우리가 만든 모델은 얼마나 좋은 것일까?
-
데이터 수집/가공/변환 ↔ 모델학습/예측 ↔ 평가
-
모델을 좋다, 그저그렇다, 나쁘다 등으로 평가할 방법은 없다.
-
대부분 다양한 모델, 다양한 파라미터를 두고, 상대적으로 비교한다.
-
회귀모델들은 실제 값과의 error를 가지고 계산
-
분류 모델은 평가 항목이 조금 많음
| 오차행렬 | Confusion Matrix |
| 정밀도 | Precision |
| 재현율 | Recall |
| F1 score | - |
| ROC AUC | - |
- 이진 분류 모델의 평가
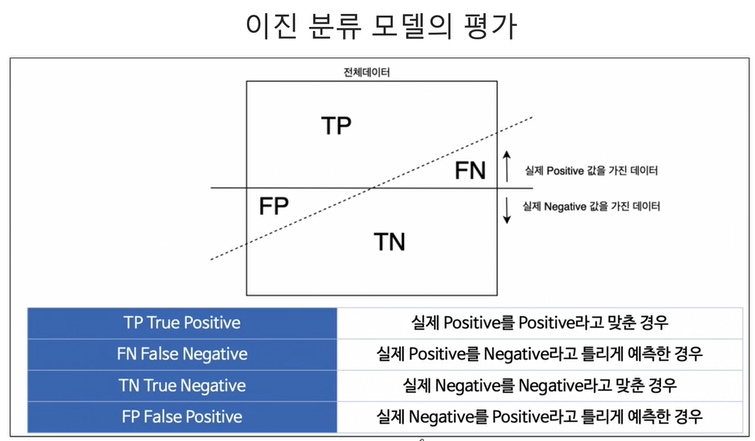
- FP는 type 1 error FN은 type 2 error이고 정확도는 아래와 같다. (전체 데이터 중 맞게 예측한 것의 비율)
- Precision : 양성이라고 예측한 것 중에서 실제 양성의 비율
- 정밀도를 높이려면 확실할 때만 정답이라고 하면 됨
- Threshold를 높게 설정하면됨
- 대표적 예시 : 중요한메일을 스팸메일이라고 예측하면 안됨, 그럴 떄 봐야하는게 Precision
-
Recall(TPR, True Positive Ratio, sensitivity) : 참인 데이터들 중에서 참이라고 예측한 것
-
싹다 참이라고 말하면 올라감
-
Threshold를 낮게 설정하면됨
-
대표적 예시 : 암인 환자를 암이라 맞출확률을 볼 때
-
- Fall-Out(FPR, False position ratio) : 실제 양성이 아닌데, 양성이라고 잘못 예측한 경우
분류모델은 그 결과를 속할 비율(확률)을 반환한다
- predict_prob는 0.5를 기준으로 작으면 0 크면 1을 반환
- 기준이되는 0.5를 threshold라고 함.
- Recall과 Precision은 서로 영향을 주기 때문에 한 쪽을 극단적으로 높게 설정하면 안됨.
F1- Score

- 조화평균임 !
ROC 와 AUC
- ROC 곡선
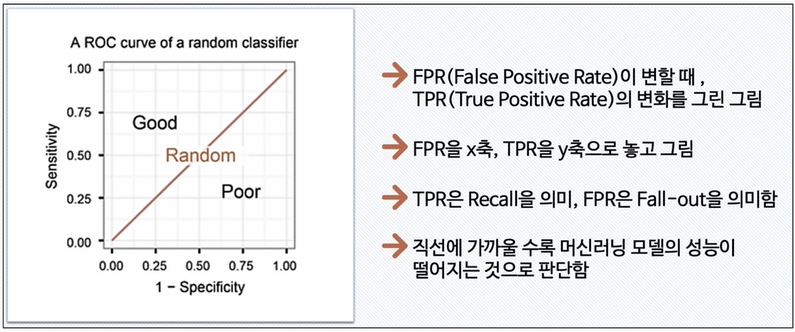
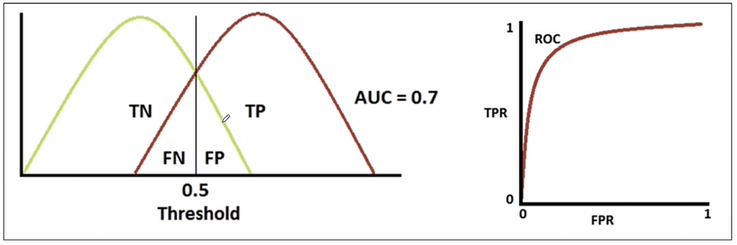
- fall-out이 여러개라면 recall값이 작은걸 선택해서 그림
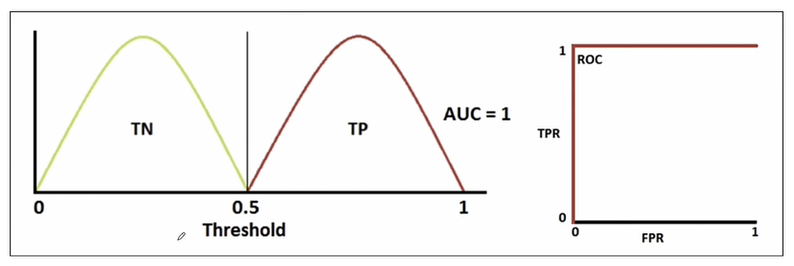
- 완벽하게 분류했다면 아래와 같은 곡선을 그림, AUC는 그래프의 면적을 뜻함
- 적당히 맞췄다면 아래와 같은 곡선이 나타난다