딥러닝의 시작, 신경망
Chap 7. 퍼셉트론과 인공지능의 시작
-
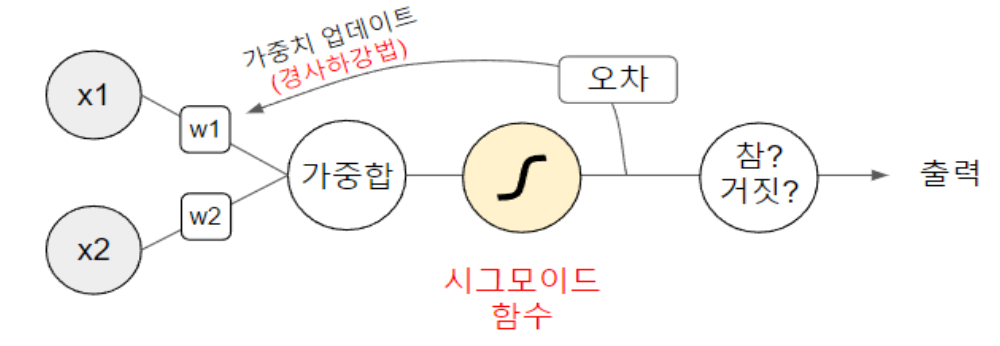
인간의 뉴런의 동작 원리 로지스틱 회귀
-
인공 신경망(artificial neural network)
뉴런과 비슷한 매커니즘. 즉, 켜고 끄는 기능이 있는 신경 을 그물망 형태로 연결하면 인공적으로 '생각'하는, 사람의 뇌처럼 동작할 수 있을 가능성이 있다. -
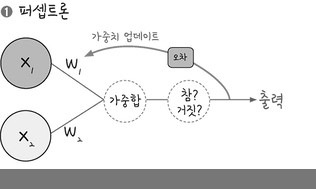
퍼셉트론(perceptron)
입력 값 여러 개 받아 출력을 만드는데 입력 값에 가중치를 조절할 수 있게 만들어 학습 을 가능하게 했다.
| 퍼셉트론 |
|---|
 |
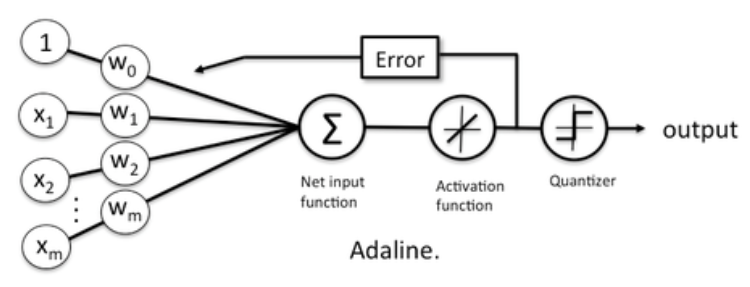
- 아달라인(Adaline)
퍼셉트론에 경사 하강법을 도입하여 최적의 경계선을 그릴 수 있게 함. 이후 서포트 벡터 머신(Support Vector Machine) 으로 발전
