
본 포스팅은 elice의 2021 NIPA AI 온라인 교육을 듣고 개인 공부를 위해 정리한 것입니다.
4. 데이터 조작 및 분석을 위한 Pandas 심화
1) 데이터프레임 정렬하기
데이터프레임은 함수를 이용해서 정렬할 수 있다! 인덱스 값을 기준으로 정렬할 수 있고 컬럼 값을 기준으로 정렬도 가능하다.
Index 값 기준으로 정렬하기
.sort_index() 라는 함수를 이용하는데 이 때, 방향(행 or 열)과 오름차순 or 내림차순을 정한다.
- axis = 0 : 행 인덱스 기준 정렬
axis = 1 : 열 인덱스(→column) 기준 정렬 - ascending = True : 오름차순 , Default 는 오름차순!
ascending = False : 내림차순
- 행 인덱스 기준 정렬, Default 오름차순
df = df.sort_index(axis = 0)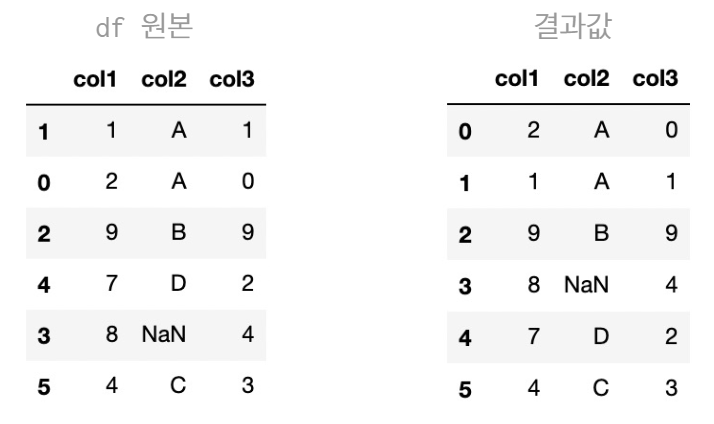
- 열 인덱스 기준 내림차순 정렬
- axis = 1 : 열 인덱스(→column) 기준 정렬
df.sort_index(axis = 1, ascending = False) # 열 인덱스 기준 내림차순 정렬, col3 - col2 - col1 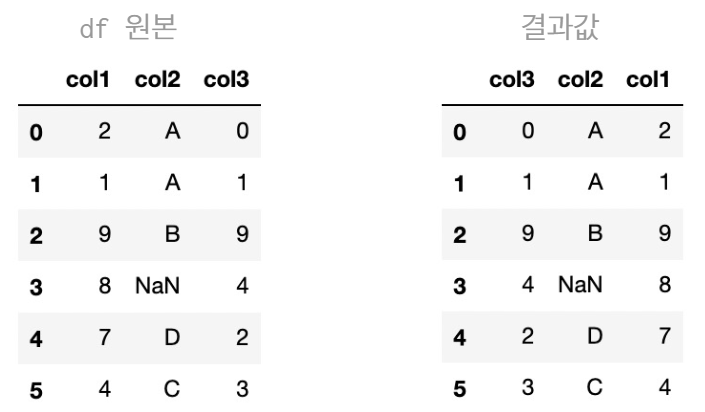
Column 값 기준으로 정렬하기
.sort_values('컬럼 이름', 오름차순/내림차순) 함수 사용, Default는 오름차순
