
Zhang, Juyong, Keyu Chen, and Jianmin Zheng. "Facial expression retargeting from human to avatar made easy." IEEE Transactions on Visualization and Computer Graphics 28.2 (2020): 1274-1287.
1.Research Background & Problem Definition
Facial expression retargeting from humans to virtual characters is a useful technique in computer graphics and animation. Traditional methods use markers or blendshapes to construct a mapping between the human and avatar faces. However, these approaches require a tedious 3D modeling process, and the performance relies on the modelers’ experience.
Facial expression
얼굴 근육의 움직임으로 유발되어지는 비언어적, 감정 전달의 수단
Facial expression retargeting
얼굴 표현을 하나의 도메인에서 다른 도메인으로 전달하는것
Traditional method
기존 retargeting 방법들의 고질적인 문제점 : 전문적인 기술이 필요하고, 비용과 시간이 많이 소요된다는 점
markers

blendshapes
블렌드쉐입은 무표정의 베이스쉐입(base shape)의 형상을 변형시켜 다른 표정의 타겟쉐입(targetshpae)을 생성하고, 두 형상간의 선형보간을 통해 새로운 얼굴 표정을 합성하는 기술이다
참고
Research Purpose
Extensive experimental results and user studies demonstrate that even nonprofessional users can apply our method to generate high-quality facial expression retargeting results with less time and effort.
적은 비용과 노력으로 비전문가도 좋은 품질의 페이스 리펙토리 결과물을 얻을 수 있는 방법을 개발하고자 한다.
2.Related Work
2.1)Blendshape base Representation
Different from these blendshapebased approaches, our work trains an embedding network with randomly generated data, which represents facial expressions in a nonlinear manner.
블렌드 쉐이프 표현 방법은 애니메이션 및 영화 산업에서 널리 사용되는 기술로써 베이스와 타겟의 선형보간을 통해 새로운 얼굴 표현을 생성하는 기술입니다. 하지만 텍스쳐를 구현하는것에 있어 많은 경험과 시간이 필요한 것이 단점입니다
대표적인 예시로써 Autodesk MAYA, 3DS Max 등이 있다.
2.2)Mesh Deformation Transfer

Mesh deformation transfer 는 베이스 오브젝트에 발생한 변형을 타겟 오브젝트에 전달하는 대응 관계를 만드는 기술입니다. 베이스와 타겟의 모양이 크게 달라질 경우 변형을 전달하는 대응관계가 생성되지 않을 수도 있습니다.
애니메이션 분야에서 기존에 사용되어지는 변환 방법으로는 controllable interactive editing, contact-aware transfer, dynamic modeling 등이 있습니다.
source와 target 간의 변환이 자동으로 이루어지므로 low cost 작업이라고 할 수 있지만, source와 target의 모양이 기하학적으로 다른 경우(디테일한 부분에서) 변형의 1:1 대응이 실패할 가능성이 존재합니다.
2.3)Deep Learning for Face Analysis
With deep learning tools, a nonlinear representation model can be trained for 3D faces by using a variational autoencoder
얼굴 분석에 딥러닝을 사용하려는 시도는 많은 관심을 받고 있으며, 3D 얼굴 표현을 학습함에 있어 기존에 사용하던 PCA 모델보다 강력한 표현력을 가진 VAE 네트워크가 제안되었습니다.
