딥러닝 기본기 다지기
Chap 13. 모델 성능 검증하기
과적합 이해하기
- 과적합(overfitting)
모델이 학습 데이터셋 안에서는 일정 수준 이상의 예측 정확도를 보이지만, 새로운 데이터에 적용하면 잘 맞지 않는 것
층이 너무 많거나 변수가 복잡할 때 혹은, 테스트셋과 학습셋이 중복될 때 발생
학습셋과 테스트셋
-
과적합을 방지하기 위해 데이터셋을 학습셋과 테스트셋으로 구분한다.
-
머신 러닝의 개발 순서
학습셋을 이용하여 만든 '모델'을 테스트셋에 적용하여 딥러닝 같은 알고리즘을 충분히 조절해 가장 나은 모델을 만들고 이를 실생활에 대입.
| 학습셋에서의 에러와 테스트셋에서의 과적합 |
|---|
 |
- 은닉층이 올라갈 수록 테스트셋의 예측률은 증가하다 과적합 발생 시 감소한다.
Python
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
import pandas as pd
df = pd.read_csv('./data/sonar3.csv', header=None)
# df.head()
X = df.iloc[:,0:60]
y = df.iloc[:,60]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=True)
model = Sequential()
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history=model.fit(X_train, y_train, epochs=200, batch_size=10)
score=model.evaluate(X_test, y_test)
print('Test accuracy:', score[1])
df.head(): 첫 5줄 데이터 출력
x : 0 ~ 59 : 속성
y : 60 : 클래스
사이킷런train_test_split()함수 : 테스트셋의 비율로 학습셋, 테스트셋 나눔
model.evaluate(): 테스트셋 적용 함수compile 실행 시 정확도
Epoch 200/200
15/15 [==============================] - 0s 3ms/step - loss: 0.0391 - accuracy: 0.9931evaluate 실행 시 정확도
Test accuracy: 0.761904776096344
- 딥러닝의 경우 데이터가 많아질수록 모델 성능이 증가됨.
- 하지만 데이터를 추가하는 것 자체가 어렵거나 추가만으로는 성능의 한계가 있다.
- 데이터 보완 방법
- 사진의 경우 크기 확대/축소, 위아래로 조금씩 움직이기
- 테이블형의 경우 크기를 조절, 시그모이드 함수로 전체를 0~1 사이의 값으로 변환
- 교차 검증 방법 사용
- 알고리즘 최적화 방법
- 은닉층의 개수, 노드 수, 최적화 함수의 종류 등을 바꾸는 것
- 데이터에 따라 딥러닝이 아닌 랜덤 포레스트, XGBoost, SVM 등 다른 알고리즘 사용
- 머신 러닝 + 딥러닝
- 많은 경험을 통해 최적의 성능을 보이는 모델을 만드는 것이 중요
모델 저장과 재사용
Python
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
import pandas as pd
df = pd.read_csv('./data/sonar3.csv', header=None)
X = df.iloc[:,0:60]
y = df.iloc[:,60]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=True)
model = Sequential()
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history=model.fit(X_train, y_train, epochs=200, batch_size=10)
score=model.evaluate(X_test, y_test)
model.save('./data/model/my_model.hdf5')
del model
model = load_model('./data/model/my_model.hdf5')
score=model.evaluate(X_test, y_test)
print('Test accuracy:', score[1])
model.save('.hdf5'): model 저장. hdf5 파일 포맷은 크고 복잡한 데이터 저장하는데 이용
from tensorflow.keras.models import load_model: 저장한 모델 불러오는 API
del model: 모델을 불러와 테스트하기 위해 save 전에 만든 모델 삭제
print 찍어보면 정확도가 같다.