- col1 컬럼 기준 오름차순 정렬
df.sort_values('col1', ascending = True)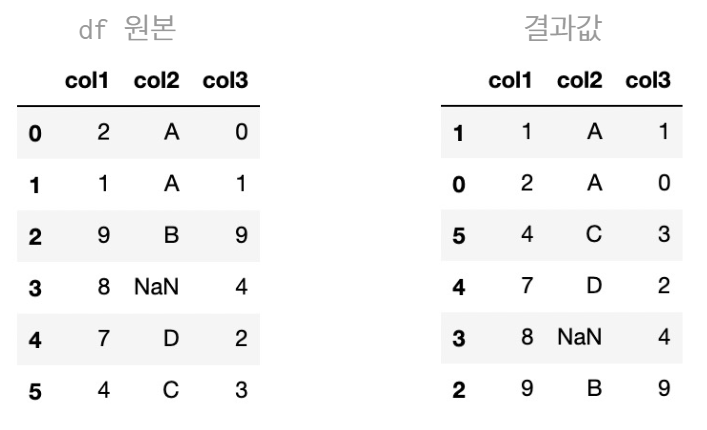
- col1 컬럼 기준 내림차순 정렬
df.sort_values('col1', ascending = False)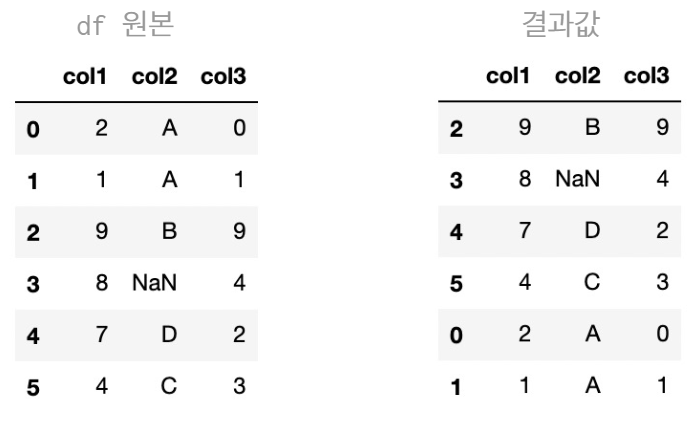
컬럼 값 기준으로 정렬을 할 때는 여러 개의 컬럼을 한번에 정렬할 수도 있다😊
- col2 컬럼 기준 오름차순 정렬 후, col1 컬럼 기준 내림차순 정렬
df.sort_values(['col2','col1'], ascending = [True, False])
# col2는 ascending = True, col1은 ascending = False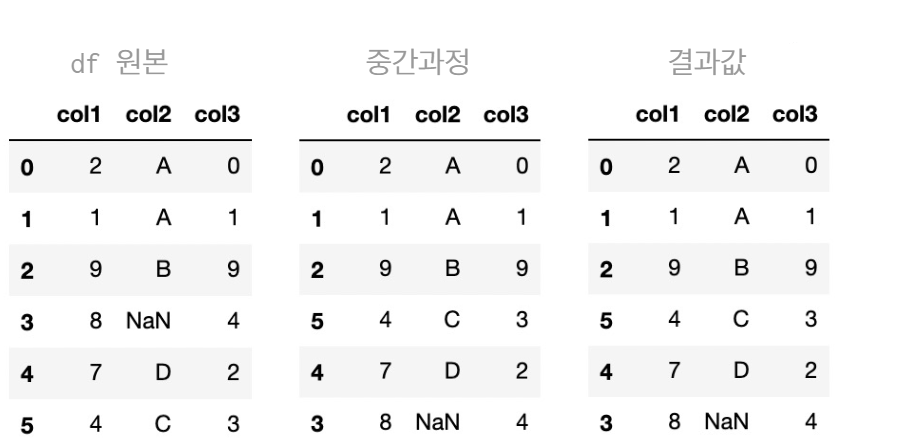
실습✍ 데이터프레임 정렬하기
- 데이터 프레임을 col1을 기준으로 오름차순 정렬한 결과를 sorted_df1에 저장하고 출력해주세요.
- 데이터 프레임을 col2를 기준으로 내림차순 정렬한 결과를 sorted_df2에 저장하고 출력해주세요.
- 데이터 프레임을 col2를 기준으로 오름차순 정렬한 뒤, col1을 기준으로 내림차순 정렬한 결과를 출력해봅시다. 즉, 2개의 정렬 기준을 두어야 합니다. 정렬한 결과를 sorted_df3에 저장하고 출력해주세요.
