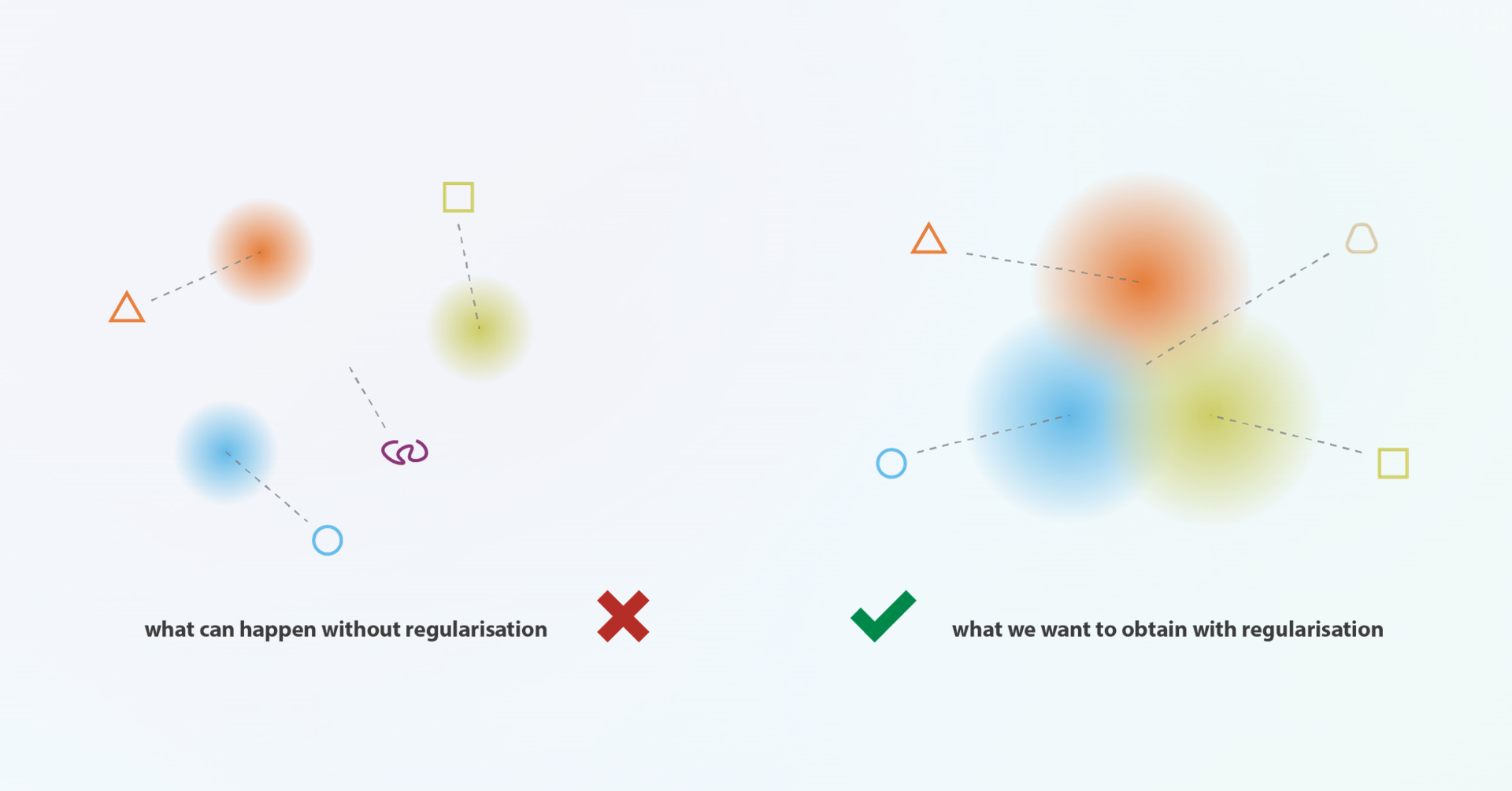
본 글에 첨부한 슬라이드는 이활석님의 '오토인코더의 모든 것'의 강의 자료에서 발췌하였음을 밝힙니다.
Apporach to VAE
본 글에서는 VAE(Variational Auto Encoder)가 무엇인지, 어떤 식으로 접근하면 좋을 지를 다룰 예정입니다.
이를 위해, 먼저 통계 추론의 핵심인 MLE의 관점으로부터 딥러닝의 학습을 간단히 다룹니다.
그 후, Auto Encoder와 Variational Auto Encoder의 핵심적인 차이를 살펴본 뒤, 본격적으로 VAE에 대해 기술합니다.
Deep learning from MLE's point of view.
First, There is Back_prop's point of view.
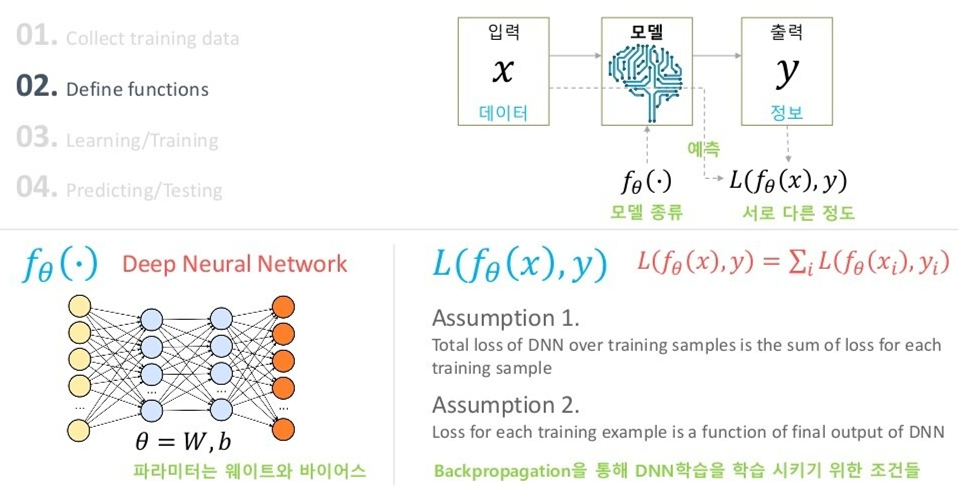
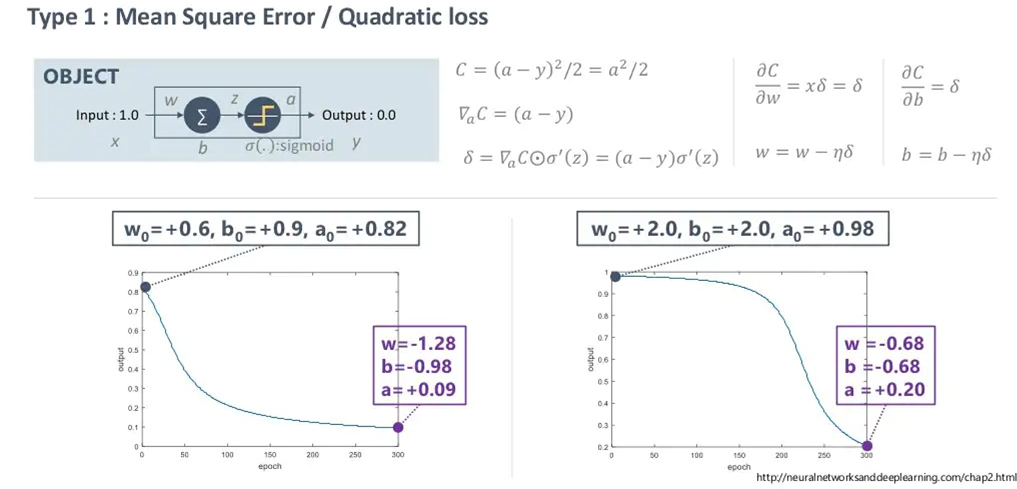

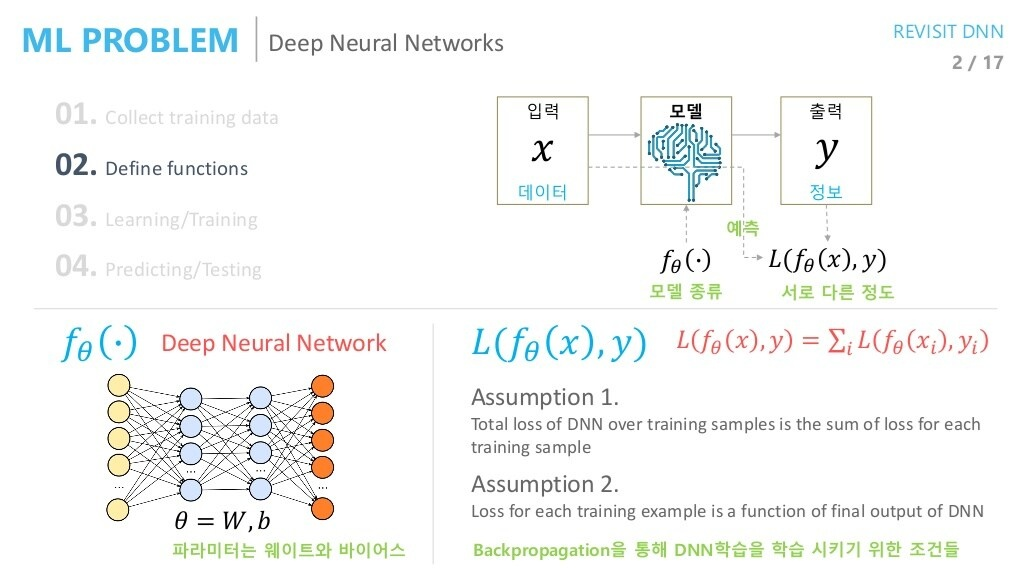
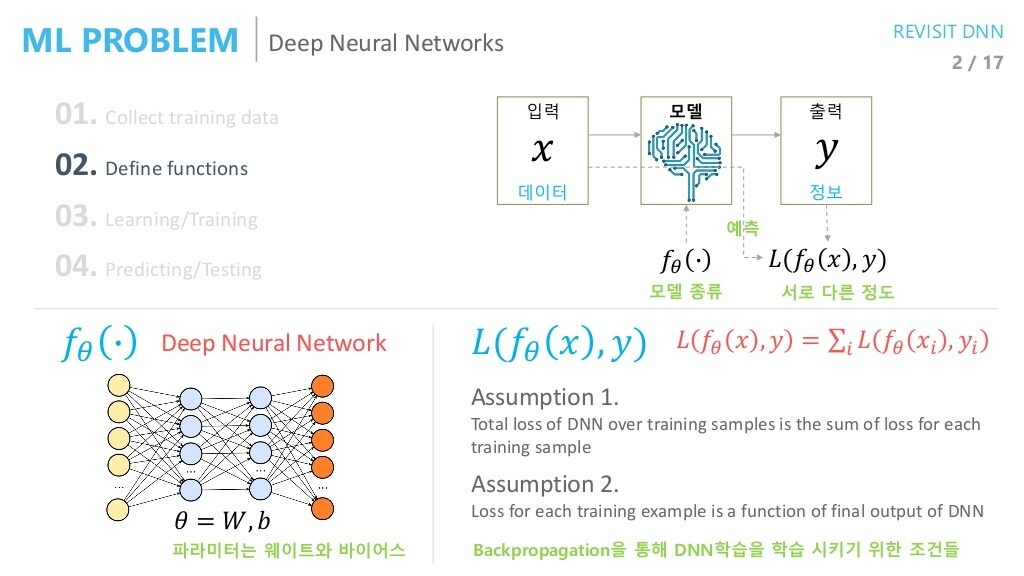
우선, 딥러닝의 학습에 그래디언트를 이용한 역전파 방식이 지배적으로 사용되는 것은 모두 잘 알고 있을 것입니다. 역전파 관점에서 MSE LOSS와 CROSS ENTORPY LOSS의 차이가 위에 나타나 있습니다(Loss: -Cost).
딥러닝의 학습에 MLE의 접근법을 적용시킬 경우 역전파 기반 방법과 어떻게 차이가 있을 지에 대해 다루어봅시다.
MLE's point of view

