모두의 딥러닝
번외 - 리눅스에서 Jupyter Notebook 개발환경 세팅
환경 : Ubuntu 22.04.2 LTS @ Virtual Box 7.0
1. 크롬 업데이트 방법
sudo apt-get update
sudo apt-get --only-upgrade install google-chrome-stable- 버전 확인
google-chrome --version
2. Anaconda3 설치
-
쉘 스크립트 파일 설치
wget https://repo.anaconda.com/archive/Anaconda3-2021.11-Linux-x86_64.sh
-
다운받은 경로로 가서 파일 실행
bash Anaconda3-2021.11-Linux-x86_64.sh
-
PATH 설정
conda init # init 하면 쉘 실행시 자동으로 base 가상환경 진입함.source ~/.bashrc위 명령어로 안되면 .bashrc 파일 열어서 마지막에 PATH 추가
vi ~/.bashrcexport PATH="/home/{username}/anaconda3/bin:$PATH"
3-1
conda activate {env name}오류
.bashrc 파일에 PATH 설정을 위와 같이 직접 할 경우conda activate deep_learning실행 시 아래와 같은 에러 메세지 발생.usage: conda [-h] [--no-plugins] [-v] command ...%0d%0aconda: error: argument command: invalid choice: 'activate'구글링 결과 PATH 충돌 혹은 설정 오류.
아래의 명령어로 가상환경 실행은 가능함 역시 스택오버플로source activate <env-name>
conda activate명령어는 쓰고싶고, 쉘 실행시 가상환경으로 넘어가기는 싫고, anaconda 전용 사용자를 따로 만들기도 싫어서 .bashrc 파일을 바꿔보았다.conda init으로 PATH 설정을 일단 해줌. (3단계 설정 안해주면conda init명령어도 실행 안됨.)- ChatGPT를 통해 해당 스크립트 명령어 해석을 부탁.
- ChatGPT의 해석을 믿고 초기 실행 구문을 삭제. 한 것이 아래 코드
if [ -f "/home/{user_name}/anaconda3/etc/profile.d/conda.sh" ]; then . "/home/{user_name}/anaconda3/etc/profile.d/conda.sh" else export PATH="/home/{user_name}/anaconda3/bin:$PATH" fi위의 스크립트문을 .bashrc 파일의 마지막 부분에 넣으면
conda activate실행 가능.
아래는 ChatGPT 대화 내용__conda_setup="$('/home/tony/anaconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)" if [ $? -eq 0 ]; then eval "$__conda_setup" else if [ -f "/home/tony/anaconda3/etc/profile.d/conda.sh" ]; then. "/home/tony/anaconda3/etc/profile.d/conda.sh" else export PATH="/home/tony/anaconda3/bin:$PATH" fi 해석해줘이 스크립트는 Conda를 환경 변수에 설정하는 Bash 스크립트입니다. 이 스크립트는 다음과 같은 작업을 수행합니다: 1. 먼저, `__conda_setup` 변수에 Conda의 Bash 쉘 후크 명령어를 할당합니다. 이 명령어는 Conda를 현재 Bash 세션에 설정하는 데 사용됩니다. 2. 다음으로, `$?` 환경 변수를 사용하여 바로 이전 명령어의 종료 코드를 확인합니다. 종료 코드가 0이라면 이전 명령어가 성공적으로 실행되었음을 의미합니다. 3. 종료 코드가 0이면 `eval "$__conda_setup"` 명령어를 실행하여 `__conda_setup`에 저장된 Conda 환경 변수 설정 명령어를 실행합니다. 4. 종료 코드가 0이 아니라면 Conda의 Bash 쉘 후크 스크립트 파일(`conda.sh`)이 존재하는지 확인합니다. 