소개
- 지침 1: 소프트웨어 디자인의 중요성을 이해하라. 결합(coupliing)과 의존성(dependency)를 소프트웨어 디자인으로 해결!
- 지침 2: 변경을 위한 디자인. 단일 책임 원칙(Single Responsibility Principle, SRP)과 반복하지 말 것(Don't Repeat Your self, DRY) 원칙
- 지침 3: 인터페이스를 분리해 인위적인 결합을 피하라. 인터페이스 분리 원칙(Interface Segregation Principle, ISP)
- 지침 4: 테스트 용이성을 위한 디자인. 비공개 함수(private function)의 테스트
- 지침 5: 확장을 위한 디자인. 개방-폐쇄 원칙(Open-Close Principle, OCP)
지침 1: 소프트웨어 디자인의 중요성을 이해하라
기능은 소프트웨어 디자인이 아니다
프로젝트의 성공을 위해서 C++의 기능에 의존하지 말고 소프트웨어의 전반적인 구조에 의존해야한다.
소프트웨어 디자인: 의존성과 추상화 관리 기술
소프트웨어에서 변하지 않는 것은 소프트웨어가 변경될 것이라는 사실이다. 그렇기 때문에 소프트웨어를 소프트웨어(software)라고 부르는 이유다. 하드웨어 비해 부드럽고 변하기 쉽기(malleable) 떄문이다.
켄트 벡(kent Beck)은 테스트 주도 개발(test-driven development)에 관한 자신의 책에서 다음처럼 표현했다.
의존성은 모든 규모의 소프트웨어 개발에서 핵심적인 문제이다.

위 그림의 예시를 위해 건축으로 비유한다. 소프트웨어 아키텍처 또는 디자인 패턴은 건물의 전체적인 구조를 설계하는 일에 비유한다. 구현 상세는 건물의 세부적인 내용, 냉장고, 액자, 침대 등등 으로 비유한다.
소프트웨어 디자인에서는 큰 그림에 초점을 맞추는 것으로 시작한다.
소프트웨어 아키텍처는 미래에 변경하기 가장 어려운 소프트웨어의 한 측면인 커다란 결정을 수반한다.
소프트웨어 아키텍처는 미래에 변경하기 가장 어려운 소프트웨어의 한 측면인 커다란 결정을 수반한다.
아키텍처는 프로젝트에서 초기에 제대로 할 수 있기를 바라는 결정이지만, 반드시 다른 결정보다 더 제대로 할 가능성이 높지는 않다.
- 랄프 존슨(Ralph Johnson
소프트웨어 아키텍처는 소프트웨어에 접근하는 전체 전략을 나타내는 반면, 소프트웨어 디자인은 전략을 펼치는 전술이라고 볼 수 있다.
관용구(idiom)는 반복적인 문제에 흔히 사용되는 언어별 해결책이다. C++에서 관용구 대부분은 구현 상세로 분류할 수 있다. 예를 들면 복사 대입 연산자 구현을 통해 알고있을 복사-교환(copy-and-swap) 관용구와 RAII(Resouce acquisition is initialization) 관용구가 있다. 그 외 소프트웨어 디자인에 속하는 관용구는 비가상 인터페이스(Non-Virtual Interface, NVI) 관용구와 Pimple 관용구가 있다.
기능에 집중하기
C++ 공동체가 기능에 집중하는 이유
- 기능이 너무 많고 때로는 복잡한 세부 내용도 있어 모든 기능을 적절히 사용하는 방법에 관해 이야기하는 데 많은 시간을 써야한다.
- 기능에 잘못된 기대를 할 수 있다는 것이다. C++ 20 모듈(module) 예시
- 소프트웨어 디자인의 복잡성에 비해 C++ 기능의 복잡성이 작다.
기능은 중요하지만 기능만으로는 프로젝트를 구원할 수 없다.
소프트웨어 디자인과 디자인 원칙에 집중하기
프로젝트 성공의 기초는 디자인
지침 2: 변경을 위한 디자인
좋은 소프트웨어에 기본적으로 기대하는 것 중 하나는 쉽게 변경할 수 있는 능력이다. 하지만 그것은 쉽지 않다.