여기서는, 네트워크의 출력 값에 대한 해석이 중요합니다.
딥러닝 태스크에서는, 우리가 원하는 출력 가 정답과 가까워지기를 희망합니다. 그를 위해 역전파를 이용할 때에는 출력()과 정답()이 다른 정도를 Loss function으로 정의하고, 두 값의 차이를 줄이는 방향으로 학습을 진행했습니다.
MLE 관점에서는 약간 다릅니다.
네트워크의 출력 값(확률 분포) 가 주어졌을 때, 정답 가 나올 확률(likelihood)가 최대가 되기를 원합니다.
즉, 이 경우 Deep Neural network 뿐만 아니라, 분포 가 어떤 분포를 따를 지 가정을 하고 가야 합니다.
해당 분포 는 가우시안을 따른다. 혹은 베르누이를 따른다. 등등..
예를 들어, 확률분포 가 주어졌을 때 타겟 가 나올 확률인 를 Gaussian Distribution(가우시안 분포)를 따른다 가정합시다. 또한, 가우시안 분포의 표준편차는 편의상 없다고 가정합시다.
그러면, 실질적으로 Deep Neural Network의 출력 은 다름아닌 가우시안 likelihood에 필요한 parameter(평균)을 추정하는 것으로 해석할 수 있습니다.
즉, 네트워크의 출력이 가우시안분포의 '평균'이 됩니다.
이를 나타내는 것이 아래의 그림입니다.
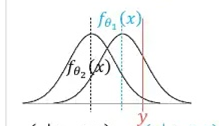
만약 최초의 네트워크의 출력 이 정해진다면, 이는 가우시안 분포의 평균이라 가정했으므로, 분포 하나가 정해집니다. 이 때, 정답 는 fixed point이기 때문에 likelihood 의 값을 구할 수 있게 됩니다.
그 이후, 도출되는 피드백을 바탕으로 네트워크의 출력이 로 개선됐다고 합시다. 그러면, 이 경우 또한 개선된 likelihood 을 얻을 수 있게 됩니다.
그러면, 직관적으로 봤을 때에도 해당 likelihood 가 최대가 될 때에는 네트워크의 출력(즉, 가우시안의 평균) 이 정답 과 일치할 때라는 것을 알 수 있습니다.
역전파 관점에서, 네트워크의 출력 값 와 정답 의 차이를 Loss로 가정하고, 이를 낮추는 방향으로 학습했다면,
MLE 관점에서는, 네트워크의 출력 값 를 likelihood의 parameter로 가정한 뒤, likelihood 를 최대화하는 방향으로 학습을 하는 것이고, 이는 바로 네트워크의 출력 이 정답 와 일치할 때 최대가 됩니다.
해당 관점을 유지한 채로, 기계학습을 진행하기 위한 Setting을 살펴보면, 아래와 같습니다.

likelihood 를 최대화 하는 것은 log likelihood 를 최대화 하는 것과 같으며, negative log likelihood 를 최소화하는 것과 동일합니다. 즉, 이 negative log likelihood를 Loss로 잡고, 최적화를 진행할 수 있습니다.
이 때 를 사용하는 것은 역전파를 수행할 때 제약 조건을 만족시키기 위함입니다. 이에 대해서는 강의 '오토인코더의 모든 것 - 1/3'의 초반부를 참고하세요.
- 수치적 안정성(numerical stability) 또한 이유가 될 수도 있을 것 같습니다.
위와 같이 Loss를 정의하고, 최적화를 수행하면 아래와 같이 최적의 parameter 를 얻을 수 있게 됩니다.
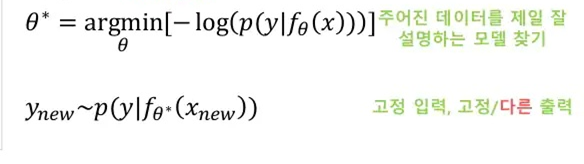
다만, 이게 전통적인 딥러닝 관점(출력 값이 likelihood )과 다른 점은, 구하고자하는 네트워크의 출력이 바로 특정 분포(의 파라미터)가 된다는 것입니다.
관점만 다를 뿐 결과 자체는 동일합니다.
이처럼 분포를 추정하게 될 경우 얻을 수 있는 이점은 기존의 방식이 고정된 입력을 넣었을 경우 고정된 출력 만을 얻을 수 있는 것과 다르게, 출력이 분포가 되기 때문에 이 분포를 토대로 샘플링을 진행할 수 있게 되는 것입니다.
즉, 잘 최적화가 된 parameter 가 있을 경우, 고정된 입력을 넣어도 분포를 토대로 다양한 출력을 이끌어낼 수 있고, 이는 추후에 서술할 VAE가 MLE관점을 주로 채택하는 이유가 되기도 합니다.
위에서 정의한 Loss인 negative log likelihood가 학습을 위한 두 조건을 충족시키는지를 봅시다.
Condition on 를 가정할 경우
즉,
- sample, 즉 들이 독립을 이룬다.
- 각 sample 별로 다른 분포를 따르지 않고 모두가 같은 분포를 따른다.
를 만족할 경우 Deep Neural Network의 2가지 조건을 아래와 같이 만족시킬 수 있습니다.

아무튼, 네트워크의 출력 값을 확률분포의 parameter로 생각한다는 것입니다.
그러면, MLE 관점을 채택했을 경우 Backpropagation 관점이랑 결과가 어떻게 달라질까?

위와 같이 네트워크의 출력 분포를 정규분포로 가정했을 때와, 베르누이 분포로 가정했을 때 likelihood를 전개해보면, 결과적으로 MSE LOSS와 Cross-entropy와 같아지는 것을 볼 수 있습니다.
즉, 결론적으로는 MLE 관점이나 Backprop 관점이나 같습니다.
위에서, 의 출력 값은 특정 분포의 모수이고, 여기서 특정 분포는 label 의 분포를 말합니다. 물론 이미지의 경우 가 거의 continuous한 분포를 갖지만, binary한 분포를 갖는다 가정하는 것이 성능이 더 좋을 때가 있다고 합니다.
(multivariate cases)

다만, MLE관점에서 어떤 Loss를 쓰는 것이 좋을 지를 판단해봅시다.
이는 negative log likelihood에서 의 분포에 따라 정해질 것입니다.
즉, 의 분포가 Gaussian에 가깝다면(즉, 가 continous 하다면) MSE loss를 쓰는 것이 타당하고,
의 분포가 Bernoulli에 가깝다면(즉, 가 discrete 하다면) Cross Entropy Loss를 쓰는 것이 타당합니다.
그렇기 때문에, Continous Value에 대해 MSE loss를 쓰는 이유는 '네트워크의 출력 값이 Gaussian에 가깝다고 가정할 것이기 때문에' 라고 철학적으로 해석할 수 있는 것입니다. 마찬가지로 Classification task의 경우에는 출력 값이 discrete하기 때문에 Cross entropy를 사용한다고 볼 수 있는 것입니다.
즉, MLE 방법을 토대로 Loss를 설정하고 학습을 진행하더라도, 엄밀한 확률 분포에 대한 고려를 모델에 포함하지 않고, Cross entropy(or MSE) loss로 학습을 진행해도 됩니다.
정규분포와 베르누이분포 외의 가정도 할 수 있지만, 수학적으로 복잡합니다. 다만, 딥러닝에서도 MSE와 Cross-entropy 외에 다른 Loss를 사용할 수 있는 만큼, 다른 분포에 대한 고려를 하는 것 또한 의미가 있다고 생각할 수 있습니다.

(네트워크의 출력 값이 likelihood가 되는 게 아닌, 분포의 parameter가 된다는 그림)
아래는, 벤지오 교수의 발표자료에 해당하는 슬라이드이다.

- 를 추정하고 싶다.
- 를 추정하기 위해 로 파라미터화하자. 여기서 parameter 를 구하는 task로 변한다.
- negative log likelihood로 loss를 정하자.
- (를 가우시안으로 가정할 경우), 분포의 평균 를 네트워크의 으로 설정한다. 이 output은 입력 에 따라 결정된다. 그러면 Loss를 위와 같이 MSE와 비슷한 꼴로 바꿀 수 있다(=1이 보통 쓰인다).
- 를 베르누이(혹은 이항분포)로 가정할 경우 위와 같이 Loss를 Cross-entropy와 비슷한 꼴로 바꿀 수 있다.
위의 2. Parametrize
에서, 등식이 성립하려면 가 deterministic function일 필요가 있습니다.
AutoEncoder vs Variational AutoEncoder
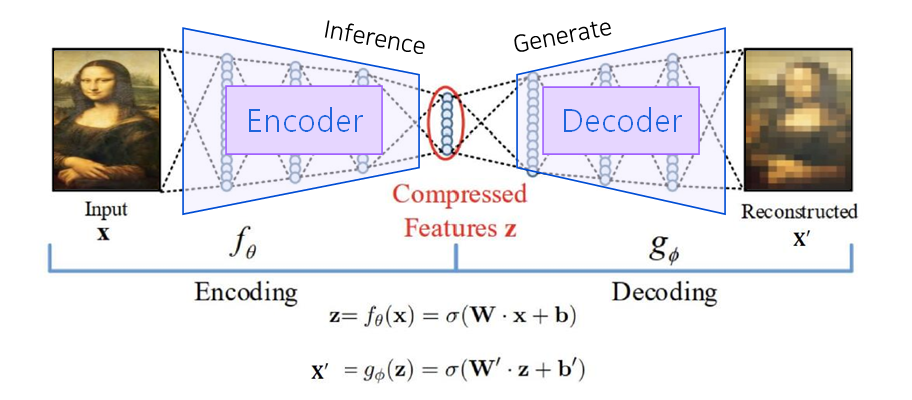
오토인코더는 위에서 보다시피, 특정 input이 주어졌을 때의 상황(output을 input에 가깝게 복원)을 다룹니다. 즉, 차원을 잘 축소하기 위해(매니폴드를 잘 학습하기 위해) Input 라는 target을 decoder에 부여하여 Supervised Learning을 진행한 것 뿐이지, Decoder는 사실상 우리의 관심 대상이 아닙니다.
반면, 후에 서술할 VAE는 그저 Dataset의 분포를 학습하여 이를 토대로 샘플 생성(Generate)을 잘 하는 것을 목표로 합니다. 즉, 이 때는 Decoder가 굉장히 중요한 역할을 합니다.