해당 파일이 존재하면 그 파일을 실행하여 Conda 환경 변수를 설정합니다. 5. 위의 두 조건이 모두 만족되지 않으면 스크립트는 Conda 바이너리가 있는 디렉토리를 현재 환경 변수 `$PATH`에 추가하여 Conda를 사용할 수 있도록 합니다. 이 스크립트는 Conda를 환경 변수에 올바르게 설정하고 실행 가능한 상태로 만들어주는 역할을 합니다.마지막의 unset __conda_setup은 뭐야`unset __conda_setup`은 `__conda_setup`이라는 환경 변수를 제거하는 명령어입니다. 스크립트가 실행된 후에 이 환경 변수가 더 이상 필요하지 않을 때 이 명령어를 사용하여 해당 환경 변수를 제거할 수 있습니다. 이렇게 하면 불필요한 환경 변수를 메모리에서 제거하여 시스템 자원을 절약할 수 있습니다.위의 코드를 이렇게 바꿔봤는데 생길 수 있는 문제가 무엇일까 if [ -f "/home/tony/anaconda3/etc/profile.d/conda.sh" ]; then . "/home/tony/anaconda3/etc/profile.d/conda.sh" else export PATH="/home/tony/anaconda3/bin:$PATH" fi위의 코드는 기존 스크립트의 일부분을 수정한 것으로 보입니다. 이 변경 사항에 따라 다음과 같은 문제가 발생할 수 있습니다: 1. **conda.sh 파일이 없는 경우 문제:** 만약 `/home/tony/anaconda3/etc/profile.d/conda.sh` 파일이 실제로 존재하지 않는다면, 해당 파일을 소스로 사용하려고 시도할 때 오류가 발생할 것입니다. 이 경우 스크립트가 실패하고 Conda 환경 변수가 설정되지 않을 것입니다. 2. **환경 변수 충돌:** 이미 `$PATH`에 같은 경로가 추가되어 있는 경우, 중복된 경로가 발생할 수 있습니다. 이는 환경 변수 충돌을 일으키고 의도치 않은 동작을 유발할 수 있습니다. 3. **권한 문제:** Conda 설치 경로나 conda.sh 파일에 대한 쓰기 및 실행 권한이 부여되어 있지 않으면 스크립트가 실패할 수 있습니다. 4. **파일 경로 변경:** Conda 설치 경로가 변경되었거나 파일 경로가 잘못 설정된 경우, 파일을 찾을 수 없어 오류가 발생할 수 있습니다. 이러한 문제를 방지하려면 스크립트를 실행하기 전에 관련 파일 및 디렉토리의 존재 여부를 확인하고, 환경 변수를 추가하기 전에 중복 여부를 확인하는 것이 좋습니다. 또한 파일 및 디렉토리에 적절한 권한이 부여되어 있는지 확인해야 합니다.
3. conda 명령어
conda install anaconda-clean # anaconda 삭제
# 이후에 $rm -rf ~/anaconda3 로 파일도 삭제
conda env list # 가상환경 리스트 확인
conda create -n {가상환경 이름} python={3.9.7} # 가상환경 생성
conda activate {가상환경 이름} # 가상환경 활성화
conda install -c conda-forge {패키지 이름} # 패키지 설치
conda uninstall {패키지 이름} # 패키지 삭제
conda list # 가상환경 내 설치된 패키지 리스트 확인
conda deactivate # 가상환경 비활성화
conda env remove -n {가상환경 이름} # 가상환경 삭제
conda create --name {새로 만들 가상환경 이름} --clone {복제할 기존 가상환경 이름}
# 기존 가상환경을 복제하여 새 가상환경 생성
conda install -c "nvidia/label/cuda-11.7.0" cuda-nvcc # cuda tool kit 설치
4. Jupyter Notebook 설치 및 실행
$ anaconda-navigator: Anaconda Navigator 실행- Open Terminal
$ conda install jupyter==1.0.0
$ conda activate {env name}$ jupyter notebook
4-1. $ anaconda-navigator 실행 안될 때
기본적으로 만들어지는 base 가상환경에서 실행.
