딥러닝 활용하기
Chap 18. 시퀀스 배열로 다루는 순환 신경망(RNN)
-
순환 신경망(Recurrent Nueral Network, RNN) : 입력 데이터의 과거와 나중의 관계를 고려해야 하는 문제를 해결하기 위한 방법
여러 개의 데이터가 순서대로 입력되었을 때 앞서 입력받은 데이터를 잠시 기억하여 스스로 가중치를 줌 -
LSTM(Long Short Term Memory) : 한 층 안에서 반복을 많이 하는 RNN의 특성상 기울기 소실 문제가 더 많이 발생하기 때문에 이를 보완한 방법. 다음 층으로 데이터를 넘길 때, 넘길지 여부를 관리하는 단계 추가
LSTM을 이용한 로이터 뉴스 카테고리 분류하기
Python
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Embedding
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.datasets import reuters
from tensorflow.keras.callbacks import EarlyStopping
import numpy as np
import matplotlib.pyplot as plt
(X_train, y_train), (X_test, y_test) = reuters.load_data(num_words=1000, test_split=0.2)
X_train = sequence.pad_sequences(X_train, maxlen=100)
X_test = sequence.pad_sequences(X_test, maxlen=100)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
model = Sequential()
model.add(Embedding(1000, 100))
model.add(LSTM(100, activation='tanh'))
model.add(Dense(46, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=5)
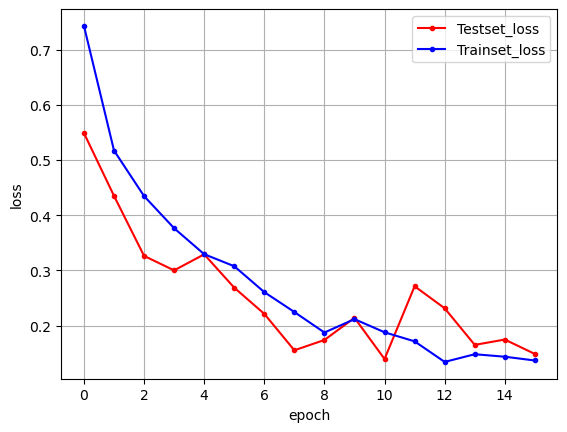
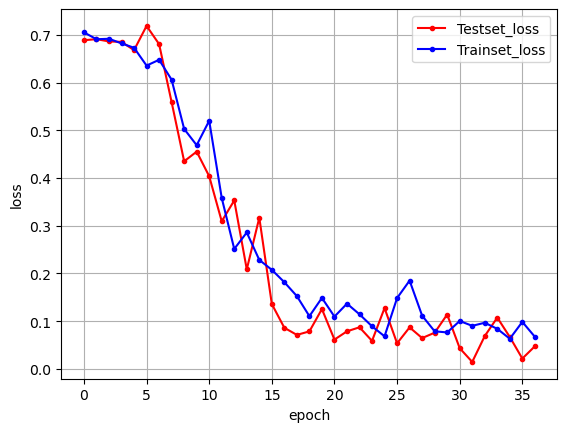
history = model.fit(X_train, y_train, batch_size=20, epochs=200, validation_data=(X_test, y_test), callbacks=[early_stopping_callback])
print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, y_test)[1]))
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
reuters.load_data(num_words=1000, test_split=0.2): 학습용 테이터가 빈도에 따른 숫자로 전처리 되어있으므로, 빈도가 1~1,000에 해당하는 단어만 선택하여 불러옴
sequence.pad_sequences(X_train, maxlen=100): 단어 수를 100개로 패딩
Embedding(1000, 100): 입력되는 단어 =num_words, 출력 단어 = 샘플당 단어 수
LSTM(100, activation='tanh'): (샘플당 단어 수, 기타 옵션). 활성함수는 주로tanh
plt.show()
LSTM과 CNN의 조합을 이용한 영화 리뷰 분류하기
Python
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Activation, Embedding, LSTM, Conv1D, MaxPooling1D
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.callbacks import EarlyStopping
import numpy as np
import matplotlib.pyplot as plt
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=5000)
X_train = sequence.pad_sequences(X_train, maxlen=500)
X_test = sequence.pad_sequences(X_test, maxlen=500)
model = Sequential()
model.add(Embedding(5000, 100))
model.add(Dropout(0.5))
model.add(Conv1D(64, 5, padding='valid', activation='relu',strides=1))
model.add(MaxPooling1D(pool_size=4))
model.add(LSTM(55))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.summary()
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=3)
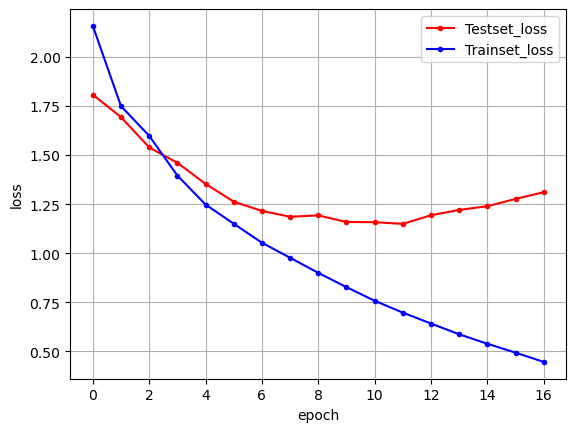
history = model.fit(X_train, y_train, batch_size=40, epochs=100, validation_split=0.25, callbacks=[early_stopping_callback])