관심사 분리
인위적인 의존성을 줄이고 변경을 단순화하는 최선의 입증된 해결책 중 하나는 관심사 분리(separation of concerns)다. 관심사 분리의 의도는 복잡도를 더 잘 이해하고 관리해 더 많은 모듈형 소프트웨어를 설계하는 것이다.
단일 책임 원칙(Single Responsibility Principle, SRP)
클래스를 변경하는 이유는 단 하나여야 한다.
모든 것은 오직 한 가지 일만 해야 한다.
인위적인 결합 예
//#include <some_json_library.h> // 잠재적인 물리적 의존성
class Document
{
public:
// ...
virtual ~Document() = default;
virtual void exportToJSON( /* ... */ ) const = 0;
virtual void serialize( ByteStream&, /* ... */) const = 0;
/// ...
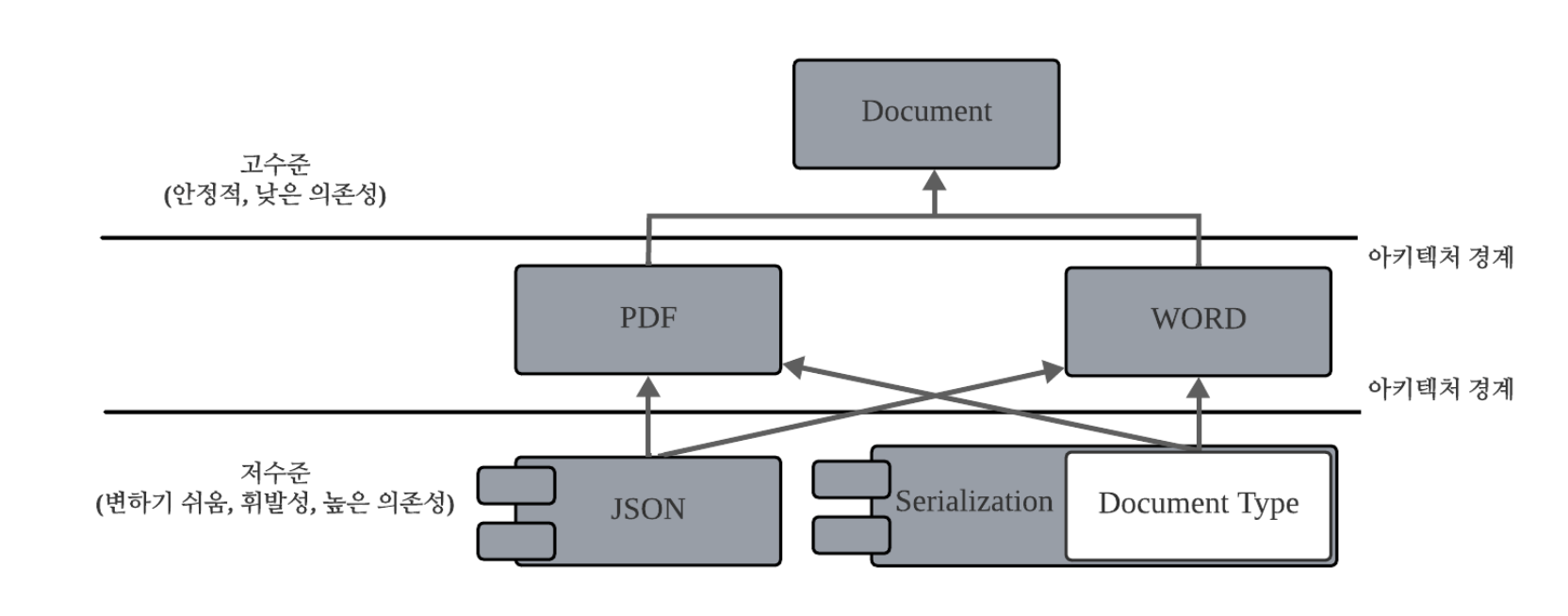
};첫 번째로 파생 클래스에서 exportToJSON()을 구현해야 한다. 파생 클래스는 JSON 내보내기를 수동으로 구현하는 부담을 지고 싶지 않을 가능성이 높으므로 json, rapidjson, simdjson 등 외부의 서드파티 JSON 라이브러리에 의존할 것이다. 이를 위해 선택한 라이브러리가 무엇이든 exportToJSON() 멤버 함수로 인해 파생 문서가 갑자기 그 라이브러리에 의존한다. 그리고 모든 파생 클래스는 일관성이라는 이유만으로 같은 라이브러리에 의존할 가능성이 크다. 따라서 파생 클래스는 실제로 독립적이지 않으며 특정 디자인 결정과 인위적으로 결합(coupling)한다. 또한 특정 JSON 라이브러리에 대한 의존성은 더 이상 가볍지 않으므로 상속 계통(hierarchy) 재사용성을 확실히 제한한다. 게다가 다른 라이브러리로 전환하면 모든 파생 클래스를 조정해야 하므로 큰 변화가 생긴다.