5. Jupyter Notebook Keyboard Shortcut
- A : 윗줄 추가
- B : 아랫줄 추가
- M : Markdown으로 변경
- Y : 코드로 변경
- Enter : 편집 모드
- Esc : 해당 블럭에서 나옴
- CTRL + Enter : 코드 블럭 실행
- Shift + Enter : 코드 블럭 실행하고 다음 블럭으로 이동
- 방향키 사용 가능, Help -> Keyboard Shortcuts 보기
명령어 설명
$ source: 현재 쉘에 .bashrc 파일 적용- bashrc 파일 : 사용자(현재 권한)가 쉘 시작 할때 자동 실행. 스크립트 명령어 적혀있음
- ~/ : 홈 폴더
sudo cp ./.bashrc /root/su실행 전 사용자 권한 상태일 때 .bashrc 파일을 /root/ 폴더에 카피함
Chap 1. 해보자! 딥러닝
| 인공지능 > 머신러닝 > 딥러닝 |
|---|
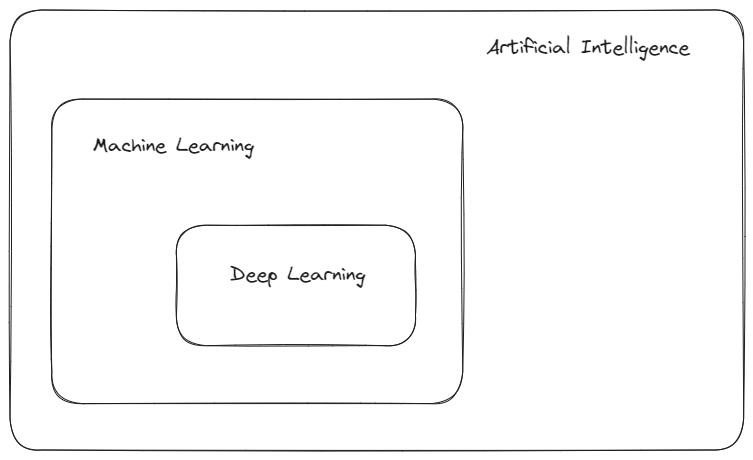 |
지도 학습 : CNN, RNN 등
비지도 학습 : GAN, 오토인코더 등 -> 후반부
Chap 2. 딥러닝의 핵심 미리보기
Hardware Spec
CPU : i7-12700H
GPU : RTX 3060 Laptop
RAM : 삼성전자 DDR5 4800 16GB x 2channels
V-Box 할당
CPU : 8개
Memory : 4096MB
Video Memory : 64MB
교재 세팅
Anaconda3-2021.11-Linux-x86_64
가상환경 내부
파이썬 : 3.9.7
jupyter notebook : 1.0.0
tensorflow : 2.6.1
keras : 2.6
교재 대로 했을 때 import tensorflow 구문에서 아래와 같은 TypeError가 떴다.
TypeError Traceback (most recent call last)
File ~/anaconda3/envs/deep_learning/lib/python3.9/site-packages/tensorflow/core/framework/resource_handle_pb2.py:16
11 # @@protoc_insertion_point(imports)
13 _sym_db = _symbol_database.Default()
---> 16 from tensorflow.core.framework import tensor_shape_pb2 as tensorflow_dot_core_dot_framework_dot_tensor__shape__pb2
17 from tensorflow.core.framework import types_pb2 as tensorflow_dot_core_dot_framework_dot_types__pb2
20 DESCRIPTOR = _descriptor.FileDescriptor(
21 name='tensorflow/core/framework/resource_handle.proto',
22 package='tensorflow',
TypeError: Descriptors cannot not be created directly.
If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.
If you cannot immediately regenerate your protos, some other possible workarounds are:
1. Downgrade the protobuf package to 3.20.x or lower.
2. Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).
More information: https://developers.google.com/protocol-buffers/docs/news/2022-05-06#python-updates해당 에러 관련 stackoverflow 와 github issue 에 따르면 버전 문제인 것 같다. 가장 먼저 의심이 되는 deep_learning의 가상환경 파이썬 버전인 3.9.7을 3.10.13으로 업데이트 해주었다.
이후 jupyter notebook에 들어가 !pip install tensorflow==2.6.1 을 실행하니 버전을 찾을 수 없다고 하였다. 그래서 가장 가까운 tensorflow 2.8.4를 설치해주었다.
-> 발생한 문제점 : import tensorflow 문 실행 시 커널이 죽음
-> 요 블로그 2번째 방법에 따라 conda install tensorflow 로 tensorflow 설치했다.
-> print(tensorflow.__version__) 을 이용하여 tensorflow 버전을 찍어본 결과 2.12.0 버전이 설치되었지만 아래의 warning이 떴다.
I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: SSE4.1 SSE4.2, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2.12.0tensorflow 가 어차피 교재 이후 버전이기 때문에 anaconda 부터 jupyter notebook, python, tensorflow 모두 버전을 지정하지 않고 가장 최근 버전으로 다운받았다. warning은 고치지 못했다.