print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, y_test)[1]))
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()1 ~ 5,000회 반복 단어 사용
길이는 500으로 패딩
절반 노드 끄고
1차원 Convolution 층 : 64개의 1차원 배열, 출력 5개
pool size : 4
LSTM input : 55
최종 출력 : 1
plt.show()
어텐션을 사용한 신경망
-
어텐션(attention) : 각 셀로부터 계산된 스코어를 이용해 소프트맥스 함수를 사용하여 어텐션 가중치 생성, 해당 가중치는 인풋 값 중 어떤 셀을 중점적으로 볼지 결정
-
문맥 벡터(context vector) : 전체 문장의 뜻이 함축되어 있는 값
Python
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Activation, Embedding, LSTM, Conv1D, MaxPooling1D
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.utils import plot_model
from attention import Attention
import numpy as np
import matplotlib.pyplot as plt
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=5000)
X_train = sequence.pad_sequences(X_train, maxlen=500)
X_test = sequence.pad_sequences(X_test, maxlen=500)
model = Sequential()
model.add(Embedding(5000, 500))
model.add(Dropout(0.5))
model.add(LSTM(64, return_sequences=True))
model.add(Attention())
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=3)
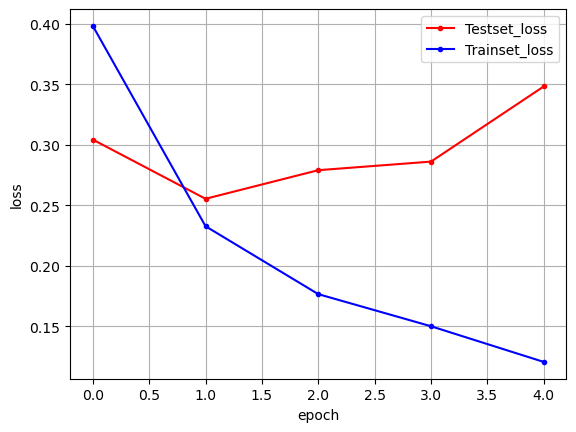
history = model.fit(X_train, y_train, batch_size=40, epochs=100, validation_data=(X_test, y_test), callbacks=[early_stopping_callback])
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()데이터 : 1 ~ 5,000 회 반복한 단어
500자로 패딩
Embedding 층 : input = 5,000 단어, output = 500 단어
LSTM : input = 64 단어
Attention(): 인코더에서 받은 단어 셀들의 스코어를 매기고, 해당 스코어를 소프트맥스 함수로 가중치를 만들어 디코더로 내보냄
plt.show()
Chap 19. GAN, 오토인코더
-
생성적 적대 신경망(Generative Adversarial Networks), GAN : 가상 이미지를 생성하는 알고리즘
-
생성자(Generator) : 가짜를 만들어 내는 파트
-
판별자(Discriminator) : 진위를 가려내는 파트
-
DCGAN(Deep Convolution GAN) : CNN을 GAN에 적용한 알고리즘
-
배치 정규화(Batch Normalization) : 입력 데이터의 평균이 0, 분산이 1이 되도록 재배치하는 것
생성자
- 생성자(generator) : 가상의 이미지를 만들어 내는 공장
랜덤한 픽셀 값으로 채워진 가짜 이미지를 판별자의 판별 결과에 따라 지속적으로 업데이트
generator = Sequential()
genearator.add(Dense(128*7*7, input_dim=100, activation=LeakyReLU(0.2)))
generator.add(BatchNormalization())
generator.add(Reshape((7, 7, 128)))
generator.add(UpSampling2D())
generator.add(Conv2D(64, kernel_size=5, padding='same'))
generator.add(BatchNormalization())
generator.add(Activation(LeakyReLU(0.2)))
generator.add(UpSampling2D())
generator.add(Conv2D(1, kernel_size=5, padding='same', activation='tanh'))MNIST 하나의 크기는 28x28,
UpSampling2D()지나면 2배 커짐 즉, 7x7 이미지가 2 번 지나면, 28x28이 되므로 처음 데이터 크기를 7x7
Reshape((7, 7, 128)):Conv2D()의input_shape의 형태로 reshape 해줌
LeakyReLU(0.2)): 뉴런들이 일찍 소실되는 단점을 보완하기 위해, 0보다 작은 값에서 특정 값(0.2)를 곱하는 함수
판별자
- 판별자(discriminator) : 생성자에서 넘어온 이미지가 가짜인지 진짜인지 판별하는 장치