Manifold Learning
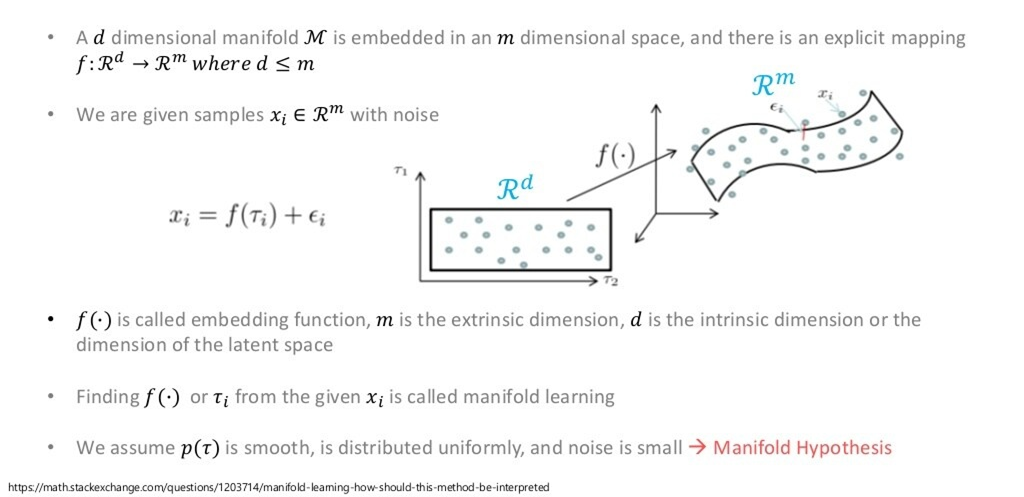
위의 그림에서는 차원을 차원으로 줄이는 과정이 담겨 있습니다.
편의상 그림에서는 , 지만, 실제로 은 훨씬 더 고차원입니다.
가령, image dataset이라면 과 같은 차원으로 이루어져 있을 것입니다.
이 때, 각 data sample을 해당 공간에 뿌리게 되면 고차원 공간의 point가 생기는 것을 볼 수 있습니다. 여기서, Manifold란 차원의 data sample들을, 보다 더 작은 sub space에서도 error 없이 다룰 수 있는 공간을 말합니다.
즉, 고차원 공간에서 데이터를 잘 아우르는 저차원 Manifold를 잘 찾을 수 있다면, 해당 manifold를 잘 펼쳐서 차원 축소를 진행할 수 있다는 개념입니다
원래의 데이터 특성을 잘 유지하는 방향으로 차원을 축소시키는 것이 매니폴드 러닝의 근본적인 목표입니다.
Curse of dimensionality
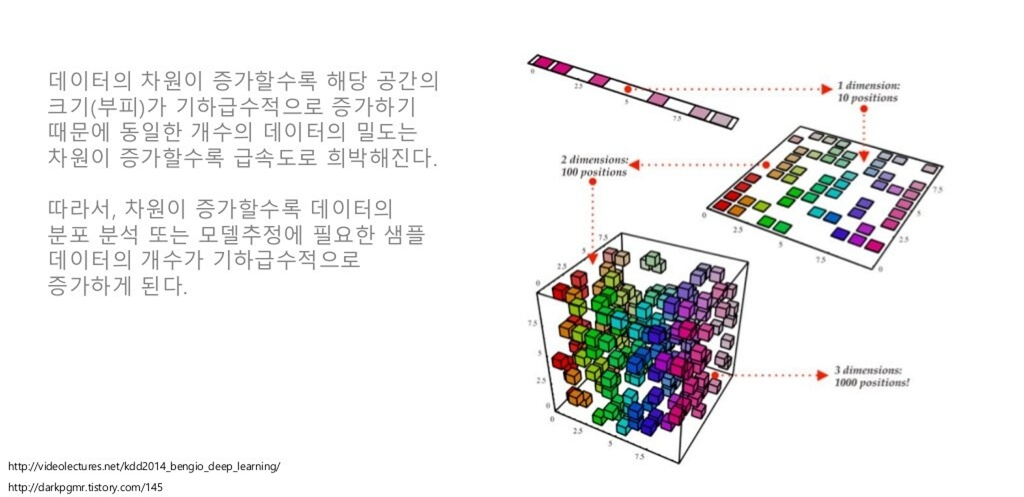
데이터 차원이 증가할 수록, 위처럼 데이터의 밀도는 희박해질 수밖에 없기 때문에 학습, 예측 등이 정상적으로 모델링 될 수가 없습니다.
하지만, 아래 그림과 같이 고차원 데이터는 저차원의 매니폴드로 잘 아우를 수 있을 것이라고 가정을 하고 진행을 합니다.
Manifold?
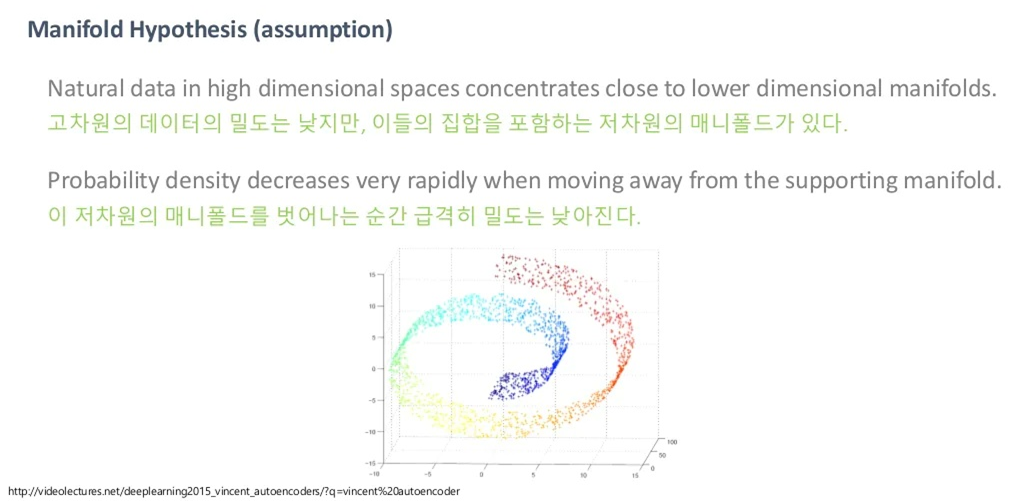
만약 저차원의 매니폴드로 아우를 수 있는 게 아니라, 고차원 공간에 골고루 퍼져 있다고 가정합시다. 그러면, Uniform sampling을 굉장히 많이 했을 때 의미 있는, 즉 semantic 한 이미지를 한 번이라도 볼 수 있어야 합니다. 하지만, 우리가 얻을 수 있는 건 오로지 노이즈밖에 못 볼 것입니다. 아무리 많이 샘플링을 한다 해도, 의미 있는 이미지를 얻을 수 없습니다.

