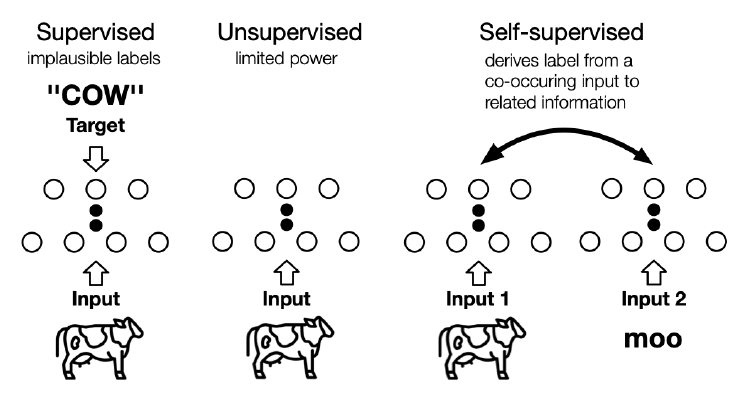
처음 기계학습을 공부할 때를 생각해보면 세상엔 두가지 종류로 나눌 수 있다고 배운다.
- 지도학습 (supervised learning)
- 비지도 학습 (unsupervised learning)
여기서 지도학습은 레이블이 존재하는 특정 태스크에 대해 수행하는 학습이고, 비지도학습은 레이블이 존재하지 않는 데이터에 대해 데이터 내의 패턴을 파악하는 알고리즘이다. 사실 분류, 회귀 등의 일반적인 태스크는 대부분 지도학습을 따르게 된다. 하지만 여기서 아래와 같은 문제가 발생한다.
- 고비용
- 어려운 일반화 및 편향(train, validation, test set)
- 의도치 않은 상관관계(인종, 성별, 직업 등)
- adversarial attack에 취약
가장 근본적으로 생각해보면, 지도학습을 하려고 레이블을 만드는 과정은 수고스럽고, 비용도 많이 드는데, 그만큼 효과적이지 않다. 그래서 최근 몇 년간 나온 딥러닝 모델을 살펴보면 알게 모르게 자기지도학습(self-supervised learning)을 도입하고 있다. 이미 우리가 접한 수많은 모델 (Bert, GPT, GAN, VAE 등)은 자기지도학습의 일종이다.
Yann LeCun의 자기지도학습의 정의는 다음과 같다.
기계가 관측치를 이용한 입력값의 일부를 예측하는 것.
"The machine predicts any parts of its input for any observed part"
여기서 자기지도학습의 두가지 특징을 알 수 있게 된다.
- 일종의 자동화된 과정을 통해 데이터 내에서 레이블을 생성
- 데이터의 다른 부분을 이용한 일부분을 예측
이때 위에서 이야기한 "다른 부분"은 잘리거나, 변환되었거나, 왜곡되거나, 오염된 상태로 모델에 제공되게 된다. 즉, 모델은 학습과정에서 온전하지 못한 데이터를 입력으로 받아 복원하는 작업을 수행하게 된다.
여기서 자기지도학습과 비지도학습의 차이점이 나타나게 되는데, 비지도학습은 데이터 내부의 패턴을 잡아내어 clustering, community dection, anomaly dection을 수행해내는데 반해, 자기지도학습은 단순히 데이터를 복원하는 과정을 통해 학습이 이루어진다. 즉, 기본적인 자기지도학습의 과정은 일종의 지도학습에 가깝다.
해당 논문에서는 다음과 같이 크게 자기지도학습을 구분하고 하나씩 설명하고 있다. 도메인으로는 이미지, 자연어, 그래프를 삼고 있는데, 그래프는 제외하고 설명하도록 하겠다.
- Generative
- Contrastive
- Generative-Contrastive(Adversarial)
1. Motivation of SSL
자기지도학습의 기본적인 아이디어에 대해 살펴보도록 하자.
기본적으로 딥러닝 모델은 매우 많은 데이터를 필요로 한다. 그 이유로는 딥러닝은 기본적으로 end-to-end를 기반으로 하고, 이는 그 과정에서 다른 방법론보다 적은 가정을 기반으로 한다. 데이터의 형태나 분포가 어때야 한다거나, 어떤 가정을 만족하는지 확인하지 않는다. 이는 모델이 편향을 학습하거나 과적합될 여지가 많아지고, 이를 방지하기 위해선 많은 데이터가 필수적이다. 그냥 데이터를 많이 확보해서 실제 분포를 모델이 최대한 학습하게 만드는 것이다.
하지만 위에서 서술했듯이, 잘 정제된 데이터를 확보하는 것은 비용이 많이 든다. 수십억장의 이미지나 수십억 문장을 학습에 사용할 수 있을 정도로 데이터가 풍부한 상황에선 현실적으로 말이 안된다.
그래서 자기지도학습은 모델이 데이터 내부에 존재하는 동시등장관계를 self-supervision으로 삼도록 한다. 예를 들자면, 동시에 자주 출현하는 단어를 학습할 수 있다면, "나는 사과와 같은 ___ 좋아한다."라는 문장이 주어지면 빈칸에 "과일을"이 들어가면 적절할 것이라는 관계를 파악할 수 있게 되는 것이다(이것이 실제로 기본적인 Language Model의 방향성이기도 하다.).
1-1. Pipeline
전반적인 파이프라인을 살펴보면 다음과 같다.
Pretext Task
모델이 사전에 정의된 임의의 태스크를 수행하면서 데이터 전반에 대한 이해도를 높일 수 있도록 설계된 태스크를 의미한다. 모델은 pretext task를 수행하여 데이터에 대해 충분히 다룰 수 있게 되고, downstream task에 대해 fine tuning되어 효율적으로 성능을 확보할 수 있다.
목적
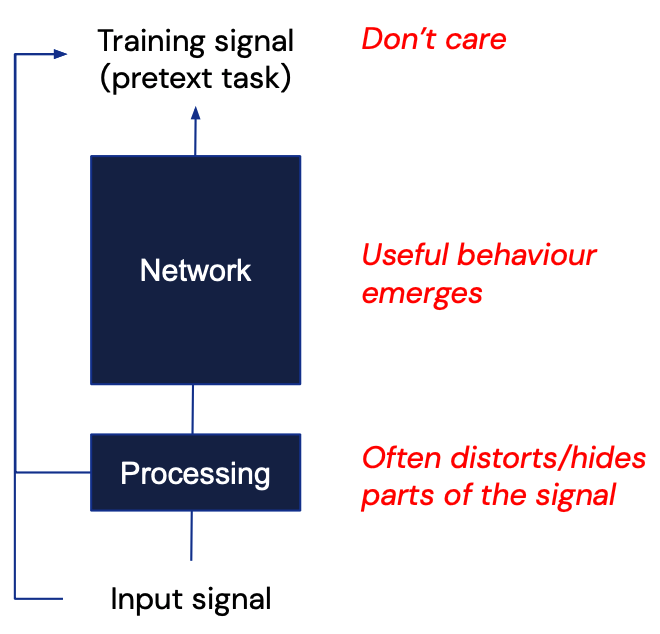
우리가 SSL에서 학습시키고자 하는 것은 pretext task를 수행하는 과정이 아니다. 즉, pretext task를 위해 추가된 SSL 모델 위에 얹어진 헤드나 pretext task 자체의 성능에 사실 크게 관심이 있지 않다. 다만, 적절한 pretext task를 통해 데이터 자체의 패턴을 학습하고, 이를 적절한 representation으로 표현하는 모델을 구성하고자 하는 것이다.