| 아달라인 |
|---|
 |
| 로지스틱 회귀 |
|---|
 |
- 가중합(weighted sum)
입력 값과 가중치를 모두 곱한 후 바이어스를 더한 값
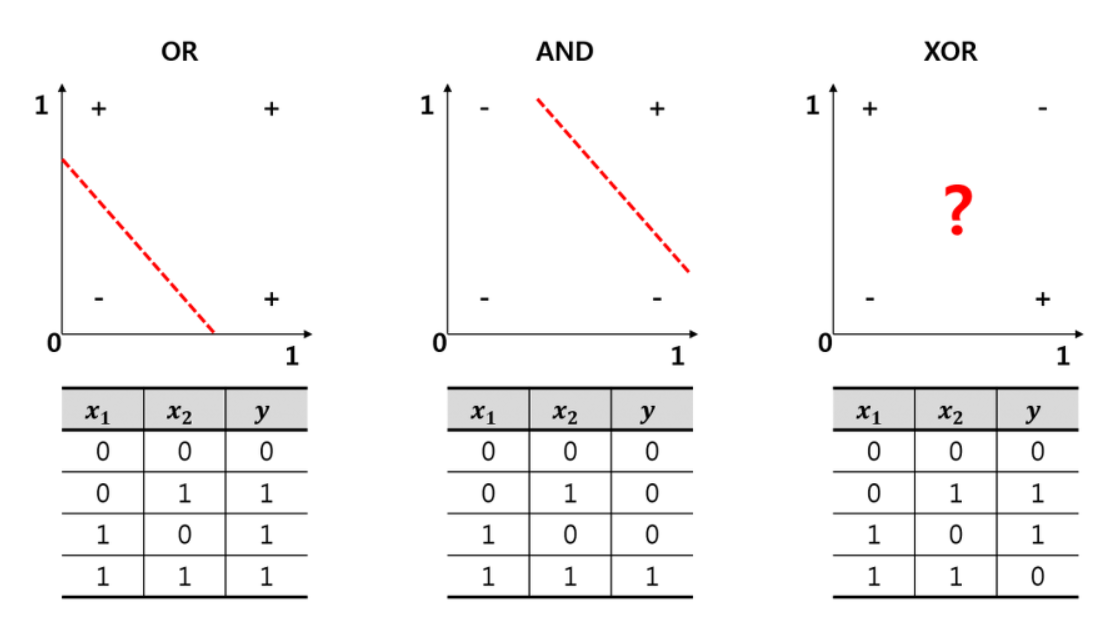
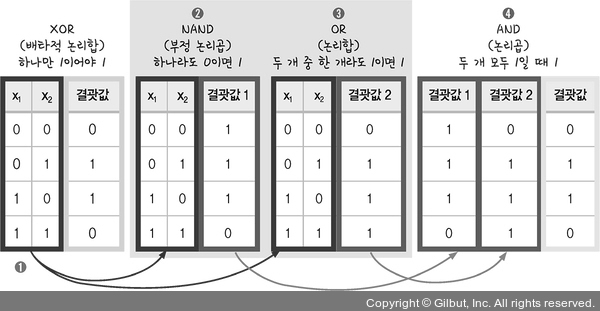
XOR 문제
2차 평면에서 직선 긋는 걸로 XOR 풀지 못함
| A | B | A ⊕ B |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
| XOR 문제 |
|---|
 |
해결법
- 다층 퍼셉트론(multilayer perceptron), 오차 역전파(back propagation)
Chap 8. 다층 퍼셉트론(multilayer perceptron)
| XOR 문제 푸는법 |
|---|
 |
즉, 퍼셉트론 두 개를 한 번에 계산하기 위해 퍼셉트론을 각각 처리하는 은닉층(hidden layer) 만듬.
