지금까지 불편한 점은?
- 코드를 하나씩 실행하다보면 혼돈이 크다
- Jupyter Notebook 상황에서 데이터의 전처리와 여러 알고리즘의 반복실행, 하이퍼 파라미터의 튜닝을 과정을 번갈아 하다 보면 코드의 실행 순서에 혼돈이 있을 수 있다.
- 이런 경우 Class로 만들어 진행해도 되지만 sklearn에는 Pipeline이라는 기능이 있다.
import pandas as pd
red_wine = pd.read_csv('./data/winequality-red.csv', sep=';')
white_wine = pd.read_csv('./data/winequality-white.csv', sep=';')
red_wine['color'] = 1
white_wine['color'] = 0
wine = pd.concat([red_wine, white_wine])
X = wine.drop(['color'], axis=1)
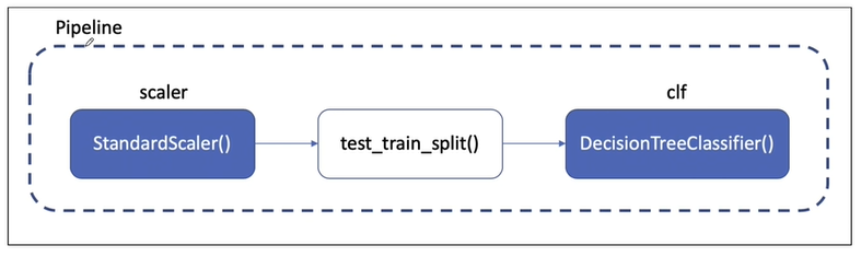
y= wine['color']레드/화이트 와인 분류기의 동작 Process
-
여기서 test_train_split은 Pipeline 내부가 아니다.
이 Pipeline을 코드로 구현한다면?
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [('scaler', StandardScaler()),
('clf', DecisionTreeClassifier())]
pipe = Pipeline(estimators)pipe.steps
#output:
[('scaler', StandardScaler()), ('clf', DecisionTreeClassifier())]
# setparams를 이용해 파라미터를 바꿀 수 있다
pipe.set_params(clf__max_depth=2)
pipe.set_params(clf__random_state=42)
# '스탭이름' + __(언더바 2개) + 속성이름 - Pipeline을 이용한 분류기 구성
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
pipe.fit(X_train, y_train)
from sklearn.metrics import accuracy_score
y_pred_tr = pipe.predict(X_train)
y_pred_test = pipe.predict(X_test)
print('Train Acc : ', accuracy_score(y_train, y_pred_tr))
print('Test Acc : ', accuracy_score(y_test, y_pred_test))
# output:
Train Acc : 0.9545891860688859
Test Acc : 0.9584615384615385