k겹 교차 검증
- k겹 교차 검증(k-fold cross validation)
데이터셋을 여러 개로 나누어 하나씩 테스트셋으로 사용하고 나머지를 모두 학습셋으로 사용하는 방법
모든 결과의 평균이 최종 결과
Python
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score
import pandas as pd
df = pd.read_csv('./data/sonar3.csv', header=None)
X = df.iloc[:,0:60]
y = df.iloc[:,60]
k=5
kfold = KFold(n_splits=k, shuffle=True)
acc_score = []
def model_fn():
model = Sequential()
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
return model
for train_index , test_index in kfold.split(X):
X_train , X_test = X.iloc[train_index,:], X.iloc[test_index,:]
y_train , y_test = y.iloc[train_index], y.iloc[test_index]
model = model_fn()
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history=model.fit(X_train, y_train, epochs=200, batch_size=10, verbose=0)
accuracy = model.evaluate(X_test, y_test)[1]
acc_score.append(accuracy)
avg_acc_score = sum(acc_score)/k
print('정확도:', acc_score)
print('정확도 평균:', avg_acc_score)
kFold(n_spilits=k, shuffle=True): k개로 나누기, 샘플이 한쪽에 치우치지 않도록 shuffle
kfold.split(X): kFold의 split 메서드이다.(문자열 나누는 split 아님)
X 즉, 0부터 59까지 특성 데이터를 5개로 나누고 2종류의 index를 반환하는데 각각 train_index와 test_index로 반환한다.
verbose=0: 학습 과정의 출력 생략
Chap 14. 모델 성능 향상시키기
데이터의 확인과 검증셋
- 학습셋을 학습셋과 검증셋으로 나누어 데이터셋을 학습셋, 검증셋, 테스트셋으로 구분
Python
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
import pandas as pd
df = pd.read_csv('./data/wine.csv', header=None)
X = df.iloc[:,0:12]
y = df.iloc[:,12]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True)
model = Sequential()
model.add(Dense(30, input_dim=12, activation='relu'))
model.add(Dense(12, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history=model.fit(X_train, y_train, epochs=50, batch_size=500, validation_split=0.25)
score=model.evaluate(X_test, y_test)
print('Test accuracy:', score[1])입력 속성 12개, 출력 값 1개
은닉층은 3개, 노드는 각각 30, 12, 8개
검증셋을 만들기 위해model.fit()함수에 validation_split 옵션 사용
train_test_split(X, y, test_size = 0.2)에서 전체 데이터의 0.8을 학습셋으로 사용
validation_split=0.25이므로, 0.8의 0.25 즉, 전체 데이터의 0.2가 검증셋으로 사용됨.
모델 업데이트하기
- 에포크(epochs) : 학습을 몇 번 반복할 것인지. 많이 반복한다고 지속적으로 좋아지는거 아님
모델을 저장할 때, 에포크와 정확도를 함께 저장.
Python
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.callbacks import ModelCheckpoint
from sklearn.model_selection import train_test_split
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv('./data/wine.csv', header=None)
X = df.iloc[:,0:12]
y = df.iloc[:,12]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True)
model = Sequential()
