오늘의 논문리뷰는 VGGNet입니다. VGGNet은 2014년 ImageNet Challenge에서 Top-5 Accuracy 92.7%를 달함으로써 GoogleLeNet 다음으로 2위를 차지 했습니다. VGGNet은 'Very Deep Convolutional Networks for large-scale image recognition'에서 제시가 되었으며 8개의 layer를 통해서 높은 성능을 내었던 AlexNet 보다 2배 이상의 16-19개의 layer로 구성되어 있습니다.
하지만 layer의 깊이가 깊어짐에 따라 overfitting, gradient vanishing, 연산량 문제가 생기기 때문에 깊이를 증가시키는 것이 쉬운 문제는 아니었습니다.논문의 내용을 살펴보며 어떻게 VGGNet이 깊은 네트워크를 구성하면서 좋은 성능을 낼 수 있었는지 살펴보겠습나다.
VGGNet의 구조.
이번 논문 리뷰에서는 VGG-16 기준으로 살펴볼 예정입니다. VGG는 층의 개수에 따라 VGG-16 , VGG-19 , VGG-23 로 불리고 있습니다. 만약 층의 개수가 30개 이라면 VGG-30이 되게 됩니다.
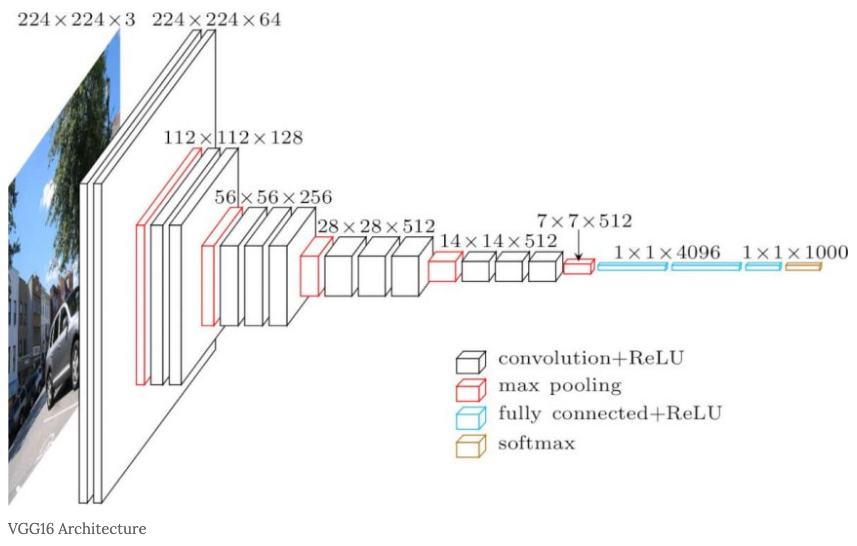
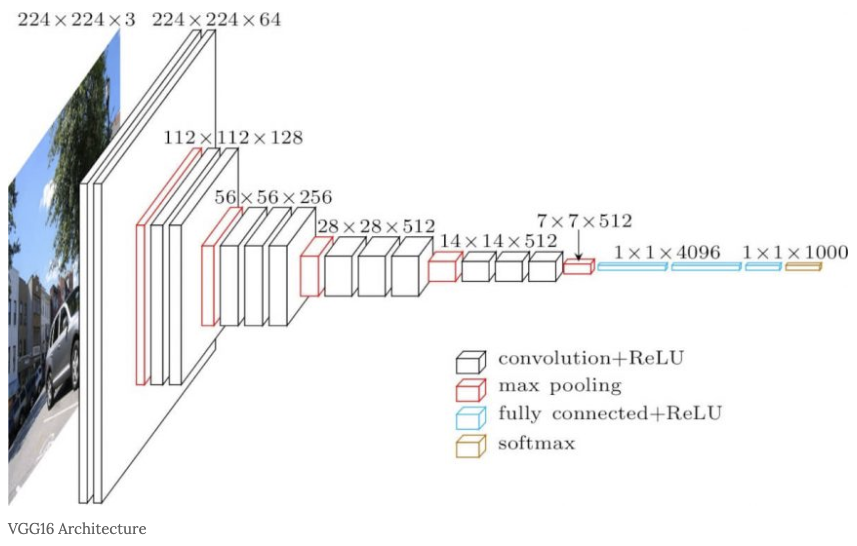
VGGNet-16의 구조
VGG의 Input:trainning set의 각 pixel에 평균 RGB 값을 빼준 전처리를 거친 224 * 224 RGB 이미지입니다.