과정
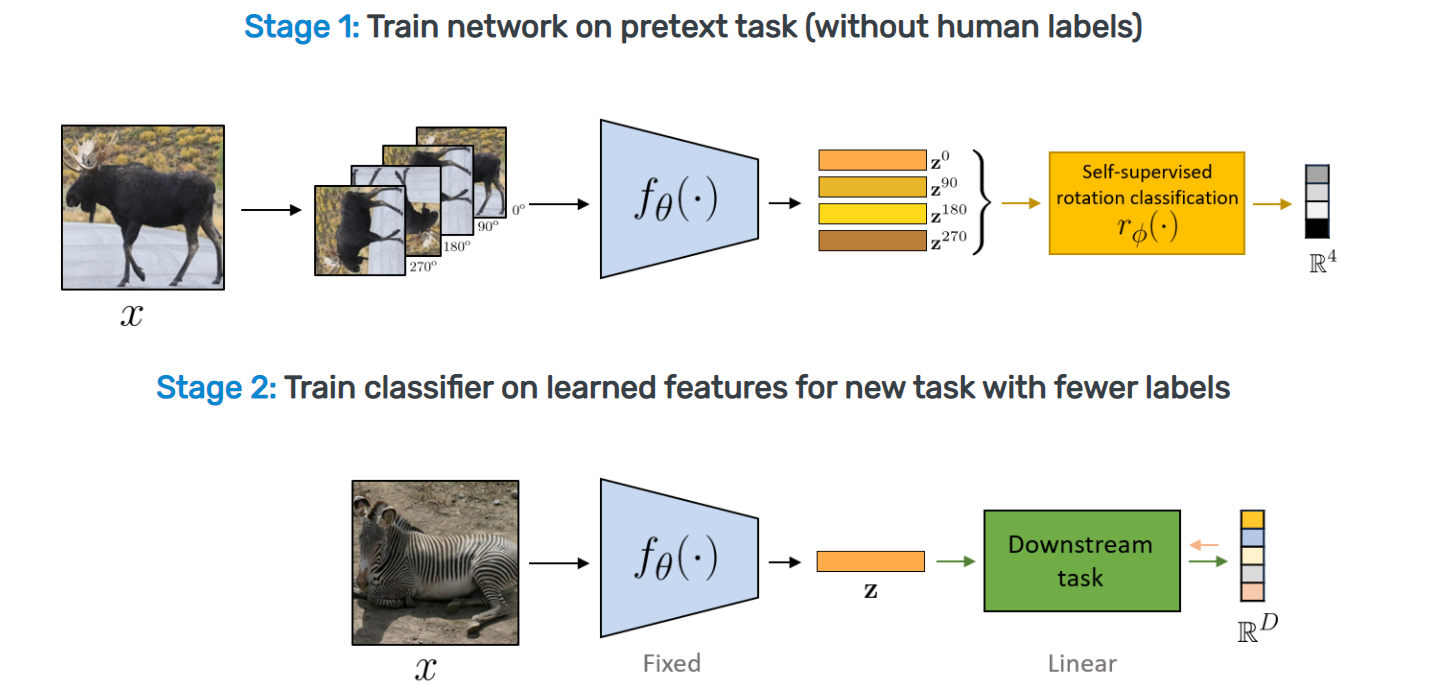
- 사전에 정의한 pretext task에 대하여 레이블이 없는 상태에서 학습을 진행
- 학습된 SSL 모델 위에 downstream task에 적합한 헤드를 붙이고, 레이블이 있는 소수의 데이터에 대해 학습(transfer learning)
분류
그래서 자기지도학습을 세가지로 나눠보자면 다음과 같다.
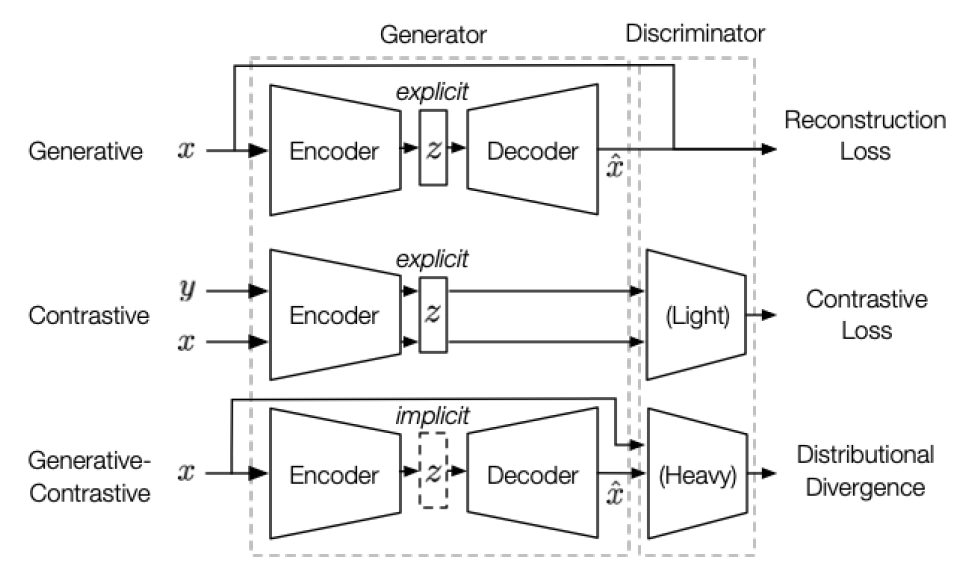
- Generative : 인코더가 입력데이터를 받아 잠재 벡터 z를 생성하고, 이를 디코더가 다시 본래 데이터로 복구한다. 이때 목적함수로는 본래 데이터를 복원하는 reconstruction loss를 사용한다.
- Contrastive : 인코더가 다수의 입력데이터를 받아 잠재 벡터 z를 생성하고, 이를 이용해 유사도를 측정한다. 이때 목적함수로는 데이터 간 유사도 지표를 기반으로 하는 contrastive similarity metric을 사용한다.
- Generative-Contrastive(Adversarial) : 인코더-디코더가 입력데이터를 받아 이와 유사한 데이터를 생성해낸다. 그리고 분류기가 이를 실제 데이터와 분류한다. 이 과정에서 잠재 벡터는 명시적으론 존재하지 않는다. 이때 목적함수로는 실제 데이터와 생성된 데이터 간의 차이를 비교하는 다양한 distributional divergence(KL-Divergence, JS-Divergence, Wasserstein Distance)를 사용한다.
그러면 하나씩 살펴보도록 하자.
2. Generative SSL
2-1. Auto-Regressive(AR) Model
ar 모델들은 방향성이 있는 모델링을 기반으로 한다. 방향성이 있는 모델링이란 연속된 입력값에 대해 한 방향으로 그 정보를 반영하고 있다는 것이다. ar 모델이 다른 생성모델과 다른 것은 만들고자 하는 데이터가 실제로 존재하는 데이터라는 점일 것이다. 텍스트에서는 정답 문장이 주어지고, 이미지에선 정답 이미지가 주어진다.
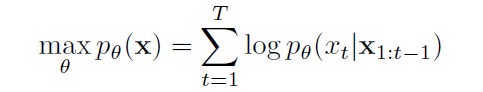
식으로 보면 조금 더 이해가 쉽다. 아마 NLP가 가장 대표적인 분야일텐데 GPT 류의 모델이 순방향 ar 모델이라고 할 수 있다. GPT류의 모델은 위의 수식처럼 이전 시점까지 등장한 단어를 조건으로 하여 이번 시점의 단어를 생성해낸다. 간단히 표현하면 다음 순서대로 단어를 만든다.
- 나는
- 나는 오늘
- 나는 오늘 몇 시에
- 나는 오늘 몇 시에 잘
- 나는 오늘 몇 시에 잘 수
- 나는 오늘 몇 시에 잘 수 있을까?
여기서 GPT-2는 더 나아가서 여러 태스크에 대한 일반화 성능을 확보하기 위해서 를 모델링했다.
이러한 자연어의 아이디어를 이어받아서 나온 것이 Pixel-CNN, PixelRNN이다. 두 모델 모두 이전의 cnn 기반 모델들이 지역적 정보를 모델링하는 접근에서 벗어나 왼쪽->오른쪽, 위->아래 방향으로 픽셀을 순서대로 모델링하는 방법을 취하고 있다.
AR 모델은 그 특성상 맥락을 매우 잘 모델링한다는 장점이 있다. 이미지든 텍스트든 사전에 정의한 방향을 따라 입력값을 처리하기 때문에, 맥락 정보를 다루면서 데이터를 생성할 수 있게 된다. 하지만 그 방향이 정해져있기 때문에, 정보가 하나의 방향으로 흐른다는 문제점 역시 존재한다.
2-2. Auto-Encoding Model
Auto Encoder(Basic)
AR 모델이 정해진 데이터를 생성해내도록 초점을 맞추고 있다면, AE 모델은 손상된 데이터를 입력으로 하여 이를 복원하는데 초점을 맞추고 있다. 이미지에선 오토인코더가 AE 모델이라 할 수 있는데, 입력 값이 인코더와 디코더를 통과하여 입력값과 동일한 값을 생성하도록 하기 때문이다.
CBOW & SKip-Gram(Context Prediction)
자연어에서는 word2vec이 ae 모델이라 할 수 있다. 기본적으로 주변단어를 이용해 중심단어를 생성하거나, 중심단어를 이용해 주변단어를 생성하는 과정을 수행하기 때문이다.
