작성자 : 이예진
이번 시간에는 Few-shot learning 중에서도 Non-Parametric 방법에 대해서 공부해보겠습니다. stanford 대학의 cs330(Multi-Task and Meta-Learning) 강의 중에 Lecture4.Non-Parametric Meta-Learners 에 해당합니다.
학습목표
- 많은 방법들의 흐름을 파악하고 비교를 할 수 있다.
- 해다 용어는 알고 있어서 추후에 구글링 해 볼 수 있다.
- 관련된 용어는 알고 있어서 추후에 논문 읽기에 도움이 될 수 있다.
Contents
0. Intro
- Transfer learning, Multi-task learning, Meta-learning, Few-shot Learning (,Semi-supervised learning)
1. Non-parametric methods
- Siamese networks, matching networks, prototypical networks Embed, then nearest neighbors
2. Case Study(Non-parametric methods)
3. Properties of Meta-Learning Algorithms
- 각 접근법 비교
0. Intro
~ learning에 대한 개념이 끊임 없이 나오고 few-shot, meta-learning에 대한 다양한 관점을 보고 있기 때문에 각 학습법의 개념에 대해서 짚고 넘어가겠습니다.

Machine Learning with Limited Data!
- Data augmentation
- Generative models, self-supervised learning - Unsupervised learning
- Transfer Learning
- Meta Learning (Learn to learn)
- Metric-based approach
- Model-based approach(black-box,parameter generation based)
- Optimization-based approach
- Graph Neural network-based approach
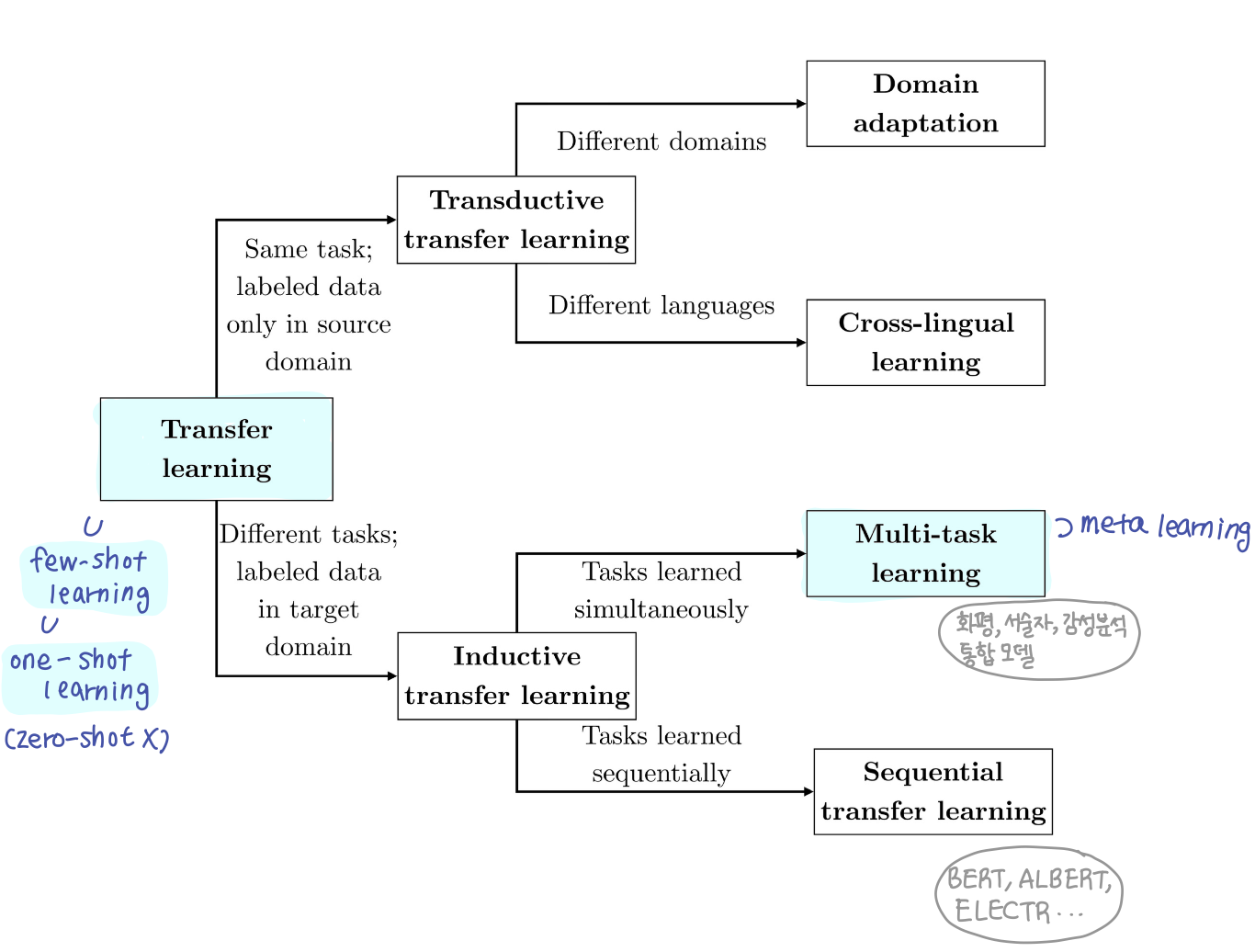
Transfer Learning
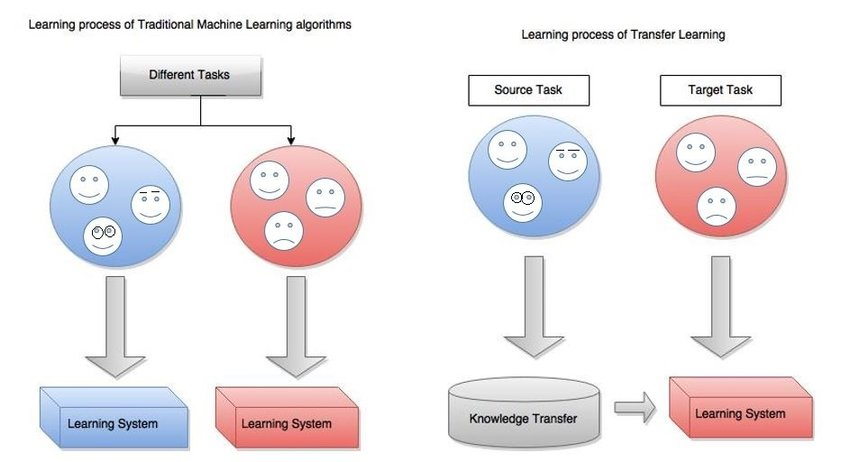
Transfer Learning(전이학습) : 사전작업(source task)에 대해 학습된 정보를 목표(target task)에 활용하는 방법