그렇기 때문에, 위처럼 얼굴, 스케치, 문자 등이 어느 한 곳에 가까이 몰려 있을 것이라고 생각합니다.
그래서 결국 저차원 manifold를 잘 찾아낸다는 것은, 데이터를 잘 아우르는 저차원 manifold의 분포를 토대로 sampling을 할 수 있다는 것이고, 이로부터 새로운 data sample을 생성할 수 있게 됩니다.
200x200이 작아보이지만 사실상 엄청난 공간을 다루고 있는 것. 200x200일지라도 해당 차원에서 다양한 class들을 아우르는 manifold 찾기는 굉장히 어렵고, 적어도 도메인을 한정 지어야만 의미 있는 manifold를 찾을 수 있을 것(2018년 기준).
반면, 매니폴드를 잘 찾는다는 것은, 아래와 같이 의미 있는 feature(representation)을 찾는다는 것과 같습니다.
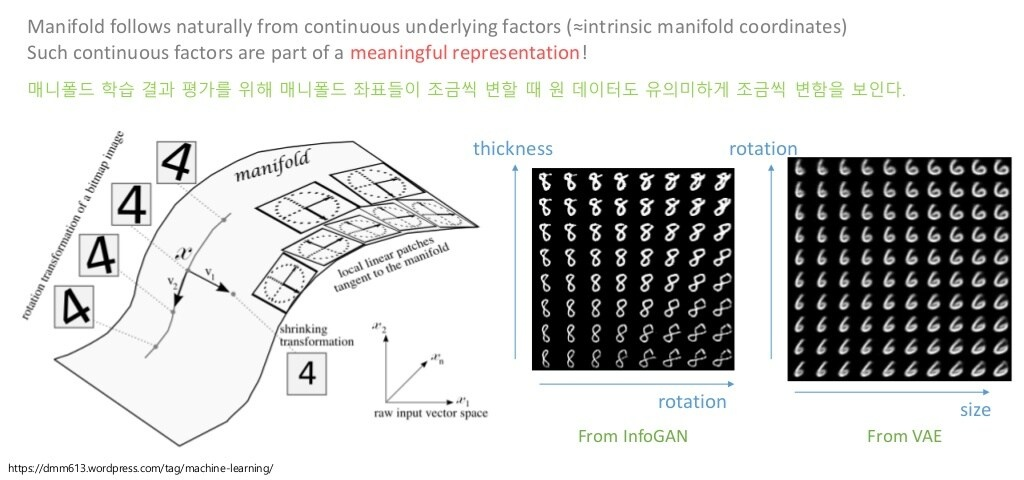
즉, manifold에서 좌표가 조금 변한다면, 원 데이터 또한 유의미하게 바뀔 것이라 가정합니다(그림에서 글자의 두께, 회전, 크기 등).
당연히, Unsupervised Learning이기 때문에 의미 있는 feature들은 자동으로 찾는 것이 목표입니다.
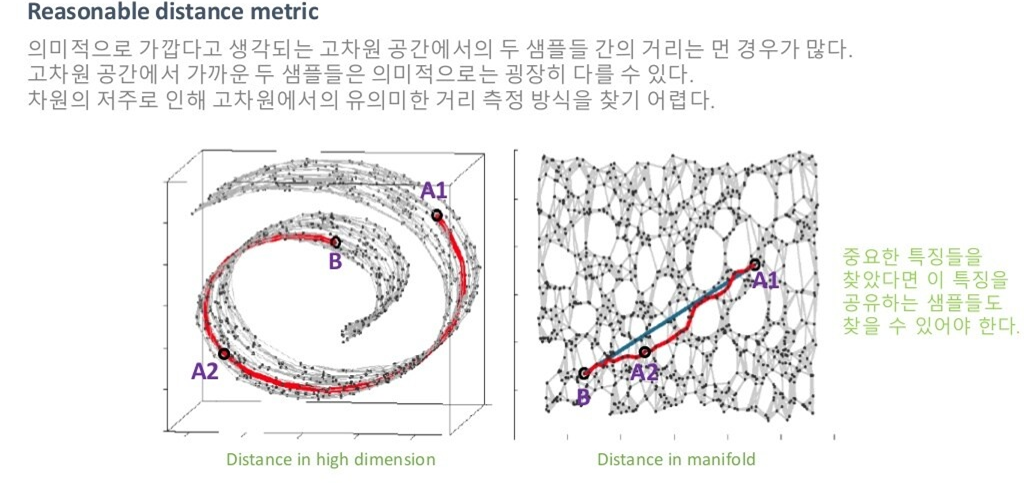
위의 그림을 살펴봅시다.
같은 거리 metric을 사용하더라도, 저차원 공간에서의 거리와 고차원 공간에서의 거리는 다를 수 있습니다. 즉, 고차원 공간에서 가깝더라도, 의미적으로는 가깝지 않을 수 있습니다. 저차원 매니폴드가 이미지의 의미 있는 feature를 잘 담고 있다고 가정하니까, 저차원 공간에서 가까운 것이 오히려 의미 있는 distance metric이라고 할 수 있는 거죠. 당연히 매니폴드를 잘 못 찾았다면 거리 개념이 잘 작동하지 않겠지만요.
예시로 보겠습니다.
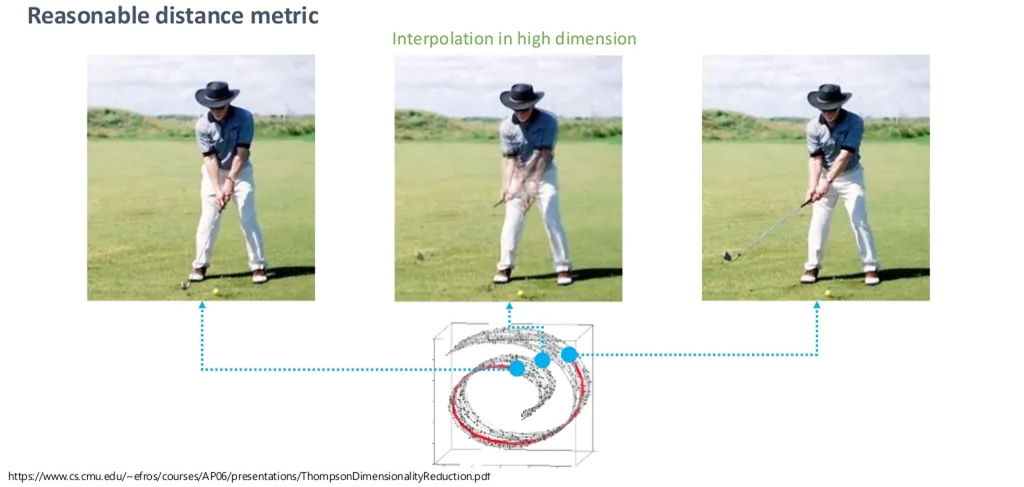
위처럼, 매니폴드에서 벗어나는 순간 큰 의미가 없는 단지 원래 공간의 픽셀 값의 중간 값만을 반환합니다.
하지만, 매니폴드를 잘 찾았다는 가정 하에서 매니폴드 공간에서의 중간 값을 취한다면, 훨씬 semantic한 sample을 찾을 수 있을 것입니다.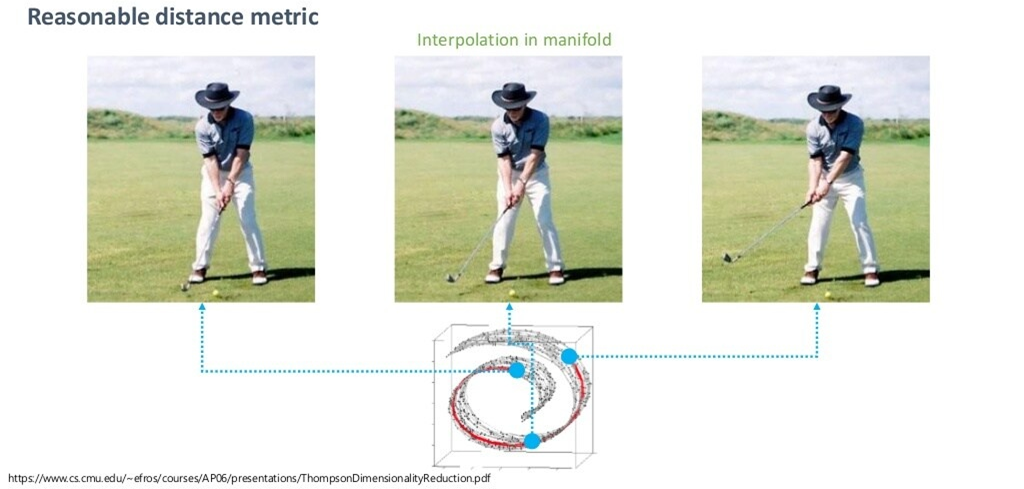
Entangled vs Disentangled in Manifold
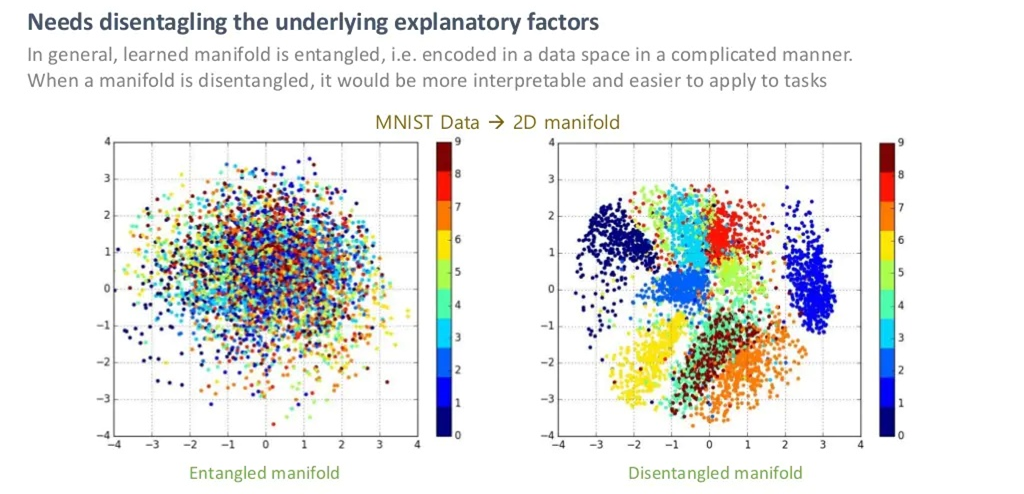
28x28차원의 MNIST Data를 2차원 매니폴드에서 봤을 때, 위 그림의 왼쪽처럼 1~9의 숫자가 잘 나뉘어 있지 않다면 이를 Entangled 하다고 하며, 그림의 오른쪽처럼 1~9가 잘 나뉘어 있다면, 이를 Disentangled하다고 합니다.
즉, 오른쪽의 Disentangled manifold에서는 숫자의 모양을 결정짓는 Dominant한 feature 2개를 잘 찾았다고 볼 수 있습니다.
Taxonomy of Dimensionality Reduction
대표적인 차원 축소 방법들은 아래와 같이 나타나있습니다.

VAE를 더욱 직관적으로 잘 이해하기 위해서는 차원공간을 다루는 다른 Method들 또한 알고 있는 것이 좋지만, 해당 글에서는 생략하도록 하겠습니다.
VAE
Variational Auto Encoder의 저자인 King. ma는 Adam optimizer 또한 개발했다고 합니다. 수학적으로 수준이 높은 저자다 보니, VAE의 original 논문 또한 이해하기가 상당히 힘들다고 합니다.
Code를 보게 되면 AutoEncoder와 크게 다를 것 없어 보입니다. 하지만, 논문의 흐름을 따라 가면 완전히 다른 모델을 볼 수 있을 것입니다. 즉, VAE는 엄밀히 따지면 AutoEncoder와는 다른 모델입니다.
왜냐면, AutoEncoder는 애초에 input을 잘 압축(즉, 매니폴드를 잘 학습)하는 것이 최종적인 목표이고, 이를 위해 Decoder에 Target(Input과 동일)을 주어서 Supervised Learning을 진행했을 뿐입니다. 즉, Decoder에는 관심을 두지 않습니다.
VAE는 샘플 Generate를 잘 하는 것이 목표기 때문에 Decoder가 주요 관심 대상이 되고, Encoder는 그를 위한 수단일 뿐입니다.
Sample Generation
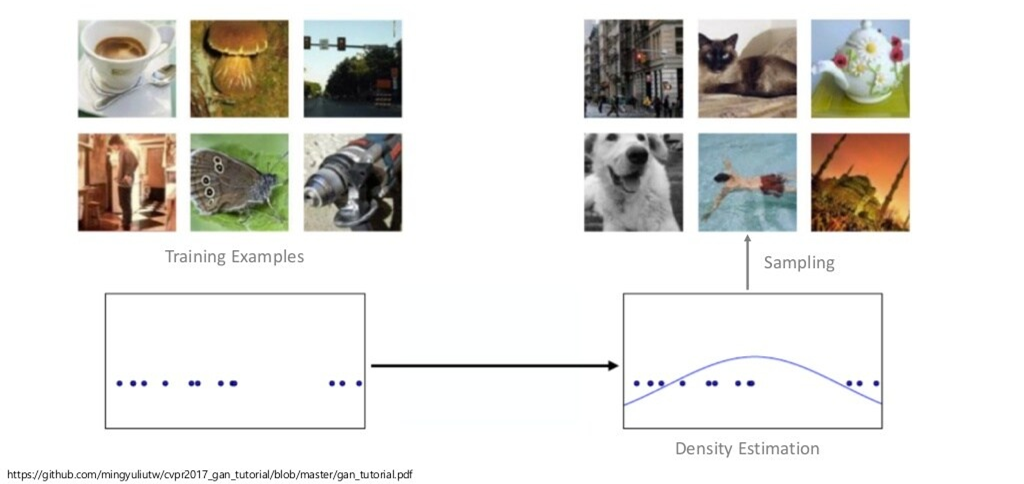
(생성모델의 목적은 Dataset의 data sample들을 이용해, 해당 sample들을 잘 표현하는 확률 분포를 학습하는 것)
만약 Dataset의 분포를 잘 학습할 수 있다면, 해당 분포로부터 새로운 data sample 또한 잘 생성할 수 있겠죠?
수식으로 나타내면, 아래와 같습니다.

