
본 포스팅은 elice의 2021 NIPA AI 온라인 교육을 듣고 개인 공부를 위해 정리한 것입니다.
2. 데이터 핸들링을 위한 라이브러리 NumPy
1) NumPy란?
NumPy는 Nemerical Python, 즉 수치적 파이썬을 의미한다
Python에서 대규모 다차원 배열을 다룰 수 있게 도와주는 라이브러리이다.
대규모는 많은, 다차원은 2차원 이상, 배열은 데이터들이 나열되어있는 것을 뜻한다.
참고🎈 파이썬에는 Pandas, NumPy, Matplotlib 등의 라이브러리가 있다.
그렇다면 왜 대규모 다차원 배열을 알아야할까?
👉 데이터의 대부분은 숫자의 배열로 볼 수 있기 때문이다!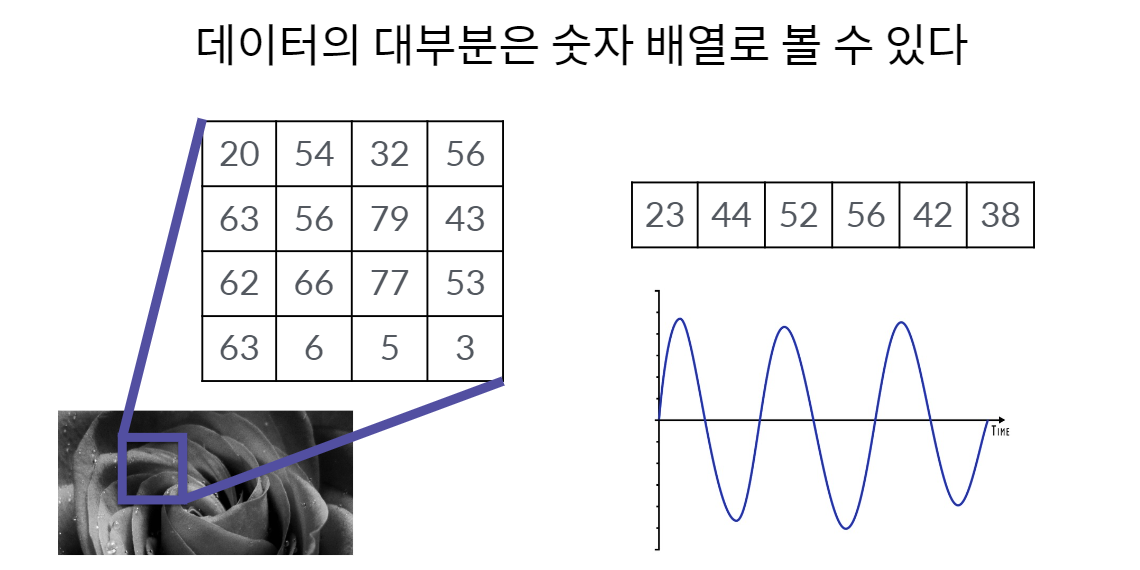
이미지도 사운드 데이터도 숫자 배열로 나타낼 수 있다.
많은 데이터들을 숫자의 배열로 보고 이를 처리하기 위해 NumPy를 사용하는 것!!
NumPy의 특징
반복문 없이 배열 처리 가능
파이썬 리스트에 비해 빠른 연산을 지원하고 메모리를 효율적으로 사용
✨ 리스트와 다른점
- list 배열 생성 및 출력 형태 확인
list_arr = list(range(5))
print(list_arr) # [0, 1, 2, 3, 4] → 콤마(,)로 구분
print(type(list_arr)) # <class 'list> 자료형이 리스트!- NumPy 배열 생성 및 출력 형태 확인
NumPy는 라이브러리 이기 때문에 import 키워드를 이용하여 불러와야 한다.
import numpy as np: numpy 모듈 불러와서 'np'별칭 부여
ndarray: n차원의 배열(n-dimensional array)
import numpy as np
np_arr = np.array(range(5))
print(np_arr) # [0 1 2 3 4] → 공백으로 구분
print(type(np_arr)) # <class 'numpy.ndarray'>✨ 콤마로 구분된 것은 1차원 리스트! 공백으로 구분된 것은 n차원 배열!
실습✍ 배열 만들기
0부터 4까지 연속적인 숫자가 들어있는 배열을 만들어 array라는 배열에 저장해봅시다!
import numpy as np
array = np.array(range(5))
print(array)
>>> [0 1 2 3 4]2) 배열의 기초
배열의 데이터 타입 dtype
파이썬 리스트와 달리 같은 데이터 타입만 저장 가능!