| XOR 문제 푸는법 with 다층 퍼셉트론 |
|---|
 |
| XOR 문제 푸는법 with 다층 퍼셉트론 |
|---|
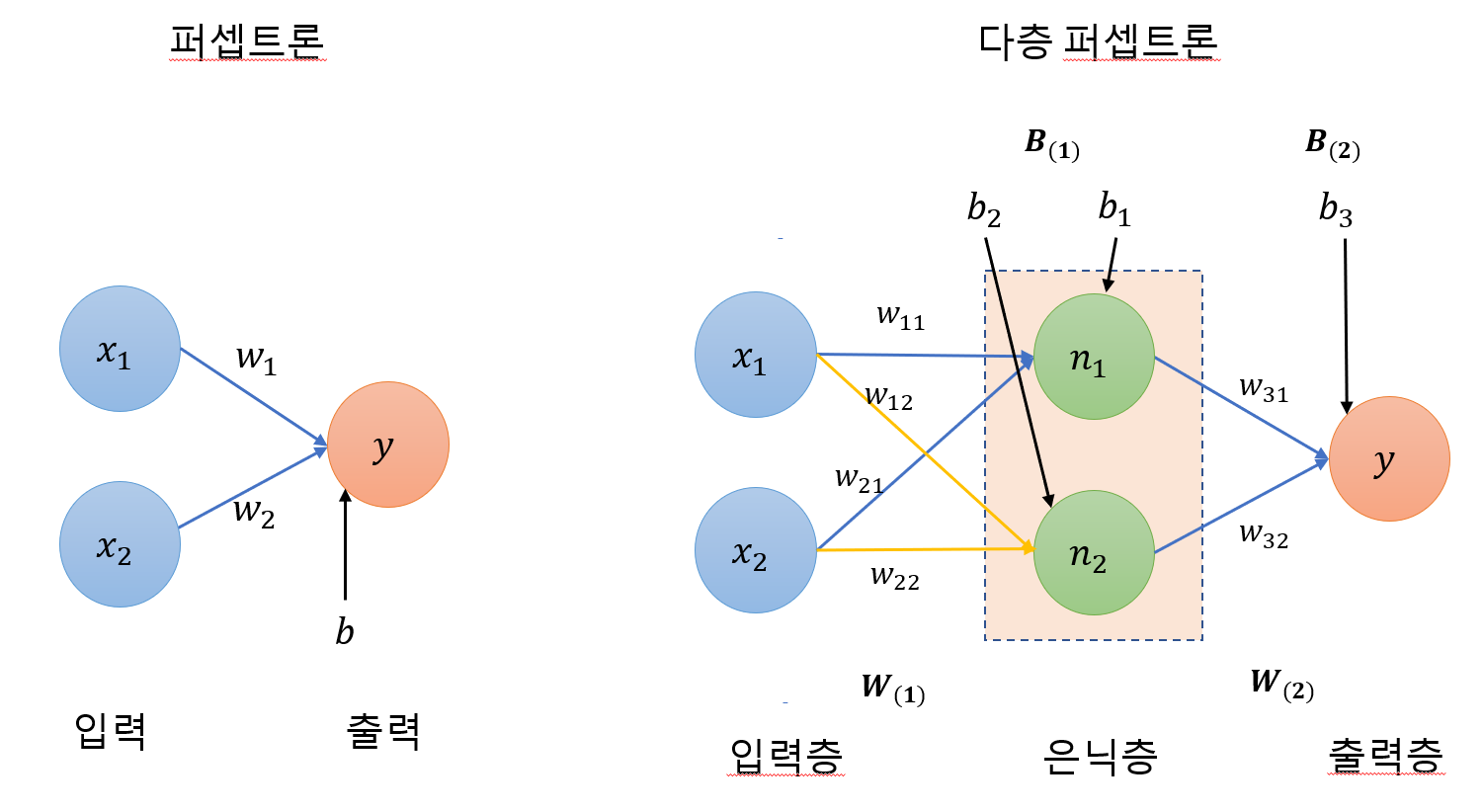 |
- , : 입력 값
- : 가중치
- : 바이어스
- : node, 은닉층의 중간 정거장
예시
즉, 2개의 은닉층을 위해 6개의 가중치와 3개의 바이어스가 필요하다.