두 번째로 serialize() 함수로 인해 같은 인위적 의존성이 생긴다. serialize() 또한 protobuf 나 Boost.serialization 같은 서드 파티 라이브러리로 구현할 것이다. 이는 직교적이고 관련 없는 두 가지 디자인 관심사 (JSON과 serialize) 사이에 결합(coupling)을 만들므로 의존성 상황을 상당히 악화시킨다.
세 번째는 serialize() 함수로 인한 것이다. 이 함수로 인해 Documnet에서 파생한 클래스는 문서를 직렬화하는 방법에 관한 전역 결정에 의존한다. 리틀엔디언(little endian), 빅엔디언(big endian)? PDF 파일, WORD 파일? 예를 들어 열거형(enum)을 사용할 수 있다.
enum class DocumentType
{
pdf,
word,
// ... 있을 수 있는 더 많은 문서유형
};이 접근법은 직렬화에 매우 일반적이다. 하지만 이 저수준 문서 표현을 Document 클래스 구현 내에서 사용하면 실수로 서로 다른 모든 종류의 문서를 결합할 수 있다. 모든 파생 클래스는 다른 모든 Document 타입에 관해 암시적으로 알 고 있으며, 결과적으로 새로운 문서 종률르 추가하면 모든 기존 문서 유형에 직접 영향을 미친다.