- 목표 작업에 대한 수렴속도와 성능 향상
- 사전 작업 데이터가 충분히 많다면 목표 작업 데이터는 조금 적어도 됨
- 최근 few-shot classification은 transfer learning의 특별한 경우로 볼 수 있음
- -> We transfer knowledge from data set to novel dataset
이용하는 법
- Weight initialization : 사전 작업에 사용된 구조를 목표 작업 모델에 적용, 사전학습한 모델의 가중치로 초기화 (fine-tuning 할 수도 있고 안할 수도 있음)
- Feature Extraction : 사전 작업에 사용된 구조를 목표 작업을 위한 모델에 적용, 재사용된 구조에 대한 Fine-tuning 하지 않음
분류
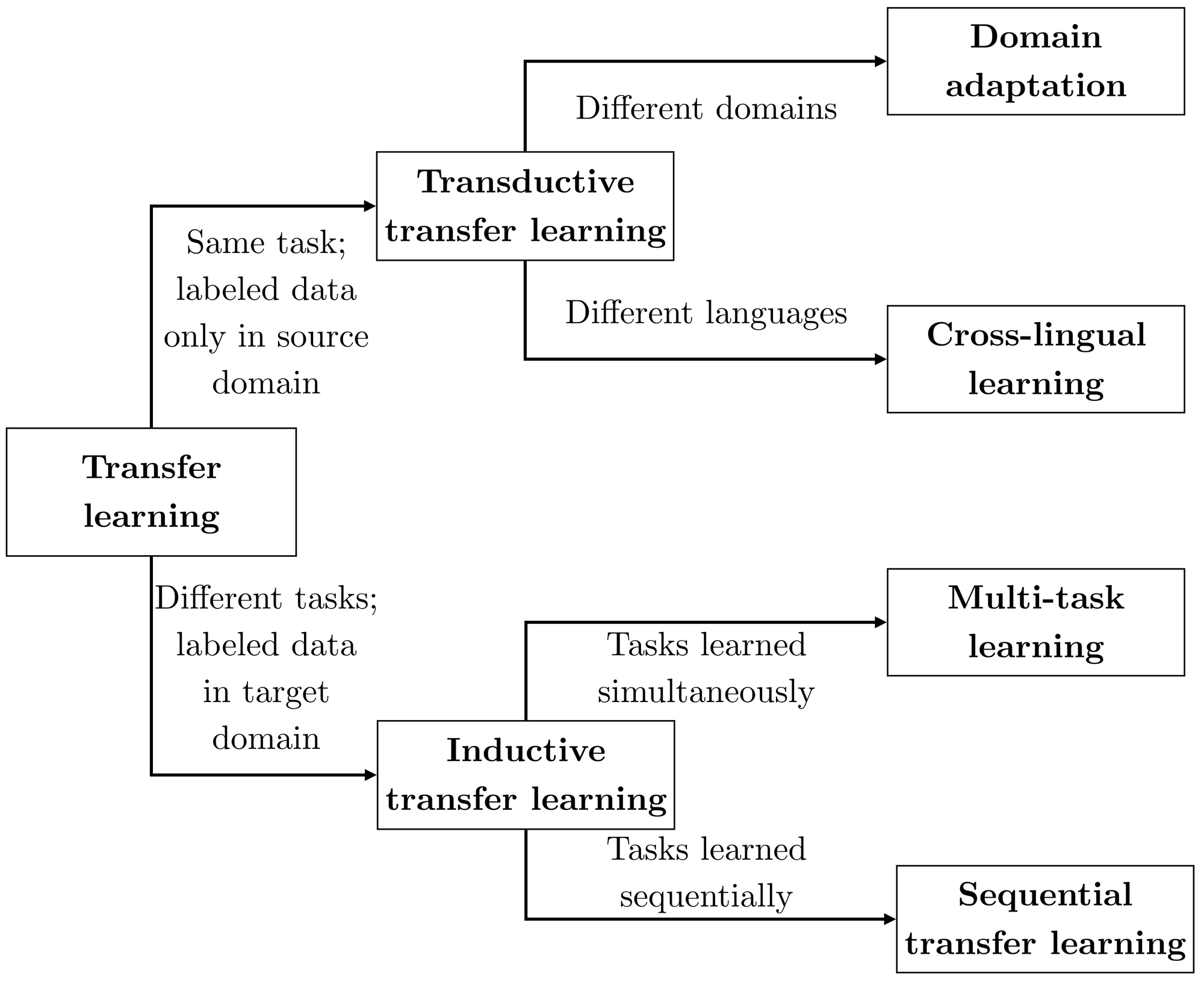
Multi-task learning
Inductive transfer learning 중에 task 에 대해서 한번에 학습 시키는 방법이 Multi-task learning
- 사용이유 : 특정 작업 하나에만 학습하게 될 경우, 해당 작업에만 초점이 맞춰져 있기 때문에 유용하게 사용될 수 있는 정보임에도 놓치는 위험성이 존재함
-> 그냥 한번에 학습시켜서 공유시키자! - 관련있는 작업들의 표현을 공유함으로써 모델의 일반화 능력 향상 시키는 접근방식
- 일반적으로 최적화 문제가
하나 이상의 손실함수를 갖는 경우 - Meata-learning은 모든 task가 동일한 task 분포에서 샘플링되는 multi-task learning의 특별한 경우로 볼 수 있음 (모든 task가 동일한 통계 공유)
| Hard parameter sharing | Soft parameter sharing |
|---|---|
| 작업별 출력레이어를 유지하면서 히든 레이어 공유 | 각 작업에 대응하는 매개변수를 갖는 고유한 모델 존재 |
| 동시에 학습하는 작업이 많을 수록 과적화될 가능성 낮아짐 | 각 모델 매개변수 사이의 거리를 정규화하여 각 매개변수가 유사하도록 유도 |
| Constrained layer들 사용, "공유하는 부분만 공유하자" |
(나머지 내용은 8주차 참고)
Inductive transfer learning 중에 task 에 대해서 순차적으로 학습 시키는 방법이 Sequential Transfer Learning
- Bert pre-trained model을 사용했다~ 의 그 transfer learning임.