최종적인 목표를 위해, 우리는 잠재벡터 가 주어졌을 때 데이터 sample 가 나올 likelihood를 가장 최대화하는 방향으로 학습하고 싶습니다.
이 때, Dataset의 분포를 무작위하게 모사하는 것 외에도, 분포를 잘 학습해서 우리가 원하는 feature를 조절할 수 있으면 더욱 좋을 것입니다. 즉, 잠재 벡터 를 remote controller 정도로 볼 수 있습니다. 의 특성을 약간 바꾸어 우리가 원하는 새로운 data sample 를 만들 수 있으니까요.
아무튼, 해당 잠재 벡터 를 사전 분포 에서 샘플링하고, 결정적(Deterministic) 함수인 에 태우면 확률 분포의 parameter를 반환합니다. 그렇기 때문에 를 와 같이 해석할 수 있습니다( : 분포의 parameter).
그러면, 우리가 원하는 Train DB에 대한 확률 분포 를, 를 통해 얻을 수 있게 됩니다. 는 우리가 정의하는 사전 분포이기 때문에 알 수 있고, 또한 샘플링한 와 결정적 함수 (Neural Net)를 통해 알 수 있으니까요.
이 때, 를 다루기 쉬운 확률 분포에서 뽑아야 우리가 제어하기도 편하기 때문에 를 보통 가우시안분포나 균등분포와 같은 쉬운 분포로 정의합니다.
Q1. 사전 분포를 다루기 쉬운 분포로 정의하면 복잡한 매니폴드를 잘 표현할 수 있을까요?
우리가 제어하고자 하는 잠재벡터 는 매니폴드 상에서의 값들입니다.
이전의 글에서 봤다시피 매니폴드 또한 굉장히 고차원의 공간이기 때문에 복잡할텐데,
이런 를 정규분포에서 샘플링하게 되면 이런 복잡한 매니폴드를 잘 표현할 수 있을까요?
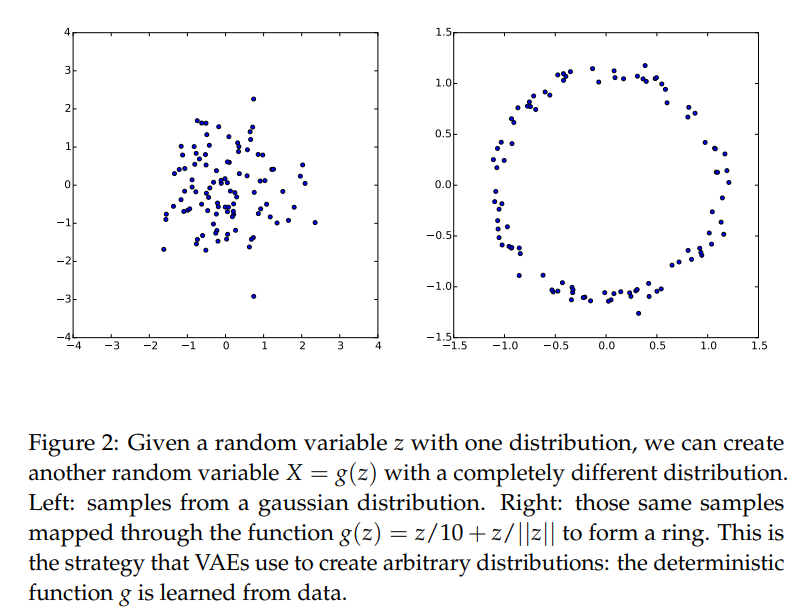
(Figure in Tutorial on Variational Autoencoders)
A. 어차피, Deep Nerual Net은 굉장히 복잡합니다. 그렇기 때문에 Deep Neural Net의 초반 Layer는 충분히 복잡한 매니폴드를 표현하기 위한 역할을 취할 수 있습니다(수학적으로도 잘 증명됐겠죠 뭐..).
Q2. 그냥 p(x)를 최대화하기 위해서 MLE(Maximum Likelihood Estimation)을 적용하면 안되나요?
즉, 로 생각해서,
(우변의 식들은 모두 알 수 있으므로)
적당히 결과 값을 몬테카를로 샘플링해 근사화하면 안되나요?

(Figure in Tutorial on Variational Autoencoders)
A. 는 Training DB의 sample하나 입니다. 즉, 이는 실제 샘플이기 때문에 또한 높게 나와야 합니다.
위 그림의 우측 (a),(b),(c)를 보면, (a)가 원본 이미지 , (b)는 에서 약간의 픽셀을 자른 이미지, (c)는 (a)의 화소를 오른쪽으로 한 칸씩 미룬 이미지입니다.
의미적으로는 (a)와 (c)가 훨씬 가까울 것입니다.
하지만, MSE 관점에서는 (a)와 (b)가 훨씬 가깝습니다.
이게 왜 문제가 되냐면,
를 가우시안 분포로 가정하고 를 샘플링해 학습을 시켰을 경우,
(MLE 관점에서의 가우시안 분포가 Back propagation 관점에서의 MSE Loss와 같았기 때문에 - 와 사이의 MSE,)
(c)보다는 MSE loss가 더 좋은 (b)의 분포에서 훨씬 샘플링이 많이 되기 때문입니다.
즉, (a)와의 likelihood는 의미적으로 거리가 먼 (b)가 대신 구한 평균 에 해당할 때 더 높게 찍힙니다. 평균이 (b)에 가까울 때 샘플링을 하다보면 결국 의미적으로 좋지 않은 표본이 나올 확률이 커집니다.
MSE에 따라 학습을 시키다 보면 평균이 (b)에 가까워질 것이고, 그 곳에서 샘플링을 하게 되면 (b)와 가까운 샘플들이 나옵니다.
위에서, 가우시안을 가정했을 경우 는 를 따르는데, 이에 대해서는 Tutorials for VAE를 참고하면 자세히 알 수 있습니다.
그렇기 때문에 우리는 를 가우시안분포로 가정한 뒤 단순하게 를 에서 뽑아 학습을 진행하면 안됩니다.
ELBO
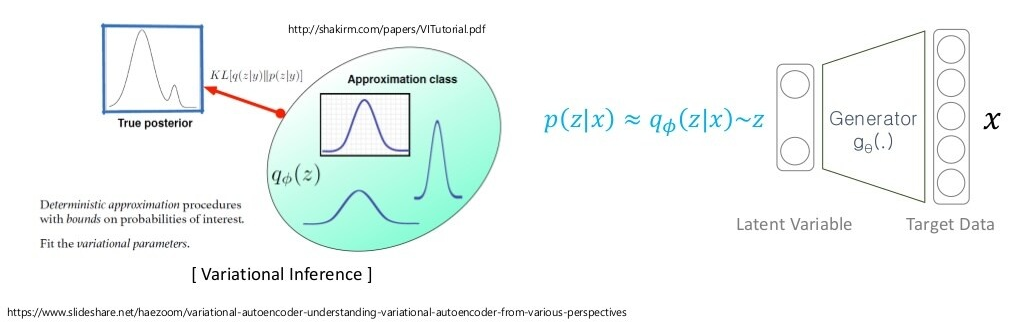
한 가지 가능한 해법은 를 에서 샘플링하는 것 말고, 와 유의미하게 유사한 샘플이 나올 수 있는 로부터 샘플링하는 것입니다.
단, 를 모르기 때문에, 우리가 알고 있는 분포(Approximation class) 를 택해서, 그 분포의 파라미터 값을 최적화함으로써 true posterior 에 제일 가까운 분포를 만듭니다.
여기서, 분포의 파라미터()를 조정하기 때문에 Variational Inference란 단어가 쓰이는 것입니다.
다시 말하자면, 일반적으로 AutoEncoder 방식으로 학습을 한다면 는 여차저차 찾을 수는 있는 반면, Decoder의 성능이 좋지 않아 현실 Dataset에 맞는 샘플 를 잘 생성할 수는 없습니다.
하지만, 좋은 Generation 할 수 있게끔, 이상적인 true posterior 에 가까워지도록 설계된 샘플링 함수 의 파라미터를 잘 조정해가면서 를 해당 샘플링 함수에서 뽑아 학습을 진행한다면 에 가까운 좋은 샘플이 잘 나올 수 있을 것입니다.
잠깐 정리하면, 우리가 궁극적으로 원하는 함수는
였습니다. 이를
로 바꿔 구할 수 있었고,
여기서 를 prior 로부터 단순하게 샘플링하면 문제가 생겼으므로, true posterior 에 가까운 approximation class 를 정의해서 를 샘플링 하려고 했습니다.
여기서, 우리는 이들() 간의 관계식을 찾은 뒤, Loss function을 정해야 합니다. 구할 수 없는 식들을 구할 수 있는 식들로 나타내야 하니까요. 다만 이 과정에서 완벽한 loss를 찾기는 힘들고, 편의를 위해 특정한 가정을 함으로써 식을 전개해나가는 일이 부지기수입니다.
조금 뜬금 없지만, NLP분야의 연구 Show, Attend and Tell: Neural Image Caption Generation with Visual Attention에도 이와 비슷한 관점이 사용됩니다.
(목적함수 대신 Lower bound 를 잡아 새로운 목적함수로 사용하는 모습 - approximate variational lower bound)

결론적으로, 위에서 중요하게 살폈던 term들 간의 관계를 나타낸 식이 ELBO : Evidence Lower BOund입니다.
여기서, Evidence의 단어 자체가 큰 의미를 갖는데, 특정한 정보를 주기 때문입니다.
ELBO 유도 (1)

- 를 최대화 하기 위해 를 최대화하거나 를 최소화합니다.
- 주변확률 분포()를 이용하고, 젠센 부등식을 활용해 Lower bound를 잡을 수 있습니다.
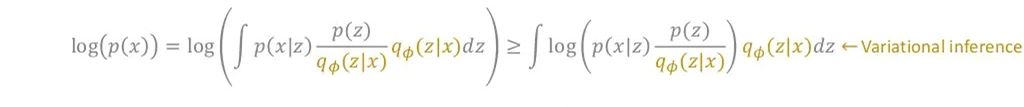
- 대신 를 샘플링해줄 를 포함한 식으로 변경시켜줍니다(Variational Inference).
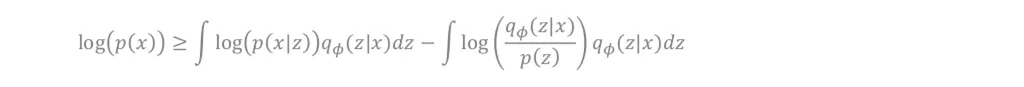
- 그 후 마지막 식의 내 항들을 전개해줍니다.