- 주어진 DataFrame
import numpy as np
import pandas as pd
print("DataFrame: ")
df = pd.DataFrame({
'col1' : [2, 1, 9, 8, 7, 4],
'col2' : ['A', 'A', 'B', np.nan, 'D', 'C'],
'col3': [0, 1, 9, 4, 2, 3],
})
print(df, "\n")DataFrame:
col1 col2 col3
0 2 A 0
1 1 A 1
2 9 B 9
3 8 NaN 4
4 7 D 2
5 4 C 3 - 답안 작성하기
# 1. col1을 기준으로 오름차순으로 정렬하기.
sorted_df1 = df.sort_values("col1", ascending = True)
print(sorted_df1, "\n")
# 2. col2를 기준으로 내림차순으로 정렬하기.
sorted_df2 = df.sort_values("col2", ascending = False)
print(sorted_df2, "\n")
# 3. col2를 기준으로 오름차순으로, col1를 기준으로 내림차순으로 정렬하기.
sorted_df3 = df.sort_values(["col2", "col1"], ascending = [True, False])
print(sorted_df3, "\n")- 결과
1. col1을 기준으로 오름차순으로 정렬하기.
col1 col2 col3
1 1 A 1
0 2 A 0
5 4 C 3
4 7 D 2
3 8 NaN 4
2 9 B 9
2. col2를 기준으로 내림차순으로 정렬하기.
col1 col2 col3
4 7 D 2
5 4 C 3
2 9 B 9
0 2 A 0
1 1 A 1
3 8 NaN 4
3. col2를 기준으로 오름차순으로, col1를 기준으로 내림차순으로 정렬하기.
col1 col2 col3
0 2 A 0
1 1 A 1
2 9 B 9
5 4 C 3
4 7 D 2
3 8 NaN 4 2) 데이터프레임 분석용 함수
복잡한 데이터를 처리하기 위해 함수로 데이터를 연산할 수 있다. 데이터프레임을 분석하는 함수는 여러가지 있는데 이번 시간에는 집계함수(count, max, min, sum, mean 등)를 알아보도록 하자
집계함수 - Count
count 메서드를 활용하여 데이터 개수 확인 가능 (Default: 열 기준, NaN값 제외)
axis = 0 : 열 기준, axis = 1 : 행 기준
💎 이건 또 데이터프레임 정렬할 때랑 다르다.
df.sort_index(axis=0)에서 axis = 0은 행 인덱스 기준으로 정렬하는 거였는데 주의할 것!
개인적으로 쉽게 생각하기위해서 axis = 0 은 세로, axis = 1 은 가로😀
import numpy as np
import pandas as pd
data = {
"korean" : [50, 60, 70],
"math" : [10, np.nan, 40]