3.Overview
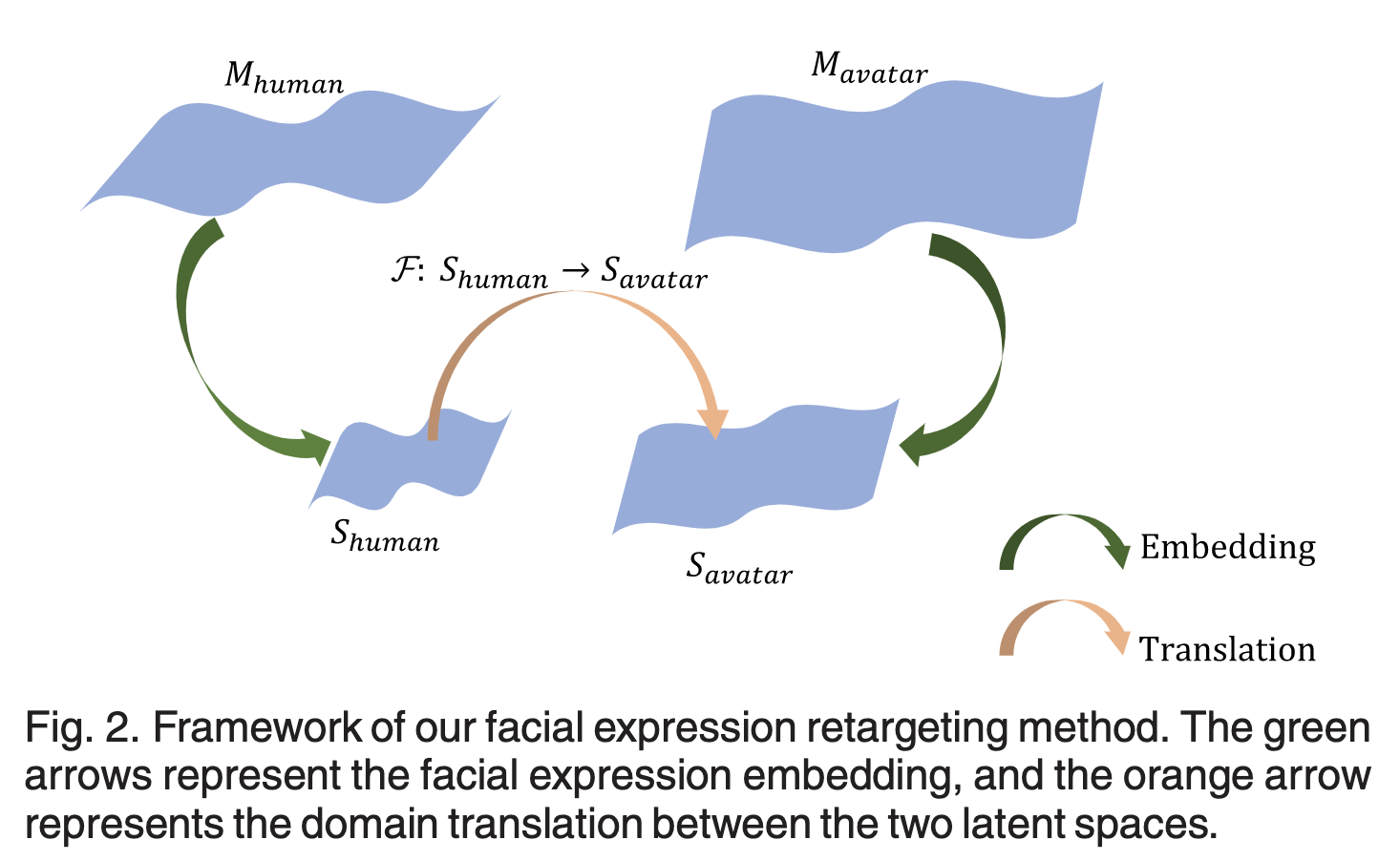
Framework of our facial expression retargeting method. The green arrows represent the facial expression embedding, and the orange arrow represents the domain translation between the two latent spaces.
본 논문의 목표는 주워진 사람의 표정(M human)을 아바타의 표정(M avater)로 맵핑하는것이다.
이를 달성하기 위해 M human과 M avater를 저차원으로 임베딩(S human,S avater)하는 과정(3.1)과
두 embed space를 변환하는 함수(3.2)가 필요하다.
3.1)Facial Expression Embedding
블랜드쉐이프 기반 모델을 사용해 얼굴 표현을 쉽게 저차원 embed space으로 만들 수 있지만, 두가지 단점이 존재한다. 우선 블랜드쉐이프 모델은 주워진 선형변환 이상의 변화를 표현하기가 어렵다.(이를태면 과도한 과장이나 표정이 생략될경우) 다음으로 사람의 얼굴 모양을 블랜드쉐이프 모델로 만드려는 과정을 자동화 하는 시도들이 있었음에도 불구하고 여전히 많은 비용과 시간이 소모된다.