- 그러면, 최종적으로 위와같은 식으로 변경해줄 수 있습니다.
즉, 를 최대화하기 위해서 값을 최대화해줍니다.
과연 Lower bound를 최대화하는 것만으로 의 최대화 문제를 대체할 수 있을 까요? 이에 대해 정확한 이해를
ELBO 유도 (2)

위 식에서, 는 우리가 최대화하고자 하는 상수 값으로 보고 고정할 수 있습니다( : target image). 또한 우리의 목표는 approximation class 를 에 가깝게 하는 것이이기 때문에, 두 분포 간의 차이를 나타내는 term인 은 최소가 되어야 합니다. 즉, 를 최대화하면 됩니다.
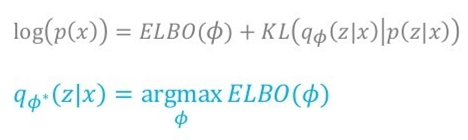
즉, 목표는 값을 최대화하는 것으로 바뀌게 되고, 유도 (1)에서 봤다시피 식은 아래와 같이 기댓값(평균값)과 KL term으로 나뉩니다.

위의 그림에 써있다 시피, 를 전개했을 때 ELBO와 KL term으로 나눠졌고, 그 때의 KL term에는 가 쓰인 반면, 를 전개해 기댓값과 KL term으로 나눠졌을 때의 KL Term에는 가 쓰입니다.
즉, 를 최대화하는 문제를 값을 최대화하는 문제로 확대해 바라볼 경우, 는 작아지게끔 학습이 되며, 결론적으로 잘 학습이 됐다면 를 에서 샘플링하지 않고 간단한 가우시안 prior인 로부터 샘플링해도 괜찮은 generation 결과를 볼 수 있습니다.
Loss
정리
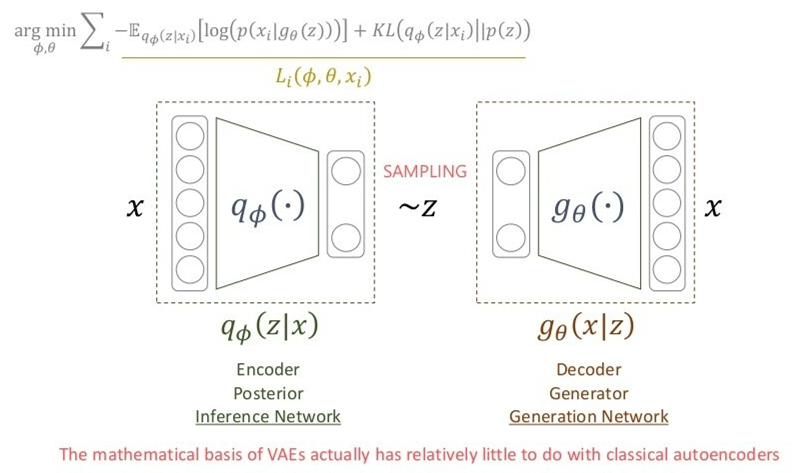
- 에서 를 샘플링했더니 생성이 잘 안 됨
- input 에 대한 정보를 받은 에서 를 샘플링하고 싶음.
- 는 모르니까 를 최적화해서 사용할 것임.
- 즉, 를 활용하기 위해 term을 최대화하는 를 찾을 것임.
- 추가로, 에서도 와 유사한 샘플을 생성할 확률을 높힐 를 구해야 하는데, 그것 또한 term의 첫 항에서 고려됨.
즉, term을 에 대해서 최적화할 경우 좋은 샘플링 함수를, 에 대해서 최적화할 경우 좋은 generator를 얻을 수 있게 됩니다.
(같은 Loss 함수를 사용하지만 결국 에게 모두 이롭게끔 학습됩니다)
자세한 내용은 understanding-variational-autoencoders-vaes를 참고하세요.
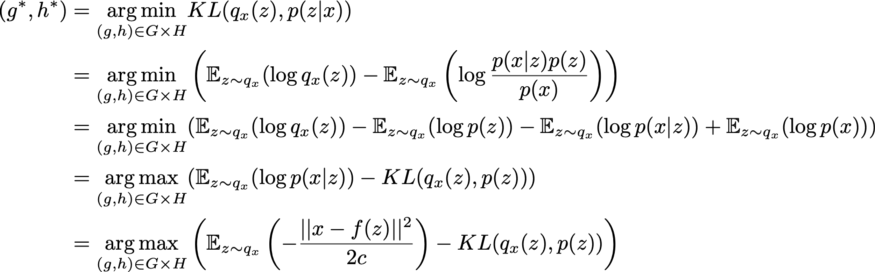

여기서 : Gaussian decoder, : encoder(평균/ 분산)
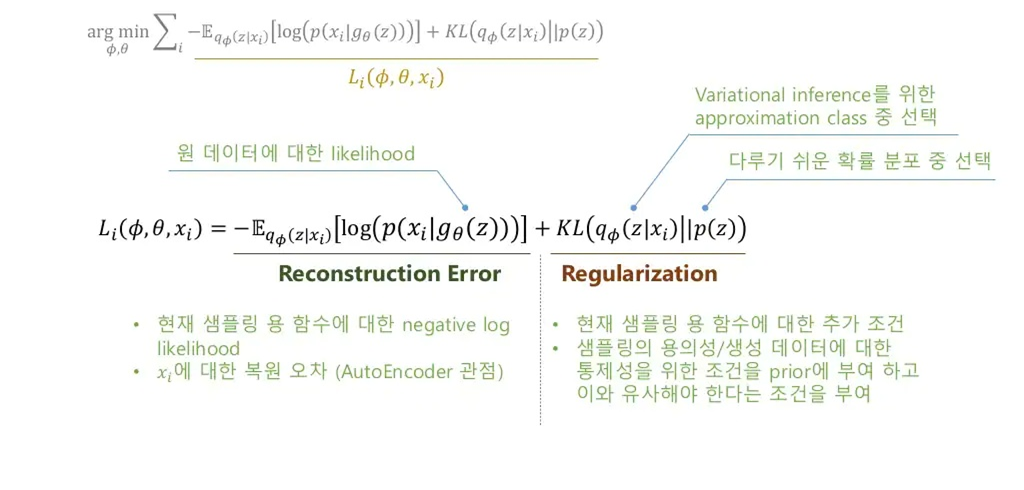
좌측의 Reconstruction Error term은 AutoEncoder와 같은 term으로, 해당 분포가 어떤 분포(가우시안 or 베르누이)를 따르느냐에 따라 MSE or Cross Entropy loss로 갈립니다. likelihood이므로 높아지게끔 학습이 진행됩니다.
우측의 Regularization term은 Reconstruction Error가 좋을 경우 이왕이면 Approximation class 가 prior 와 유사했으면 좋겠다는 생각을 반영하는 term입니다. 를 샘플링할 분포는 (표준정규) prior 와 같이 다루기 쉬워야 하니까요.
이제, KL-Divergence term을 계산해봅시다.
KL-Divergence term

위에서, prior 와 approximation class 는 정규분포로 가정했습니다.
좋은 sampling함수를 찾는다는 것은 , 즉 정규분포(가우시안분포)의 평균과 분산을 찾는 것과 같습니다.
두 분포가 가우시안으로 같기 때문에, 아래와 같이 구해진 공식을 토대로 KL term은 closed form으로 정확히 해를 구할 수 있게 됩니다.