}
df = pd.DataFrame(data, index = ["a","b","c"])
df.count(axis = 0) # 열 기준
df.count(axis = 1) # 행 기준
집계함수 - max, min
max, min 메서드 활용하여 최대, 최소값 확인 가능 (Default: 열 기준, NaN값 제외)
data = {
"korean" : [50, 60, 70],
"math" : [10, np.nan, 40]
}
df = pd.DataFrame(data, index = ["a","b","c"])
df.max() # 최댓값
df.min() # 최솟값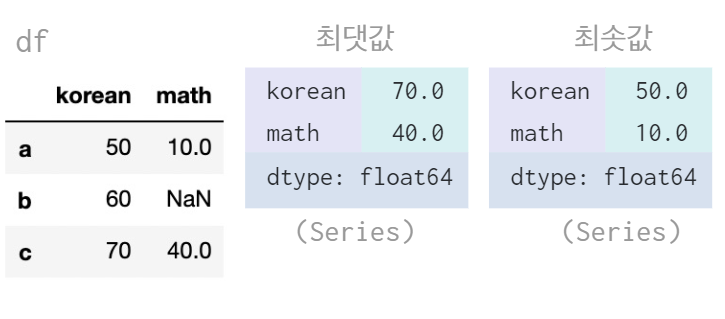
👉 이 때 dtype이 float64 실수형이 나온다는 점을 유의하자
집계함수 - sum, mean
sum, mean 메서드 활용하여 합계 및 평균 계산 (Default: 열 기준, NaN값 제외)
data = {
"korean" : [50, 60, 70],
"math" : [10, np.nan, 40]
}
df = pd.DataFrame(data, index = ["a","b","c"])
df.sum() # 합계
df.mean() # 평균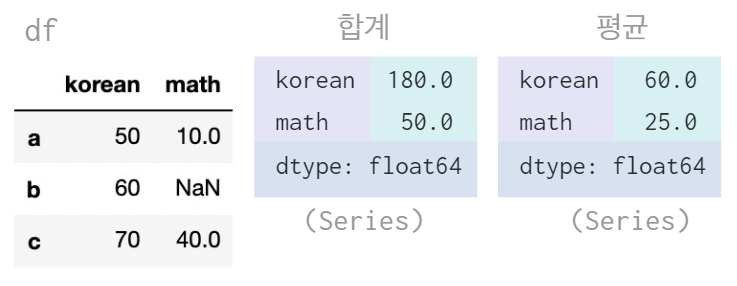
👉 math 의 평균은 NaN 값을 제외하므로 으로 25가 된다.
🎈 axis, skipna 인자 활용하여 합계 및 평균 계산 (행 기준, NaN값 포함 시)
- axis = 1 : 원래 Default는 열 기준, 그러나 axis = 1을 넣어주면 행 기준으로 연산처리한다.
- skipna : skip + Na 즉, 값이 없는 데이터가 있으면 무시할 것인지 묻는 것으로
skipna = False는 무시하지 않고 NaN을 반환하겠다는 뜻이다.
data = {
"korean" : [50, 60, 70],
"math" : [10, np.nan, 40]
}
df = pd.DataFrame(data, index = ["a","b","c"])
df.sum(axis = 1) # 합계
df.mean(axis = 1, skipna = False) # 평균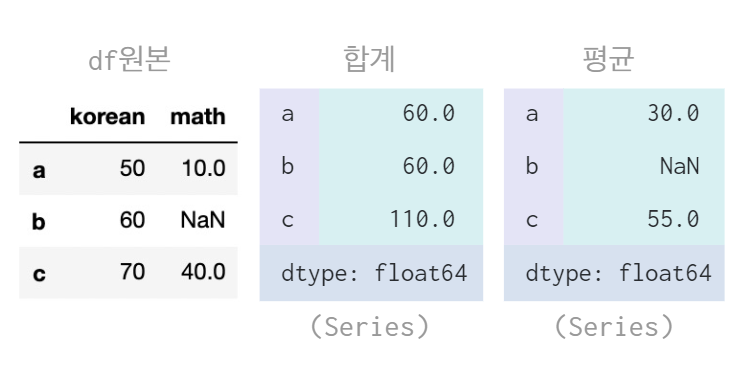
👉 NaN 값을 반환하는 skipna = False를 사용했으므로 b의 평균()은 값을 구할수가 없기 때문에 NaN으로 나타난다. 만약 skipna = True 라고 하면 NaN값은 없는 셈 치므로 b의 평균()은 60이 된다.
🎈 fillna 활용하여 NaN값이 존재하는 column의 평균 구하여 NaN 값 대체
B_avg = df["math"].mean()
print(B_avg) # 25.0
# NaN 값 대체
df["math"] = df["math"].fillna(B_avg) # NaN값 자리에 column의 평균 25.0을 넣어준다.