- 자세한 설명 생략
Few-shot Learning
Few-shot Learning : 사전 지식을 활용하여 일반화된 정보를 학습하고, 적은 수의 새로운 테스크 데이터에 적용하는 방법
- N-way K-shot learning
- 일반적으로 성능은 N에 반비례, K에 비례 -> 보통 N은 10이하로, K는 1이나 5로 설정
- one-shot learning은 few-shot learning으로 연구되지만 zero-shot learning은 few-shot learning으로 연구되지 않음
- few-shot classification은 transfer learning의 특별한 경우로 볼 수 있음
- Few-shot과 semi-supervised learning은 교차점(interaction)이 있음
(+ Semi-supervised Learning)
- Few-shot과 semi-supervised learning은 교차점(interaction)이 있음
- labeled data와 unlabeled data 모두 사용 (few-shot은 labeled data가 더 제한적)
- semi-supervised learning이 사용할 수 있는 labeled data와 unlabeled data가 few-shot 보다 더 많음
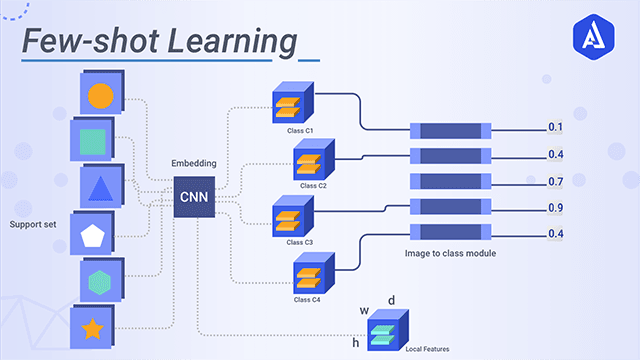
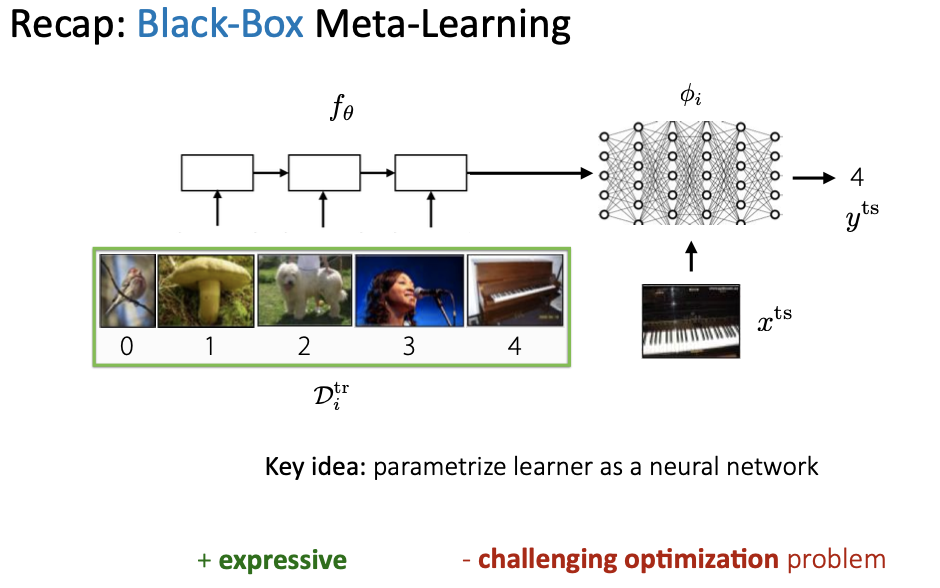
1. Non-parametric methods
Why
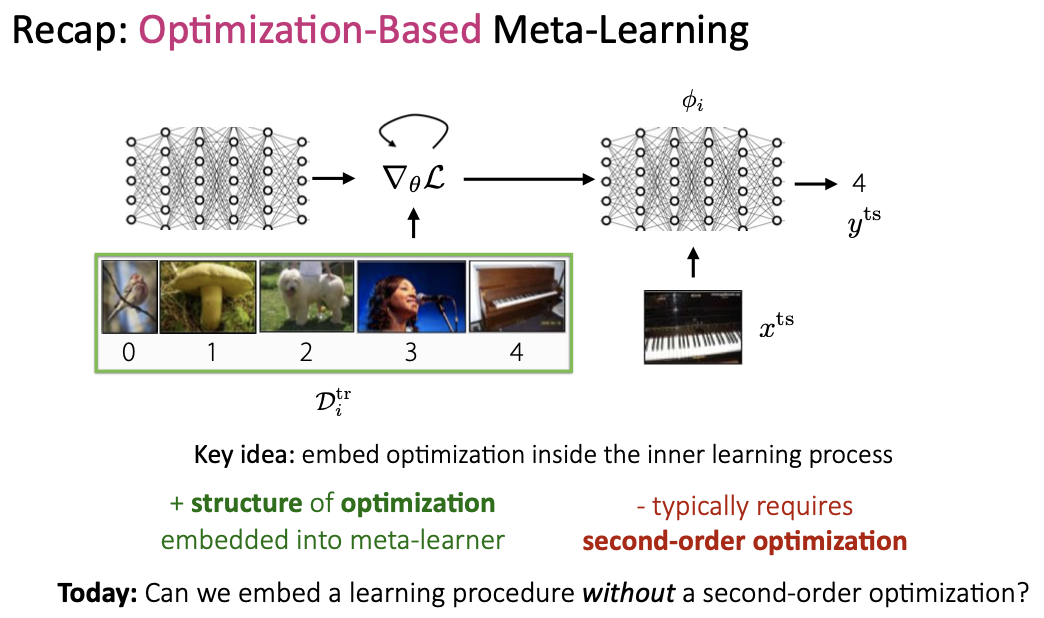
Non-parametric methods == Metric-Based Approach
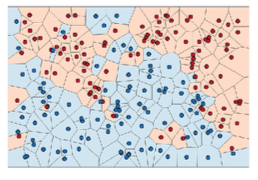
- 근본적이 개념은 nearst neighbors algorithm과 유사함
- data가 단순하고 저차원일수록 non-parametric 방법이 잘됨
- meta-test time : few-shot learning <-> low data regime
- meta-training : still want to be parametric
- 효율적인 비모수 학습기를 생성하기 위해서 모수적 메타 학습기를 사용하자
Basic
- Key Idea : Use non-parametric learner
- test datapoint()를 training data()과 비교해서 가장 가까운 training data point의 label을 가져온다.