입력된 이미지는 3 3 필터를 적용한 ConvNet을 통과하며, 비선형성을 위해 1 1 필터도 적용합니다.
stride = 1이 적용되고 공간 해상도 유지를 위해 3 * 3 conv layer에 대해 1pixel에 padding을 적용합니다.
Max-pooling은 2 * 2pixel 에서 stride = 2 로 수행된됩니다.
Convolution layers에 뒤에는 3개의 FC-layer가 뒤따릅니다. 첫번째와 두번째 FC-layer는 각 4096개의 채널을 가지고 마지막 세번째는 1000개의 채널을 가진다. FC-layer 다음으로는 Softmax가 뒤따릅니다. FC-layer의 구성은 모든 네트워크에서 동일합니다. 모든 hidden layer에 Activation(활성화) 함수로 ReLU를 사용하며 AlexNet에 적용된 LRN(Local Response Normalization)는 VGGNet 성능에 영향이 없기 때문에 적용하지 않습니다.
Input : 224 x 224 x 3
filter : 3x3x64(padding same , stride =1) (1)
Output : 224 x 224 x 64
Input : 224 x 224 x 64
filter : 3x3x64(padding same , stride =1) (2)
Output : 224 x 224 x 64
Input : 224 x 224 x 64 + MaxPooling 2x2
Output: 112 x 112 x 64
Input : 112 x 112 x 64
filter : 3x3x128(padding same , stride =1) (3)
Output : 112 x 112 x 128
Input : 112 x 112 x 128
filter : 3x3x128(padding same , stride =1) (4)
Output : 112 x 112 x 128
Input : 112 x 112 x 128 + MaxPooling 2x2
Output: 56 x 56 x 128
Input : 56 x 56 x 128
filter : 3x3x256(padding same , stride =1) (5)
Output : 56 x 56 x 256
Input : 56 x 56 x 256
filter : 3x3x256(padding same , stride =1) (6)
Output : 56 x 56 x 256
Input : 56 x 56 x 256
filter : 3x3x256(padding same , stride =1) (7)
Output : 56 x 56 x 256
Input : 56 x 56 x 256 + MaxPooling 2x2
Output: 28 x 28 x 256
Input : 28 x 28 x 256
filter : 3x3x512(padding same , stride =1) (8)
Output : 28 x 28 x 512
Input : 28 x 28 x 512
filter : 3x3x512(padding same , stride =1) (9)
Output : 28 x 28 x 512
Input : 28 x 28 x 512
filter : 3x3x512(padding same , stride =1) (10)
Output : 28 x 28 x 512
Input : 28 x 28 x 512 + MaxPooling 2x2
Output: 14 x 14 x 512
Input : 14 x 14 x 512
filter : 3x3x512(padding same , stride =1) (11)
Output : 14 x 14 x 512
Input : 14 x 14 x 512
filter : 3x3x512(padding same , stride =1) (12)
Output : 14 x 14 x 512
Input : 14 x 14 x 512
filter : 3x3x512(padding same , stride =1) (13)
Output : 14 x 14 x 512
Input : 14 x 14 x 512 + MaxPooling 2x2
Output: 7 x 7 x 512
Input: 7 x 7 x 512
Fully Connected Layer (14)
Output : 4096
Input: 4096
Fully Connected Layer (15)
Output : 4096
Input: 4096
Fully Connected Layer (16)
Output : 1000
Softmax
3x3 filter
VGGNet의 큰 특징은 3x3 filter를 사용했다는점이다. VGG 모델 이전에 Convolutional Network를 활용하여 이미지 분류에서 좋은 성과를 보였던 모델들은 비교적 큰 Receptive Field를 갖는 11x11 필터나 7x7 필터를 포함합니다.
그러나 VGG 모델은 오직 3x3 크기의 작은 필터만 사용했음에도 이미지 분류 정확도를 비약적으로 개선시켰습니다.