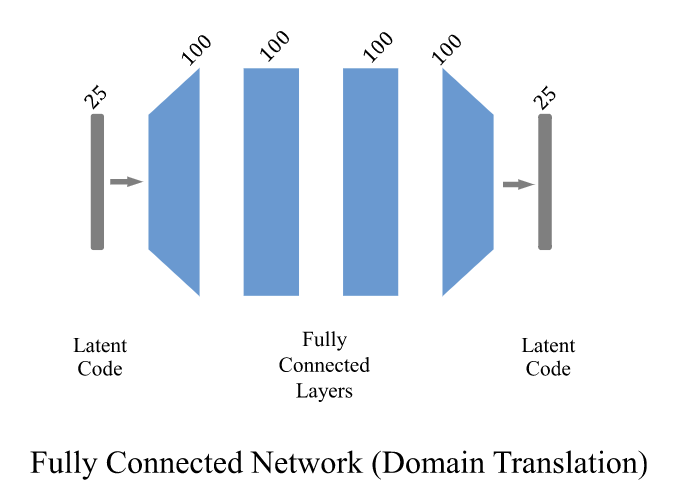
3.2)Expression Domain Translation
embed space를 변환하는 과정에서 고려해야하는 두가지 사항이 있다.
- Geometric consistency constraint: The original andretargeted expressions should have similar local geo-metric details.
- Perceptual consistency constraint: The original andretargeted expressions should have similar seman-tics according to human visual perception.
1.변환된 메트릭스(embed space)들은 기하학적인 관점에서 지역적인 유사성을 지니고있어야 한다.