- metric으로 pixel space, l2 distance를 계산하는 방식 대신 meta-training data를 이용한다.

Algorithms
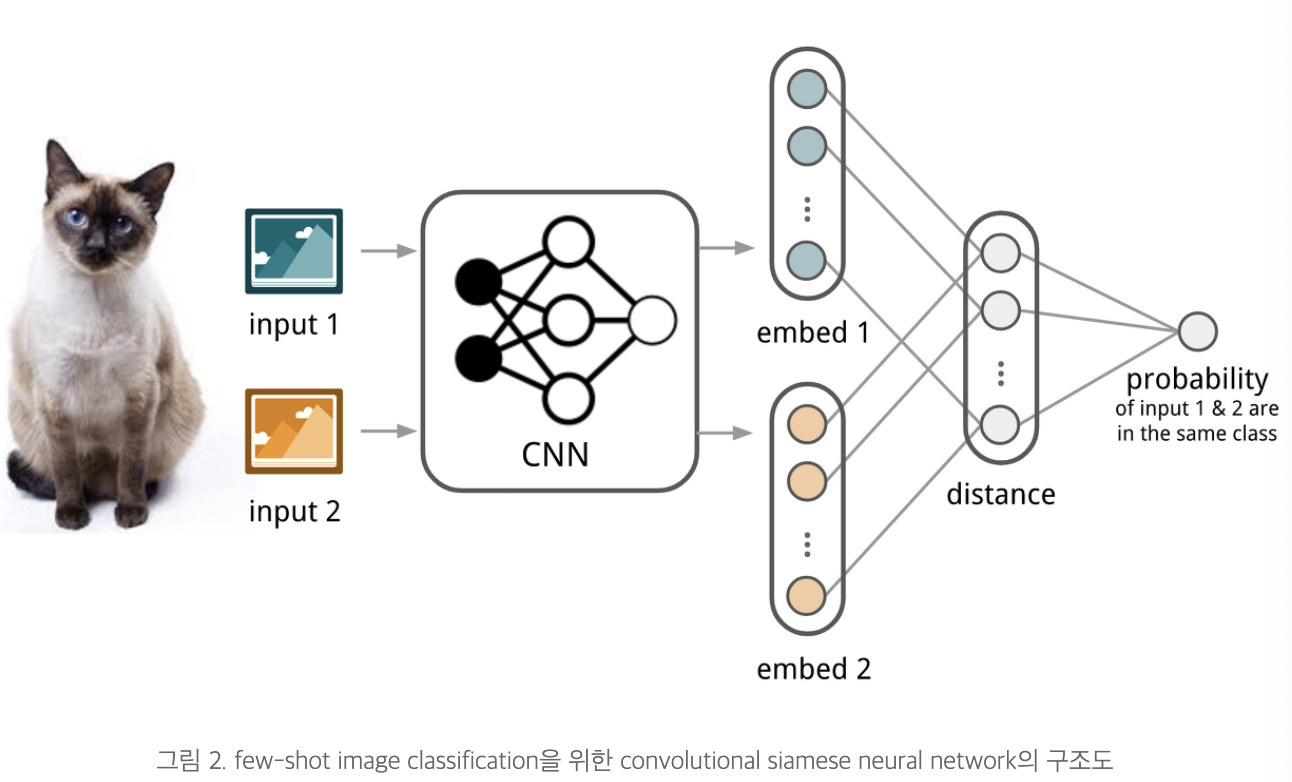
Siamese network
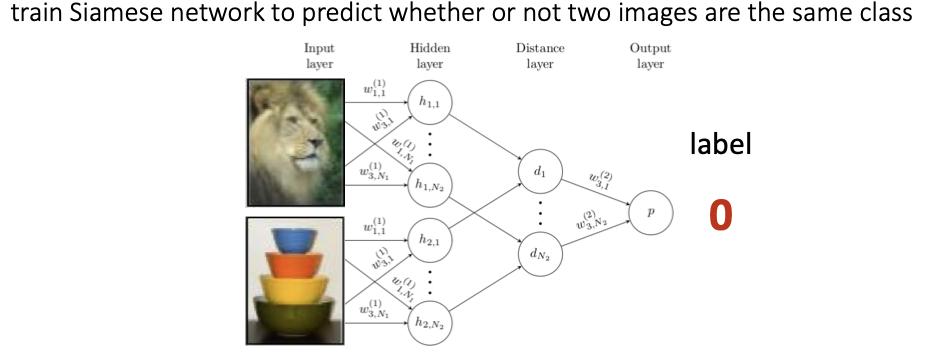
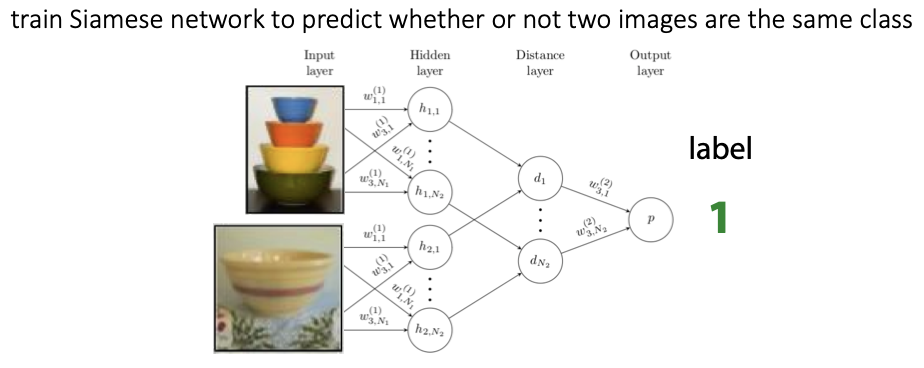
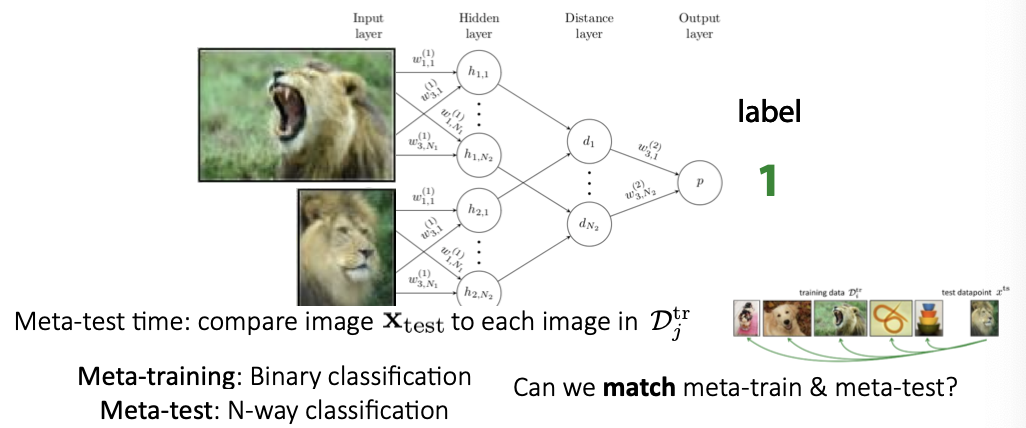
- 두 이미지가 동일한 것인지 예측하는 task
- 이미지쌍을 비교하는 법 배우는 메타러닝 -> 확장해서 두 이미지 사이의 거리를 배울 수 있음
- Meta-training : 메타훈련으로는 이진 분류를 배움
- Meta-test : 메타 테스트에서 N-way classificationㅇ 이뤄짐
- 샴네트워크 두개를 사용하고, 네트워크끼리 가중치와 네트워크 파라미터를 공유함
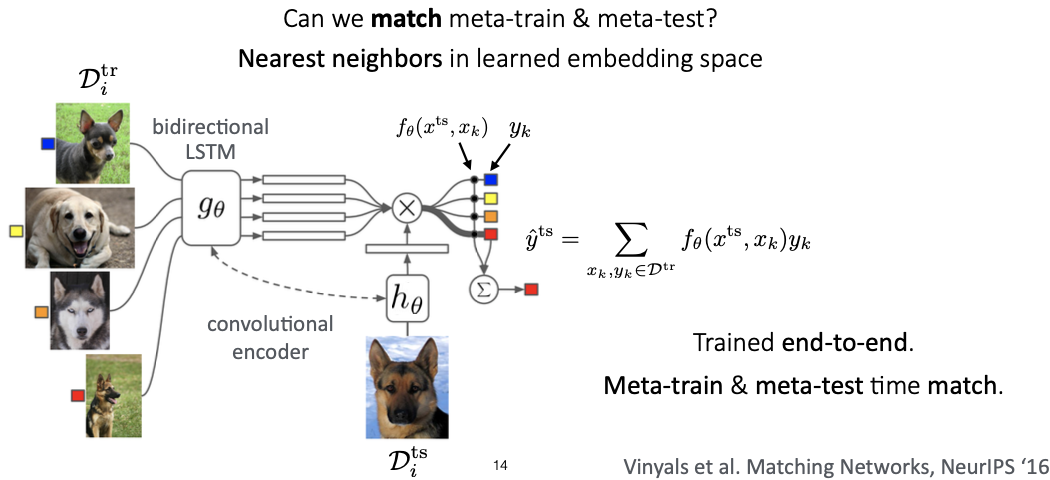
Matching Networks
- 적은 양의 support set(k-shot classification)을 가지고 classifer를 학습시키는 방법
- 가 들어오면 ouput label y에 대한 probability distribution을 정의한다.