Python
import numpy as np
w11 = np.array([-2, -2])
w12 = np.array([2, 2])
w2 = np.array([1, 1])
b1 = 3
b2 = -1
b3 = -1
def MLP(x, w, b):
y = np.sum(w * x) + b
if y <= 0:
return 0
else:
return 1
def NAND(x1,x2):
return MLP(np.array([x1, x2]), w11, b1)
def OR(x1,x2):
return MLP(np.array([x1, x2]), w12, b2)
def AND(x1,x2):
return MLP(np.array([x1, x2]), w2, b3)
def XOR(x1,x2):
return AND(NAND(x1, x2),OR(x1,x2))
for x in [(0, 0), (1, 0), (0, 1), (1, 1)]:
y = XOR(x[0], x[1])
print("입력 값: " + str(x) + " 출력 값: " + str(y)) Chap 9. 오차 역전파에서 딥러닝으로
| 은닉층이 존재하는 다층 퍼셉트론 |
|---|
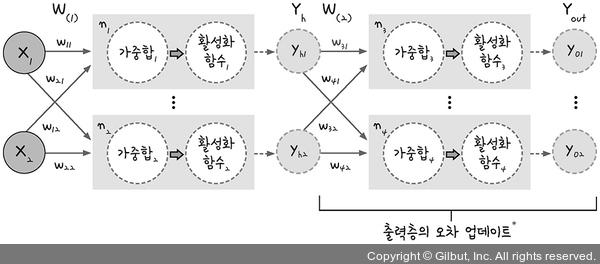 |
문제점 1 : 은닉층의 오차 구하기
-
경사 하강법을 위해서는 오차를 구해야 한다.
→ 오차는 실제 값과 결과 값을 비교해 구한다.
→ 은닉층의 결과 값을 구할 수 없다. -
해결법 : 출력층의 오차를 이용
첫 번째 가중치 업데이트 공식 :
두 번째 가중치 업데이트 공식 :
델타식 :
수식 설명
을 이용하여 가중치 와 를 업데이트 하는것이 머신러닝의 동작이다.
의 을 업데이트 해보기
은 다음과 같이 업데이트 할 수 있다. 가중치 업데이트
이를 위해 의 오차를 구한다.
-
안에는 과 두 개의 출력 값이 있다. 즉, 의 오차 = 의 오차 + 의 오차
-
MSE 를 이용하여 오차 , 구하기 ( : target 즉, 실제 값)
- 연쇄 법칙(chain rule) 을 이용하여 구하기
- 우변의 첫 항 구하기
- 둘째 항 구하기
활성화 함수를 시그모이드 함수라 하면,
- 셋째 항 구하기
시그모이드 함수에서 가장 안정된 예측을 위한 바이어스 값은 1이다.
델타식 을 라 하면,
의 업데이트 하기
- 우변 첫번째 항 구하기
- 구하기
- 구하기
한편, 은닉층에서는 을 구하는 중이므로, 으로 두면
즉
따라서 은닉층의 오차 업데이트 식은 다음과 같다.
-
출력층()의 오차 업데이트 수식 :
-
은닉층()의 오차 업데이트 수식 :
은 오차 값 이므로 도 오차 값이다.
따라서 은닉층도 '오차 ' 이므로
Python
import random
import numpy as np
# xor 진리표
data = [
[[0, 0], [0]],
[[0, 1], [1]],
[[1, 0], [1]],
[[1, 1], [0]]
]
# 실행 횟수(iterations), 학습률(lr), 모멘텀 계수(mo)
iterations=5000
lr=0.1
mo=0.4
# 활성화 함수 1 sigmoid 함수, 미분값을 반환하거나 sigmoid 함수값 반환
def sigmoid(x, derivative=False):
if (derivative == True):
return x * (1 - x)
return 1 / (1 + np.exp(-x))
# 활성화 함수 2 하이퍼볼릭 탄젠트 함수, 미분값을 반환하거나 tanh 함수값 반환
def tanh(x, derivative=False):
if (derivative == True):
return 1 - x ** 2
return np.tanh(x)
# 가중치들을 저장하는 배열
def makeMatrix(i, j, fill=0.0):
mat = []
for i in range(i):
mat.append([fill] * j)
return mat
# 위에서 계산한 수식 토대로 신경망 학습 실행
class NeuralNetwork:
