Batch : Batch size는 전체 데이터 셋을 나누었을 때 하나의 그룹에 속하는 데이터 수
Epoch : 한 번의 Epoch이라는 것은 전체 데이터 셋에 대해 한 번 학습을 완료한 것
Iteration : 1번의 Epoch을 마치는 데 필요한 parameter 업데이트 횟수 (전체 데이터를 모델에 한번 학습시키는 데 필요한 배치의 수)
Multi-class Classification
Labeling
One-hot Encoding
0과 1만 쓰는 고차원 벡터로 labeling함
Ex) 0부터 9를 labeling할 때 0->[1 0 0 ... 0], 9->[0 0 0 ... 1]
Activation Function
Softmax
Output activation을 Sigmoid로 하면 문제가 생김
=> Sigmoid 대신 Softmax 사용
활성화된 출력 값은 0~1 사이의 값이 되며 전체 출력 값의 합은 1이 됨-> 출력을 '확률'로 해석 가능
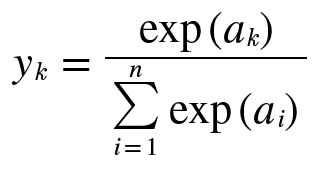
Loss
Cross-Entropy
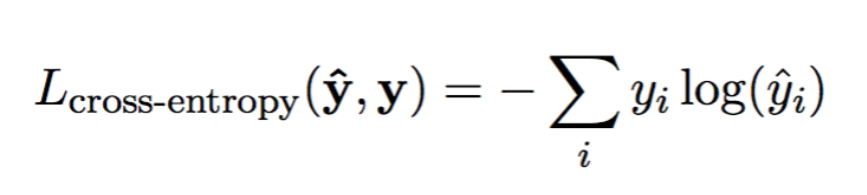
How to Solve the Over & Underfit issue
Regularizer
: cost에 일정 값을 더해서 fit의 시점을 늦추는 방식
: 일반적인 Cost function에 가중치 절댓값을 더해줌
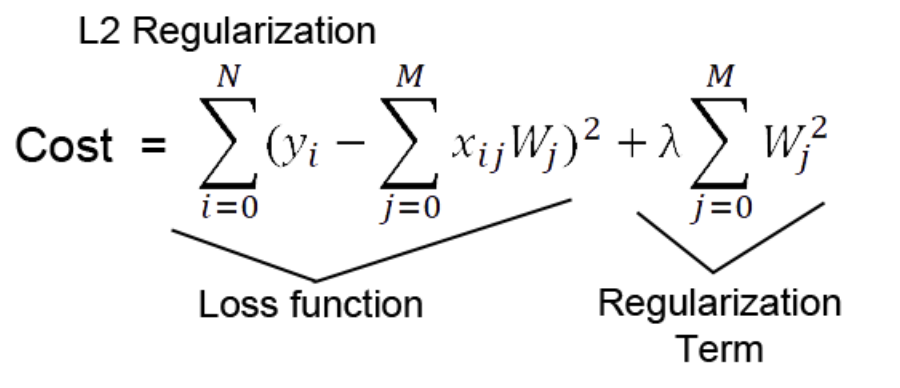
: 일반적인 Cost function에 제곱한 가중치 값을 더해줌. 람다가 클수록 regularization 효과가 큼from tensorflow.keras import regularizers def regularizer_model(): model=Sequential() model.add(Dense(20,'relu',kernel_regularizer=regularizers.l2(0.001)))
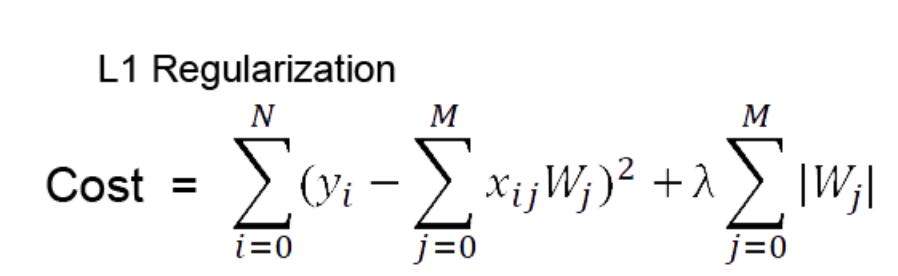
Dropout
: 매 학습마다 설정한 drop rate만큼 random하게 node를 지워서 학습시킴. 매 학습마다 다른 node들이 지워졌다가 복원되었다가를 반복
from tensorflow.keras.layers import Dropout def dropout_model(): model=Sequential() model.add(Dense(units=10, activation='relu')) model.add(Dense(21,'relu')) model.add(Dropout(0.2)) #바로 위의 layer를 dropout #rate: 버릴 unit의 비율 결정