판별만 할 뿐, 학습을 하는데 쓰이지 않아야 함
discriminator = Sequential()
discriminator.add(Conv2D(64, kernel_size=5, strides=2, input_shape=(28,28,1), padding="same"))
discriminator.add(Activation(LeakyReLU(0.2))
discriminator.add(Dropout(0.3))
discriminator.add(Conv2D(128, kernel_size=5, strieds=2, padding="same"))
discriminator.add(Activation(LeakyReLU(0.2)))
discriminator.add(Dropout(0.3))
discriminator.add(Flatten())
discriminator.add(Dense(1, activation='sigmoid'))
discriminator.compile(loss='binary_crossentropy', optimizer='adam')
discriminator.trainalbe=False
strides: 커널 윈도를 몇 칸씩 이동시킬지 정하는 옵션
드롭아웃이나 풀링과 같은 새로운 필터를 적용한 효과
Flatten(): 출력이 0 또는 1이므로 1차원으로 평활화
activation:sigmoid, 0 또는 1
loss:binary_crossentropy, 0 또는 1
optimizer:adam
생성자는 출력 수를 28로 맞추기 위해 업샘플링을 하였지만, 판별자는 구분만 하면 되기 때문에 필요 없음
discriminator.tranable = False: 학습 기능 off
적대적 신경망 실행하기
ginput = Input(shape=(100,))
dis_output = discriminator(generator(ginput))
gan = Model(ginput, dis_output)
gan.compile(loss='binary_crossentropy', optimizer='adam')생성자 입력을
Input()함수로 생성, 랜덤한 100개의 벡터를 집어넣음
생성자에Input()을 넣은 결과를 판별자의 input으로 넣고
output을 케라스의Model()함수를 이용하여gan이라는 이름의 새로운 모델을 만듬
gan은 이진 로스 함수와 아담 최적화 함수로 컴파일
def gan_train(epoch, batch_size, saving_interval):
(X_train, _), (_, _) = mnist.load_data()
X_train = X_train.reshape(X_train.shpe[0], 28, 28, 1).astype('flaot32')
X_train = (X_train - 127.5) / 127.5MNIST 데이터 불러와서 X_train에 입력값 모두 저장
입력값은 28x28, 1 channel 실수 데이터
0 ~ 255를 127.5로 빼고, 127.5로 나누면 -1 ~ 1로 바뀜 (tanh()쓰는 이유)
true = np.ones((bath_size, 1))
idx = np.random.randint(0, X_train.shape[0], bath_size)
imgs = X_train[idx]
d_loss_real = discriminator.tran_on_batch(imgs, true)
bath_size크기의 행, 1개의 열을 가지는 배열을 생성, 모두 1로 채워짐 → '참(1)'이라는 레이블 값을 가진 배열
np.random.randint(a, b, c): 0부터 X_tran.shpe[0]까지 중에서, 랜덤한 정수를bath_size만큼 반복해서 가지고 옴
discriminator.tran_on_batch(imgs, true):imgs를 입력 값으로,true를 레이블(출력)으로 받아서 한 번 학습을 실시해 모델 업데이트
fake = np.zeros((batch_size, 1))
noise = np.random.normal(0, 1, (batch_size, 100))
gen_imgs = generator.predict(noise)
d_loss_fake = discriminator.tran_on_batch(gen_imgs, fake)'모두 거짓(0)'이라는 레이블 값을 가진 열을
batch_size만큼 생성
0에서 1사이의 랜덤 실수를batch_size개의 행, 100개의 열 만큼 생성
해당noise를 생성자 input에 넣고 결과를gen_imgs로 저장
판별자에gen_imgs를 입력,fake를 출력(레이블)로 학습
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
g_loss = gan.train_on_batch(noise, true)판별자의 오차는 실제 이미지의 오차와 가상 이미지의 오차의 평균
생성자의 오차는 아까 만든
gan모델에서 인풋 값으로 넣은noise를true로 계산
Python
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Input, Dense, Reshape, Flatten, Dropout