# 초기화
def __init__(self, num_x, num_yh, num_yo, bias=1):
self.num_x = num_x + bias
self.num_yh = num_yh
self.num_yo = num_yo
# 활성화 함수 input = 입력 값 개수, hidden = 은닉층 개수, out = 출력값 개수
self.activation_input = [1.0] * self.num_x
self.activation_hidden = [1.0] * self.num_yh
self.activation_out = [1.0] * self.num_yo
# weight_in = 배열
self.weight_in = makeMatrix(self.num_x, self.num_yh)
# weight_in[입력 값, 은닉층]에 랜덤값 저장
for i in range(self.num_x):
for j in range(self.num_yh):
self.weight_in[i][j] = random.random()
# weight_out = 배열
self.weight_out = makeMatrix(self.num_yh, self.num_yo)
# weight_out[은닉층, 출력 값] = 랜덤
for j in range(self.num_yh):
for k in range(self.num_yo):
self.weight_out[j][k] = random.random()
# 모멘텀 SGD를 위한 이전 가중치 초깃값
self.gradient_in = makeMatrix(self.num_x, self.num_yh)
self.gradient_out = makeMatrix(self.num_yh, self.num_yo)
# 업데이트 함수
def update(self, inputs):
# inputs : 진리표
for i in range(self.num_x - 1):
self.activation_input[i] = inputs[i]
# 은닉층의 활성화 함수
for j in range(self.num_yh):
sum = 0.0
for i in range(self.num_x):
# sum = 진리표 * 은닉층 들어올 때 가중치(초기:랜덤값) 합
sum = sum + self.activation_input[i] * self.weight_in[i][j]
# hidden = 입력과 출력 표에 가중치를 곱한 값들의 합을 tanh를 거쳐서
self.activation_hidden[j] = tanh(sum, False)
# 출력층의 활성화 함수
for k in range(self.num_yo):
sum = 0.0
for j in range(self.num_yh):
# sum = 은닉층 출력 * 가중치들의 합
sum = sum + self.activation_hidden[j] * self.weight_out[j][k]
# out = sum을 tanh 거쳐서
self.activation_out[k] = tanh(sum, False)
return self.activation_out[:]
# 역전파의 실행
def backPropagate(self, targets):
# 델타 출력 계산
output_deltas = [0.0] * self.num_yo
for k in range(self.num_yo):
# targets : 진리표, error = 실제 값 - 예측 값
error = targets[k] - self.activation_out[k]
# output_deltas = 예측 값을 tanh의 미분 함수(yo(1-yo))에 넣고 * 오차(yt-yo)
output_deltas[k] = tanh(self.activation_out[k], True) * error
# 은닉 노드의 오차 함수
hidden_deltas = [0.0] * self.num_yh
for j in range(self.num_yh):
error = 0.0
for k in range(self.num_yo):