2.원래의 표현과 리타겟팅된 표현은 인간의 시각적 인식에 따라 유사한 의미를 가져야 합니다.
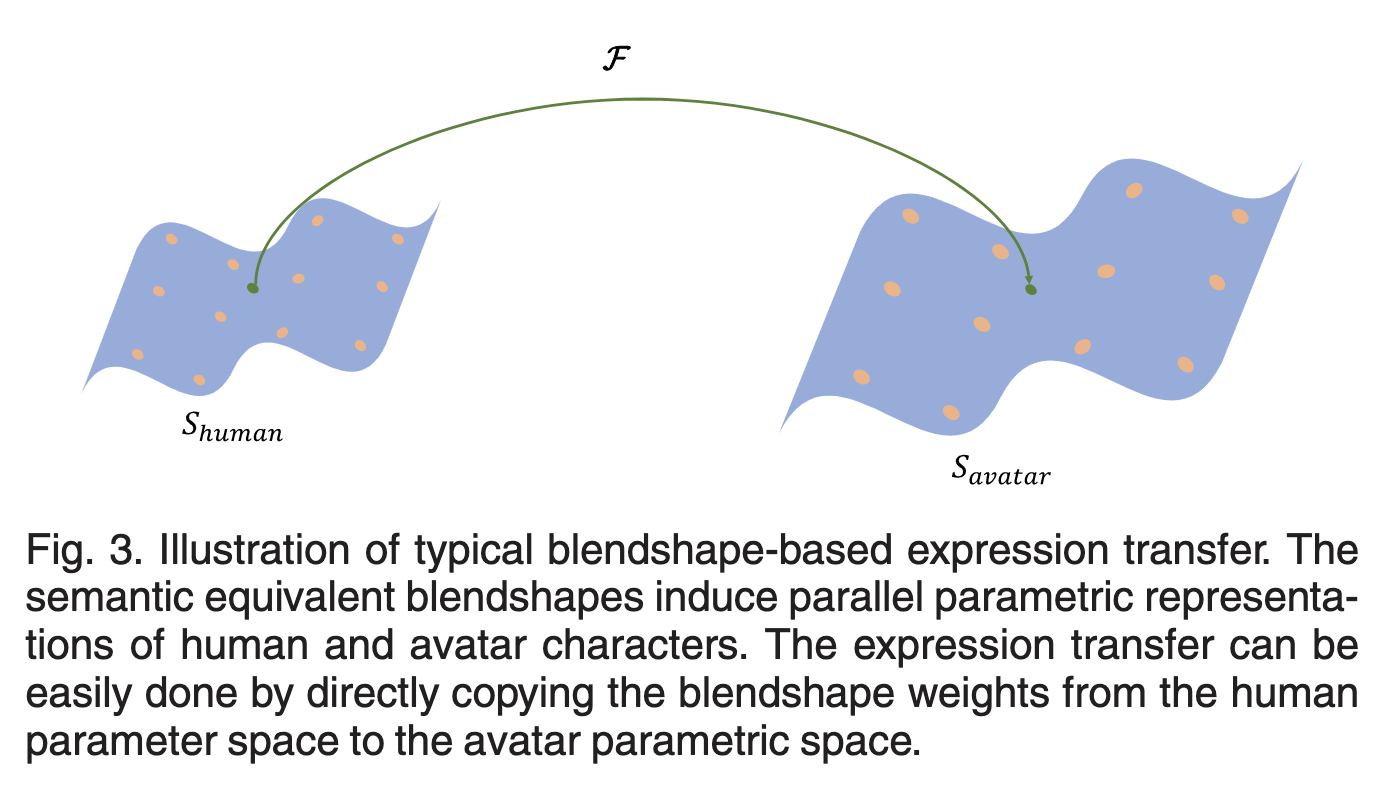
한 가지 접근 방식은 일반적으로 캐릭터 애니메이션에 사용되는 소스와 대상 캐릭터 간의 대응으로 두 그룹의 병렬 블렌드 셰이프를 만드는 것입니다. 기본 의미론적 동등성을 사용하면 그림 3과 같이 블렌드 모양 가중치가 소스 매개변수 공간에서 대상 매개변수 공간으로 직접 복사됩니다. 그러나 사람 참조에 해당하는 아바타 블렌드 모양을 만드는 것은 노동 집약적이며 전문가에게도 높은 기술이 필요합니다. 애니메이터. 또한 리타게팅 결과의 품질은 애니메이터의 미적 취향에 달려 있습니다.
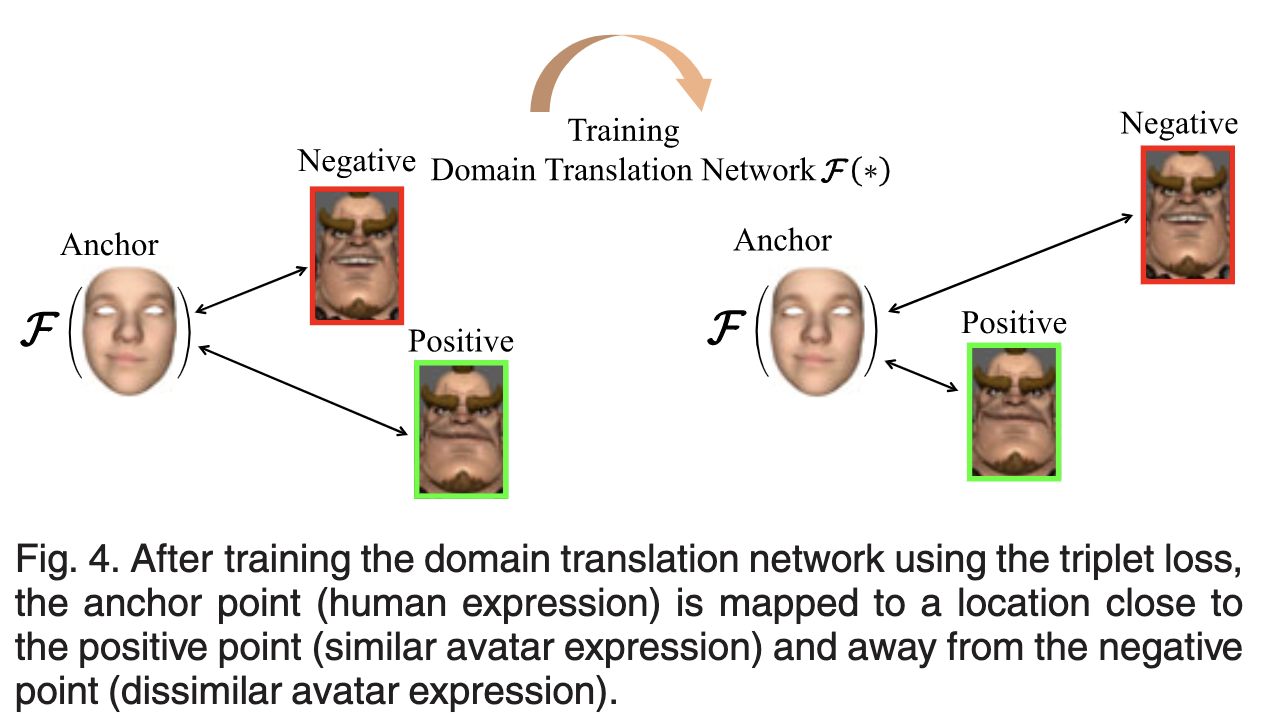
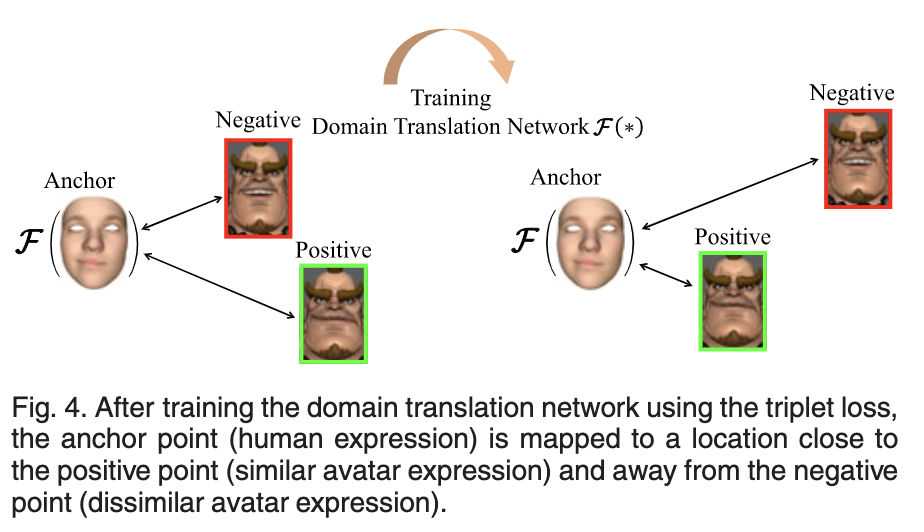
이러한 문제를 극복하고자 논문에서는 Triplet Loss을 사용하여 domain transladtion network를 훈련시켰다.
Facenet: A unified embedding for face recognition and clustering
Triplet Loss는 2015년 CVPR에서 발표한 논문인 FaceNet에서 제안한 Loss 로써 임베딩된 값들의 유클리드 거리를 구해 그림과 같이 Anchor와 Positive의 거리는 가까워지고 Negative와의 거리는 멀어지도록 만드는 Loss 입니다. 본 논문에서는 이를 하나의 얼굴 표현에 대하여 두가지 아바타 표현을 조합하여 만든 anno 방식으로 활용하여 도베인 변역 네트워크를 유저가 두가지의 아바타 표현중 더 유사한(Positive) 아바타로 변역할 수 있도록 학습시켰습니다.
