현재 진행중인 프로젝트인 foodly-store의 상품페이지를 크롤링해보자.(BeatifulSoup 라이브러리 사용법을 자세하게 설명하진 않는다.)
크롤링(Crawling)
상품에 해당하는 정보는 전체상품페이지, 상품하나를 클릭하고 들어가서 나오는 페이지에서 확인할 수 있다.
여기서는 전체상품페이지에서 상품 이름(name), 수확년도(harvest_year), 단위(measure), 재고여부(is_in_stock)을 가져오고, 하나의 상품페이지에 들어가서 필요한 정보를 가져와보자.(중복되는 방법의 데이터 크롤링에 대해서는 코드로서 언급하지 않음)
import requests, csv, re
from bs4 import BeautifulSoup
import pandas as pd크롤링에 필요한 라이브러리, csv, 정규식 re를 import한다.
그리고 csv저장을 위해서 pandas라이브러리도 불러온다.
# empty list set to add new column
mCols = []
df = pd.DataFrame(columns=mCols)그리고 csv파일에 들어갈 column을 리스트로 만들어준다. 지금상태에서는 컬럼이 추가되지 않은 상태이기 때문에 빈 리스트를 설정해주고 pandas 객체를 통해 DataFrame을 만들어 인스턴스화 한다.
# space deleteing function
def re_palce(tag):
pattern = re.compile(r'\s+')
sentence = re.sub(pattern, ' ', tag)
return sentence크롤링 데이터에 공백을 없애주는 함수를 정규식을 이용해 생성해준다.
# set empty list waiting for appending
descs = []
prices = []
titles = []
small_imgs = []
big_imgs = []
harvest_year = []
is_in_stock = []
measures = []
vitamins = []
minerals = []
energys = []
carbonhydrates = []
fats = []
proteins = []각각의 데이터를 담을 빈 리스트를 생성해준다.
# access from first page to last page
last_page = 6
for i in range(1,last_page):
url = f'https://foodly-store.myshopify.com/collections/all-products?page={i}'
html = requests.get(url).text
soup = BeautifulSoup(html, 'html.parser')전체 for문을 통해서 페이지별 접근을 한다.
c=soup.select('div.product__info > span')
for i in range(0,len(c)):
>> "2016|
In stock|
kg"
selector값을 가져와보면 여러데이터거 하나의 스트링으로 묶여있고 불필요한 엔터와 띄워쓰기가 되어있다.
# unnecessary indent remover
sense = re_palce(c[i].text).split('|')처음에 정의했던 re_place함수를 통해서 불필요한 엔터와 띄워쓰기를 없애준다. '|'을 기준으로 문자열을 나누어 리스트에 담아주고 변수지정을 해준다.
try:
harvest_year.append(sense[0])
is_in_stock.append(sense[1])
measures.append(sense[-1])
except:
harvest_year.append('')
is_in_stock.append('')
measures.append('')리스트안의 데이터를 인댁싱해서 위에서 정의해주었던 빈리스트에 넣어준다. 값이 없으면 빈 값을 추가한다.
# get prodcut deatail page url
d = soup.select('div.product__info > h4 > a')
unit_urls = ['https://foodly-store.myshopify.com'+d[i]['href'] for i in range(len(d))]이제 해당 상품의 상품상세페이지로 가는 url을 가져와 리스트에 담는다.
# access to each and every product detail page
for i in unit_urls:
html = requests.get(i).text
soup = BeautifulSoup(html, 'html.parser')리스트에 담긴 url을 하나하나 타고들어가기 위해 for문을 사용한다.
# get energy info
try:
energy = soup.select_one('li > span > strong')
energys.append(energy.text)
except:
energy = ''
energys.append(energy)상품 상세정보안의 에너지 정보를 selector을 통해서 가져오고 값이 있으면 객체의 text를 enegys리스트에 추가한다. 만약 값이 없다면 text를 가져올 때 에러가 생기기 때문에 except처리를 해주어서 빈값을 energys리스트에 넣도록 설정한다.
pandas를 사용해 csv로 저장
# put values in each list to created column to data frame
df['titles'] = titles
df['prices'] = prices
df['descs'] = descs
df['small_imgs'] = small_imgs
df['big_imgs'] = big_imgs
df['energys'] = energys
df['carbonhydrates'] = carbonhydrates
df['proteins'] = proteins
df['fats'] = fats
df['minerals'] = minerals
df['vitamins'] = vitamins
df['is_in_stock'] = is_in_stock
df['harvest_year'] = harvest_year
df['measures'] = measures위에서 정의해주었던 DataFrame에 컬럼을 추가하고 가져온 데이터를 담은 list를 value로서 넣어준다.
# change data frame to .csv file
df.to_csv("./realfinal.csv", encoding='utf8')DataFrame에 들어간 데이터를 csv파일로 만들어준다.
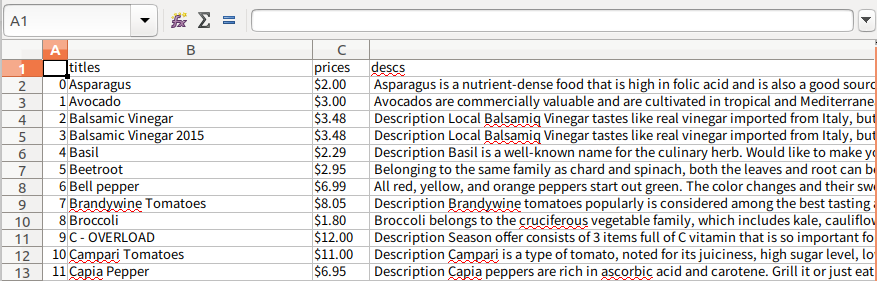
설정해준 컬럼이 생성되고, id가 자동으로 생성 되었음을 확인 할 수 있다.

독학으로 코딩 공부하고 있는 완전 비전공자 입니다. 다들 스크래핑 하고 나서 그 데이터를 print만 하고 끝내더라구요 ㅠㅠ.. for문 돌면서 한줄씩 데이터를 쏟아내는데 그걸 합쳐서 써먹으려고 했는데 어떻게 합치는 지를 몰라서 거의 4시간 넘게 구글링 하다가 여기서 해결하고 갑니다ㅎㅠㅠㅠ... 감사합니다. ===>각각의 데이터를 담을 빈 리스트를 생성해준다.<=== 이부분이 너무 도움되었어요 !! 천재신거 같아요. 다시 한번 감사드립니다. 좋아요도 누르고 가요~