- 이 때 g(LSTM) 사용으로 context를 반영한 임베딩 값을 사용하고, f는 다시 LSTM을 통해서 test sample x를 encoding한다. (Full Contextual Embeddings(FCE))

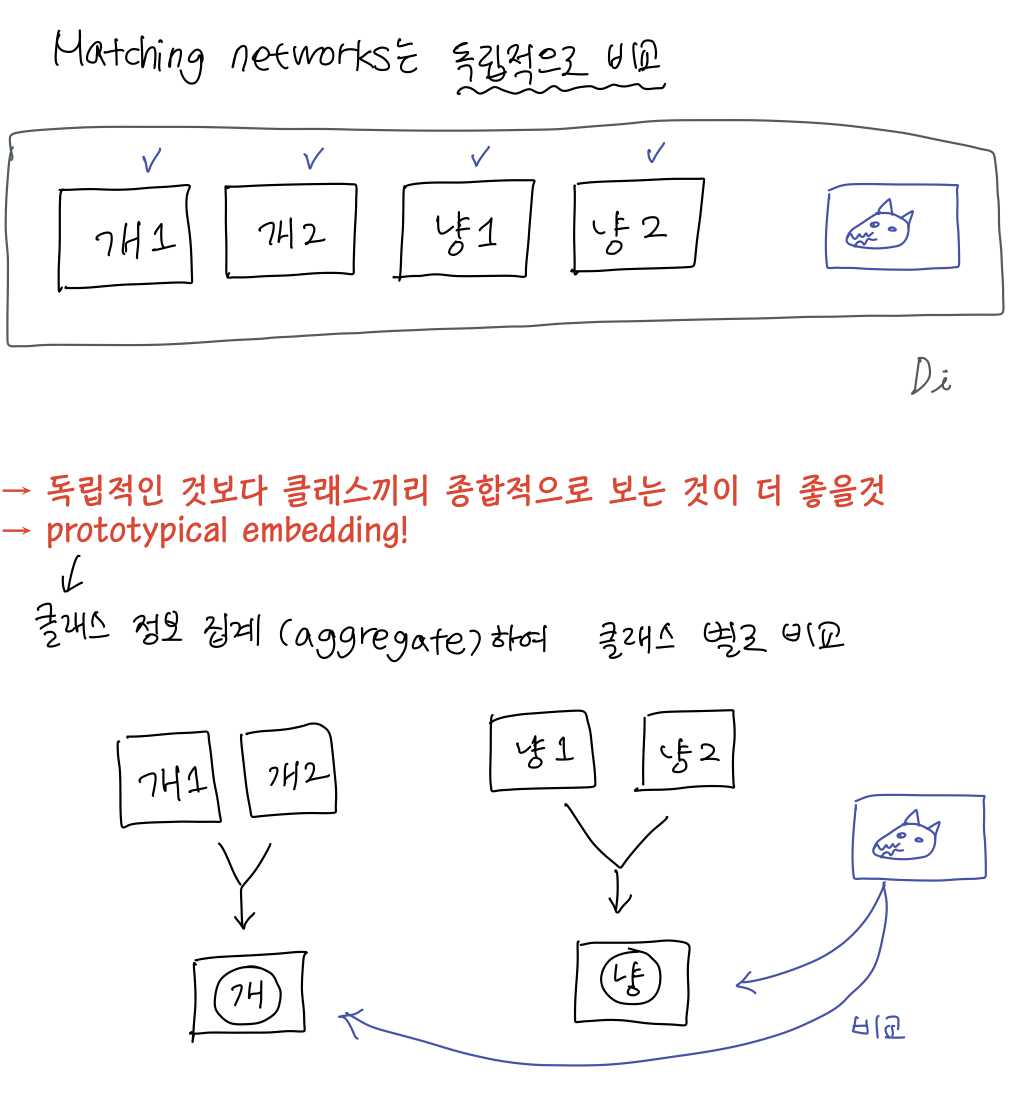
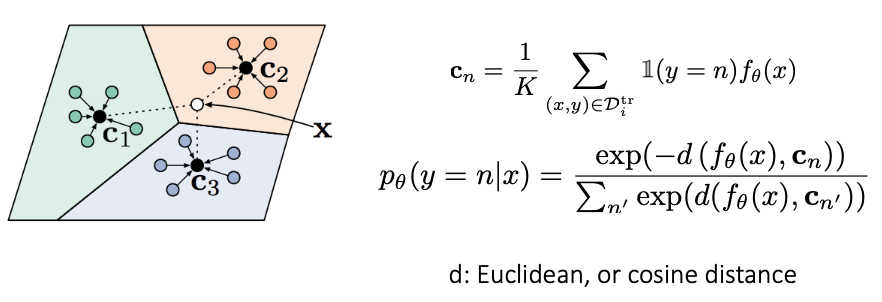
Prototypical Networks
- 각 클래스에 대한 데이터(example)이 한 개 이상인 경우, 각 클래스에 대한 정보를 집계(aggregation)하여 사용한다.