# 평균
df.mean(axis = 1, skipna = False)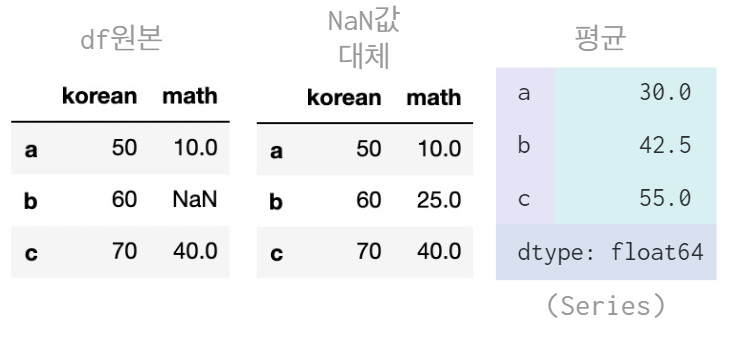
실습✍ 집계함수
- 각 컬럼별 데이터 개수를 col_num 변수에 저장하고 출력해보세요.
- 각 행별 데이터 개수를 row_num 변수에 저장하고 출력해보세요.
- 각 컬럼별 최댓값을 구하여 col_max 변수에 저장하고 출력해보세요.
- 각 컬럼별 최솟값을 구하여 col_min 변수에 저장하고 출력해보세요.
- 각 컬럼별 합계를 구하여 col_sum 변수에 저장하고 출력해보세요.
- math 컬럼의 결측값을 해당 컬럼의 최솟값으로 대체하고 df를 출력해보세요.
- 각 컬럼별 평균을 구하여 col_avg 변수에 저장하고 출력해보세요.
- 주어진 DataFrame
import numpy as np
import pandas as pd
data = {
'korean' : [50, 60, 70],
'math' : [10, np.nan, 40]
}
df = pd.DataFrame(data, index = ['a','b','c'])
print(df, "\n") korean math
a 50 10.0
b 60 NaN
c 70 40.0 - 답안 작성하기
# 각 컬럼별 데이터 개수
col_num = df.count() # df.count(axis = 0)
print(col_num, "\n")
# 각 행별 데이터 개수
row_num = df.count(axis = 1)
print(row_num, "\n")
# 각 컬럼별 최댓값
col_max = df.max()
print(col_max, "\n")
# 각 컬럼별 최솟값
col_min = df.min()
print(col_min, "\n")
# 각 컬럼별 합계
col_sum = df.sum()
print(col_sum, "\n")
# 컬럼의 최솟값으로 NaN값 대체
math_min = df["math"].min()
df['math'] = df["math"].fillna(math_min)
print(df, "\n")
# 각 컬럼별 평균
col_avg = df.mean()
print(col_avg, "\n")- 결과
1. 각 컬럼별 데이터 개수
korean 3
math 2
dtype: int64
2. 각 행별 데이터 개수
a 2
b 1
c 2
dtype: int64
3. 각 컬럼별 최댓값
korean 70.0
math 40.0
dtype: float64
4. 각 컬럼별 최솟값
korean 50.0
math 10.0
dtype: float64
5. 각 컬럼별 합계
korean 180.0
math 50.0
dtype: float64
6. 컬럼의 최솟값으로 NaN값 대체
korean math
a 50 10.0
b 60 10.0
c 70 40.0
7. 각 컬럼별 평균
korean 60.0
math 20.0
dtype: float64 3) 그룹으로 묶기
groupby
간단한 계산 이상으로 조건부로 집계하고 싶을 때 사용, sql에 있는 개념과 같다.