리스트 : [1, 1,4, True, "S"] ⇒ 여러 데이터 O.K🙆♀️🙆♂️
넘파이 : [1 1.4 True "S"] ⇒ Nope!🙅♀️🙅♂️ 단일 데이터만 가능!!
astype()다른 데이터 타입으로 바꿔준다astype(int)는 정수형으로 전환!
arr = np.array([0, 1, 2, 3, 4], dtype = float) # float는 실수형
print(arr) # [0. 1. 2. 3. 4.] # float형으로 데이터 타입을 지정하였으므로 정수 부분 뒤에 .이 나타남
print(arr.dtype) # 'float64'
print(arr.astype(int)) # [0 1 2 3 4] dtype 종류
| dtype | 설명 | 예시 | 다양한 표현 |
|---|---|---|---|
| int | 정수형 타입 | 1, 2, 3 | i, int_, int32, int 64, i8 |
| float | 실수형 타입 | 0.2, 1.4 | f, float_, float32, float64, f8 |
| str | 문자열 타입 | "S", 's' | str, U, U32 |
| bool | 부울 타입 | True, False | ?, bool_ |
- int_ 를 가장 많이 쓴다. int64 = i8
- int32, int64 등 뒤의 숫자는 용량을 뜻한다. 32비트보다 64비트가 더 크겠죠😘
- float_ = float64 = f8
- str의 경우 유니코드를 뜻하는 U로 나타내기도 한다
- bool은 참과 거짓을 판단,
?를 사용하기도 한다.
ndarray 배열의 속성
☝ ndarray 의 차원 관련 속성 : ndim & shape
ndim : n + dimension, n차원
shape : 모양에 대한 함수, (row, column) , 행이 하나만 존재 할 경우 (데이터 갯수, )
# 1차원배열.py
list = [0, 1, 2, 3]
arr = np.array(list)
print(arr.ndim) # 1 → 1차원
print(arr.shape) # (4, ) → 4개의 값이 한 행에 존재# 2차원배열.py
list = [[0, 1, 2], [3, 4, 5]]
arr = np.array(list)
print(arr.ndim) # 2 → 2개의 행이니까 2차원
print(arr.shape) # (2, 3) → 2개의 행이 3개의 열로 존재✌ ndarray의 크기 속성과 shape 조절
arr.size와 len(arr)의 개념은 다르다.
size는 배열 안에 들어가는 요소의 갯수 len은 행의 갯수(단, 1차원의 경우 요소의 갯수 반환)
arr = np.array([0, 1, 2, 3, 4, 5])
print("arr.shape: {}".format(arr.shape)) # arr.shape: (6, )
print("배열 요소의 수: {}".format(arr.size)) # 배열 요소의 수: 6
print("배열의 길이: {}".format(len(arr)) # 배열의 길이 : 6
arr.shape = 3, 2 # arr.shape를 (3, 2)로 바꿈
print("arr.shape: {}".format(arr.shape)) # arr.shape: (3, 2)
print("배열 요소의 수: {}".format(arr.size)) # 배열 요소의 수: 6
print("배열의 길이: {}".format(len(arr)) # 배열의 길이 : 3실습✍ 배열의 기초(1)
import numpy as np
print("1차원 array")
array = np.array(range(10))
print(array)
# 1. array의 자료형을 출력해보세요.
print(type(array))
# 2. array의 차원을 출력해보세요.
print(array.ndim)
# 3. array의 모양을 출력해보세요.
print(array.shape)
# 4. array의 크기를 출력해보세요.
print(array.size)
# 5. array의 dtype(data type)을 출력해보세요.
print(array.dtype)
# 6. array의 인덱스 5의 요소를 출력해보세요.
print(array[5])
# 7. array의 인덱스 3의 요소부터 인덱스 5 요소까지 출력해보세요.
print(array[3:6])
💎 속성에 속하는 ndim, shape, size, dtype은 .과 함께 써준다
실습✍ 배열의 기초(2)
import numpy as np
print("2차원 array")
#1부터 15까지 들어있는 (3,5)짜리 배열을 만듭니다.
matrix = np.array(range(1,16))
matrix.shape = 3,5
print(matrix)
# 1. matrix의 자료형을 출력해보세요.
print(type(matrix))
# 2. matrix의 차원을 출력해보세요.
print(matrix.ndim)
# 3. matrix의 모양을 출력해보세요.
print(matrix.shape)
# 4. matrix의 크기를 출력해보세요.
print(matrix.size)
# 5. matrix의 dtype(data type)을 출력해보세요.
print(matrix.dtype)
# 6. matrix의 dtype을 str로 변경하여 출력해보세요.
print(matrix.astype(str)) # 'str'도 가능
# 7. matrix의 (2,3) 인덱스의 요소를 출력해보세요.
print(matrix[2,3])
# 8. matrix의 행은 인덱스 0부터 인덱스 1까지, 열은 인덱스 1부터 인덱스 3까지 출력해보세요.
print(matrix[0:2,1:4])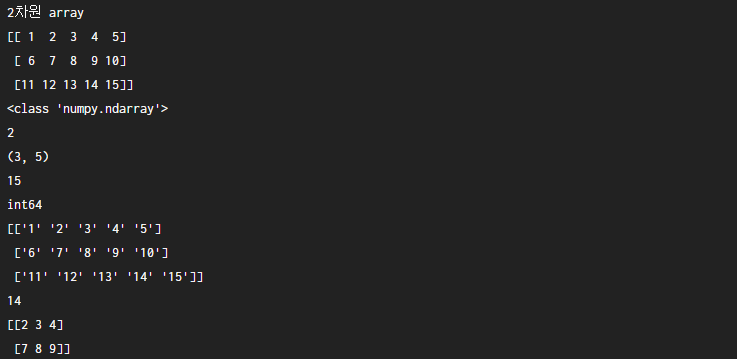
💎 인덱스(index)는 0부터 시작한다는 것 명심하기!