MLM(Denoising)
입력값에 노이즈를 추가하고, 이를 복원하는 모델도 있다. Bert에서 처음 사용된 MLM은 입력 문장에 마스킹을 씌우고 해당 부분을 복원하는 작업을 취한다. 이때 마스킹이 실제 문장에서 사용되지 않기 때문에, 추론 과정과의 통일성을 위해 일부분은 실제 단어를 이용해 대체하기도 한다. 또한, SpanBert와 같이 span을 이용해 마스킹을 하기도 하고, ERNIE처럼 문구나 entity를 마스킹하기도 한다.
AR 모델과 비교해보자면 AE 모델은 주변 단어의 정보를 양방향에서 가져올 수 있다. 하지만 이는 주변 단어가 해당 단어의 정보를 포함하지 않고 있는 독립적 상황이라 가정하는데, 실제로 그렇지 않아 단점이라 할 수 있다.
VAE(Varitational)
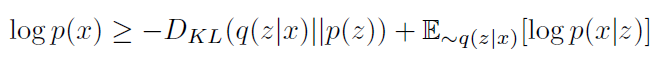
오토 인코더의 잠재 벡터가 특정 분포를 가정하지 않는다면, VAE의 잠재벡터는 잠재벡터를 특정 분포로 가정하고 모델링하게 된다. 이 과정에서 모델은 실제 데이터가 잠재벡터에서 생성될 수 있어야 하고(reconstruction), 입력값을 인코딩한 잠재벡터가 실제로 분포를 따르도록 학습된다.
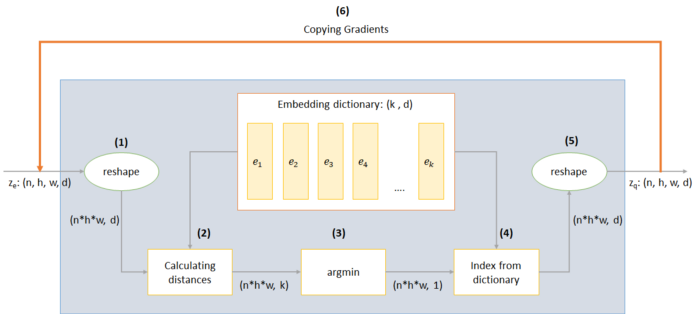
최근까지 VAE 연구에서 GAN에 비해 큰 성능적 개선을 보이지 못하다가 VQ-VAE가 좋은 성과를 보였다고 한다. VQ-VAE는 인코더가 이미지를 입력으로 하여 discrete한 분포를 생성하면, 이와 가장 유사한 벡터를 임베딩 테이블에서 꺼내와 디코더가 이미지를 생성하게 된다.
이는 실제로 다양한 분야(이미지, 텍스트, 그래프 등등)에서 실제 분포가 continuous하기 보단 discrete한 특징을 가지고 있다는 점을 반영하여 모델을 구성한 것이라 할 수 있다.
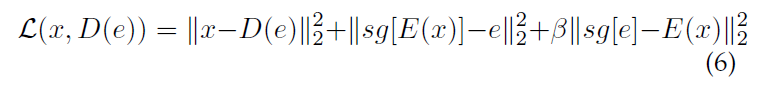
그 결과 손실함수는 위와 같이 구성이 되는데, 여기서 sg는 stop gradient로 argmin이 그래디언트를 전달하지 못하기 때문에, 그래디언트 전달을 멈추고, 코드북(임베딩 테이블)을 통해서만 그래디언를 전달받는 것을 의미한다.
손실함수의 항을 설명하면, (reconstruction loss, 코드북 학습, 인코더 학습)의 순으로 구성되어 있다.
최근 발표된 VQ-VAE-2의 경우 BigGAN의 성능을 넘으면 이미지넷에서 SOTA를 달성했다고 한다.
2-3. Hybrid Generative Models
PLM
AE와 AR을 혼합하는 방법론 역시 존재한다. AR이 이전 시점의 정보를 이용해 데이터를 생성하고, AE가 양방향 정보를 이용해 데이터를 생성하는 점을 종합하여, 시점을 섞고, 섞은 정보를 순차적으로 처리하도록 학습하는 것이 PLM(Permutation LM)이다. XLNet을 통해 최초로 제안되었으며 Transformer-XL의 영향을 받은 것으로 알려져있다.

기존의 AR 방식은 위와 같이 이전 시점의 정보만 attention에서 마스킹하지 않고 가져오도록 되어 있다.
하지만 PLM에선 위 그림의 오른쪽 부분처럼 시점을 섞는다. 우리가 인식할 때 문장은 순서대로 입력되어야 자연스럽지만, 사실 SSL의 관점에서 문장의 순서 역시 일종의 정보일 따름이고, 토큰의 정보를 섞어서 양방향의 정보를 받는 AR 모델을 만들 수 있는 것이다. 이는 실제로는 Attention mask를 조정하여 왼쪽 그림처럼 구현된다.
2-4. Pros & Cons
이러한 generative SSL 모델이 성공할 수 있었던 주요한 이유는 downstream task에 대한 특별한 가정없이 데이터 자체의 분포를 학습하는데 초점을 맞추고 있기 때문이다. 이를 통해 학습된 모델은 태스크에 구애받지 않고 데이터를 잘 다룰 수 있기 때문에 광범위한 태스크에 적용될 수 있게 된다. 특히 generative SSL의 경우 구현이 명확하기 때문에 이미지와 텍스트 등 도메인에 구애받지 않고 다양하게 사용되고 있다.
하지만 그에 비해 다음과 같은 두가지 단점 역시 존재한다. 첫번째, 후에 소개할 constrative SSL에 비해 분류 태스크에서 성능이 떨어진다. constrative SSL은 애초에 분류 태스크를 가정한 SSL 방법론으로 광범위하게 적용되는 generative SSL이 성능이 떨어지게 된다.
두번째, generative SSL의 목적함수는 요소별로 이루어져있다. 이미지에선 픽셀 단위로, 텍스트에선 토큰 단위로 목적함수를 구현하여 MLE를 수행하게 된다. 이 과정에서 중대한 두가진 문제점이 발생한다.
- 분포에 영향을 많이 받는다. : 목적함수는 로 구성되는데, 이는 에 영향을 많이 받을 수 받게 없다. 즉, 자주 등장하지 않는 데이터의 영향을 많이 받는 것이다.
- 저수준 목적함수 : 목적함수가 요소별로 이루어져있다는 것은 모델이 이미지의 픽셀 간, 텍스트의 토큰 간 관계 파악에 집중한다는 의미이다. 이는 분류, object dection, 긴 문장 요약 등 요소들의 많은 관계를 파악해야 하는 고수준 요약(high-level abstraction)에 대한 성능 저하를 가져온다.
위 단점을 보완하고자 adversarial SSL은 고수준 즉 데이터 분포 자체를 비교하는 방법론을 취하고 있다.
3. Contrastive SSL
머신러닝 모델들은 두가지로 분류해보면 생성모델과 분류(discriminative)모델로 구분할 수 있을 것이다. 생성모델은 를 모델링하게 되고, 분류모델은 를 모델링하게 된다. representation learning 즉, 데이터의 매니폴드를 포착하는 학습은 결국 데이터(X)의 분포를 잡아내거나 관계를 포착해내는 작업이기 때문에 전통적으로 생성모델을 이용해야 한다고 할 수 있다.
하지만 최근 연구에서 Deep InfoMax, MoCo, SimCLR 등 다양한 분류태스크를 학습한 모델들이 representation learning의 훌륭한 방법론으로 주목받고 있다. 그리고 이러한 contrastive learning은 주어진 데이터들을 비교하면서 학습한다. 비교하는 과정은 다음과 같은 Noise Contrastive Estimation 목적함수를 통해 이루어진다.
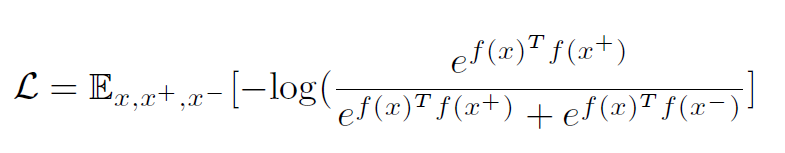
- x : 기준이 되는 데이터, query 데이터
- : 관련이 있는 데이터 혹은 x와 유사한 데이터
- : 관련이 없는 데이터 혹은 x와 유사하지 않은 데이터
전반적인 프레임워크는 결국 기준이 되는 데이터와 유사한 데이터는 가까운 곳에 맵핑이 되고, 기준이 되는 데이터와 유사하지 않은 데이터는 멀리 떨어진 곳에 맵핑이 되도록 인코더를 학습하는 것이다.