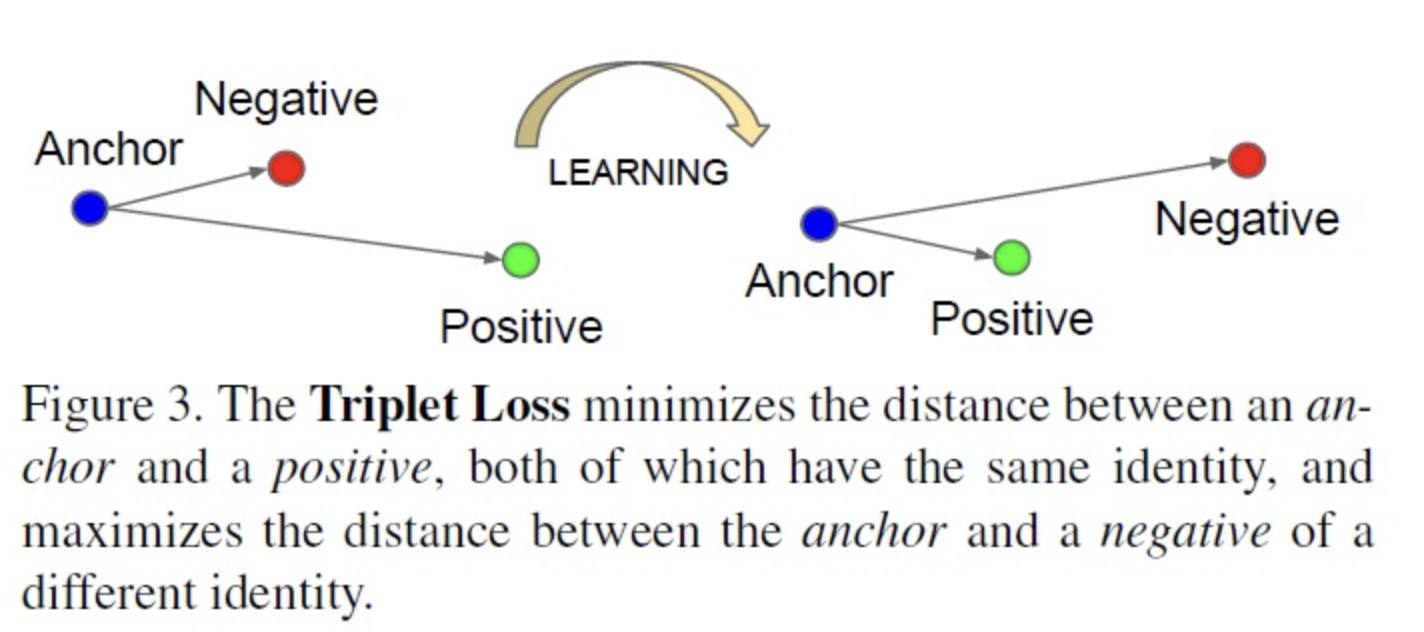
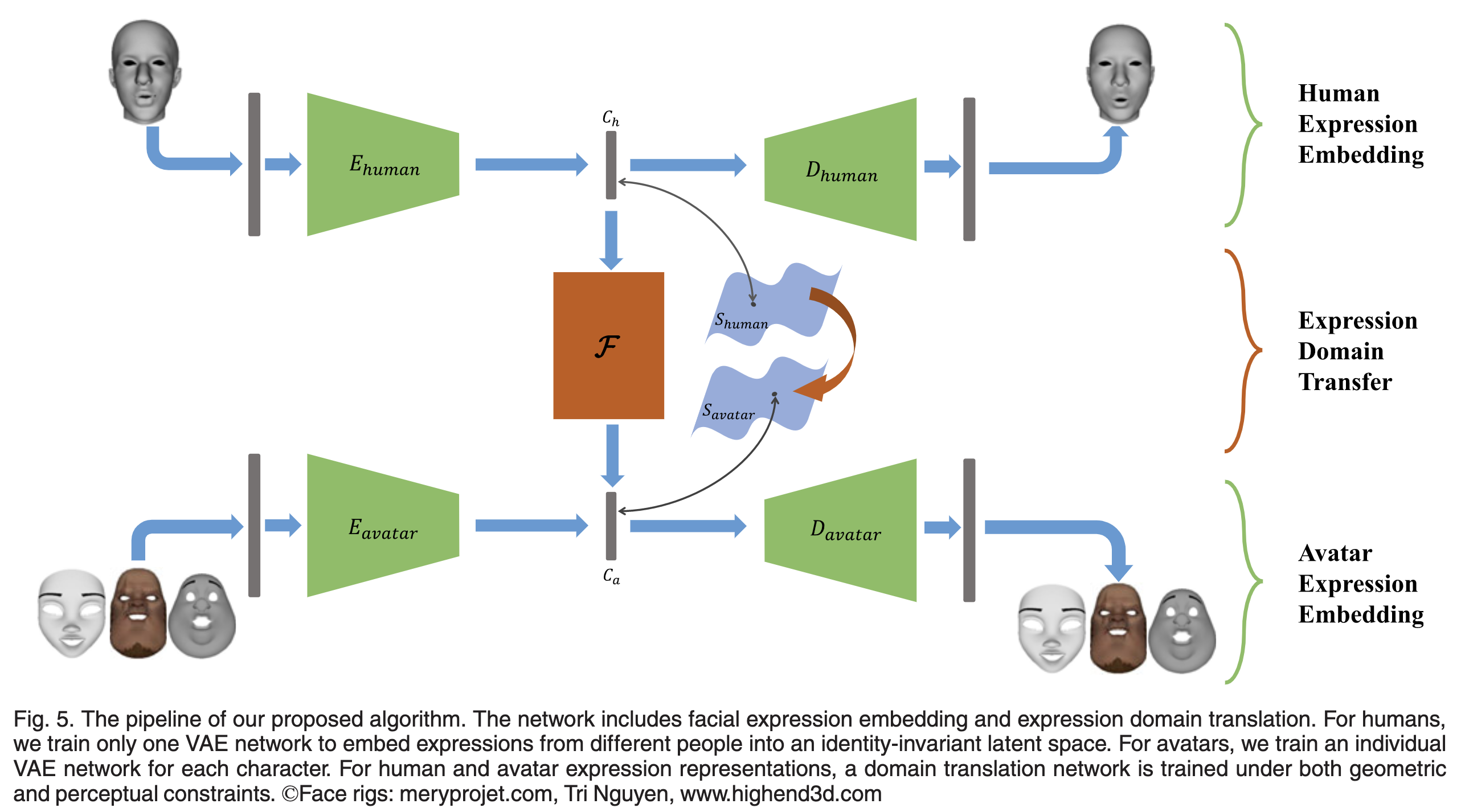
그림 5는 제안된 얼굴 리타게팅 접근 방식의 파이프라인을 보여줍니다. 상단 및 하단 분기는 인간 및 아바타 표현 표현 학습을 위한 별도의 그래프 컨볼루션 VAE 네트워크입니다. 두 개의 잠재 공간에 걸쳐 완전히 연결된 네트워크 F는 도메인 번역을 위해 훈련됩니다. 추론 단계에서 프레임워크는 3D 사람의 얼굴 모양을 입력으로 받아 리타게팅된 아바타 표현 모양을 출력합니다.