 3x3 filter와 5x5 filter의 차이 - 출저 bskyvision, [CNN 알고리즘들] VGGNet의 구조 (VGG16)
3x3 filter와 5x5 filter의 차이 - 출저 bskyvision, [CNN 알고리즘들] VGGNet의 구조 (VGG16)
사진을 보면 알 수 있듯이 7x7의 레이어에 5x5의 필터를 적용하면 49개의 파라미터를 가지며 3x3의 Feature Map이 만들어지게 됩니다. 하지만 3x3의 필터를 3번 적용시키면 5x5의 필터와 동일한 효과를 볼 수 있을 뿐더러 파라미터의 개수도 더 적은 27개가 생기게 됩니다. 같은 효과를 가지지만 더 적은 파라미터를 나온다면 학습의 효율성이 좋아질 것입니다. 그렇기 때문에 Conv 필터의 사이즈를 3x3으로 설정한 것입니다.
또한 Layer 수가 많아질수록 더 많은 Non-linear activation function인 ReLU 를 사용할 수 있고, 그에 따라 Non-linearity가 증가 하여 더 유용한 Feature를 추출할 수 있다. 그래서 실제로 7x7 Filter 1개보다는 3x3 Filter 3개가 성능이 더 좋습니다.
1x1 filter
또한 Non-linearity를 증가시키기 위해 1x1 Conv. filter를 사용했는데 (GoogLeNet등의 경우에는 Parameter 수의 감소 목적으로 사용되었습니다.), 3x3 Conv. filter를 사용한 경우보다 오히려 성능이 더 안 좋아졌다 (뒤에 결과에 나옴). 결과에서 다시 언급하겠지만, 논문에서는 1x1 Conv. filter를 사용하면 Non-linearity는 높아지지만 Spatial한 Context 정보를 놓치기 때문 에 오히려 성능이 더 낮아졌다고 언급했다.
Hyper Parameter
- batch size = 256
- momentum = 0.9
- weight decay = 0.0005
- drop out = 0.5
- epoch = 74
- learning rate = 0.01(10배씩 감소)
Data Augmentation
-
224 * 224 size로 crop된 이미지 랜덤으로 수평 뒤집기
-
랜덤으로 RGB값 변경
-
Training image rescale
실험을 위해 3가지 방법으로 rescale을 하고 비교를 합니다. -
input size = 256, 256로 고정
-
input size = 356 356로 고정
-입력 size를 [256, 512] 범위로 랜덤하게 resize 합니다. 이미지 안의 object가 다양한 규모로 나타나고, 다양한 크기의 object를 학습하므로 training에 효과가 있었다고 합니다. 빠른 학습을 위해서 동일한 배치를 갖은 size=384 입력 image로 pre-trained 된 것을 fine-tunning함으로써 multi-scale 모델을 학습시켰습니다.
Tensorflow Code
Pretrained 된 VGG16 모델을 로드하여 VGG의 구조 확인 할 수 있는 코드입니다.
import numpy as np
import pandas as pd
import os
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
input_tensor = Input(shape=(224, 224, 3))
base_model = VGG16(input_tensor=input_tensor, include_top=True, weights='imagenet')
model = Model(inputs=input_tensor, outputs=base_model.output)
model.summary()VGGNet 클래스 만들기
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense , Conv2D , Dropout , Flatten , Activation, MaxPooling2D , GlobalAveragePooling2D
from tensorflow.keras.optimizers import Adam , RMSprop
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.callbacks import ReduceLROnPlateau , EarlyStopping , ModelCheckpoint , LearningRateScheduler
def create_vggnet(in_shape=(224, 224, 3), n_classes=10):
input_tensor = Input(shape=in_shape)
# Block 1
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv1')(input_tensor)
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool')(x)
# Block 2
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv1')(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool')(x)
# Block 3
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv1')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv2')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool')(x)
# Block 4
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool')(x)
# Block 5
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block5_pool')(x)
x = GlobalAveragePooling2D()(x)
x = Dropout(0.5)(x)
x = Dense(units = 120, activation = 'relu')(x)
x = Dropout(0.5)(x)
# 마지막 softmax 층 적용.
output = Dense(units = n_classes, activation = 'softmax')(x)
model = Model(inputs=input_tensor, outputs=output)
model.summary()
return model모델 생성하기
model = create_vggnet(in_shape=(224, 224, 3), n_classes=10)
VGG16을 연속된 Conv를 하나의 block으로 간주하고 이를 생성할 수 있는 conv_block()함수 만듬.