from tensorflow.keras.layers import BatchNormalization, Activation, LeakyReLU, UpSampling2D, Conv2D
from tensorflow.keras.models import Sequential, Model
import numpy as np
import matplotlib.pyplot as plt
import os
if not os.path.exists("./data/gan_images"):
os.makedirs("./data/gan_images")
generator = Sequential()
generator.add(Dense(128*7*7, input_dim=100, activation=LeakyReLU(0.2)))
generator.add(BatchNormalization())
generator.add(Reshape((7, 7, 128)))
generator.add(UpSampling2D())
generator.add(Conv2D(64, kernel_size=5, padding='same'))
generator.add(BatchNormalization())
generator.add(Activation(LeakyReLU(0.2)))
generator.add(UpSampling2D())
generator.add(Conv2D(1, kernel_size=5, padding='same', activation='tanh'))
discriminator = Sequential()
discriminator.add(Conv2D(64, kernel_size=5, strides=2, input_shape=(28,28,1), padding="same"))
discriminator.add(Activation(LeakyReLU(0.2)))
discriminator.add(Dropout(0.3))
discriminator.add(Conv2D(128, kernel_size=5, strides=2, padding="same"))
discriminator.add(Activation(LeakyReLU(0.2)))
discriminator.add(Dropout(0.3))
discriminator.add(Flatten())
discriminator.add(Dense(1, activation='sigmoid'))
discriminator.compile(loss='binary_crossentropy', optimizer='adam')
discriminator.trainable = False
ginput = Input(shape=(100,))
dis_output = discriminator(generator(ginput))
gan = Model(ginput, dis_output)
gan.compile(loss='binary_crossentropy', optimizer='adam')
gan.summary()
def gan_train(epoch, batch_size, saving_interval):
(X_train, _), (_, _) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32')
X_train = (X_train - 127.5) / 127.5
true = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for i in range(epoch):
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
d_loss_real = discriminator.train_on_batch(imgs, true)
noise = np.random.normal(0, 1, (batch_size, 100))
gen_imgs = generator.predict(noise)
d_loss_fake = discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
g_loss = gan.train_on_batch(noise, true)
print('epoch:%d' % i, ' d_loss:%.4f' % d_loss, ' g_loss:%.4f' % g_loss)
if i % saving_interval == 0:
noise = np.random.normal(0, 1, (25, 100))
gen_imgs = generator.predict(noise)
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(5, 5)
count = 0
for j in range(5):
for k in range(5):
axs[j, k].imshow(gen_imgs[count, :, :, 0], cmap='gray')
axs[j, k].axis('off')
count += 1
fig.savefig("./data/gan_images/gan_mnist_%d.png" % i)
gan_train(2001, 32, 200)
fig

이미지의 특징을 추출하는 오토인코더
-
오토인코더(Auto-Encoder, AE) : 입력 데이터의 특징을 효율적으로 담아낸 이미지 생성
영상 의학 분야 등 아직 데이터 수가 충분하지 않은 분야에서 사용 -
원리 : 입력 데이터를 적은 수의 노드의 은닉층으로 넣어 차원을 줄인다.