- 사용한 JSON 라이브러리에 대한 직접적인 의존성 때문에 exportToJSON() 함수 구현 상세가 바뀐다.
- 바탕 구현 내용이 바뀌기 때문에 exportToJSON() 함수 시그니처가 바뀐다.
- ByteStream 클래스에 대한 직접적인 의존성 때문에 Document 클래스와 serialize() 함수가 바뀐다.
- 구현 상세에 관한 직접적인 의존성 때문에 serialize() 함수의 구현 상세가 바뀐다.
- DocumentType 열거형에 대한 직접적인 의존성 때문에 모든 문서 유형이 바뀐다.
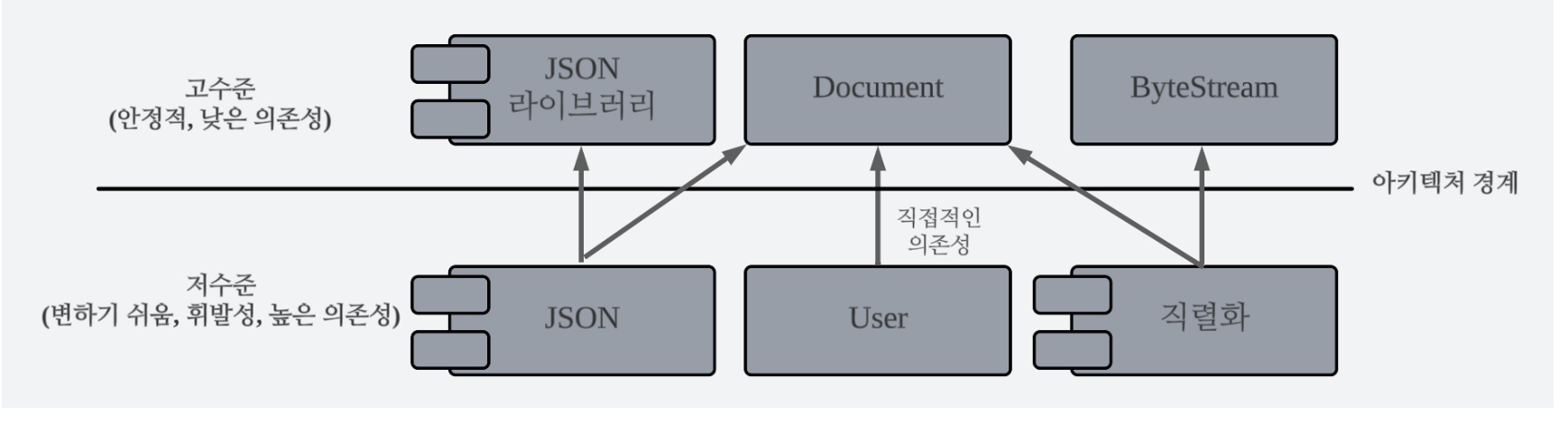
논리적 결합 대 물리적 결합
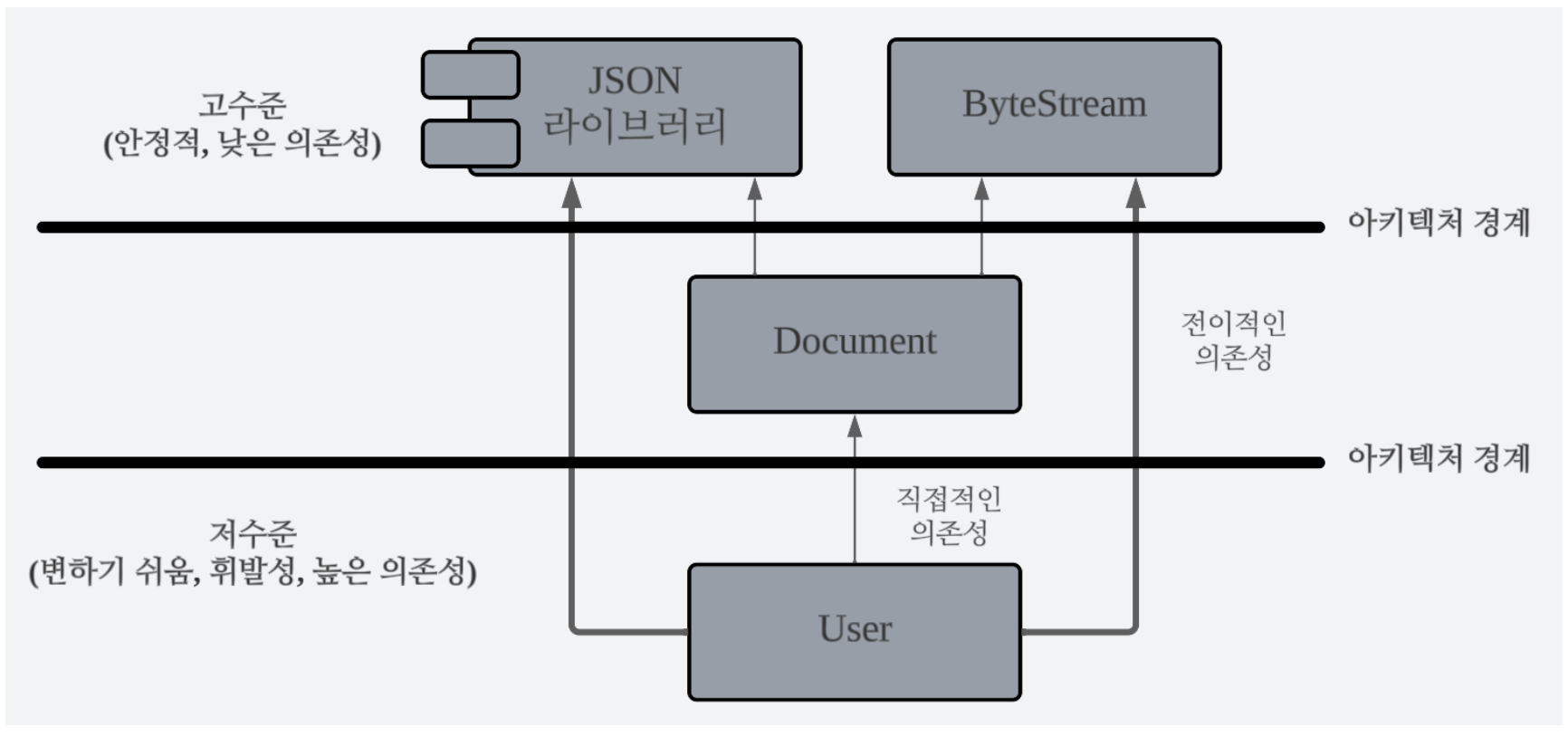
SRP는 관심사와 진적으로 속하지 않는 것, 즉 비응집적(접착적)인 것을 분리해야 한다고 조언한다. 여러 가지 이유로 변경하는 것을 변형점(variation point)으로 분리하도록 조언한다.
