Label-encoder
- 사이킷런에서 라벨은 숫자여야함
- label Encoder란?
- 문자를 숫자로 바꿔줌
import pandas as pd
df = pd.DataFrame({
'A' : ['a', 'b', 'c', 'a', 'b'],
'B': [1, 2, 2, 1, 0]
})
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(df['A'])
# df 의 A컴럼기준으로 fit
le.classes_
le.transform(df['A'])
# output : array([0, 1, 2, 0, 1])
df['le_A'] = le.transform(df['A'])
- fit과 transform을 한번에 실행
le.fit_transform(df['A'])
> output : array([0, 1, 2, 0, 1])
# 해당 문자가 어떻게 바뀌었는지 알려줌
le.transform(['a'])
# output : array([0])
# 역으로 원래 라벨을 보여줌
le.inverse_transform(df['B'])
> output : array(['b', 'c', 'c', 'b', 'a'], dtype=object)min-max scaler
-
min-max scaling 이란?
서로 다른 크기를 통일하기 위해 크기를 변환하는 개념, 여기는 최소를 0 최대를 1로 변환
원데이터 분포를 유지하면서 정규화, outlier에 대응 잘 안됨
의미 : 전체길이로 나눠준다 !
💍 레이텍 분수 사용법 {X\over\Y}
df = pd.DataFrame({
'A':[10, 20, -10, 0 ,25],
'B':[1, 2, 3, 1, 0]
})
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
mms.fit(df)
df_mms = mms.transform(df)
df_mms
# output :
array([[0.57142857, 0.33333333],
[0.85714286, 0.66666667],
[0. , 1. ],
[0.28571429, 0.33333333],
[1. , 0. ]])
# 역변환
mms.inverse_transform(df_mms)
# output:
array([[ 10., 1.],
[ 20., 2.],
[-10., 3.],
[ 0., 1.],
[ 25., 0.]])
# 한번에 적용
mms.fit_transform(df)Standard Scaler
- 표준정규분포를 사용하여 표준화 시킴!
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(df)
# 평균과 표준편차
ss.mean_, ss.scale_
# transform
df_ss = ss.transform(df)
df_ss
# output :
array([[ 0.07808688, -0.39223227],
[ 0.85895569, 0.58834841],
[-1.48365074, 1.56892908],
[-0.70278193, -0.39223227],
[ 1.2493901 , -1.37281295]])
# 한번에 하기
ss.fit_transfrom(df)
Robust Scaler
- 중간값(median)과 사분위수를 이용한 스케일 방법
- 이상치에 강하게 대응 가능!
df = pd.DataFrame({
'A':[-0.1, 0., 0.1, 0.2, 0.3, 0.4, 1.0, 1.1, 5.0]
})
# 해당 df를 다 스케일 해보자!
from sklearn.preprocessing import MinMaxScaler, StandardScaler, RobustScaler
mm = MinMaxScaler()
ss = StandardScaler()
rs = RobustScaler()
df_scaler = df.copy()
df_scaler['MinMax'] = mm.fit_transform(df)
df_scaler['Standard'] = ss.fit_transform(df)
df_scaler['Robust'] = rs.fit_transform(df)
df_scaler
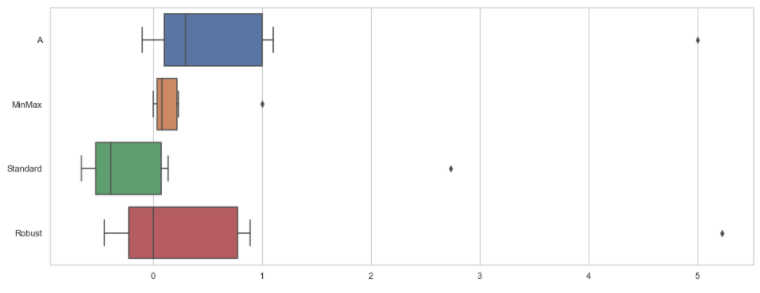
- MinMax는 이상치에 많은 영향을받아 이상치가 있는 데이터에 적합하진 않음
- Standard도 ...
- Robust는 이상치에 잘 대응
