Scaler
- MinMaxScaler
x-min(x)/max(x)-min(x)
scale을 0과 1 사이로 만들어줌from sklearn.preprocessing import MinMaxScaler mm=MinMaxScaler() mm.fit_transform(data)
- StandardScaler
x-평균/표준편차from sklearn.preprocessing import StandScaler sds = StandardScaler() sds.fit_transform(data)보통 image의 경우에는 MinMaxScaler 사용. 그 외에는 보통 StandardScaler 사용
Initialization
1. Zero Initialization
- 문제점
1) row symmetric
2) vanishing gradient- 해결
W=np.random.randn(shape)*0.012. Random Initialization
-용어
fan-in: 들어오는 layer의 unit 개수
fan-out: 현재 layer의 unit 개수
- 문제점
fan-in이 길수록 -> 출력되는 fan-out의 값이 커짐 -> gradient exploding
fan-in이 짧을수록 -> 출력되는 fan-out의 값이 작아짐 -> gradient vanishing- 해결
fan-in이 클수록 초기화 상수를 작게 설정하면 된다. fan-in에 반비례한 초기화 상수(ex.0.01)를 사용해야 한다.3. Xavier Initialization (Glorot Initialization)
- fan-in과 fan-out을 모두 고려하는 방식
- ReLU 함수에서는 layer별 output이 0 주변에 과도하게 몰릴 수 있어 ReLU 함수에는는 다른 initialization을 사용해야 한다.
4. He Initialization
- fan-in만 고려하는 방식
- ReLU 계열에 특화
Mini Batch
- Mini-Batch: 단일 train iteration에서 gradient descent하는 데에 사용하는 data의 총 개수
(코딩에서는 batch_size라고 씀)- Epoch: data 전체를 train한 횟수
Mini-Batch Gradient Descent
- Batch Gradient Descent: 한 번에 모든 data를 train
- Mini-Batch Gradient Descent: 한 번에 mini-batch씩만 train (코딩에서는 SGD+batch_size 1이상 으로 사용)
- Stochastic Gradient Descent(SGD): 한 번에 1개의 data씩만 train
- batch_size 관련 Tip
- 2의 거듭제곱으로 설정
- batch_size는 클수록 좋다. (Out Of Memory가 일어나지 않을 정도로만) batch size가 클수록 더 정확한 gradient를 계산하는 경향이 있다.
- 대체적으로 최소 32이상으로 설정
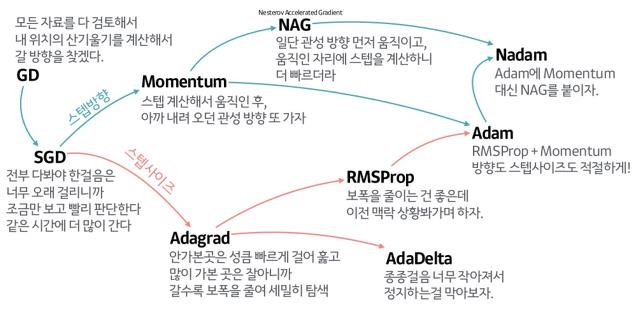
Optimizer
SGD
random하게 추출한 mini-batch씩 gradient descent 진행
단점 : 해당 위치에서의 gradient만 고려한다.
해결책 : 관성
- optimizer의 2가지 계보
- gradient에 관성을 주는 경우
- learning rate에 관성을 주는 경우
sgd=SGD(learning_rate=0.001, momentum=0.9)
대체적으로 Adam이 좋지만 항상 그렇지는 않다.model.compile(optimizer="adam", loss="~~", metrics="~~")