저자들은 또한 contrastive learning을 두가지 유형으로 나누어 context-instance와 instance-instance로 구분했다. 하나씩 살펴보자.
3-1. Context-Instance
context-instance 혹은 global-local contrast로 불리는 이 방법론은 주어진 데이터의 국소적인 특징들이 전반적인 맥락 표상(context representation)과 유사한 정도 혹은 관계를 모델링하는 데 초점을 맞추고 있다.
이를 다시 두가지로 나누어 Predict Relative Position과 Maximize Mutual Information으로 구분할 수 있다.
- Predict Relative Position: PRP는 국소 부분들의 상대적인 관계를 파악하려고 한다. 이때 global context는 전반적인 구조를 제시하면서 이 관계 파악에 도움을 주는 정도이다.
- Maximize Mutual Information : MI는 국소 부분과 global context의 직접적인 관계를 파악한다. 즉, 국소 부분들의 관계에는 관심이 없다.
3-1-1. Predict Relative Position(PRP)
많은 데이터들이 자연스레 공간적 혹은 시간적 정보를 가지고 있게 된다. 텍스트는 단어와 문장이 순서를 가지고 제시되고, 이미지는 각 요소들이 공간적 관계를 가지고 배치된다. 예를 들어 아래와 같은 코끼리 사진이 주어지면 당연히 다리는 몸통과 연결되고, 귀와 코는 머리와 연결되어 제시될 것이다.

NLP
텍스트 분야에서 사용되는 PRP로는 NSP(Next Sentence Prediction)가 대표적이다. NSP역시 MLM처럼 BERT에서 최초로 제시되었으며 입력된 두 문장이 서로 이어지는 문장인지, 랜덤하게 샘플링된 문장인지 이진분류하는 pretext task를 통해 구현되었다. 하지만 RoBERTa에서 NSP가 모델 성능에 거의 영향을 미치지 못하는 pretext task라는 점이 밝혀지면서 ALBERT에선 SOP(Sentence Order Prediction)으로 대체되었다. 이는 자연어에서 부정샘플(주어진 데이터와 관련이 없는 샘플)이 랜덤하게 다른 코퍼스에서 추출되는 과정으로인해 난이도가 너무 쉬어져서 발생한 문제를 해결한 것이다. SOP는 동일 코퍼스의 문장들의 순서를 섞기 때문에, 문장 간 주제가 동일하여 문장 간의 상대적 정보를 파악하는 것이 어렵다. 즉, 모델은 SOP를 통해 문장 간 의미적 관계를 다루게 된다.
CV
이미지 분야에서 사용되는 PRP로는 PIRL에서 사용한 Jigsaw가 대표적이다.
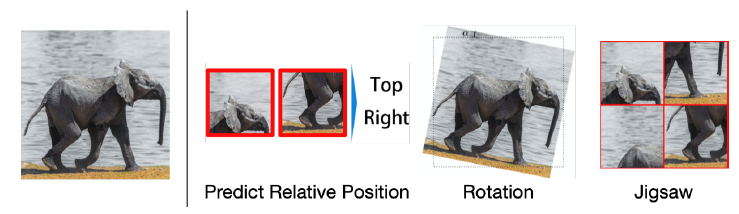
이미지에서 국소부분이란 위 예시에서 볼 수 있듯이 이미지를 잘라서 만들어낸 패치일 것이다. 만약 모델이 이미지를 제대로 다루고 있다면 회전하고, 자르는 등의 임의의 변환 작업을 수행하더라도 패치들 간의 상대적 관계를 잡아낼 수 있어야 한다. 즉, 원본 이미지와 위 그림에서의 Jigsaw 이미지는 매우 유사하도록 인코딩 되어야 한다. PIRL에선 그래서 변환작업을 통해 생성된 이미지를 긍정샘플로, 다른 이미지들을 부정샘플로 간주한다. 그리고 위에서 제시한 NCE 목적함수를 사용하여 인코더(ResNet50)을 최적화하게 된다.
3-1-2. Maximize Mutual Information(MI)
Mutual Information은 상호정보량으로 두 분포가 서로 얼마나 독립적이지 않은지 판단하는 지표이다.
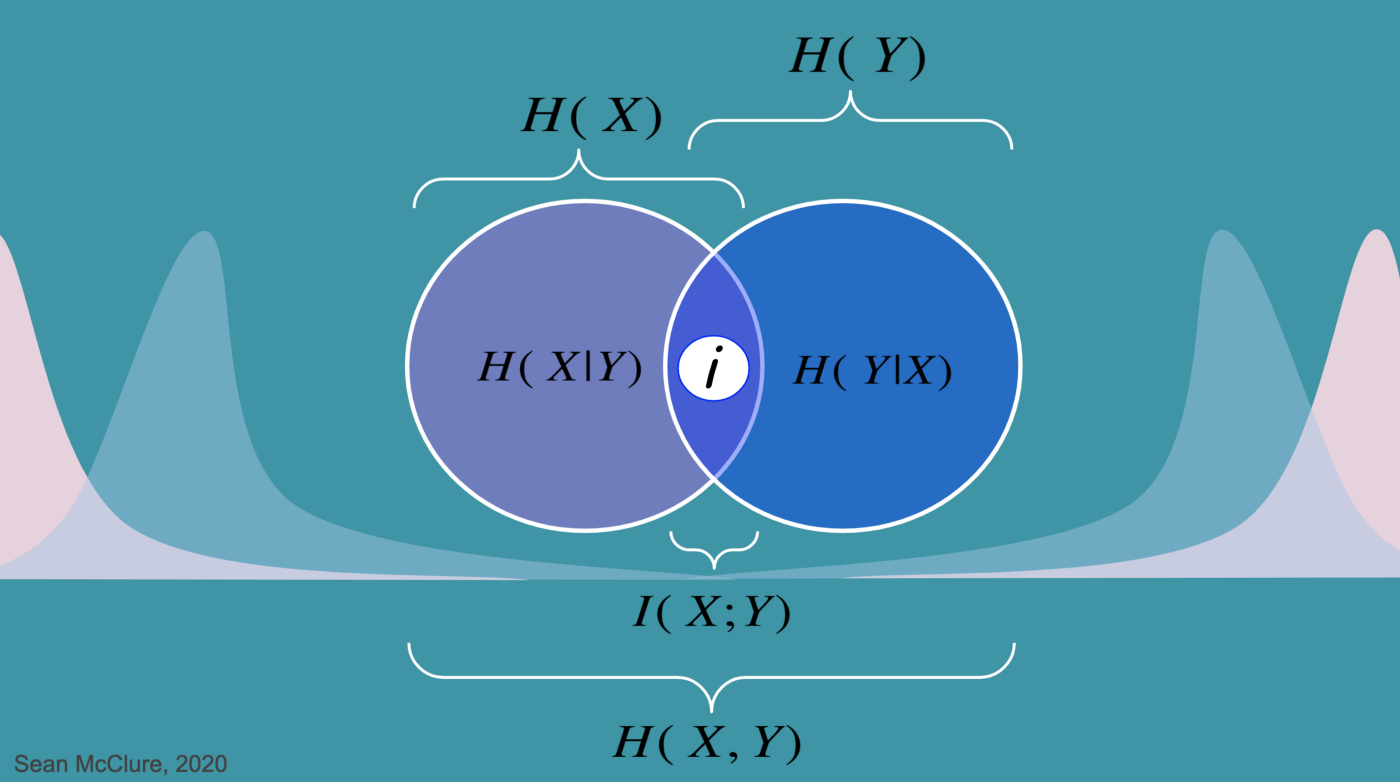
즉 위 표와 같이 두 분포가 가지고 있는 정보들 중에서 사실은 공유하고 있는 정보의 양을 측정하는 지표이다.
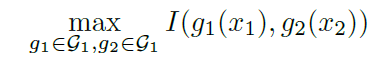
MI에선 결국 관련된 두 데이터 간의 공유하는 정보가 최대로 하도록 인코더를 학습시키게 된다. 하지만 이 과정에서 정보량을 계산하는 다른 지표들이 그렇듯이 연산량이 엄청 많기 때문에 I의 하한선을 최대화하는 위의식에서 NCE 목적함수로 대체하여 사용한다.