4.Nonlinear Expression Embedding
비선형공간의 얼굴표현 임베딩을 학습하기 위해 VAE 네트워크를 훈련시킨다.
4.1)Avatar Expression Domain
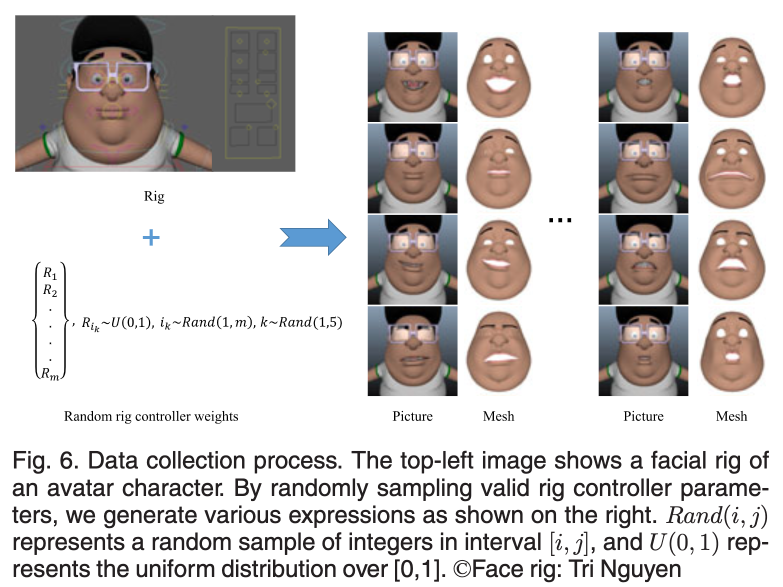
신뢰할만한 아바타 얼굴 표현들을 표현하기 위해 아바타 얼굴 표현의 파라미터를 간소화시키고, 간소화시킨 파라미터를 렌덤으로 조정하여 2000개의 표현 가능한 얼굴들을 자동으로 생성하였다.