이후 소실된 데이터를 복원하는 학습을 시작, 이 과정을 통해 입력 데이터의 특징을 효율적으로 응축한 새로운 출력이 나옴
Python
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Input, Dense, Conv2D, MaxPooling2D, UpSampling2D, Flatten, Reshape
import matplotlib.pyplot as plt
import numpy as np
(X_train, _), (X_test, _) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32') / 255
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1).astype('float32') / 255
autoencoder = Sequential()
autoencoder.add(Conv2D(16, kernel_size=3, padding='same', input_shape=(28,28,1), activation='relu'))
autoencoder.add(MaxPooling2D(pool_size=2, padding='same'))
autoencoder.add(Conv2D(8, kernel_size=3, activation='relu', padding='same'))
autoencoder.add(MaxPooling2D(pool_size=2, padding='same'))
autoencoder.add(Conv2D(8, kernel_size=3, strides=2, padding='same', activation='relu'))
autoencoder.add(Conv2D(8, kernel_size=3, padding='same', activation='relu'))
autoencoder.add(UpSampling2D())
autoencoder.add(Conv2D(8, kernel_size=3, padding='same', activation='relu'))
autoencoder.add(UpSampling2D())
autoencoder.add(Conv2D(16, kernel_size=3, activation='relu'))
autoencoder.add(UpSampling2D())
autoencoder.add(Conv2D(1, kernel_size=3, padding='same', activation='sigmoid'))
# autoencoder.summary()
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
autoencoder.fit(X_train, X_train, epochs=50, batch_size=128, validation_data=(X_test, X_test))
random_test = np.random.randint(X_test.shape[0], size=5)
ae_imgs = autoencoder.predict(X_test)
plt.figure(figsize=(7, 2))
for i, image_idx in enumerate(random_test):
ax = plt.subplot(2, 7, i + 1)
plt.imshow(X_test[image_idx].reshape(28, 28))
ax.axis('off')
ax = plt.subplot(2, 7, 7 + i +1)
plt.imshow(ae_imgs[image_idx].reshape(28, 28))
ax.axis('off')
plt.show()인코더 :
Conv2D()와MaxPooling2D()를 통해 차원 축소
디코더 :Conv2D()와UpSampling2D()를 통해 크기를 늘림첫 입력 : 28x28 크기
이후MaxPooling2D()2번 지나면서 절반씩 줄어들고
UpSampling2D()3번 지나는데 디코더 중간Conv2D()에 패딩 옵션이 없으므로 1번 절반으로 줄어들고 3번 2배씩 증가하므로, 크기는 동일해짐_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_8 (Conv2D) (None, 28, 28, 16) 160
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 14, 14, 16) 0
_________________________________________________________________
conv2d_9 (Conv2D) (None, 14, 14, 8) 1160
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 7, 7, 8) 0
_________________________________________________________________
conv2d_10 (Conv2D) (None, 4, 4, 8) 584
_________________________________________________________________
conv2d_11 (Conv2D) (None, 4, 4, 8) 584