- conv_block()함수는 인자로 입력 feature map과 Conv 연산에 사용될 커널의 필터 개수와 사이즈(무조건 3x3), 그리고 출력 feature map을 크기를 줄이기 위한 strides를 입력 받습니다.
- 또한 repeats인자를 통해 연속으로 conv 연산 수행 횟수를 정합니다.
from tensorflow.keras.layers import Conv2D, Dense, MaxPooling2D, GlobalAveragePooling2D, Input
from tensorflow.keras.models import Model
# 인자로 입력된 input_tensor에 kernel 크기 3x3(Default), 필터 개수 filters인 conv 연산을 n회 연속 적용하여 출력 feature map을 생성.
# repeats인자를 통해 연속으로 conv 연산 수행 횟수를 정함
# 마지막에 MaxPooling(2x2), strides=2 로 출력 feature map의 크기를 절반으로 줄임. 인자로 들어온 strides는 MaxPooling에 사용되는 strides임.
def conv_block(tensor_in, filters, kernel_size, repeats=2, pool_strides=(2, 2), block_id=1):
'''
파라미터 설명
tensor_in: 입력 이미지 tensor 또는 입력 feature map tensor
filters: conv 연산 filter개수
kernel_size: conv 연산 kernel 크기
repeats: conv 연산 적용 회수(Conv2D Layer 수)
pool_strides:는 MaxPooling의 strides임. Conv 의 strides는 (1, 1)임.
'''
x = tensor_in
# 인자로 들어온 repeats 만큼 동일한 Conv연산을 수행함.
for i in range(repeats):
# Conv 이름 부여
conv_name = 'block'+str(block_id)+'_conv'+str(i+1)
x = Conv2D(filters=filters, kernel_size=kernel_size, activation='relu', padding='same', name=conv_name)(x)
# max pooling 적용하여 출력 feature map의 크기를 절반으로 줄임. 함수인자로 들어온 strides를 MaxPooling2D()에 인자로 입력.
x = MaxPooling2D((2, 2), strides=pool_strides, name='block'+str(block_id)+'_pool')(x)
return xVGGNet 모델 생성
def create_vggnet_by_block(in_shape=(224, 224,3), n_classes=10):
input_tensor = Input(shape=in_shape, name='Input Tensor')
# (입력 image Tensor 또는 Feature Map)->Conv->Relu을 순차적으로 2번 실행, 출력 Feature map의 filter 수는 64개. 크기는 MaxPooling으로 절반.
x = conv_block(input_tensor, filters=64, kernel_size=(3, 3), repeats=2, pool_strides=(2, 2), block_id=1)
# Conv연산 2번 반복, 입력 Feature map의 filter 수를 2배로(128개), 크기는 절반으로 출력 Feature Map 생성.
x = conv_block(x, filters=128, kernel_size=(3, 3), repeats=2, pool_strides=(2, 2), block_id=2)
# Conv연산 3번 반복, 입력 Feature map의 filter 수를 2배로(256개), 크기는 절반으로 출력 Feature Map 생성.
x = conv_block(x, filters=256, kernel_size=(3, 3), repeats=3, pool_strides=(2, 2), block_id=3)
# Conv연산 3번 반복, 입력 Feature map의 filter 수를 2배로(512개), 크기는 절반으로 출력 Feature Map 생성.
x = conv_block(x, filters=512, kernel_size=(3, 3), repeats=3, pool_strides=(2, 2), block_id=4)
# Conv 연산 3번 반복, 입력 Feature map의 filter 수 그대로(512), 크기는 절반으로 출력 Feature Map 생성.
x = conv_block(x, filters=512, kernel_size=(3, 3), repeats=3, pool_strides=(2, 2), block_id=5)
# GlobalAveragePooling으로 Flatten적용.
x = GlobalAveragePooling2D()(x)
x = Dropout(0.5)(x)
x = Dense(units = 120, activation = 'relu')(x)
x = Dropout(0.5)(x)
# 마지막 softmax 층 적용.
output = Dense(units = n_classes, activation = 'softmax')(x)
# 모델을 생성하고 반환.
model = Model(inputs=input_tensor, outputs=output, name='vgg_by_block')
model.summary()
return model모델 생성하기
model = create_vggnet_by_block(in_shape=(224, 224, 3), n_classes=10)이렇게 pretained model을 생성하거나 custom으로 VGG모델을 만들어 보았습니다. 감사합니다.