class Document
{
public:
// ...
virtual ~Document() = default;
// 'exportToJSON()' 과 'serialize()' 함수는 더 이상 없다.
// 강한 결합을 일으키지 않는 매우 기본적인 문서 연산만 남아있다.
// ...
}반복하지 말 것
// ---- <Money.h> ----
class Money { /* ... */ };
Money operator*(Money money, double factor);
Money operator*(Money lhs, Money rhs);
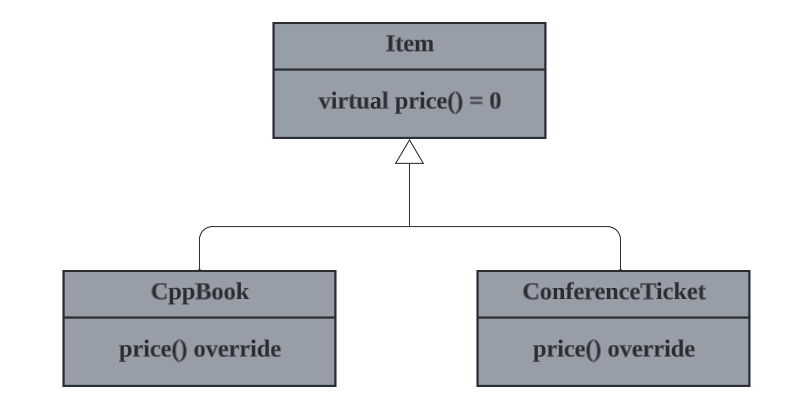
// ---- <Item.h> ----
#include <Money.h>
class Item
{
public:
virtual ~Item() = default;
virtual Money price() const = 0;
};// ---- <CppBook.h> ----
#include <Item.h>
#include <Money.h>
#include <string>
class CppBook : public Item
{
public:
explicit CppBook(std::string title, std::string author, Money price)
: title_(std::move(title)), author_(std::move(author)), priceWithTax_(price * 1.15)
{}
std::string const& title() const { return title_; }
std::string const& author() const { return author_; }
Money price() const override { return priceWithTax_; }
private:
std::string title_;
std::string author_;
Money priceWithTax_;
};// ---- <ConferenceTicket.h> ----
#include <Item.h>
#include <Money.h>
#include <string>
class ConferenceTicket : public Item
{
public:
explicit ConferenceTicket(std::string name, Money price)
: name_(std::move(name)), priceWithTax_(price * 1.15) // 15%
{}
std::string const& name() const { return name_; }
Money price() const override { return priceWithTax_; }
private:
std::string name_;
Money priceWithTax_;
};#include <CppBook.h>
#include <ConferenceTicket.h>
#include <algorithm>
#include <cstdlib>
#include <memory>
#include <numeric>
#include <vector>
int main()
{
std::vector<std::unique_ptr<Item> items{};
items.emplace_back(std::make_unique<CppBook>("Effective C++", "Scott Meyers", 19.99));
items.emplace_back(std::make_unique<CppBook>("C++ Templates", "David Vandevoorde et al.", 49.99));
items.emplace_back(std::make_unique<ConferenceTicket>("CppCon", 999.0);
items.emplace_back(std::make_unique<ConferenceTicket>("Meeting C++", 699.0);
items.emplace_back(std::make_unique<ConferenceTicket>("C++ on Seq", 499.0);
Money const total_price = std::accumulate(std::begin(items), std::end(items), Money{},
[](Money accu, auto const& item) {
return accu + item->price();
});
// ...
return EXIT_SUCCESS;
}잘 짜여진 코드처럼 보이지만 세율이 변경될 시 코드베이스 전체가 변경되어야한다.