import numpy as np
import pandas as pd
df = pd.DataFrame({
"data1" : range(6),
"data2" : [4,4,6,0,6,1],
"key" : ["A","B","C","A","B","C"]
})
a = df.groupby("key").sum() # 1번
b = df.groupby(["key","data1"]).sum() # 2번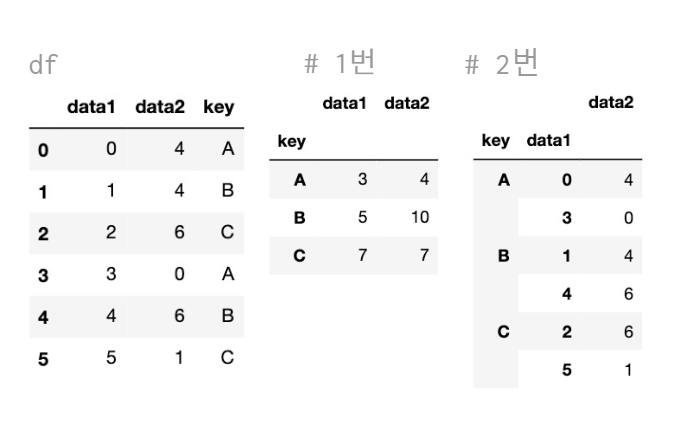
👉 2번은 key로도 groupby, data1로도 groupby한 결과(계층적으로 groupby)에 sum
aggregate
aggregate 함수를 이용하여 groupby로 한번에 계산하는 방법
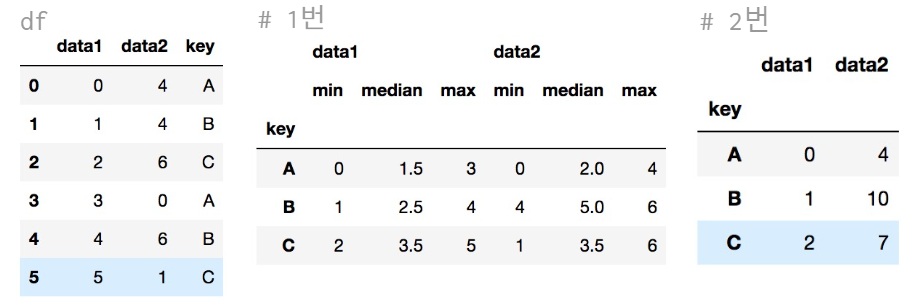
df.groupby("key").aggregate(["min", np.median, max]) # 1번
df.groupby("key").aggregate({"data1": "min", "data2": np.sum}) # 2번👉 ["min", np.median, max] 표현 방법이 다 다르지만 모두 사용가능하다는 걸 보여주기 위해 일부러 이렇게 표기하였다. ("min"은 일반적인 집계함수, np.median은 넘파이 함수, max는 판다스 함수(따옴표X))
👉 data1은 min값, data2에 대해서는 sum
filter
groupby를 통해서 그룹 속성을 기준으로 데이터 필터링
def filter_by_mean(x):
return x["data2"].mean() > 3
df.groupby("key").mean() # 1번
df.groupby("key").filter(filter_by_mean) # 2번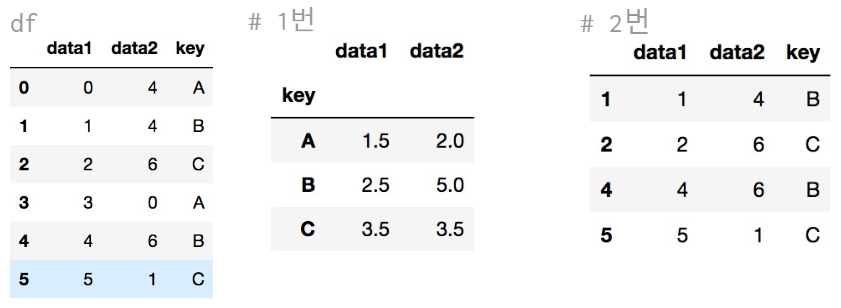
👉 filter_by_mean(x) 함수 정의를 통해 x의 "data2"값의 평균이 3보다 크면 True, 작으면 False를 return한다.
df.groupby("key").filter(filter_by_mean) "data2"에 있는 column을 key로 묶으면, A는 2(4, 0)로 3보다 작으므로 반환하지 않는다. B는 5(4, 6), C는 3.5(6, 1) 조건에 부합하므로 filter로 필터링을 통해 반환한다.
apply, lambda
groupby를 통해서 묶인 데이터에 함수 적용
apply함수 : 데이터 프레임에 특정 함수를 적용시키는 함수lambda함수 : 한 번 쓰고 버리는 일회용 함수
lambda 함수 : 사용자정의 함수를 문법에 맞추어 작성하는 것보다 훨씬 간단하게 한줄 정도로 해결할 수 있는 함수이다. lambda 함수의 기본구조는 다음과 같다.