# error = (yt-yo)(yo(1-yo)) * 출력층 가중치 들의 합
error = error + output_deltas[k] * self.weight_out[j][k]
# hidden_deltas = yh(1-yh) * error
hidden_deltas[j] = tanh(self.activation_hidden[j], True) * error
# 출력 가중치 업데이트
for j in range(self.num_yh):
for k in range(self.num_yo):
# gradient = (yt-yo)(yo(1-yo)) * yh
gradient = output_deltas[k] * self.activation_hidden[j]
# v = 모멘텀 계수 * gradient_out - 학습률 * gradient
v = mo * self.gradient_out[j][k] - lr * gradient
# weight_out = 출력층 가중치
self.weight_out[j][k] += v
#gradient_out = 출력층 가중치 업데이트 공식
self.gradient_out[j][k] = gradient
# 입력 가중치 업데이트
for i in range(self.num_x):
for j in range(self.num_yh):
gradient = hidden_deltas[j] * self.activation_input[i]
v = mo*self.gradient_in[i][j] - lr * gradient
self.weight_in[i][j] += v
self.gradient_in[i][j] = gradient
# 오차의 계산(최소 제곱법)
error = 0.0
for k in range(len(targets)):
error = error + 0.5 * (targets[k] - self.activation_out[k]) ** 2
return error
# 학습 실행
def train(self, patterns):
for i in range(iterations):
error = 0.0
for p in patterns:
inputs = p[0]
targets = p[1]
self.update(inputs)
error = error + self.backPropagate(targets)
if i % 500 == 0:
print('error: %-.5f' % error)
# 결괏값 출력
def result(self, patterns):
for p in patterns:
print('Input: %s, Predict: %s' % (p[0], self.update(p[0])))
if __name__ == '__main__':
# 두 개의 입력 값, 두 개의 레이어, 하나의 출력 값을 갖도록 설정
n = NeuralNetwork(2, 2, 1)
# 학습 실행
n.train(data)
# 결괏값 출력
n.result(data)
# Reference: http://arctrix.com/nas/python/bpnn.py (Neil Schemenauer)문제점 2 : 가중치 수정 중 0에 수렴하는 문제
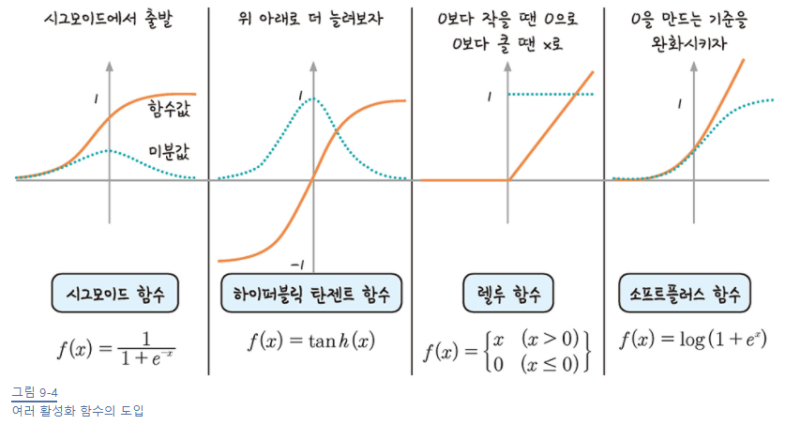
-
활성화 함수인 시그모이드 함수의 미분 최대값은 0.25. 즉, 0보다 작으므로 은닉층이 많아질 수록 0에 수렴.
-
해결법 : 새로운 활성화 함수
| 활성화 함수와 미분값 |
|---|
 |
| 그 외 활성화 함수 |
|---|
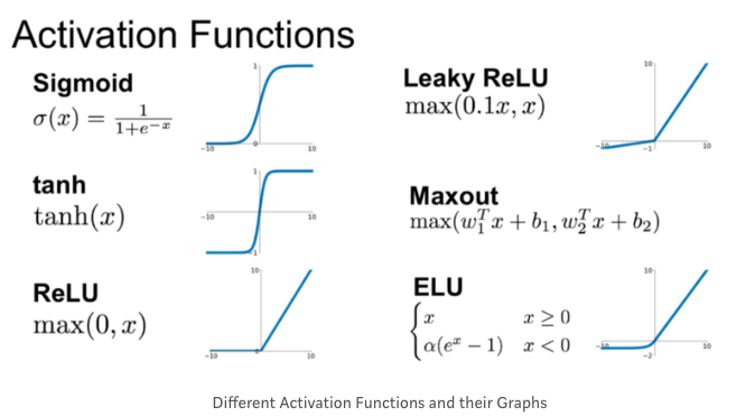 |
고급 경사 하강법
확률적 경사 하강법(Stochastic Gradient Descent, SGD)
랜덤하게 추출한 일부 데이터만 사용하여 오차 수정
모멘텀 확률적 경사 하강법 (momentum SGD)
오차를 수정하기 전 바로 앞 수정 값과 방향을 참고해 같은 방향으로 일정한 비율만 수정되게 하는 방법
그 외
- 아다그라드(adagrad)
- 네스테로프 모멘텀(NAG)
- 알엠에스프롭(RMSProp)
- 아담(adam)
