크롤링데이터를 저장한 csv파일을 mysql 데이터베이스에 넣어보자.
우선 csv에있는 데이터를 mysql로 넣기 위해서는 csv의 데이터성격과 mysql의 데이터 필드 타입을 확인해야한다.
csv파일 정리
데이터베이스 테이블의 필드타입 확인을 위해서 models.py를 확인해보자
class Product(models.Model):
name = models.CharField(max_length = 45, unique = True)
price = models.CharField(max_length = 50, null = True)
description = models.CharField(max_length = 1000, null = True)
small_image = models.CharField(max_length = 2000, null = True)
big_image = models.CharField(max_length = 2000, null = True)
energy = models.CharField(max_length = 10, null = True)
carbonydrate = models.CharField(max_length = 10, null = True)
protein = models.CharField(max_length = 10, null = True)
fat = models.CharField(max_length = 10, null = True)
mineral = models.CharField(max_length = 100, null = True)
vitamin = models.CharField(max_length = 100, null = True)
is_in_stock = models.BooleanField(default = True)
is_on_sale = models.BooleanField(default = False)
harvest_year = models.ForeignKey('HarvestYear', on_delete = models.SET_NULL, null = True)
measure = models.ForeignKey('Measure', on_delete = models.SET_NULL, null = True)
recipe = models.ForeignKey('Recipe', on_delete = models.SET_NULL, null = True)
similar_product = models.ManyToManyField('self', through = 'SimilarProduct', symmetrical = False)
bundle = models.ManyToManyField('Bundle', through = 'ProductBundle')
class Meta:
db_table = 'products'
csv필드의 데이터는 string으로 되어있기 때문에 위의 모델에서 고려해야 할 사항은 테이터타입이 BooleanField, ForeignKey 인 경우이다.
다행히도 정수형태의 데이터타입은 정수형태 그대로 데이터베이스에 들어가기 때문에 BooleanField는 0(False)또는 1(True)로 표시하고, ForeignKey가 들어가야하는 필드도 정수를 넣어준다.
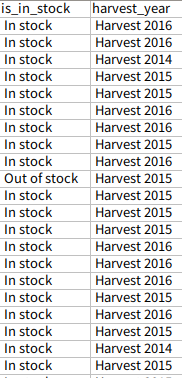
하지만 실제로 데이터를 가져올 때 is_in_stock또는 harvest_year의 경우 0또는 1로 가져오는것이 아닌 실재 string으로 데이터를 가져온다.
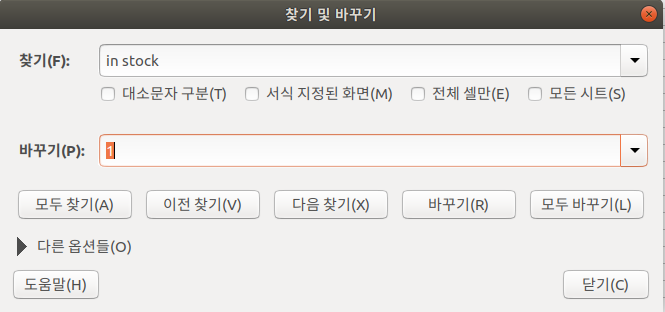
때문에 excel의 찾아바꾸기 기능을 통해서 is_in_stock은 0또는1, harvest_year는 HarvestYear모델의 id값으로 바꾸어준다.(id값을 넣어주는 경우 데이터베이스에 정참조하는 필드의 객체가 들어가있어야 한다.)
bulk_create
import csv
from products.models import *
with open('./realfinal.csv') as csv_file:
... data = csv.reader(csv_file)
... print(data)
<_csv.reader object at 0x7f76e72329e8>
shell로 이동해서 만든 csv파일을 open으로 열어준다. 그리고 as csv_file로 변수설정을 해준다.
csv_file변수를 read한 인스턴스 data를 생성하고 프린트를 해보면 csv를 읽어온 객채가 생성되었음을 알 수 있다.