SRP가 변형점을 분리하라고 조언하는 만큼 코드베이스 전체에 정보를 중복하지 않도록 주의해야한다. 모든 것에 책임이 하나(단 하나의 변경 이유)이어야 하는 만큼, 모든 책임은 시스템에 단 한 번 존재해야 한다. 이 아이디어를 반복하지 말 것(DRY) 원칙이라 한다.
너무 이른 관심사 분리를 피한다
SOLID를 달성하려고 하지 말고 SOLID를 사용해 유지보수성을 달성하라
YAGANI 원칙(You aren't gonna need it)은 필요한 것만 할것이라는 원칙이다.
쉬운 변경의 한 측면은 그 변경이 기대하는 행위를 깨뜨지 않는다는 것을 확인할 수 있는 단위테스트(unit test)를 준비하는 것이다.
지침 3: 인터페이스를 분리해 인위적인 결합을 피하라
class Document
{
public:
// ...
virtual ~Document() = default;
virtual void exportToJSON( /* ... */ ) const = 0;
virtual void serialize( ByteStream&, /* ... */) const = 0;
/// ...
};인터페이스를 분리해 관심사 분리하기
void exportDocument(Document const & doc)
{
// ...
doc.exportToJSON(/* 필요한 인자를 전달한다 */);
// ...
}class JSONExportable
{
public:
// ...
virtual ~JSONExportable() = default;
virtual void exportToJSON( /* ... */ ) const = 0;
// ...
};
class Serializable
{
public:
// ...
virtual ~Serializable() = default;
virtual void serialize(ByteStream& bs, /* ... */) const = 0;
// ...
};
class Document : public JSONExportable, public Serializable
{
public:
// ...
};void exportDocument(Document const & exportable)
{
// ...
doc.exportToJSON(/* 필요한 인자를 전달한다 */);
// ...
}템플릿 인자의 요구 사항 최소화하기
ISP가 기초 클래스에만 적용할 수 있는 것처럼 보이고 대부분 객체 지향 프로그래밍을 통해 도입하지만, 인터페이스로 인한 의존성을 최소화하는 일반적인 아이디어는 템플릿에도 적용할 수 있다.
template<typename InputIt, typename OutputIt>
OutputIt copy( InputIt first, InputIt last, OutputIt d_first);C++20에서는 콘셉트(concepts)를 적용해 요구사항을 표현할 수 있다.
template<std::input_iterator InputIt, std::output_iterator OutputIt>
OutputIt copy( InputIt first, InputIt last, OutputIt d_first);std::copy()는 복사할 범위인 입력 반복자(input iterator)와 대상 범위인 출력 반복자(output iterator)쌍을 기대한다.
만약 std::copy()가 std::input_iterator와 std::output_iterator 대신 std::forward_iterator를 요구한다고 가정하면
template< std::forward_iterator ForwardIt >
OutputIt copy( ForwardIt first, ForwardIt last, OutputIt d_first);불행히도 이는 std::copy() 알고리즘의 유용성(usefullness)을 제한한다. 일반적으로 다중 경로 보증(multipass gaurantee)을 하지 않으며 기록할 수 없으므로 더 이상 입력 스트림에서 복사할 수 없다. 의존성에 초점을 맞추면 이제 std::copy()는 필요하지 않은 연산과 요구 사항에 의존한다. 그리고 std::copy()에 전달한 반복자는 추가 연산을 제공하도록 강제되므로 std::copy()는 이 반복자에 대한 의존성을 강제한다.
지침 4: 테스트 용이성을 위한 디자인
비공개 멤버 함수 테스트 방법
다음 updateCollection() 멤버 함수를 어떻게 테스트할까?
class Widget
{
// ...
private:
void updateCollection( /* collection을 갱신하는 데 필요한 인자 */ );
std::vector<Blob> blobs_;
/* 있을 수 있는 다른 데이터 멤버 */
};updateCollection() 멤버 함수를 비공개 구역에 선언했다.
첫 번째 아이디어: updateCollection을 호출하는 공개 함수를 테스트하는 방법
class Widget
{
public:
// ...
void addBlob( Blob const& blob, /* ... */)
{
// ...
updateCollection(/* ... */);
// ...