- 데이터를 같은 임베딩 공간에 삽입, 각 prototypical class까지 거리 계산
- 평균이용해서 집계한 후에 거리(d)측정해서 softmax 사용
더 복잡한 관계의 데이터들의 임베딩을 위해서는..
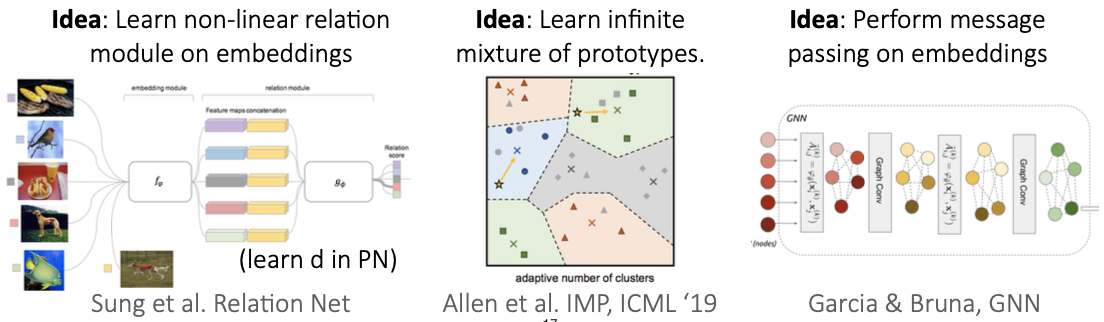
2. Case Study(Non-parametric few-shot learning)
cs330 2020 슬라이드 참고
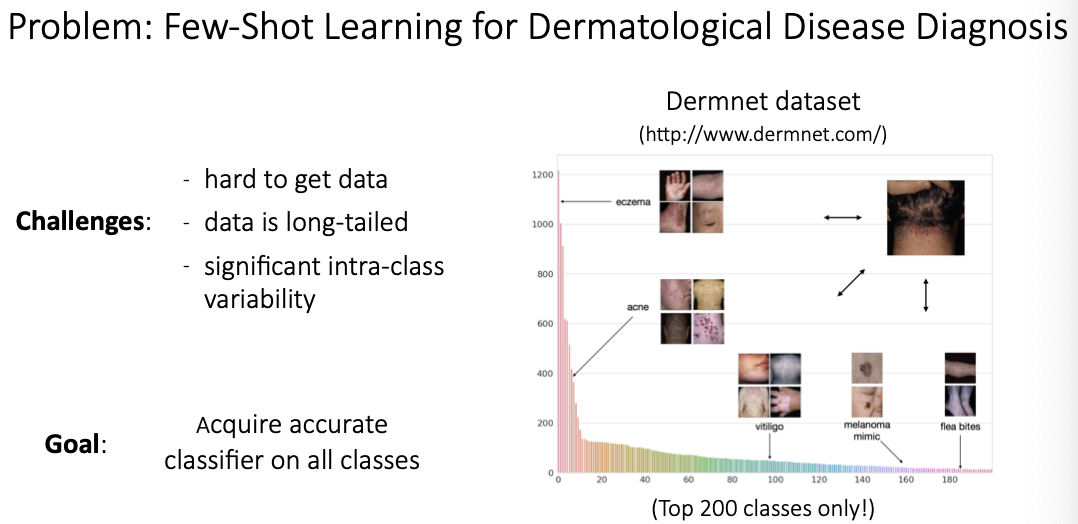
Prototypical Clustering Networks for Dermatological Image Classification

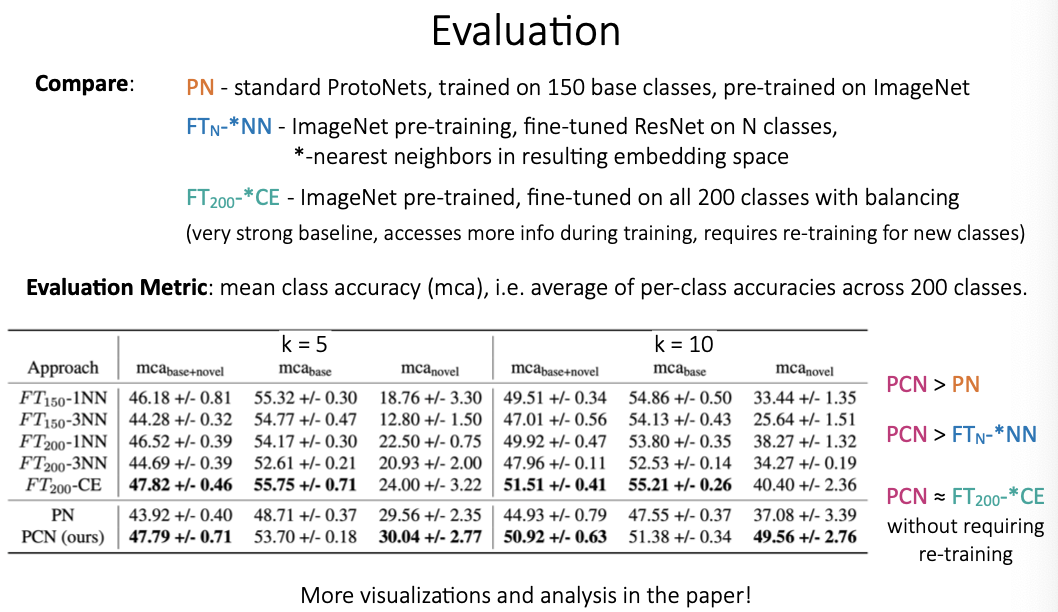
3. Properties of Meta-Learning Algorithms
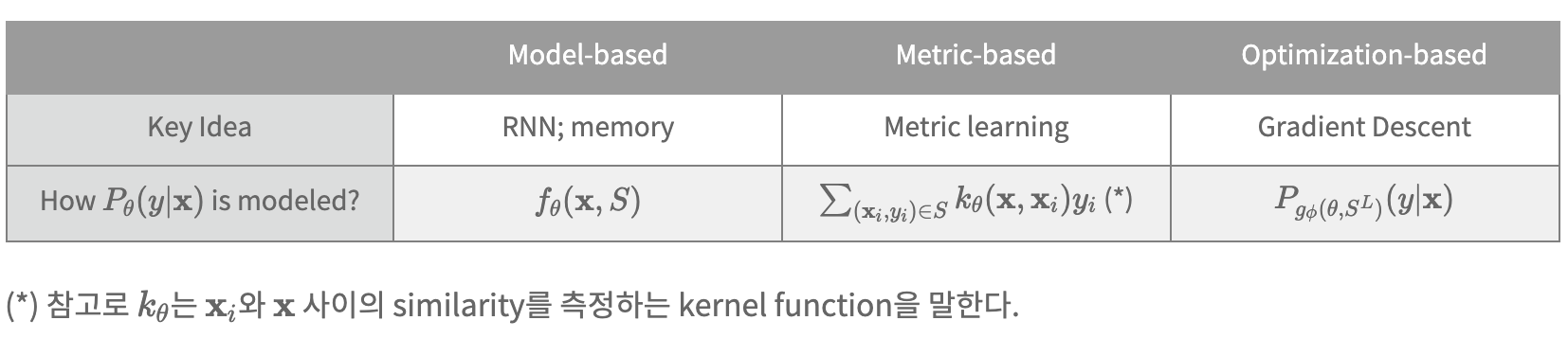
Black-box(Model-based) vs Optimization-based vs Non-parametric(metric-based)
Computation graph 관점

이외의 네트워크

Algorithmic properties 관점
'표현력'과 '일관성'이 중요
- 확장성, 다른 도메인들로의 활용을 위해서 표현력이 중요
- 메타러닝이 학습된 절차를 생성해놓으면 OOD(Out-of-distribution) task에도 잘 작용
장단점 비교

- Uncertainty awareness를 잘 하는 것 -> Basian-based meta-learning
References
- cs330(Multi-Task and Meta-Learning), Lecture4.Non-Parametric Meta-Learners
- 건국대학교 컴퓨터공학부 인공지능 수업
- meta-learning 분류,
Meta-Learning in Neural Networks: A Survey
Timothy Hospedales, Antreas Antoniou, Paul Micaelli, Amos Storkey - 전이학습 그림, https://www.researchgate.net/figure/Difference-between-Traditional-Machine-Learning-process-and-Transfer-Learning_fig7_326649052
- 전이학습 분류, https://ruder.io/thesis/index.html
- Machine learning with limited data F Yao ,2021
- Meta learning의 광대한 survey 보고 싶다면 Youtube