Deep InfoMax
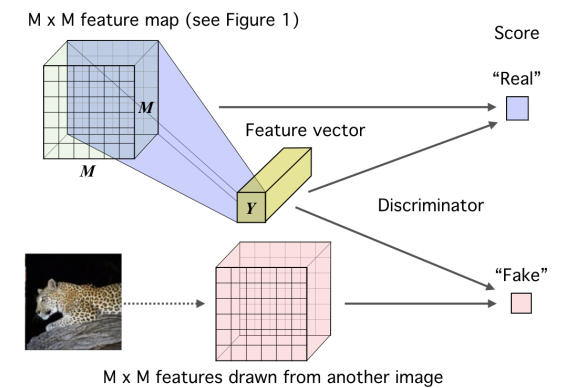
Deep InfoMax는 contrastive learning에서 처음으로 MI를 도입한 모델이다. 이 모델은 local patch와 global context 간의 MI를 최대화하는 pretext task를 수행하였다. 이를 구성하는 요소들은 다음과 같다.
- 실제 이미지 x
- encoder f :실제 이미지 에서 크기의 패치에 대한 feature vector를 생성하는 인코더.
- summary function g: 인코더를 통과한 feature map에 대해 전체 이미지의 정보를 담고 있는 context vector s를 생성하는 인코더
- 다른 이미지 와 context vector
- 손실 함수
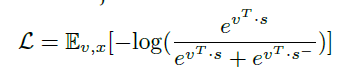
전체 과정은 위 이미지처럼 인코더를 통과하여 생성된 f에서 특정 패치의 feature vector와 context vector의 내적은 작아지도록(가까이 맵핑되도록) 다른 이미지의 context vector와 현재 이미지의 context vector의 내적은 커지도록(멀리 맵핑되도록)한다.
이를 통해 각 이미지의 패치들이 context vector의 주변부에 맵핑되면서 모델은 전체 이미지와 부분 이미지들의 관계를 파악하게 된다.
3-2. Instance-Instance
Context-Instance는 결국 긍정샘플로 지역적 정보를 instace로 활용하고 있다. 즉, 부정샘플은 다른 데이터로 고정한채 긍정샘플을 어떻게 생성할지 집중한다. 하지만 후속연구들에서 metric learning과 연관지으면서 실제로는 부정샘플을 처리하기 위해 인코더 구조에 집중해야 한다는 지적들이 나온다. 이에 맞추어서 instance-instance는 확실한 긍정샘플을 가지고, 부정샘플을 효과적으로 활용하는 방안을 모색하는 방법이다. MLM에서도 부정샘플이 제대로 추출되지 않아 MLM의 효과가 거의 없다고 지적된 것을 상기하자.
이미지를 예시로 들어보자면 이미지의 일부분끼리 비교하는 것이 어떻게 유용한 방법론이 될 수 있을까? 분류 태스크에서는 context-level보다 instance level이 중요하기 때문이다.
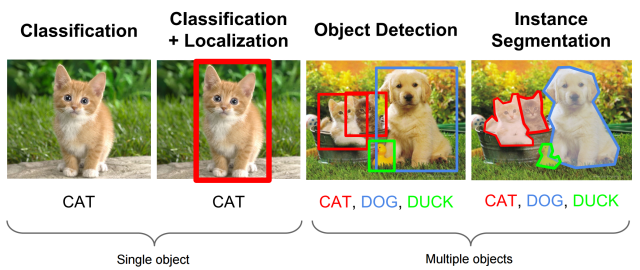
위에서 볼 수 있듯이 하나의 이미지에 하나의 레이블을 붙이는 것은 사실 인간의 편의를 위해 고른 방법이다. 왼쪽 고양이 그림에도, 고양이, 풀, 땅 등 다양한 요소가 있지만 우리는 이미지의 일부분에 고양이가 있기 때문에 고양이라고 레이블링하게 된다.
즉, 이미지 분류에서 중요한 요소는 context-level로 전체 이미지에 나타나는 색, 질감 등의 요소가 아니라 instance level의 이미지의 일부분이다. 이는 텍스트 분야에서 감성 분석 시 일부 단어가 크게 영향을 미친다는 점에서도 일맥상통한다.
3-2-1. Cluster Discrimination
instance-instance contrast는 클러스터 기반 방버론에서 다뤄졌다고 한다. 이와 관련된 논문이 DeepCluster이다. 이미지 분류를 클러스터링으로 생각해보면, 동일한 클래스의 이미지들은 representation들이 비슷한 공간에 맵핑되어 있어야 한다. 이때 지도학습에선 레이블을 이용해서 동일 클래스를 임베딩 공간에서 가까이 맵핑되도록 만든다. 하지만 자기지도학습의 환경에선 레이블이 없기 때문에 이러한 학습이 불가능합니다.
그로인해 DeepCluster에선 두 단계를 통해 학습이 진행됩니다.
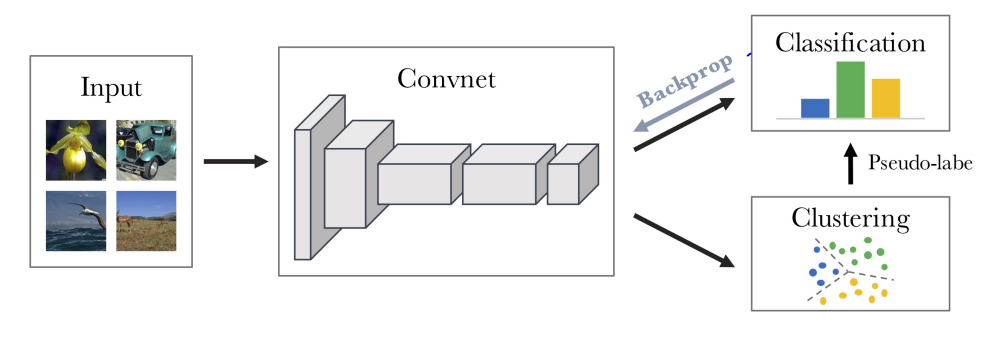
1. 이미지가 convnet을 통과하여 생성된 representation에 대해 k-means 알고리즘을 통해 pseudo label을 부여합니다.
2. discriminator가 convnet을 통과한 representation을 이용해 레이블을 예측합니다. 그리고 1에서 생성된 pseudo label과 손실함수를 계산하여 convnet까지 역전파합니다.
위 과정을 반복하면서 학습이 진행됩니다.
이전에 이야기했던 VQ-VAE 역시 이미지를 임베딩하여 representation을 생성하고 이와 가장 유사한 벡터를 임베딩 테이블에서 찾아 생성에 이용한다는 점에서 DeepCluster와 비슷한 점이 있다.
하지만 이러한 2-stage 클러스터링 방법론들은 기본적으로 속도가 느리고 성능이 좋지 못하다는 한계가 있었다. 이를 개선한 모델들이 instance discriminatio-based 방법론들로, 오늘 중점적으로 다룰 CMC, MoCo, CimCLR이다. 세 모델 모두 오랜 시간이 걸리는 클러스터링 단계를 없애고, 효과적인 augmentation 전략을 이용하여 성능을 끌어올렸다.
3-2-2. Instance Discrimination
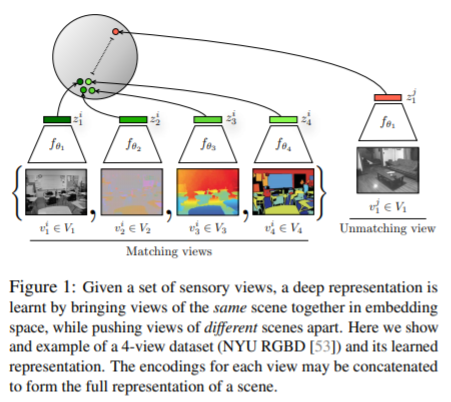
CMC(Contrastive Multiview Coding)
CMC는 다양한 관점에서 하나의 이미지에 접근하여 긍정샘플을 생성하고, 다른 이미지에서 부정샘플을 생성하는 모델이다. 이때 다양한 관점이란 색, 각도, 밝기, 뎁스 등의 요소를 의미한다. 손실함수로는 이전에 소개한 NCE Loss를 그대로 사용하고 있습니다. 이를 통해 다양한 관점의 이미지들은 비슷한 공간에 임베딩 되도록 하고 있다. 이때 다양한 관점이라는 것이 이미지의 일부 요소이므로 이를 instance로 활용하고 있는 모습이다.
위에서 언급한 NCE를 다시 살펴보자.