model.add(Dense(30, input_dim=12, activation='relu'))
model.add(Dense(12, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
modelpath="./data/model/all/{epoch:02d}-{val_accuracy:.4f}.hdf5"
checkpointer = ModelCheckpoint(filepath=modelpath, verbose=1)
history=model.fit(X_train, y_train, epochs=50, batch_size=500, validation_split=0.25, verbose=0, callbacks=[checkpointer])
score=model.evaluate(X_test, y_test)
print('Test accuracy:', score[1])케라스 API의
ModelCheckpoint()함수를 사용하여 학습 중인 모델 저장
verbose=1옵션을 줘서 진행되는 현황 모니터링 가능
그래프로 과적합 확인하기
-
model.fit()은 기본적으로loss값이 출력되고model.compile()에서metrics=['accuracy']로 주면accuracy값이 함께 출력됨. -
loss: 오차,accuracy: 정확도 -
검증셋 지정시
val_loss,val_accuracy값도 함께 출력됨
Python
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.callbacks import ModelCheckpoint
from sklearn.model_selection import train_test_split
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv('./data/wine.csv', header=None)
X = df.iloc[:,0:12]
y = df.iloc[:,12]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True)
model = Sequential()
model.add(Dense(30, input_dim=12, activation='relu'))
model.add(Dense(12, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history=model.fit(X_train, y_train, epochs=2000, batch_size=500, verbose=0, validation_split=0.25)
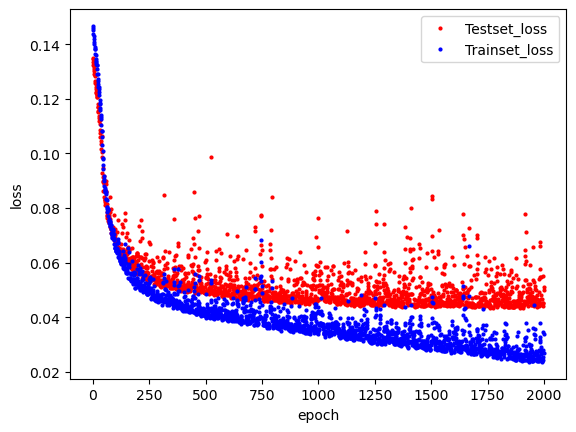
hist_df=pd.DataFrame(history.history)
hist_df
y_vloss=hist_df['val_loss']
y_loss=hist_df['loss']
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, "o", c="red", markersize=2, label='Testset_loss')
plt.plot(x_len, y_loss, "o", c="blue", markersize=2, label='Trainset_loss')
plt.legend(loc='upper right')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
hist_df실행시 출력 값
loss accuracy val_loss val_accuracy 0 0.146690 0.948935 0.135123 1 0.145879 0.949705 0.134455 2 0.145025 0.948935 0.133661 3 0.143699 0.950475 0.132337 4 0.142883 0.950475 0.131549 ... ... ... ... 1995 0.034471 0.989222 0.044063 1996 0.028033 0.992045 0.045314 1997 0.024501 0.993328 0.045275 1998 0.026760 0.993072 0.051263 1999 0.033970 0.990249 0.049976
len(y_loss): y_loss는 한 열이므로 배열(?)의 길이를 반환
※ pandas series 객체는 배열과 유사하다(?)
np.arrange(len(y_loss)): y_loss 길이만큼의 수열 생성 즉, 0부터 len(y_loss)-1까지의 정수로 이루어진 NumPy 배열 반환
plt.plot(): x축 값, y축 값, 데이터 포인트"o": 원. 나머지는 색, 크기, 라벨 보이는 그대로
plt.legend(loc='upper right'): 범례 추가, location : 오른쪽 상단
학습셋에서의 오차와 검증셋에서의 오차 비교
빨간색이 커지는 부분 즉, testset에서의 오차가 커지는 부분은 epochs가 커서 과적합이 발생한 부분이다.
학습의 자동 중단
Python