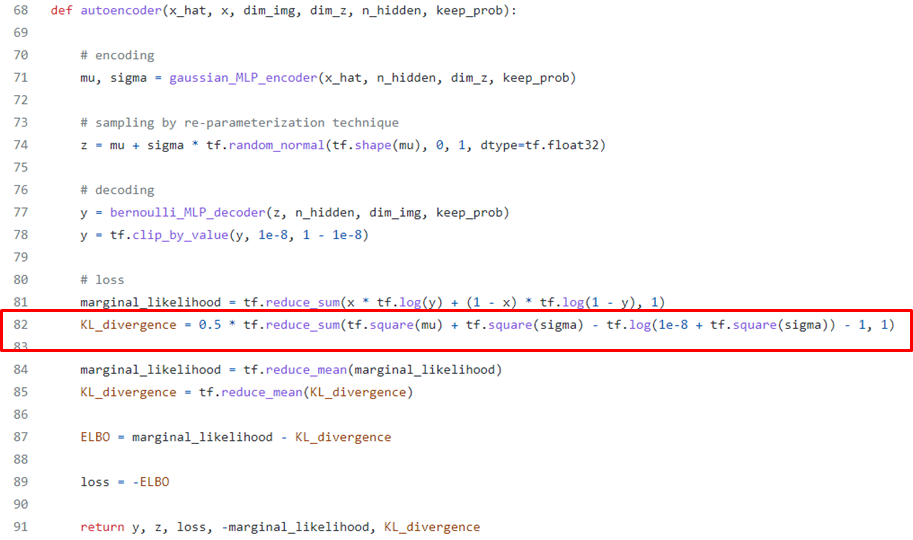
Code of KL-Divergence
출처 : https://github.com/hwalsuklee/tensorflow-mnist-VAE/blob/master/vae.py
Reconstuction Error term
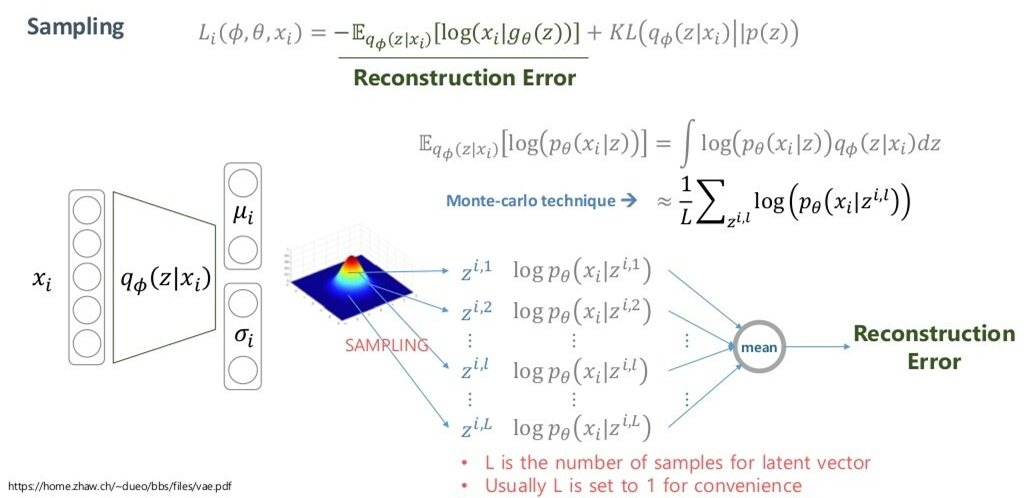
이 때, sampling을 진행해서 를 사용하는데, 문제는 샘플링 함수는 random function이기 때문에 일반적으로 역전파를 진행할 수 없다는 것입니다. 저희는 가 도출되는 를 학습시켜야 하기 때문에 역전파는 구해야 합니다.
re-parameterization trick
그래서, 우리는 re-parameterization trick을 사용해 아래와 같이 식을 변경해줍니다.
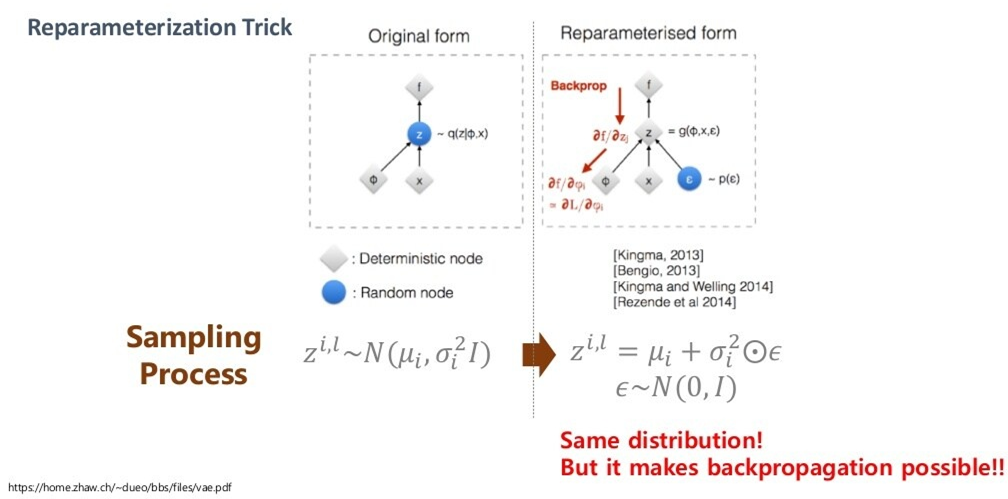
우측의 식으로 변형하더라도 분포는 변하지 않기 때문에 위와 같이 변형을 할 수 있는 것이고, 이로부터 에 대한 그래디언트를 구할 수 있게 됩니다.
Code of re-parameterization trick
출처 : https://github.com/hwalsuklee/tensorflow-mnist-VAE/blob/master/vae.py
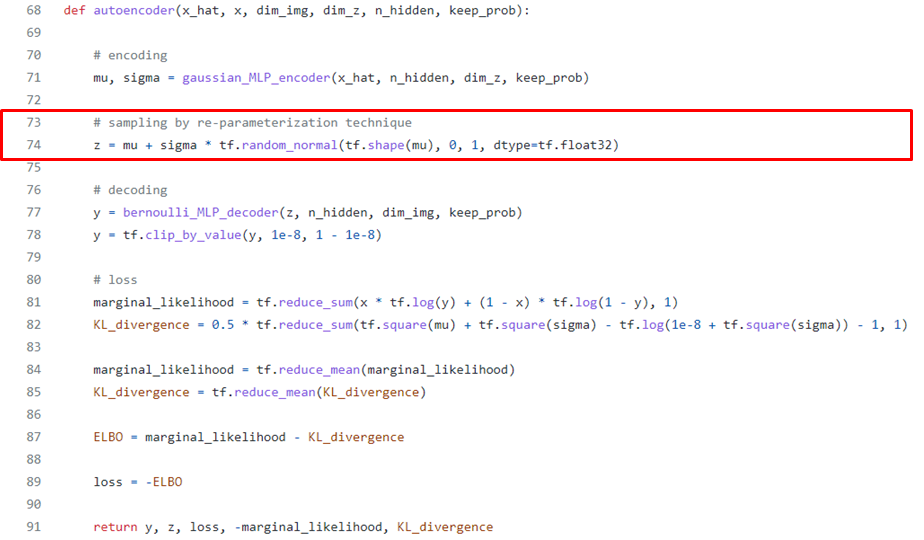
단,
tf.random_normalmethod 내에 이미 re-parameterization trick이 적용되어 있기 때문에 실질적으로 mu와 sigma를 인자에 넣고 를 단순히 샘플링해도 문제는 없습니다.
Bernoulli Decoder vs Gaussian Decoder
Bernoulli Decoder

또한, 원래 샘플링을 통한 몬테카를로 방법을 적용해야 하지만 일반적으로 샘플링도 단 한번만 적용해 사용한다고 합니다.
King.Ma, Auto-Encoding Variational Bayes (4p 중 발췌)
위의 예시처럼 generator의 likelihood 가 베르누이분포를 따른다고 가정했을 때, 최종적인 likelihood는 network의 input 와 network의 output 의 Cross-entropy가 됩니다.
네트워크의 출력이 베르누이 분포의 출력인 0 or 1이 되는 것이 아닙니다. 네트워크의 입력 또한 무조건적으로 베르누이 분포를 따라 의 값을 갖는 것이 아닙니다. 단지 그냥 합리적(경험적) 가정일 뿐이며, 은 확률적인 관점에서 의 값(즉, 0과 1 사이의 값)을 output으로 가집니다. 또한 최종적인 Cross entropy에서도 굳이 label이 0과 1만을 가질 필요는 없습니다.
Cross entropy의 대표적인 사용처인 Classification에서는 label이 one-hot encoding으로 0과 1의 값만 가지는 것은 그저 극단적인 정답의 예시(hard)일 뿐, 0과 1사이의 값을 가져도 cross entropy를 사용할 수 있습니다(softmax).
 !()
!()
Gaussian Decoder
만약 likelihood 가 가우시안분포를 따른다고 가정한다면?
즉, 를 조건으로 받은 generator의 output이 평균 와 분산 를 따른다면?

위와같이 최종적인 likelihood 는 input 와 output (를 따르는 샘플) 간의 MSE loss가 됩니다.
특히, 분산을 0으로 했을 때에 완벽한 MSE loss가 됩니다.
위에서 평균과 분산은 element-wise 될 것이기 때문에 그냥 차원의 vector가 하나 생긴다고 보면 됩니다.
또한, 학습이 잘 됐다면 를 에서 샘플링했음에도 불구하고, 이상적인 와 굉장히 유사해질 것이고, 그에 따라 나온 를 토대로 generator 또한 최적화된 것이기 때문에 생성 성능이 좋습니다.
Bernoulli Decoder
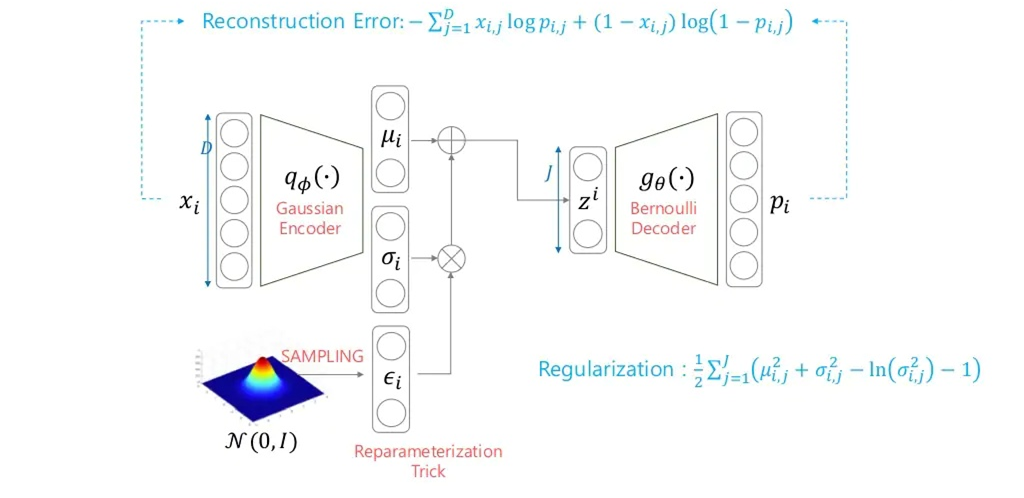
그래서, 한 장으로 요약하면 결국 Reconstruction Error는 (디코더의 likelihood를 베르누이로 가정했기에) input과 ouptut의 Cross-entropy term으로 바뀌며, Regularization Error는 (사전분포와 Approximation class를 가우시안분포로 가정했기에) closed form으로 계산할 수 있게 됩니다.
Gaussian Decoder
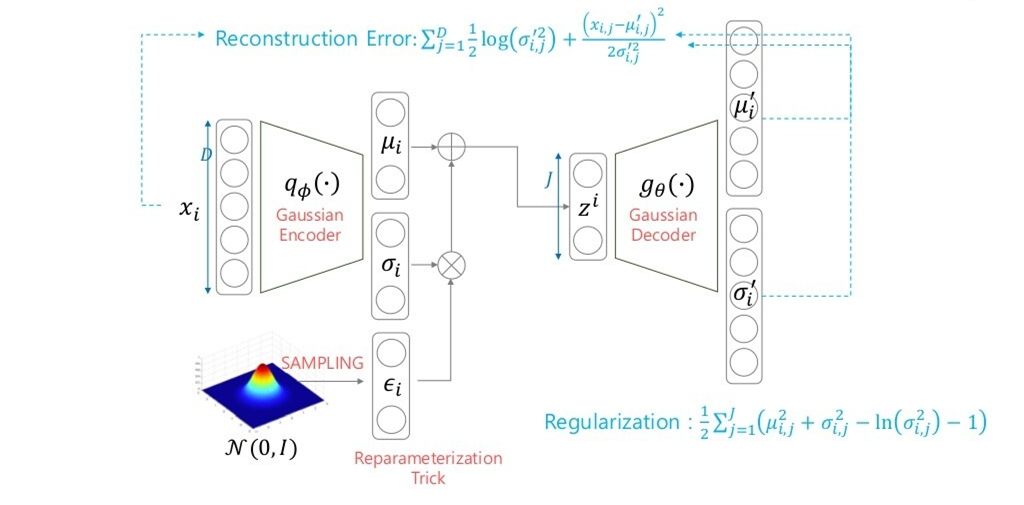
- 마찬가지로, 위와 같이 표현할 수 있습니다.
만약 위에서 분산 가 1이 아니라면, 분산이 커질수록 Reconstruction Error, 즉 observations(data)의 영향력은 작아지고, Regularization Error, 즉 prior의 영향력은 강해집니다. 즉, 기본적으로 베이지안 추론의 관점(data+prior -> posterior)에서 data와 prior간의 trade-off를 control하는 term이 의 역할이라고 해석할 수도 있습니다.
Decoder의 분포에 변화를 주는 것과 다르게 Encoder의 분포는 고정시키는데, 이는 정규분포가 아닌 경우 KL-발산 term을 구하기가 쉽지 않기 때문입니다. 이러한 한계에 대해 해결한 것이 Adversarial Auto Encoder입니다.
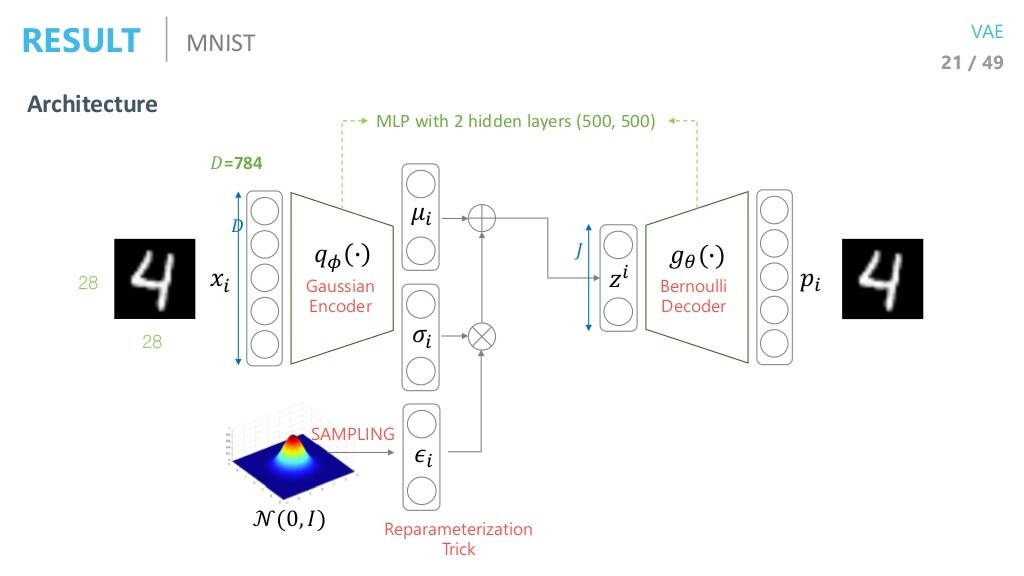
Result
Architecture
Code(Bernoulli Decoder)
출처 : https://github.com/hwalsuklee/tensorflow-mnist-VAE/blob/master/vae.py
위의 코드에서 평균과 분산을 따로 나눠서 결과로 내는 것을 볼 수 있습니다. 이는 두 parameter를 각각 추정해야하기 때문이며, 최종적인 sample의 값은 element-wise됩니다. n_output은 추정할 잠재벡터 의 차원입니다. 즉, 최종적으로 반환되는 평균과 분산은 모두 n_output 차원을 갖습니다.
Encoder