_________________________________________________________________
up_sampling2d_4 (UpSampling2 (None, 8, 8, 8) 0
_________________________________________________________________
conv2d_12 (Conv2D) (None, 8, 8, 8) 584
_________________________________________________________________
up_sampling2d_5 (UpSampling2 (None, 16, 16, 8) 0
_________________________________________________________________
conv2d_13 (Conv2D) (None, 14, 14, 16) 1168
_________________________________________________________________
up_sampling2d_6 (UpSampling2 (None, 28, 28, 16) 0
_________________________________________________________________
conv2d_14 (Conv2D) (None, 28, 28, 1) 145
=================================================================
Total params: 4,385
Trainable params: 4,385
Non-trainable params: 0
_________________________________________________________________
plt.figure(figsize=(7, 2)): 이미지 크기 지정
plt.show()

Chap 20. 전이 학습을 통해 딥러닝의 성능 극대화하기
- 전이학습(transfer learning) : 기존의 이미지에서 학습한 정보를 가져와 프로젝트에 활용하는 것
미리 학습한 가중치 값을 가져와 프로젝트에 사용
소규모 데이터셋으로 만드는 학습 모델
- 지도 학습(supervised learning) : CNN, 분류, 예측 등
- 비지도 학습(unsupervised learning) : GAN, 오토인코더 등
MRI 뇌 사진을 보고 치매, 일반인 구분하기
- 데이터 구조
총 280장; 일반인 140, 치매 환자 140장
160장은 train, 120장은 test
ad : 치매, normal : 일반인
train_datagen = ImageDataGenerator(rescale=1./255,
horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.1,
rotation_range=5,
shear_range=0.7,
zoom_range=1.2,
vertical_flip=True,
fill_mode='nearest')
rescale: 이미지의 크기가 0~255 를 1/255를 곱해 0~1의 값으로 변환 = 정규화
horizontal_flip,vertical_flip: 수평 또는 수직으로 뒤집음
zoom_range: 해당 범위 내에서 축소 또는 확대
width_shift_range,height_shift_range: 정해진 범위 안에서 그림을 수평 또는 수직으로 랜덤하게 평행 이동
rotation_range: 정해진 각도만큼 이미지 회전
shear_range: 좌표 하나릉 고정시키고 다른 몇 개의 좌표를 이동시키는 변환 즉, 기울임
fill_mode: 빈 공간을 채우는 방법nearest: 가장 비슷한 색
- 데이터 부풀리기는 학습셋에만 적용, 테스트셋은 실제 정보를 그대로 유지하는게 과적합의 위험을 줄임
Python
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation, Dropout, Flatten, Conv2D, MaxPooling2D
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras import optimizers
import numpy as np
import matplotlib.pyplot as plt
train_datagen = ImageDataGenerator(rescale=1./255,
horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.1,
#rotation_range=5, # 정해진 각도만큼 회전시킵니다.
#shear_range=0.7, # 좌표 하나를 고정시키고 나머지를 이동시킵니다.
#zoom_range=1.2, # 확대 또는 축소시킵니다.
#vertical_flip=True, # 수직 대칭 이미지를 만듭니다.
#fill_mode='nearest' # 빈 공간을 채우는 방법입니다. nearest 옵션은 가장 비슷한 색으로 채우게 됩니다.