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
import os
import pandas as pd
df = pd.read_csv('./data/wine.csv', header=None)
X = df.iloc[:,0:12]
y = df.iloc[:,12]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True)
model = Sequential()
model.add(Dense(30, input_dim=12, activation='relu'))
model.add(Dense(12, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=20)
modelpath="./data/model/Ch14-4-bestmodel.hdf5"
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=0, save_best_only=True)
history=model.fit(X_train, y_train, epochs=2000, batch_size=500, validation_split=0.25, verbose=1, callbacks=[early_stopping_callback,checkpointer])
score=model.evaluate(X_test, y_test)
print('Test accuracy:', score[1])
EalyStopping():model.fit()의 결과중monitor의 값이patience값만큼 반복해도 증가하지 않을 때, 학습을 멈추는 함수
ModelCheckpoint()함수를 이용하여modelpath에 저장,val_loss값이 이전 모델의 값보다 작을 때만 저장
위의 두 함수의 반환값은model.fit()메서드의 callbacks 옵션에 추가14.1의 결과
41/41 [==============================] - 1s 21ms/step - loss: 0.1099 - accuracy: 0.9600
Test accuracy: 0.9599999785423279
14.4의 결과
41/41 [==============================] - 0s 4ms/step - loss: 0.0524 - accuracy: 0.9815
Test accuracy: 0.9815384745597839
Chap 15. 실제 데이터로 만들어 보는 모델
데이터 파악하기
Python
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
df = pd.read_csv("./data/house_train.csv")
df
df.dtypes
Id int64 MSSubClass int64 MSZoning object LotFrontage float64 LotArea int64 ... ... MoSold int64 YrSold int64 SaleType object SaleCondition object SalePrice int64 Length: 81, dtype: object
결측치, 카테고리 변수 처리하기
Python
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
df = pd.read_csv("./data/house_train.csv")
df.isnull().sum().sort_values(ascending=False).head(20)
df = pd.get_dummies(df)
df = df.fillna(df.mean())
df
isnull(): 결측치 확인
sum(): 결측치의 합계 출력
sort_values(): 소팅
head(20): 전부 말고 앞의 20개만
get_dummies(): 원-핫 인코딩, LUT 또는 MUX 비스무리한거 -> Chap 12.3
fillna(): 결측치 채우는 함수
dropna(how='any'): 결측치가 하나라도 있으면 해당 속성 제거
dropna(how='all'): 모든 값이 결측치이면 해당 속성 제거
속성별 관련도 추출하기
Python
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
df = pd.read_csv("./data/house_train.csv")
df = pd.get_dummies(df)
df = df.fillna(df.mean())
df_corr=df.corr()
df_corr_sort=df_corr.sort_values('SalePrice', ascending=False)
df_corr_sort['SalePrice'].head(10)
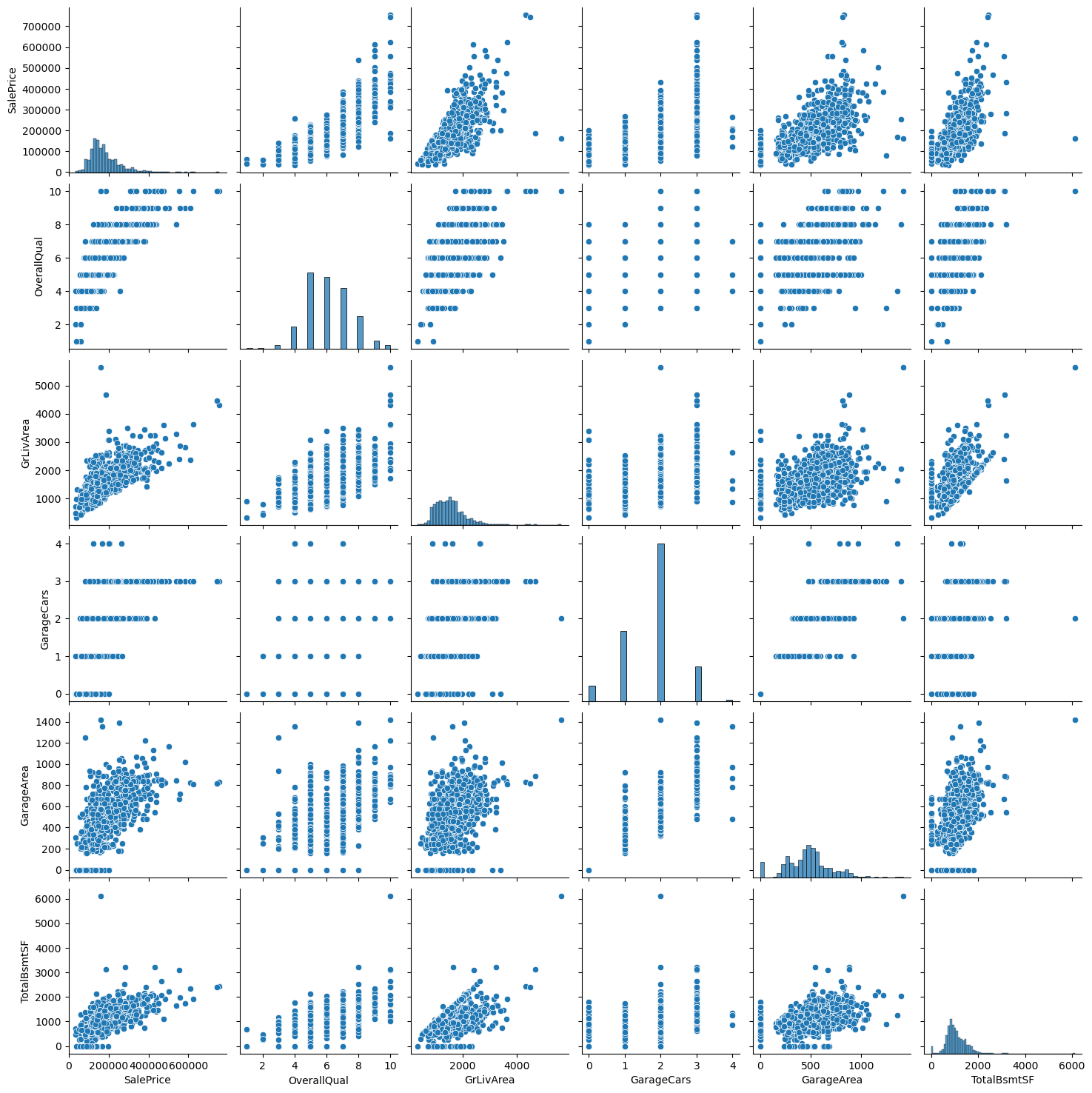
cols=['SalePrice','OverallQual','GrLivArea','GarageCars','GarageArea','TotalBsmtSF']
sns.pairplot(df[cols])
plt.show()