}
private:
void updateCollection( /* collection을 갱신하는 데 필요한 인자 */ );
std::vector<Blob> blobs_;
/* 있을 수 있는 다른 데이터 멤버 */
};이러한 테스트를 화이트박스 테스트(white box test)라고 한다. 화이트박스 테스트는 어떤 함수의 내부 구현 상세를 알고 그 지식을 바탕으로 테스트한다. 이렇게 하면 테스트 코드가 제품 코드의 구현 상세에 의존한다. 이 접근법의 문제는 소프트웨어가 변한다는 점이다. 코드는 바뀌고 세부내용도 변한다. 예를 들어 미래 어느 시점에 addBlob() 함수를 재작성해 collection을 더 이상 갱신하지 않을 수도 있다. 그러면 해당 테스트는 그렇게 작성한 작업을 더 이상 수행하지 않는다. 심지어 그 사실을 알아채지도 못한 채 updateCollection() 테스트를 잃게 될 것이다. 따라서 화이트박스 테스트는 위험을 품고 있다. 제품 코드에서 의존성을 피하고 줄여야 하는 만큼('지침 1: 소프트웨어 디자인의 중요성을 이해하라' 참고) 테스트와 제품 코드의 세부 내용 간 의존성도 피해야 한다.
블랙박스 테스트(blackbox test)는 내부 구현 상세에 대해 어떤 가정도 하지 않고 예상하는 행위에 대해서만 테스트한다.
아이디어 2: Widget 클래스의 friend class에서 테스트한다.
class Widget
{
// ...
private:
friend class TestWidget;
void updateCollection( /* collection을 갱신하는 데 필요한 인자 */ );
std::vector<Blob> blobs_;
/* 있을 수 있는 다른 데이터 멤버 */
};Widget은 TestWidget의 존재를 몰라야하지만 인위적인 의존성이 추가되었다.
friend는 인위적인 결합을 추가한다. 이것은 피하는 것이 좋다. 패스키(Passkey) 관용구는 숨겨진 프렌드로 사용할 수 있는 관용구이다.
아이디어 3: private를 protected로 변경하고 테스트를 Widget에서 상속받는다.
class Widget
{
// ...
protected:
void updateCollection( /* collection을 갱신하는 데 필요한 인자 */ );
std::vector<Blob> blobs_;
/* 있을 수 있는 다른 데이터 멤버 */
};
class TestWidget : private Widget
{
// ...
};상속이 답인 경우는 드물다.
상속을 사용하여 테스트하는 방법은 public으로 변경하여 테스트하는 방법과 거의 동일하다.
진정한 해결책: 관심사 분리
자유 함수로 분리하는 방법
void updateCollection( std::vector<Blob> blobs,
/* collection을 갱신하는 데 필요한 인자 */ );
class Widget
{
// ...
private:
std::vector<Blob> blobs_;
/* 있을 수 있는 다른 데이터 멤버 */
};클래스로 분리하는 방법
namespace widgetDetails {
class BlobCollection
{
public:
void updateCollection( /* collection을 갱신하는 데 필요한 인자 */ );
private:
std::vector<Blob> blobs_;
};
} // namespace widgetDetails
class Widget
{
// ...
private:
widgetDetails::BlobCollection blos_;
/* 있을 수 있는 다른 데이터 멤버 */
};관심사 분리가 가지는 이점
- Widget의 캡슐화를 강화한다.
- updateCollection 함수를 더 쉽게 테스트 할 수 있다.
- Widget 클래스에서 다른 기능을 추가할 필요가 없다.
지침 5: 확장을 위한 디자인
개방-폐쇄 원칙
class Document
{
public:
// ...
virtual ~Document() = default;
virtual void serialize( ByteStream&, /* ... */) const = 0;
/// ...
};class PDF : public Document
{
public:
// ...
void serialize( ByteStream& bs /*, ... */) const override;
// ...