)
train_generator = train_datagen.flow_from_directory(
'./data/train',
target_size=(150, 150),
batch_size=5,
class_mode='binary')
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
'./data/test',
target_size=(150, 150),
batch_size=5,
class_mode='binary')
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(150,150,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.summary()
model.compile(loss='binary_crossentropy', optimizer=optimizers.Adam(learning_rate=0.0002), metrics=['accuracy'])
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=5)
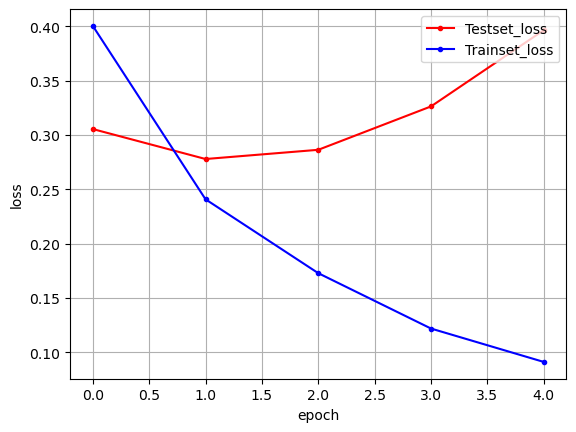
history = model.fit(
train_generator,
epochs=100,
validation_data=test_generator,
validation_steps=10,
callbacks=[early_stopping_callback])
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
horizontal_flip=True: 수평 대칭 이미지를 50% 확률로 만들어 추가
width_shift_range=0.1: 전체 크기의 15% 범위에서 좌우로 이동
height_shift_range=0.1: 전체 크기의 15% 범위에서 위, 아래로 이동
test_datagen = ImageDataGenerator(rescale=1./255): test data는 저런 변형 안함
optimizer=optimizers.Adam(learning_rate=0.0002): adam을 쓰지만 학습률 지정
plt.show()
전이 학습으로 모델 성능 극대화하기
- 전이학습 과정
이미지넷 등 방대한 데이터로 같은 동작(형태를 구분하는)을 학습시킨 모델을 몇 없는 내 데이터에 적용
Python
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import Input, models, layers, optimizers, metrics
from tensorflow.keras.layers import Dense, Flatten, Activation, Dropout
from tensorflow.keras.applications import VGG16
from tensorflow.keras.callbacks import EarlyStopping
import numpy as np
import matplotlib.pyplot as plt
train_datagen = ImageDataGenerator(rescale=1./255, # 주어진 이미지의 크기를 설정합니다.
horizontal_flip=True, # 수평 대칭 이미지를 50% 확률로 만들어 추가합니다.
width_shift_range=0.1, # 전체 크기의 15% 범위에서 좌우로 이동합니다.
height_shift_range=0.1, # 마찬가지로 위, 아래로 이동합니다.
#rotation_range=5, # 정해진 각도만큼 회전시킵니다.
#shear_range=0.7, # 좌표 하나를 고정시키고 나머지를 이동시킵니다.
#zoom_range=1.2, # 확대 또는 축소시킵니다.
#vertical_flip=True, # 수직 대칭 이미지를 만듭니다.
#fill_mode='nearest' # 빈 공간을 채우는 방법입니다. nearest 옵션은 가장 비슷한 색으로 채우게 됩니다.
)
train_generator = train_datagen.flow_from_directory(
'./data/train',
target_size=(150, 150),
batch_size=5,
class_mode='binary')
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
'./data/test',
target_size=(150, 150),
batch_size=5,
class_mode='binary')
transfer_model = VGG16(weights='imagenet', include_top=False, input_shape=(150, 150, 3))
transfer_model.trainable = False
transfer_model.summary()
finetune_model = models.Sequential()
finetune_model.add(transfer_model)
finetune_model.add(Flatten())
finetune_model.add(Dense(64))
finetune_model.add(Activation('relu'))
finetune_model.add(Dropout(0.5))
finetune_model.add(Dense(1))
finetune_model.add(Activation('sigmoid'))
finetune_model.summary()
finetune_model.compile(loss='binary_crossentropy', optimizer=optimizers.Adam(learning_rate=0.0002), metrics=['accuracy'])
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=5)
history = finetune_model.fit(
train_generator,
epochs=20,
validation_data=test_generator,
validation_steps=10,
callbacks=[early_stopping_callback])
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
VCG16(): 옥스포드 대학 연구 팀이 개발한 이미지 인식 모델을 keras로 호출
include_top: 전체 모델의 마지막 층. 로컬 네트워크로 연결할 것이므로False
model.trainable = False: 해당 모델을 학습 시킬 것은 아님Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 150, 150, 3)] 0block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 0
Non-trainable params: 14,714,688
_________________________________________________________________
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Functional) (None, 4, 4, 512) 14714688flatten_1 (Flatten) (None, 8192) 0
dense_2 (Dense) (None, 64) 524352
activation_5 (Activation) (None, 64) 0
dropout_1 (Dropout) (None, 64) 0
dense_3 (Dense) (None, 1) 65
activation_6 (Activation) (None, 1) 0
=================================================================
Total params: 15,239,105
Trainable params: 524,417
Non-trainable params: 14,714,688
_________________________________________________________________
plt.show()