https://www.youtube.com/watch?v=c-ZgGEJ_M8M&list=WL&index=1 - 한국어로 현존하는 최고의 정리글, https://talkingaboutme.tistory.com/entry/DL-Meta-Learning-Learning-to-Learn-Fast
Appendix
[추가적인 용어 정리]
휴리스틱
휴리스틱(Heuristic)이란 시간이나 정보가 불충분하여 합리적인 판단을 할 수 없는 경우, 신속하게 사용하는 어림짐작의 기술을 일컫는다. 휴리스틱은 시험과 같은 추정뿐만 아니라 의사결정 문제에서도 자주 사용되는데, 그 중 가장 대표적인 것이 오컴의 면도날 (Occam's Razor)이다.
오컴의 면도날
Frustra fit per plura quod potest fieri per pauciora
같은 현상을 설명하는 두 개의 주장이 있다면, 간단한 쪽을 선택하라
Inductive bias
bias란 편견이나 offset과 비슷한 의미
여기서 inductive, 즉 귀납적이라는 말을 붙여서 기계학습에서의 inductive bias는, 학습 모델이 지금까지 만나보지 못했던 상황에서 정확한 예측을 하기 위해 사용하는 추가적인 가정을 의미합니다. (Wikipedia)
기계학습에서는 특정 목표 출력(target output)을 예측하기 위해 학습 가능한 알고리즘 구축을 목표로 하고, 학습 모델에는 제한된 수의 입력과 출력에 대한 data가 주어짐
학습이 성공적으로 끝난 후에, 학습 모델은 훈련동안에는 보이지 않았던 예들 까지도 정확한 출력에 가까워지도록 추측해야하기 때문에 이럴 때 추가적인 가정이 없이는 불가능한데, 이 Target function의 성질에 대해 필요한 가정과 같은 것이 Inductive bias라고 볼 수 있음
inductive bias의 예시로 오컴의 면도날이 있음
Model-Agnostic
model-agnostic 하다는 것은 학습에 사용된 model이 무엇인지에 구애받지 않고 독립적으로 모델을 해석할 수 있다는 의미입니다. 즉, 학습에 사용되는 모델과 설명에 사용되는 모델을 분리하겠다는 것입니다. 학습 모델과 설명 모델을 분리하는 것의 가장 큰 장점은 자율성입니다.분석가들은 기존에 자신들이 사용하던 모델들을 그대로 사용할 수 있으며, 어떤 모델을 사용했더라도 동일한 방식으로 해석할 수 있습니다.특히 비슷한 성능을 가지는 여러 모델 중 하나를 선택해야하는 상황이 발생했을 때, 모델을 해석한 결과를 동일한 기준으로 비교하여 객관적으로 더 나은 모델을 택할 수 있게 합니다.