Image Model 학습 with Visdom & CNN
진행 순서
- 나만의 데이터 셋 준비하기
- torchvision.datasets.ImageFolder으로 불러오기
- transforms 적용하여 저장 하기 origin_data -> train_data
- 이번 예제의 모델 : 의자
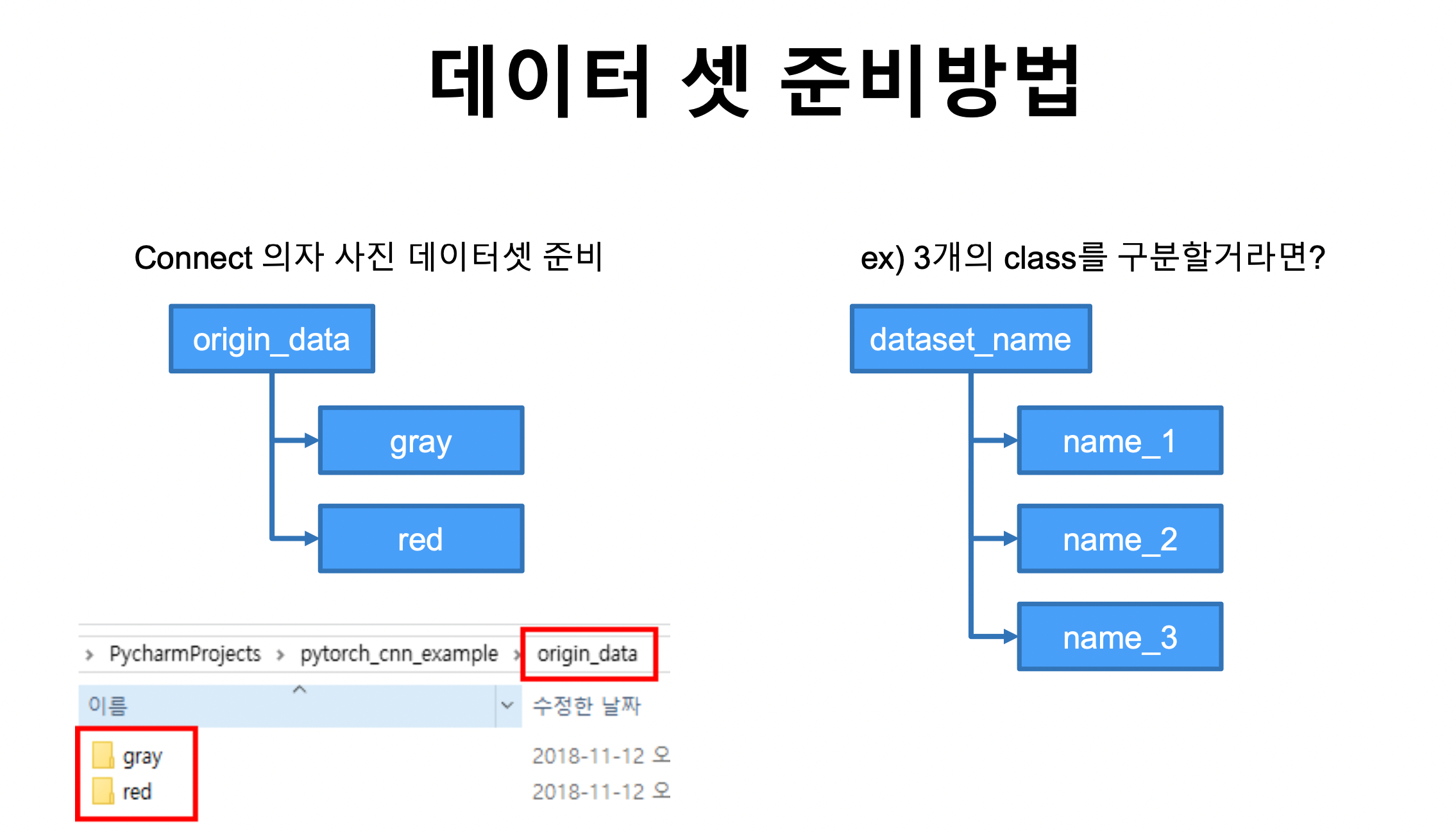
데이터셋 준비 방법 :
- origin_data > gray & red 에 데이터 저장 ( 두개이므로 0과 1로 라벨링)
데이터셋 크기 줄이기
- 데이터 셋이 예시와 같이(512*256)처럼 크기가 클경우 사이즈를 줄여주기도 함
transforms.Compose()과transforms.Resize()를 이용해서 사이즈를 줄여줌

모델 만들기

코드
-
print(shape.out()을 이용해 모델의 그때 그때 사이즈를 체크해줄 수 있음. 사이즈가 헷갈릴 때 디버깅할 수 있는 좋은 방법 -
아래의 코드를 이용해서 학습된 결과를 데이터를 저장하고 불러오는 기능을 제공함. 효율적인 학습과 테스트를 위해서 알아두는게 좋음
torch.save(net.state_dict(), "./model/model.pth")
new_net = CNN().to(device)
new_net.load_state_dict(torch.load('./model/model.pth'))* 전체 소스코드
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
import torchvision
import torchvision.transforms as transforms
device = 'cuda' if torch.cuda.is_available() else 'cpu'
torch.manual_seed(777)
if device =='cuda':
torch.cuda.manual_seed_all(777)
trans = transforms.Compose([
transforms.ToTensor()
])
train_data = torchvision.datasets.ImageFolder(root='./custom_data/train_data', transform=trans)
data_loader = DataLoader(dataset = train_data, batch_size = 8, shuffle = True, num_workers=2)
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(3,6,5),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.layer2 = nn.Sequential(
nn.Conv2d(6,16,5),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.layer3 = nn.Sequential(
nn.Linear(16*13*29, 120),
nn.ReLU(),
nn.Linear(120,2)
)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.view(out.shape[0], -1)
out = self.layer3(out)
return out
#testing
net = CNN().to(device)
test_input = (torch.Tensor(3,3,64,128)).to(device)
test_out = net(test_input)
optimizer = optim.Adam(net.parameters(), lr=0.00005)
loss_func = nn.CrossEntropyLoss().to(device)
total_batch = len(data_loader)
epochs = 7
for epoch in range(epochs):
avg_cost = 0.0
for num, data in enumerate(data_loader):
imgs, labels = data
imgs = imgs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
out = net(imgs)
loss = loss_func(out, labels)
loss.backward()
optimizer.step()
avg_cost += loss / total_batch
print('[Epoch:{}] cost = {}'.format(epoch+1, avg_cost))
print('Learning Finished!')
torch.save(net.state_dict(), "./model/model.pth")
new_net = CNN().to(device)
new_net.load_state_dict(torch.load('./model/model.pth'))
print(net.layer1[0])
print(new_net.layer1[0])
print(net.layer1[0].weight[0][0][0])
print(new_net.layer1[0].weight[0][0][0])
net.layer1[0].weight[0] == new_net.layer1[0].weight[0]
trans=torchvision.transforms.Compose([
transforms.Resize((64,128)),
transforms.ToTensor()
])
test_data = torchvision.datasets.ImageFolder(root='./custom_data/test_data', transform=trans)
test_set = DataLoader(dataset = test_data, batch_size = len(test_data))
with torch.no_grad():
for num, data in enumerate(test_set):
imgs, label = data
imgs = imgs.to(device)
label = label.to(device)
prediction = net(imgs)
correct_prediction = torch.argmax(prediction, 1) == label
accuracy = correct_prediction.float().mean()
print('Accuracy:', accuracy.item())

사회적 가치를 실현하는 프로그래머