지금까지 긍정샘플을 추출하는 다양한 방법론들을 이야기 했지만, 부정샘플은 단순히 다른 이미지에서 가져오고 있었다. 어떻게 하면 부정샘플을 효과적으로 가져와서 손실함수를 구성할 수 있을까? 즉, 정말 현재 샘플 x와 다른 부정샘플의 양을 늘릴 수 있을까?
현재까지 이야기한 내용을 요약하면 다음과 같다.
- : 전체 이미지에 대해 인코딩하여 query를 구성하는 인코더()
- : 긍정 및 부정 샘플을 생성하여 key를 구성하는 인코더()
- 위 두가지 요소를 조합하여 생성한 손실함수 infoNCE :
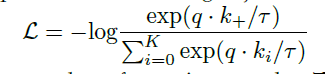
하지만 이 과정에서 컴퓨팅 자원이 제한되어 있기 때문에 key는 미리 생성하여 저장하고 학습과정에서는 만 업데이트 된다. 즉, GAN에서 생성자와 판별자가 따로 학습되는 것처럼 와 가 학습된 정도가 달라지는 문제가 발생한다.
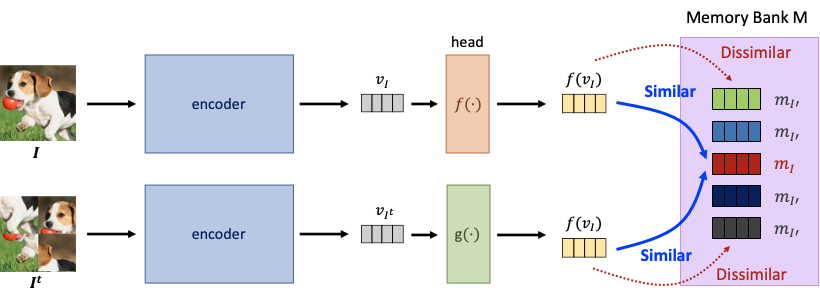
MoCo
기존의 부정샘플을 다루던 방식은 아래와 같이 총 두가지이다.
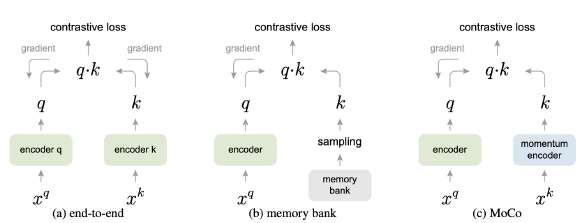
- end-to-end :동일 미니 배치 내의 샘플만 부정샘플로 이용하게 되어 부정샘플의 갯수가 제한적이다(vram에 올릴 수 있는 데이터의 수는 제한적이다.).
- memory bank : 미리 부정샘플을 만들어 사용하는 방법으로 key를 생성하는 는 와 함께 학습되지 못한다. 이로인해 GAN의 생성자와 판별자의 경우처럼 두 인코더가 비슷하게 학습되지 않아 학습이 불안정하다.
MoCo는 이를 개선하여 1. 충분한 부정샘플(65536개)를 사용하면서도, 2. 를 학습하는 방법을 마련한 모델이다.
그 과정은 다음과 같다.
- x를 두가지 인코더로 각각 인코딩하여, q와 k를 생성한다.
- 이번 배치에 새로 생성된 k는 기존에 생성된 k와 함께 저장하고 오래된 k는 제거한다(65536개 유지).
- 동일한 x에서 생성된 q와 k를 긍정샘플로 간주하고 이외의 k를 부정샘플로 간주하여 InfoNCE를 계산한다.
- 손실함수를 에 대해 업데이트한다.
- 다음 식을 이용해 를 업데이트 한다. 즉, 는 일부분 를 따라가게 된다.
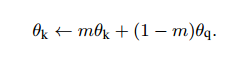
하지만 MoCo 역시 한계점은 존재한다. 긍정샘플이 단순히 다른 인코더를 통과한 representation이라는 점이다. 심지어 두 인코더는 서로 비슷한 파라미터를 가지도록 학습 과정이 짜여져 있다. 이로인해 긍정샘플이 원래 샘플과 임베딩 공간에서 비슷하게 위치하는 것이 너무 쉬운 태스크가 되었다. 이를 PIRL에서 jigsaw augmentation을 통해 개선한 것이다.
SimCLR

MoCo가 부정샘플의 수와 질을 획기적으로 개선했다면, SimCLR은 긍정샘플의 질을 개선하였다. 이는 CMC에 end-to-end를 도입한 것이다.
- CMC처럼 10가지 augmentation을 도입하여 긍정샘플 생성
- MoCo와 다르게 배치 사이즈를 8196까지 늘려 부정샘플 생성
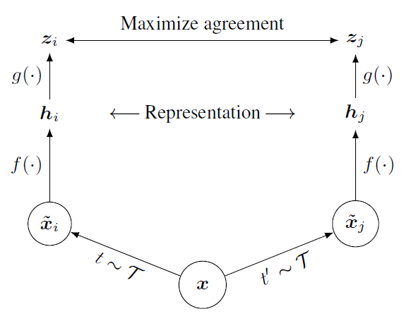
즉, 위 그림과 같이 단순한 end-to-end 모델을 대용량 gpu에 학습시킨 것이다. 그런데 이처럼 다양한 augmentation이 실제로 중요할까?
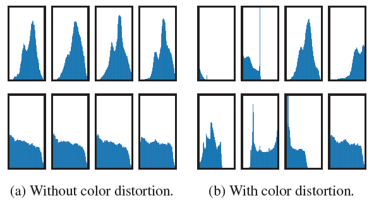
한가지 예시로 color distortion 즉, 색 왜곡에 대한 ablation analysis를 보면 그 효과가 명확하다. 위 그림은 행 별로 두 이미지의 다른 crop이 인코더를 통과하여 가지는 픽셀별 분포를 보여주고 있다. 왼쪽은 색 왜곡을 진행하지 않은 상태이고, 오른쪽은 색 왜곡을 넣은 상태이다. 색왜곡을 넣지 않으면 전혀 다른 crop 간에도 비슷한 분포를 보이고 있는데, 이는 색 분포를 학습했기 때문이다. 즉, 인코더가 이미지의 시각적인 특징을 잡아내지 못하고 색 분포만 잡아낸 것이다. 이에 비해 오른쪽에선 다른 crop 간에 다른 분포를 보이면서 서로 다른 crop 간 다른 시각적 특징을 잡아내는 모습을 보이고 있다.
BYOL(Bootstrap Your Own Latent)
기존의 Instance Discriminator 모델들이 부정샘플을 사용한 이유는 다음과 같다.
다양한 관점의 긍정샘플이 학습 과정에서 관점과 관계없이 동일한 representation을 생성하지 않도록 방지하기 위해서
즉, augmentation을 통해 이미지의 다양한 요소를 representation에 녹여내려 했지만, 긍정샘플만 사용할 경우 인코더가 augmentation을 무시하고 context-level의 representation을 만들어내게 된다. 이를 방지하기 위해 전혀 다른 context를 가지는 이미지를 가져와 부정샘플로 삼는 분류문제로 전환한 것이다.
하지만 이를 위해선 많은 부정샘플이 필요해지고, augmentation의 방법론 역시 효과적으로 개발되어야 해서 쉽지 않은 과제들이 산재한다. 이를 타개하고자, BYOL은 단순한 아이디어를 가져온다. 그 아이디어는 다음과 같다.
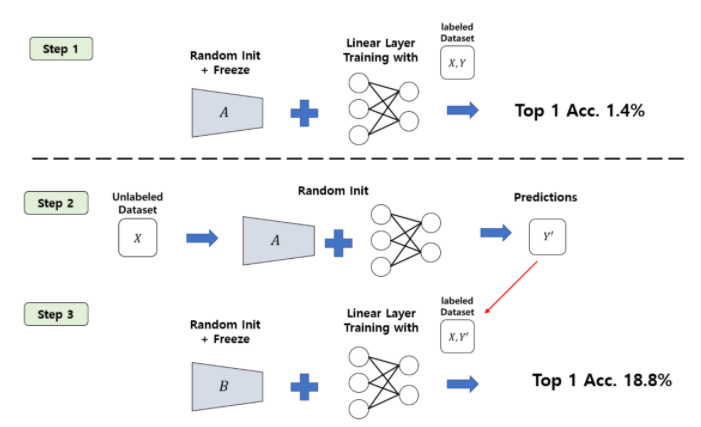
전혀 학습되지 않은 네트워크 A를 가지고 와서 이미지를 분류하여 pseudo label을 생성하도록 한다. 당연히 학습되지 않았으므로 성능이 좋지 않다. 하지만 재밌는 점은 이 레이블을 이용해 학습되는 네트워크 B를 학습시키면, 성능이 비약적으로 상승한다. (나도 이게 가능한게 솔직히 이해가 되지 않는다.)