버전 정보
Anaconda3-2023.09-0-Linux-x86_64
가상환경 내
python : 3.12가 최신인데 3.11.5를 추천하길래 이걸로 설정함
jupyter notebook : --version 찍어서 나온 것 중 일부
IPython : 8.15.0
ipykernel : 6.25.0
jupyter_client : 7.4.9
jupyter_core : 5.5.0
jupyter_server : 1.23.4
jupyterlab : 3.6.3
notebook : 6.5.4
tensorflow : 2.12.0
keras : 2.12.0
- 라이브러리 호출
from tensorflow.keras.models import Sequential # 텐서플로의 케라스 API에서 필요한 함수들을 불러옵니다.
from tensorflow.keras.layers import Dense # 데이터를 다루는데 필요한 라이브러리를 불러옵니다.
import numpy as nptensorflow의 keras API에 있는 models 클래스로부터 Sequential 함수 불러오기
numpy 라이브러리를 np라는 이름으로 사용
라이브러리에 포함된 모듈이 너무 많고, 지금 일부 모듈만 필요할 때
from (라이브러리명) import (함수명)
- 넘파이 라이브러리를 이용한 데이터 불러오기
data_set = np.loadtxt("./data/ThoraricSurgery3.csv", delimiter=",")현재 폴더의 data의 ThoraricSurgery3.cst 내용을 data_set에 넣음. 구분점은 ,
ThoraricSurgery3.csv data set 형태
1,2.88,2.16,1,0,0,0,1,1,3,0,0,0,1,0,60,0
2,3.4,1.88,0,0,0,0,0,0,1,0,0,0,1,0,51,0
2,2.76,2.08,1,0,0,0,1,0,0,0,0,0,1,0,59,0
2,3.68,3.04,0,0,0,0,0,0,0,0,0,0,0,0,54,0
2,2.44,0.96,2,0,1,0,1,1,0,0,0,0,1,0,73,1
2,2.48,1.88,1,0,0,0,1,0,0,0,0,0,0,0,51,0
2,4.36,3.28,1,0,0,0,1,0,1,1,0,0,1,0,59,1
1,3.19,2.5,1,0,0,0,1,0,0,0,0,1,1,0,66,1
2,3.16,2.64,2,0,0,0,1,1,0,0,0,0,1,0,68,0
2,2.32,2.16,1,0,0,0,1,0,0,0,0,0,1,0,54,0
딥러닝을 위한 데이터셋 구성은 속성과 클래스로 구성. (class는 이름표 같은거)
Thoraric*.csv 에서 앞의 16개는 attribute(의료 기록), 마지막 하나는 class(사망: 0, 생존: 1)
- 딥러닝을 위한 데이터셋 지정
Data_set = np.loadtxt("./data/ThoraricSurgery3.csv", delimiter=",") # 준비된 수술 환자 데이터를 불러옵니다.
X = Data_set[:,0:16] # 환자의 진찰 기록을 X로 지정합니다.
y = Data_set[:,16] # 수술 후 사망/생존 여부를 y로 지정합니다.Data_set의 모든 행의 1번째 열부터 16번째 열까지 X에 지정
Data_set의 모든 행의 17번째 열의 데이터를 y에 지정
속성과 클래스를 서로 다른 데이터셋으로 지정.
콜론 앞의 숫자는 범위의 맨 처음.
콜론 뒤는 이 숫자가 가리키는 위치 바로 앞이 범위의 마지막.
a[1:7]이면 1번 인덱스인 2번째 데이터부터 7번 인덱스 바로 앞인 7번째 데이터까지
보통 집합은 대문자로, 원소는 소문자로 표시
- Keras 사용법
model = Sequential() # 딥러닝 모델의 구조를 결정합니다.
model.add(Dense(30, input_dim=16, activation='relu'))
model.add(Dense(1, activation='sigmoid'))딥러닝의 층 구조를 Keras의 Sequential() 함수로 선언
model.add로 1층, 2층 적층
Dense : 입력과 출력을 모두 연결.
이 외의 내용은 추후에 -> 나중에 나오면 링크 걸어두기
딥러닝 설계 : 어떤 층을 몇 개로 어떻게 쌓을 것인지, 내부 변수들을 어떻게 정할지 고민하는 것.