};enum class
{
pdf,
word,
// ... 있을 수 있는 더 많은 문서 유형
];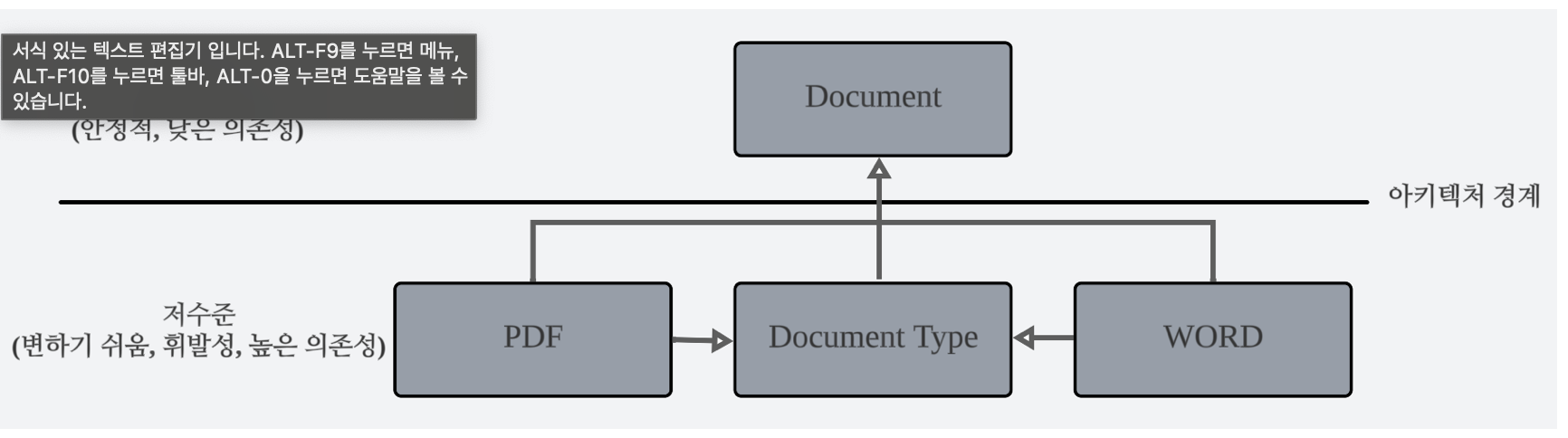
enum class DocumentType
{
pdf,
word,
xml, // 새 문서 유형
// ...
};새로운 DocumentType을 추가하려면 pdf, word 를 다시 컴파일 해야하는 문제가 있다.
개방-폐쇄 원칙
(클래스, 모듈, 함수 등) 소프트웨어 산출물은 확장에는 열려 있지만 수정에는 닫혀 있어야 한다.
컴파일 시점의 기능 확장성
Document 예시는 이런 디자인 고려 사항을 모두 런타임 다형성에 적용한다는 인상을 줄 수 있다. 하지만 동일한 고려 사항과 주장이 컴파일 시점 문제에도 적용된다.
std::swap 알고리즘을 보면, C++11 이후 std::swap()은 다음처럼 정의한다.
namespace std {
tmpplatee <typename T >
void swap( T& a, T& b )
{
T tmp( std::move(a) );
a = std::move(b);
b = std::move(tmp);
}
} // namespace std아이디어 1: 오버로딩
namespace custom {
class CustomType
{
/* 특수한 형태의 swap이 필요한 구현 */
}
void swap( CustomType& a, CustomType& b )
{
/* 'CustomType' 타입인 두 인스턴스를 교환하는 특수한 구현 */
}
} // namespace customtemplate< typename T >
void some_function( T& value )
{
// ...
T tmp( /* ... */ );
using std::swap; // 컴파일러가 후속 호출에 std::swap을 고려하게 한다.
swap( tmp, value ); // 두 값을 교환한다. 한정하지 않은 호출과 ADL 덕분에
//'T'가 'CustomType'일 때 'custom::swap()'을 호출한다.
// ...
}아이디어 2: 템플릿
template< typename InputIt, typename T >
constexpr InputIt find( inputIt first, InputIt last, T const& value );
template< typename InputIt, typename UnaryPredicate >
constexpr InputIt find_if( InputIt first, InputIt last, UnaryPredicate p );아이디어 3: 템플릿 특수화
template <>
struct std::hash<CustomType>
{
std::size_t operator()( CustomType const& v ) const noexcept
{
return /* ... */;
}
};너무 이른 확장을 위한 디자인을 피한다