df.corr(): 데이터들간의 상관관계
df.corr().sort_values('SalePrice', ascending=False): SalePrice와 관련도가 큰 것부터 소팅해서 저장
df_corr_sort['SalePrice'].head(10)결과
SalePrice 1.000000 OverallQual 0.790982 GrLivArea 0.708624 GarageCars 0.640409 GarageArea 0.623431 TotalBsmtSF 0.613581 1stFlrSF 0.605852 FullBath 0.560664 BsmtQual_Ex 0.553105 TotRmsAbvGrd 0.533723 Name: SalePrice, dtype: float64
sns.pariplot(df[cols])결과
plt.show()
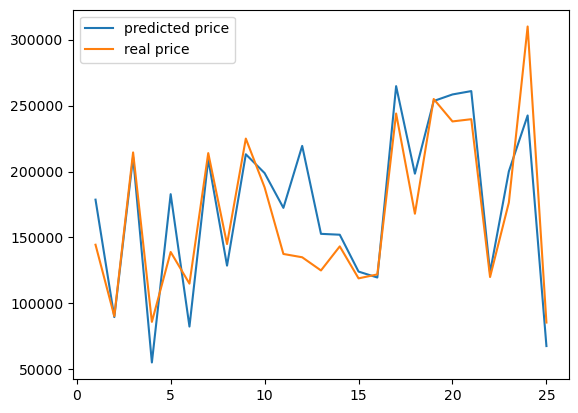
주택 가격 예측 모델
Python
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
df = pd.read_csv("./data/house_train.csv")
df = pd.get_dummies(df)
df = df.fillna(df.mean())
cols_train=['OverallQual','GrLivArea','GarageCars','GarageArea','TotalBsmtSF']
X_train_pre = df[cols_train]
y = df['SalePrice'].values
X_train, X_test, y_train, y_test = train_test_split(X_train_pre, y, test_size=0.2)
model = Sequential()
model.add(Dense(10, input_dim=X_train.shape[1], activation='relu'))
model.add(Dense(30, activation='relu'))
model.add(Dense(40, activation='relu'))
model.add(Dense(1))
# model.summary()
model.compile(optimizer ='adam', loss = 'mean_squared_error')
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=20)
modelpath="./data/model/Ch15-house.hdf5"
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=0, save_best_only=True)
history = model.fit(X_train, y_train, validation_split=0.25, epochs=2000, batch_size=32, callbacks=[early_stopping_callback, checkpointer])
real_prices =[]
pred_prices = []
X_num = []
n_iter = 0
Y_prediction = model.predict(X_test).flatten()
for i in range(25):
real = y_test[i]
prediction = Y_prediction[i]
print("실제가격: {:.2f}, 예상가격: {:.2f}".format(real, prediction))
real_prices.append(real)
pred_prices.append(prediction)
n_iter = n_iter + 1
X_num.append(n_iter)
plt.plot(X_num, pred_prices, label='predicted price')
plt.plot(X_num, real_prices, label='real price')
plt.legend()
plt.show()상관도 그래프에서 상관도가 높은 값들 중 SalePrice를 제외한 나머지 값들의 행을 따로 빼고 해당 데이터의 값들을
X_train_pre에 저장
y: 집 값
train_test_split(X_train_pre, y, test_size=0.2): X_train_pre 데이터의 20%는 테스트셋으로 지정
모델의 층은 3개, 각각 10, 30, 40개 노드 존재, 입력 속성의 개수를.shape[1]로 데이터의 열의 개수로 받음
val_loss값에 따라 학습 종료하고
.fit()에서 검증셋을 0.8의 0.25 즉, 전체의 20%로 지정,EarlyStopping와ModelCheckpoint를callbacks옵션에 넣음25번 반복하며 모델의 정확도 확인
model.predict(X_test).flatten(): 아까 나눈 test 셋의 속성 값을 모델에 주고 결과를 1차원 배열로 만들어Y_prediction에 넣음
real: 테스트 셋의 실제 값
각각의 리스트에 실제 값과 예측값 추가,n_iter로 나중에 그릴 그래프에서 x축 값도 추가
두 데이터를 라벨 붙이고, 범례도 추가
plt.show()