- 모델 실행
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 딥러닝 모델을 실행합니다.
history=model.fit(X, y, epochs=5, batch_size=16)model.compile() : model 설정 그대로 실행
model.fit() : 층을 이동하면서 몇 개의 데이터를 사용할지.
이 외의 내용은 추후에 -> 나중에 나오면 링크 걸어두기
- warning
3번째 구조 결정 단계에서 warning 뜸.
이전에 떴던 warning과 비슷한 최적화 문제인듯.
jupyter 말고 python denv로 가상환경 만들고 visual code에서 한 번 돌려보면 고쳐질수도? 안되면 Virtual box 말고 실제 머신에서 gpu 쓰도록 설정하고 돌리면 될지도
I tensorflow/core/common_runtime/process_util.cc:146]
Creating new thread pool with default inter op setting:
2. Tune using inter_op_parallelism_threads for best performance.Chap 3. 딥러닝을 위한 기초 수학
1. 다항 함수
-
1차함수
m : 기울기, b : 절편 -
2차 함수
만큼 평행이동
2. 미분
-
순간 변화율
-
편미분
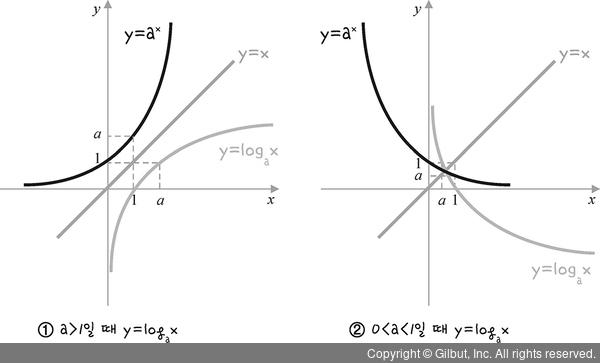
3. 지수 함수
- 값에 따라 증가 또는 감소
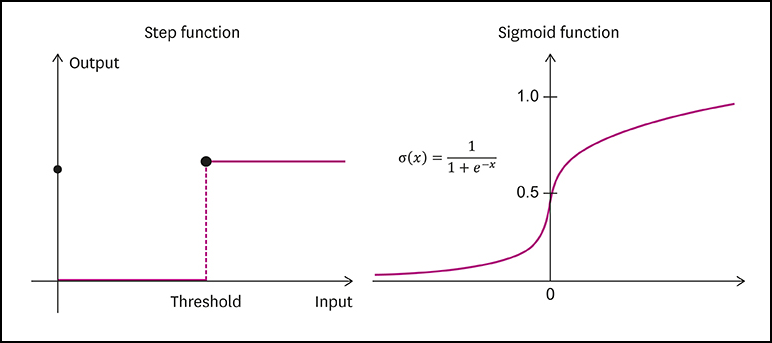
4. 시그모이드 함수
- 가 지수 함수에 포함되어 분모에 들어가는 함수
| Sigmoid Function |
|---|
 |
5. 로그 함수
- a 값에 따라 증가 또는 감소
| Exponential Function, Logarithmic function |
|---|
 |
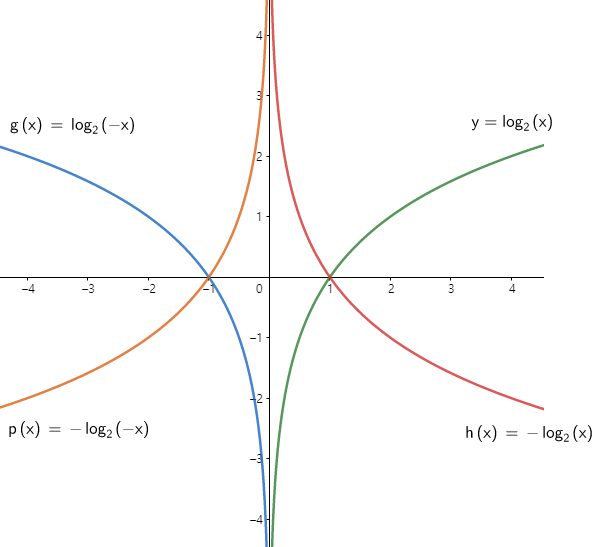
| Symmetric transposition of Logarithmic function |
|---|
 |