이를 이용하면 적당히 학습된 네트워크 A를 통해 pseudo label을 생성하고 이를 이용해 우리가 원하는 네트워크 B를 학습시키는 과정을 반복하면, 굳이 부정샘플이 없어도 효과적인 SSL이 가능해진다는 것을 의미한다.
정리하면 다음과 같다.
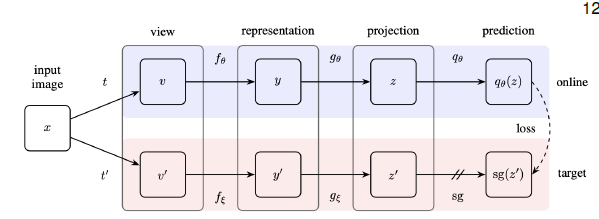
- target network : 손실함수에 의해 직접 학습되지 않는 네트워크, pseudo label을 생성하는 역할
- online network : 실제로 학습시키고자 하는 네트워크
- encoder : 이미지에서 representation을 생성하는 레이어, 실제로 SSL을 통해 학습시키고자 하는 네트워크
- projector : representation을 분류 태스크에 적합한 공간으로 맵핑시키는 레이어, MLP 사용
- predictor : 실제로 레이블을 분류하는 레이어, MLP 사용
- 손실함수 :
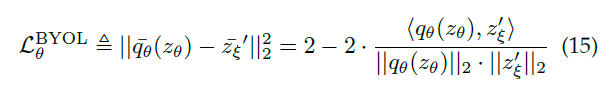
기존의 NCE를 사용하지 않고, L2 norm을 사용하고 있음.
위 요소들을 통해 online network는 학습되게 된다. 또한 이렇게 학습된 online network의 파라미터를 이용해서 target network의 파라미터를 일부 업데이트 하게 되는데, 이는 MoCo의 방식과 유사하다.
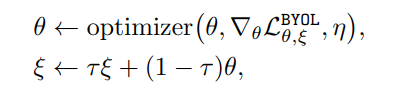
이를 통해서 BYOL은 다음과 같은 contribution을 가질 수 있었다.
- 작은 배치 사이즈에 강건한 성능 : 부정샘플을 사용하지 않기 때문에, 배치 크기가 작아도 SimCLR, MoCo와 달리 성능 저하가 크지 않다.
- 높은 최종 성능
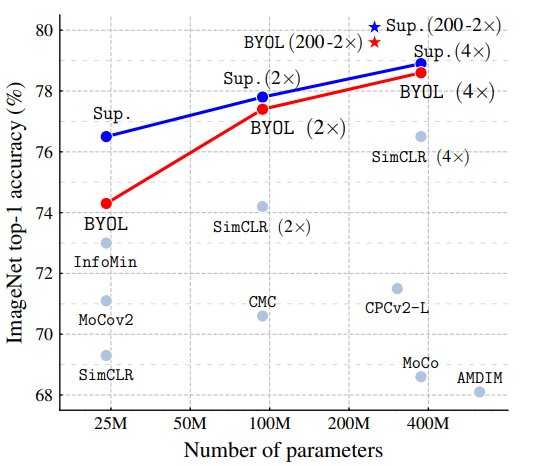
기존의 SSL 방법론들이 유의미하지만 지도학습 방법론에 비해 조금 낮은 성능을 보였지만, BYOL에 이르러서 기존 모델들과 유사한 성능을 보이기 시작했다.
3-3. Pros & Cons
Contrastive Learning은 기본적으로 분류문제를 downstream task로 염두에 두고 있다. 그래서 인코더만 모델 구조로 가지고 디코더가 존재하지 않는다. 이는 COntrastive Learning 모델들이 분류 문제에서 아주 좋은 성능을 보일 수 있게 했지만, 또한 적용가능한 downstream task의 범위가 상당히 좁아지게 했다. 또한, 다음과 같은 해결하기 힘든 문제들이 산재해있다고 한다.
-
NLP 분야의 적용
Contrastive learning을 적용하고 있는 자연어 모델은 대부분 BERT에 기반하고 있다고 한다. 심지어 BERT에서도 contrastive leaning은 지도학습으로 fine tuing 과정에서 적용되고 있다. 자연어에서 아직 pretrainig 단계에서 효과적으로 contrastive learning을 적용한 모델은 없다. -
샘플링 효율
contrastive learnig에선 부정샘플 추출이 필수적이다. 최근들어 BYOL 등과 같이 부정샘플을 사용하지 않는 모델이 발표되기는 했으나, 아직 부정샘플의 역할이 명확하지 않은 상태에서 함부로 부정샘플을 지우기도 어렵다. 이 상황에서 편향되지 않으면서 메모리와 시간 측면에서 효율적인 샘플링 방법이 필요하다. -
Data Augmentation
data augmentation은 contrastive learning의 성능 향상에 중요 요소이지만 아직 왜 성능이 향상되는지 그 원리가 규명되지 않았다. 또한, discrete한 데이터를 다루는 NLP에서 data augmentation이 활발히 사용되지 못한다는 점도 문제로 작용한다.
4. Generative-Constrastive(Adversarial) SSL
adversarial representation learning은 generative learning에서 시작되었다. generative learning이 요소별 목적함수로 구성되어 있어서 high level abstraction을 학습하는데 어려움을 겪는반면, adversarial learning은 분포 간의 차이를 목적함수로 구성하고 있어 high level abstraction에 보다 유연하다. 또한, 인코더-디코더 구조를 취하고 있기 때문에, contrastive learning에 비해 다양한 태스크에 적용될 여지가 있다.
즉, Adversarial SSL은 generative와 contrastive learning의 장점을 모두 포용할 수 있는 방법론이다. (물론 디코더의 존재로 학습이 어렵다는 단점이 있다.)
4-1. Generate with Complete Input
GAN으로 대표되는 이 방법론은 온전한 데이터를 넣어서 실제 데이터의 분포를 학습하는데 초점을 맞추고 있다. GAN류 모델들은 VQ-VAE2 이전까지 이미지 생성분야에서 거의 항상 SOTA를 달성했다. 그러나 이는 어디까지나 "생성"에 대한 내용이고, representation learning으로 시선을 돌리면 조금 이야기가 달라진다. 오토인코더나 VAE에서 잠재벡터 혹은 분포가 모델 내부에 명시적으로 존재하는 것에 비해 GAN은 잠재벡터가 모델 내부에 존재하지 않는다.
AAE(Adversarial Auto Encoder)
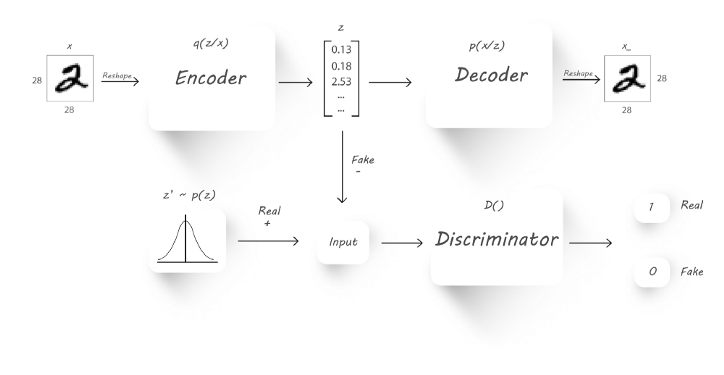
이를 보완하고자, AAE가 등장했다. AAE는 위에서 볼 수 있듯이 기존의 오토 인코더 구조와 GAN 구조를 결합한 모양이다. 목적함수로는 l2 norm에서 GAN의 Cross Entropy로 바꾸었다. 이는, 오토인코더의 l2 norm이 요소별 연산이기 때문에, high-level abstraction에 취약한 점을 개선하고자 한 것이다. 이를 판별자를 통해 high-level abstraction이 원활해지도록 한 것이다. 또한 GAN처럼 reconstruction loss를 사용하고 있다.
AAE를 통해서 GAN은 기존의 입력 데이터를 복원하는데 초점을 맞추던 태스크에서 벗어나 새로운 프레임워크를 가질 수 있게 되었다.