Decoder
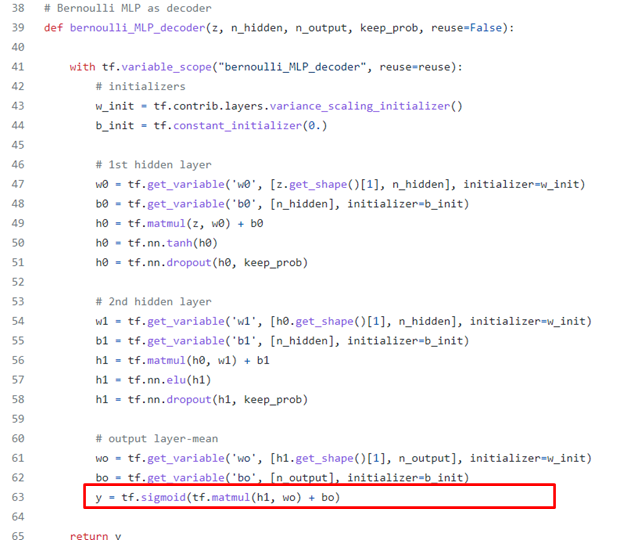
Decoder 또한 비슷하지만, output이 보통 image기 때문에 최종 활성화 함수는 sigmoid를 사용해 0~1사이의 값으로 맞추어줍니다.
VAE

- 전체 코드는 간단합니다.
Result
- input image의 차원()을 차원으로 줄였을 때의 결과입니다. 당연히, 잠재벡터의 차원이 높을수록 복원이 잘 될 것이기에 Reconstruction Error는 더 줄어듭니다.

AutoEncoder vs VAE
근본적으로 AutoEncoder의 loss와 VAE의 loss는 KL-발산 term을 제외하면 모두 같습니다.

AutoEncoder는 VAE와 구조, 그리고 Reconstruction Error가 사실상 같습니다. 하지만, AutoEncoder에서는 Decoder(Generator)의 관점에서 잠재벡터 에 대한 고려를 하지 않습니다. 즉, 가 어떤 range에 놓여야 이상적으로 generation을 하는 지는 모르고, 그저 복원 성능만을 신경씁니다.
반면, VAE에서는 학습이 잘 됐다면 를 에서 샘플링했음에도 불구하고, 이상적인 (정규분포)와 굉장히 유사해질 것이고, 그에 따라 나온 를 토대로 generator 또한 최적화됩니다.
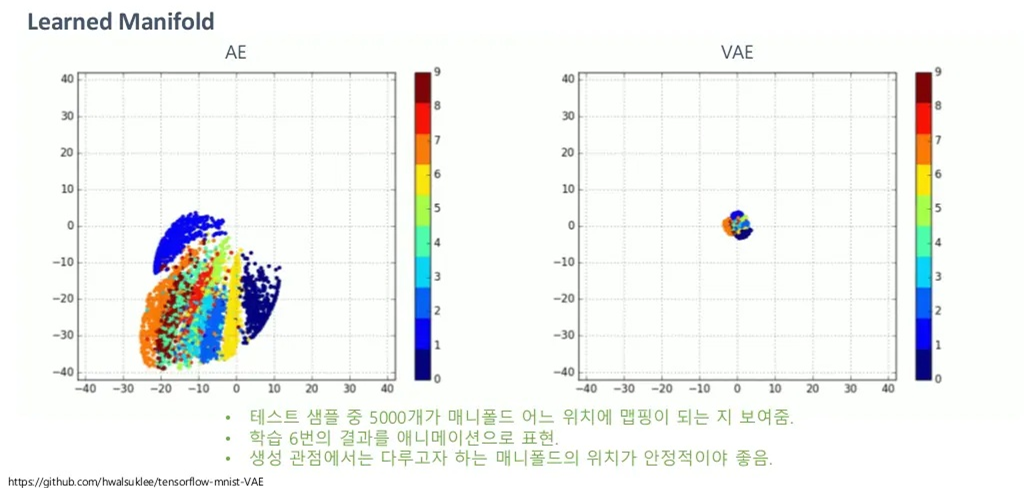
결론적으로, AutoEncoder는 학습을 새로 할 때마다 의 분포가 매우 달라지고, 난장판이 되는 반면 VAE는 학습을 새로 하더라도 가 안정적으로 정규분포를 따르기 때문에 추후에 샘플을 생성할 때에도 그저 학습된 의 prior 분포(즉, 정규분포)로부터 를 뽑아서 생성하면 됩니다. 훨씬 더 편하게, 그리고 유의미하게 잠재벡터를 다룰 수 있는 것입니다.
우리의 loss는 (가정상 정규)사전분포 와 샘플링함수 가 가까워지게끔 학습을 시켜줍니다.

이러한 VAE의 특성으로 인해 잠재벡터 는 아래와같이 자동적으로 유의미한 특성을 지니게끔 학습되고, 정규분포를 따릅니다.
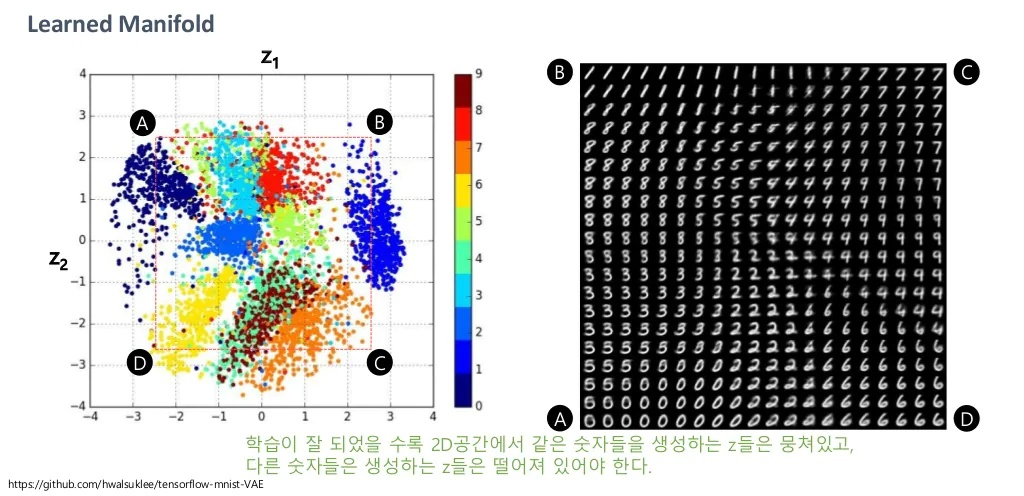
물론 위의 예시에서는 균등분포에서 샘플링을 했지만, 정규분포에 따라 샘플링을 한다면 클래스 별 빈도정도는 다를 수 있습니다.
마치며
- MNIST VAE에서 베르누이 분포를 가정하고 BCE loss를 사용하는 이유
:또한, 굳이 BCE loss가 0과 1의 값만 다룰 필요는 없다. - negative log likelihood를 사용하는 이유
:MSE and cross entropy - Cross-entropy for comparing images
- softmax가 soft인이유는?
- Deterministic function?
- AutoEncoder의 응용방법?
에 대한 내용은 https://velog.io/@sjinu/VAE2 에 간략하게 달아놓았습니다.
Ref.
★★오토인코더의 모든 것
★★Tutorial on Variational Autoencoders
★★hwalsuklee's github
★Understanding Variational Autoencoders (VAEs)
★Auto-Encoding Variational Bayes(original paper)
★Introduction to Bayesian Statistics(posterior 관련 초반부)
Several Ideads for Bernoulli in VAE
Cross-entropy for comparing images
Variational autoencoder: Why reconstruction term is same to square loss?
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