3) Indexing & Slicing
데이터를 찾아내는 것을 인덱싱, 데이터를 잘라내는 것을 슬라이싱이라고 한다.
indexing
인덱스로 값을 찾아냄
numpy 모듈의 arange 함수(
np.arange(start, stop, step, dtype))는 반열린구간 [start, stop) 에서 step의 크기만큼 일정하게 떨어져 있는 숫자들을 array 형태로 반환해 주는 함수다.
stop 매개변수의 값은 반드시 전달되어야 하지만 start는 step은 꼭 전달되지 않아도 된다. start값이 전달되지 않았다면 0을 기본값으로 가지며, step값이 전달되지 않았다면 1을 기본값으로 갖게 된다.
dtype의 경우 결과로 반환되는 array의 type을 지정할 때 사용한다. dtype값이 주어지지 않는 경우 전달된 다른 매개 변수로부터 type을 추론하게 된다.
출처: https://codepractice.tistory.com/88 [코딩 연습]
# 1차원배열.py
x = np.arange(7)
print(x) # [0 1 2 3 4 5 6]
pritn(x[3]) # 3
print(x[7]) # IndexError : index 7 is out of bounds
x[0] = 10 # 데이터 변경하기
print(x) # [10 1 2 3 4 5 6]# 2차원배열.py
x = np.arange(1, 13, 1) #
x.shape = 3, 4
print(x)
# [[1 2 3 4] [5 6 7 8] [9 10 11 12]]
print(x[2, 3]) # 12slicing
인덱스의 값으로 배열의 일부분을 가져옴
파이썬의 list와 비슷하게 동작한다.
# 1차원배열.py
x = np.arange(7)
print(x) # [0 1 2 3 4 5 6]
pritn(x[1:4]) # [1 2 3]
print(x[1: ]) # [1 2 3 4 5 6]
print(x[ :4]) # [0 1 2 3]
print(x[::2]) # [0 2 4 6]# 2차원배열.py
x = np.arange(1, 13, 1) #
x.shape = 3, 4
print(x)
# [[1 2 3 4] [5 6 7 8] [9 10 11 12]]
pritn(x[1:2, :2:3]) # [[5]]
print(x[1:, :2]) # [[5 6] [9 10]]Boolean indexing
배열의 각 요소의 선택 여부를 Boolean mask를 이용하여 지정하는 방식
❔ Boolean mask : True/False로 구성된 mask array
- 조건에 맞는 데이터를 가져온다
- True인지 False인지 알려준다.
- True 해당하는 요소를 조회 할 수 있다.
x = np.arange(7)
print(x) # [0 1 2 3 4 5 6]
print(x < 3) # [True True True False False False False]
print(x > 7) # [False False False False False False False]
print(x[x < 3]) # [0 1 2]
print(x[x % 2 == 0] # [0 2 4 6]Fancy indexing
배열의 각 요소 선택을 Index 배열을 전달하여 지정하는 방식
즉, 찾고싶은 자리(=인덱스)에 어떤 값이 있는지?
# 인덱스로 찾기
x = np.arange(7)
print(x) # [0 1 2 3 4 5 6]
print(x[[1, 3, 5]]) # 인덱스 번호 [1, 3, 5] 자리에 뭐가 있는지 알려줌 → [1, 3, 5]# 행으로 찾기
x = np.arange(1, 13, 1).reshape(3, 4)
print(x)
# [[1 2 3 4] [5 6 7 8] [9 10 11 12]]
print(x[[0, 2]]) # 0번째 행, 2번째 행 → [[1 2 3 4] [9 10 11 12]]👉 원하는 요소를 지정하기 위해 Indexing과 Slicing을 적절히 조합하여 사용 가능!
x = np.arange(1, 13, 1).reshape(3, 4)
print(x)
# [[1 2 3 4] [5 6 7 8] [9 10 11 12]]
print(x[1:2, 2]) # [7]
print(x[[0,2], 2]) # [ 3 11]
print(x[[0,2], :2]) # [[ 1 2] [ 9 10]]실습✍ Indexing & Slicing
import numpy as np
matrix = np.arange(1, 13, 1).reshape(3, 4)
print(matrix)
# 1. Indexing을 통해 값 2를 출력해보세요.
answer1 = matrix[0,1]
# 2. Slicing을 통해 매트릭스 일부인 9, 10을 가져와 출력해보세요.
answer2 = matrix[2, :2] # matrix[2:, :2] → [[9 10]]
# 3. Boolean indexing을 통해 5보다 작은 수를 찾아 출력해보세요.
answer3 = matrix[matrix < 5]
# 4. Fancy indexing을 통해 두 번째 행만 추출하여 출력해보세요.
answer4 = matrix[1] # matrix[[1]] → [[5 6 7 8]]
# 위에서 구한 정답을 출력해봅시다.
print(answer1)
print(answer2)
print(answer3)
print(answer4)