>>> bulk_list = []
>>> with open('./foodlyCSV.csv') as csv_file:
... data = csv.reader(csv_file)
... for row in data:
... bulk_list.append(Product(name = 'ddd', description = 'ddd'))data(csv파일을 읽어온)의 row의 갯수만큼
이제 빈리스트를 만들어주고 그 빈 리스트에 Product테이블에 객체로서 들어갈 값을 넣어준다. 이제 data테이블의 하나의 row에 Product테이블의 객체가 들어간 상태로 bulk_list에 리스트 형식으로 담긴 상태이다.
>>> print(bulk_list)
[<Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>, <Product: Product object (None)>]
bulk_list에 Product테이블의 객체가 row의 갯수만큼 들어갔음을 확인 할 수 있다.
Product.objects.bulk_create(bulk_list)bulk_list를 bulk_create에 넣고 실행해준다.
이제 mysql 테이블을 확인해보자.
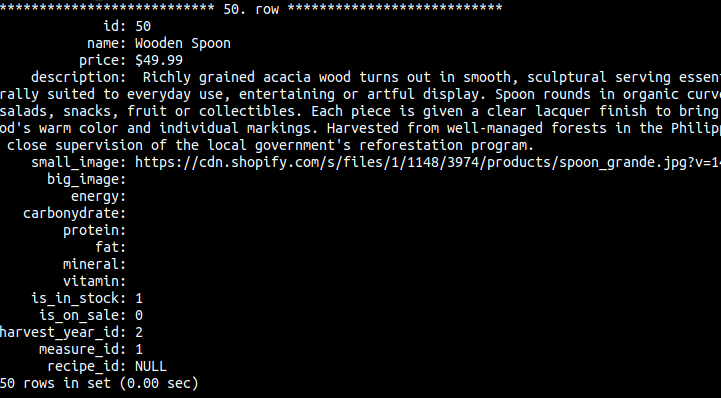
50개의 csv파일에 있는 row가 전부 mysql데이터베이스에 성공적으로 들어갔다.
다량의 데이터 업데이트하기
bulk_create도중 하나의 필드값을 실수로 빼고 넣은 경우 그 필드에는 null이 들어가게 된다. 이 경우 이미 들어간 데이터는 유지하고 null값만 업데이트 해 줄 필요가 있다.
import csv
from products.models import *
bulk_list=[]
with open('./foodlyCSV.csv') as csv_file:
data = csv.reader(csv_file)
for row in data:
bulk_list.append(Product(price=row[5]))
우선 bulk_list에 값을 넣어서 리스트를 만들어준다. bulk_list에는 Product테이블에 big_image2필드에 row[5]가 들어간 객체가 리스트형태로 들어간다.
>>> for i in range(1,Product.objects.all().count()):
... Product.objects.filter(id=i).update(price=bulk_list[i-1].big_image2)이제 1부터 Product테이블의 객체 갯수만큼 for문을 걸어주고 id필터링을 1부터 객체 갯수만큼 걸어준다.
>>> bulk_list[2].price
'3.48'
bulk_list의 객체하나를 뽑아서 값을 확인하면 위와 같이 들어간 값을 확인할 수 있다. 이제 이값을 update매서드에 넣어주면 된다.
>>> Product.objects.values('price')
<QuerySet [{'price': '2.00'}, {'price': '3.00'}, {'price': '3.48'}, {'price': '3.48'}, {'price': '2.29'}, {'price': '2.95'}, {'price': '6.99'}, {'price': '8.05'}, {'price': '1.80'}, {'price': '12.00'}, {'price': '11.00'}, {'price': '6.95'}, {'price': '3.74'}, {'price': '6.90'}, {'price': '2.98'}, {'price': '16.80'}, {'price': '1.99'}, {'price': '7.50'}, {'price': '2.89'}, {'price': '9.39'}, '...(remaining elements truncated)...']>
값이 성공적으로 update되었음을 확인 할 수 있다.