lambda <매개변수1>, <매개변수2>...: 매개변수를 이용한 식(if 문이 나올 수 있음)f = lambda x, y : x + y f(5,6) >> 11출처 : https://wikidocs.net/47806 [파이썬을 활용한 회계프로그래밍]
df.groupby("key").apply(lambda x: x.max() - x.min())
👉 .groupby("key")로 묶었을 때 data1의 A는 0과 3, 즉 max는 3이고 min은 0이므로 .apply(lambda x: x.max() - x.min())은 3이다.
get_group
groupby로 묶인 데이터에서 key값으로 데이터를 가져올 수 있다
df = pd.read_csv("./univ.csv")
# 상위 5개 데이터
df.head()
# 데이터 추출
df.groupby("시도").get_group("충남") # "시도"컬럼의 "충남"만 추출
len(df.groupby("시도").get_group("충남")) # 94 - 데이터가 몇개인지
실습✍ 그룹으로 묶기(1)
- 데이터 프레임의 key 칼럼을 groupby함수로 묶고, key별로 data1과 data2 합계를 출력해보세요.
- 데이터 프레임의 key와 data1칼럼을 groupby함수로 묶고, key와 data1별로 data2의 합계를 출력해보세요.
- 주어진 DataFrame
import numpy as np
import pandas as pd
df = pd.DataFrame({
'key': ['A', 'B', 'C', 'A', 'B', 'C'],
'data1': [1, 2, 3, 1, 2, 3],
'data2': [4, 4, 6, 0, 6, 1]
})
print("DataFrame:")
print(df, "\n")DataFrame:
key data1 data2
0 A 1 4
1 B 2 4
2 C 3 6
3 A 1 0
4 B 2 6
5 C 3 1 - 답안 작성하기
# groupby 함수를 이용해봅시다.
# key를 기준으로 묶어 합계를 구해 출력해보세요.
print(df.groupby("key").sum())
# key와 data1을 기준으로 묶어 합계를 구해 출력해보세요.
print(df.groupby(["key","data1"]).sum())- 결과
1.
data1 data2
key
A 2 4
B 4 10
C 6 7
2.
data2
key data1
A 1 4
B 2 10
C 3 7실습✍ 그룹으로 묶기(2)
- 데이터 프레임을 key를 기준으로 묶고, key별 data1과 data2 각각의 최솟값과 중앙값, 최댓값을 출력해봅시다.
- 데이터 프레임을 key를 기준으로 묶고, key별 data1의 최솟값과 data2의 합계를 출력해봅시다.
- 주어진 DataFrame
import numpy as np
import pandas as pd
df = pd.DataFrame({
'key': ['A', 'B', 'C', 'A', 'B', 'C'],
'data1': [0, 1, 2, 3, 4, 5],
'data2': [4, 4, 6, 0, 6, 1]
})
print("DataFrame:")
print(df, "\n")DataFrame:
key data1 data2
0 A 0 4
1 B 1 4
2 C 2 6
3 A 3 0
4 B 4 6
5 C 5 1 - 답안 작성하기
# aggregate를 이용하여 요약 통계량을 산출해봅시다.
# 데이터 프레임을 'key' 칼럼으로 묶고, data1과 data2 각각의 최솟값, 중앙값, 최댓값을 출력하세요.
print(df.groupby("key").aggregate([min, np.median, max]))
# 데이터 프레임을 'key' 칼럼으로 묶고, data1의 최솟값, data2의 합계를 출력하세요.
print(df.groupby("key").aggregate({"data1":min, "data2":sum}))- 결과
1.
data1 data2
min median max min median max
key
A 0 1.5 3 0 2.0 4
B 1 2.5 4 4 5.0 6
C 2 3.5 5 1 3.5 6
2.
data1 data2
key
A 0 4
B 1 10
C 2 7💎 min이나 max, sum의 경우 global 함수에도 존재하지만 median의 경우 numpy의 속성이라 np.median 이라고 해줘야한다.