- Generator G : 디코더로 동작하며, prior로부터 이미지를 생성
- Encoder E : GAN에 없던 파트로, 실제 데이터를 representation 로 맵핑하는 레이어. 즉, representation learning의 측면에서 학습시키고자 하는 레이어.
- Discriminator D : 실제 데이터에서 인코딩한 representation과 prior에서 생성한 representation 간의 차이를 판별하는 분류기.
AAE의 학습 목표는 결국 로 학습되도록 하는 것이다. 즉, 인코더는 디코더가 실제 데이터를 생성할 수 있는 유의미한 representation을 전달하는 역할을 하게 된다.
4-2. Recover with Partial Input
실제 데이터의 일부를 왜곡하여 입력값으로 사용하고 이를 복원하도록 학습시키는 이 방법론은 기존의 BiGAN 등이 AAE의 구조를 이용해 잠재벡터를 명시적으로 표현하고자 한 것에 비해, 전혀 다른 방향성을 가지고 있다.

즉, 위의 이미지에서 보이는 것처럼 원본 이미지에서 색을 빼거나, 화질을 낮추거나, 일부 영역을 마스킹하고, 이를 원본 이미지로 복원하는 작업을 수행한다. 이는 BERT 등 자연어처리에서 사용되는 Denoising AutoEncoder와 유사한 태스크를 수행하게 된다(다만 적대적 학습 환경을 취한다는 것이 다르다. 이미지는 연속된 값을 가지는 데이터니까.).
4-3. Pre-Trained Language Model
자연어 처리 분야에서 적대적학습을 취하는 것이 활발히 연구되지 않았다. 그 이유는 자연어의 특성 상 데이터에서 약간의 변화도 (토큰 하나의 변화) 의미적으로 큰 변화를 가지고 있기 때문에 적대적 학습을 적용하는 것이 쉽지 않기 때문이다. 하지만 Electra는 이를 성공적으로 도입했다.
ELECTRA
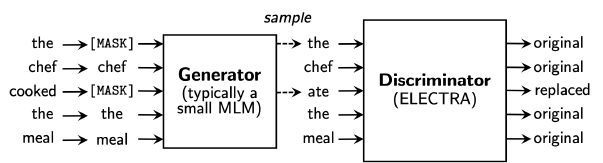
학습 과정은 다음과 같다.
1. 입력 데이터에서 일부 단어를 마스킹하여 생성자에 입력한다.
2. 생성자가 마스킹된 단어를 예측한다.
3. 판별자가 어떤 토큰이 생성되었는지 분류한다. 즉, 이진 분류 태스크를 수행한다.
ELECTRA는 BERT와 유사한 컴퓨터 자원을 소모하면서도 효과적으로 적대학습을 도입했다. 이는 생성자로 작은 모델을 사용하고, 기존의 모델이 수만개의 클래스를 가지는 소프트맥스를 수행하던 것을 이진분류를 수행하는 시그모이드 함수로 전환하여 가능해진 것이다. 하지만 이렇게 전환하는 과정에서 전반적인 의미를 파악하는 성능을 놓치게 되어 SOTA를 달성하지는 못했다. 심지어 토큰이 discrete한 데이터이기 때문에 역전파가 불가하여 생성자와 판별자가 함께 학습되지 못한다.
5. Conclusion
5-1. SSL
SSL이 가지는 장점은 다음과 같다.
- 레이블링된 데이터가 적더라도 준수한 성능
- 우수한 일반화 성능
- 적대적 학습에 비해 안정적 학습
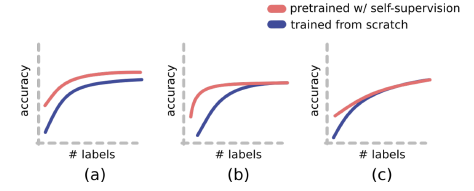
실제로 지도학습과 성능을 비교해보면 위의 상황에서 c의 상황이 발생한다고 한다. 즉, 레이블링 된 데이터가 어느정도 수준 이상으로 확보된 상태에선 지도학습과 더이상 성능차이를 보이지 못하면서 학습된다. 우리가 원하는 것은 a나 b겠지만, 그렇지 못하다는 것이다.
하지만 그럼에도 불구하고 기존의 지도학습이 의도치않은 패턴을 학습하거나, OOD 문제에 취약한 것에 비하면 SSL은 안정적인 모델을 만들 수 있다는 점에서 매력적인 분야라 할 수 있을 것이다.
참고
본 글에 소개된 다양한 모델의 논문들(arxiv 기준)
CVPR2020에서의 SSL에 대한 소개 발표
투빅스 13,14기 생성모델 심화세미나
sharifa님의 자기지도학습에 대한 설명
Auto-Regressive Generative Models (PixelRNN, PixelCNN++)
Flow-Based Model에 대한 설명
VQ-VAE에 대한 설명 블로그
XLNet에 대한 ratsgo님의 설명
PIRL에 대한 hyeonni님의 설명
MoCo에 대한 설명 블로그
SimCLR에 대한 설명 블로그
BYOL에 대한 설명 블로그
AAE에 대한 설명 블로그

2개의 댓글

너~~무 잘 들었습니다.
자기지도학습
- 생성적 모델
- 판별적 모델
- 생성-판별적 모델
생성적 모델
- 기본적인 Language Model과 유사
- AutoRegressive Model과 같은 단방향 모델
- 혹은, BERT 사전학습에 쓰이는 MLM, 즉 양방향 모델
판별적 모델
- 다른 라벨(혹은 다른 특성)을 갖는 두 이미지를 판별하면서, 서로 확실하게 구별되게끔 Embedding Space에 적당히 분리돼서 놓이도록 인코딩을 진행
- Context-Instance의 관계를 주로 파악하는 PRD(상대 위치 예측) 태스크를 pre-text task로 들 수 있음.
- 즉, 이미지에 여러가지 노이즐 주더라도 같은 데이터라면 비슷한 곳에 임베딩되게끔 학습.
- 단, 이는 NCE 학습함수에 보이는 것처럼 긍정 샘플에만 주력하는 한계 존재.
- Instance-Instance 레벨에는 Moco, SIMCLR 등 유명한 모델이 있음.
- 마찬가지로 다른 Class를 지니는 친구들은 다른 곳에 놓이게끔
생성-판별적 모델
- 디코더가 있어서 학습하긴 좀 어려움(인코더만 쓰고싶음..ㅠㅠ)
- GAN은 애초에 고수준 잠재벡터를 다루기 때문에 임베딩 스페이스를 본격적으로 다루기 힘듬(implicit..)
- Adversarial Auto Encoder 등을 이용해, 분류 태스크와 생성 태스크를 같이 수행할 수 있음.
- 역시, 이미지에 노이즈를 줘서 복원하는 쪽으로 진행하는 pre-text task
기타
- Contrastive Learning은 의외로 Fine-tuning에도 쓰일 수 있음.
- 가령, 기본적인 CE Loss와 SCL(Supervised Contrastive Learning) Loss를 같이 사용한다든지..
강의 준비하시느라 고생 많으셨습니다! 좋은 강의 고맙습니다 :)
(1) Generative : 데이터 자체의 분포를 학습하므로 광범위한 task를 잘 수행하지만, Contrastive와 비교하여 분류 성능이 떨어지고, 목적함수인 reconstruction loss가 데이터 분포의 영향을 많이 받고 고수준 abstraction을 잘 수행하지 못한다는 단점이 존재한다. # AR 모델, AE 모델
(2) Contrastive : 기준 데이터와 유사하면 가깝게, 유사하지 않다면 멀리 맵핑되도록 데이터들을 비교하면서 학습이 진행된다. Contrastive는 context-instance와 instance-instance로 분류되는데, 전자에서는 부정샘플을 고정해두고 긍정샘플을 생성하는 데 집중한다면, 후자에서는 부정샘플을 활용하는 방안에 집중한다(예를 들어, 이미지 분류에서도 context-level보다는 instance-level이 더욱 중요하기 때문). Generative와 달리 downstream task로 분류 문제를 상정하고 학습을 진행하기 때문에 수행할 수 있는 task 범위가 넓지 않고, NLP 분야에의 적용이 어렵고, 부정샘플을 효율적으로 활용해야 하며, 데이터 증강을 잘 사용하지 못한다는 단점이 존재한다.
(3) Adversarial : Generative와 달리 데이터 분포 간 차이 자체를 목적함수로 정의하여 고수준 abstraction에 용이하며, Contrastive보다 광범위한 task를 잘 수행할 수 있다(Generative와 Contrastive의 장점 각각 차용).