4.1.2)Deformation Representation Feature
DR Feature는 기존의 직교좌표를 사용한 매쉬 표현방법에 비하여 매쉬 변형에 있어 더 자세한 표현을 할 수 있는 방법이다.
4.1.3)Network Architecture and Loss Function
얼굴의 매쉬 표현을 DR feature으로 정의하고 연결된 매쉬 정보들을 처리하기 위해 Spectral graph convolutaional 연산을 사용한다.
4.2)Human Expression Domain
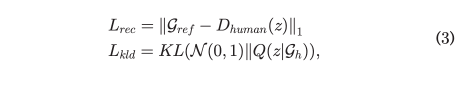
Human VAE 네트워크를 훈련시키기 위한 로스는 다음과 같이 두가지가 있는데,
는 Reconstruction Loss로써 입력된 DR feature들의 평균(사람 개인의 너무 디테일한 정보들을 제거한 표정의 특징) 에서 디코더를 거친 output 의 L1 norm을 구한것이다.
는 KL divergence Loss로써 KL을 근사하기 위해 가우시안 분포와 Variational distribution의 거리를 구하는 matrix 이다.
VAE 대신 AAE 사용해보는건?
5.Expression Domain Translation
This section describes how we construct the correspondences for the facial retargeting task and how we train the translation network to relate the human and avatar expression domains.
5.1)Geometric Consistency Constraint
Therefore, we next relax such point-scale correspondences by retrieving other similar shapes from our avatar dataset based on the distance in the DR feature space.
geomatric deformation은 포인트 스케일의 점대점 대응을 생성하는데 이는 아바타와 얼굴의 큰 모양 차이에 대해 안좋은 결과를 보여주므로 이를 완화하기 위해 아바타 데이터셋의 DR feature에서 거리를 측정하는 방식을 사용한다.
임베딩된 latent space의 꼬임을 해결하기 위해 사람의 46가지 얼굴 표현을 나타내는 latent space를 각각
으로 표현하였고 이에 대응하는 아바타의 표현 역시 으로 표현하는데 이때 는 아바타 모델의 갯수이다.
위의 임베딩 스페이스 변환을 위한 네트워크를 훈련시키는 로스 2개를 설명한다.(이후 추가적으로 하나의 로스가 더 있음)
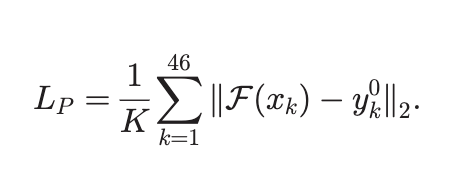
로스는 포인트스케일의 로스로써 라는 사람얼굴표정 embed 백터를 입력으로 받는 도메인 변환 네트워크 의 출력(아바타의 latent space 형식)과 아바타(하나의 아바타 모델)와의 거리의 합(46가지 표정에서 각각 구한 거리) 로스로 사용한다.
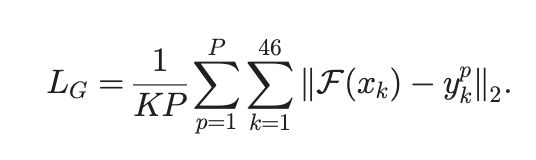
로스는 그룹스케일의 로스로써 46개의 latent vector를 각각 도메인 변환 네트워크에 통과시켜 나온 아바타 도메인의 결과 를 아바타 전체 모델(1~P개)와 비교한 거리의 합이다.
즉 항은 어떠한 얼굴 표정 에 대하여 모든 아바타의 의 거리를 Loss로 측정한다.
5.2)Perceptual Consistency Constraint
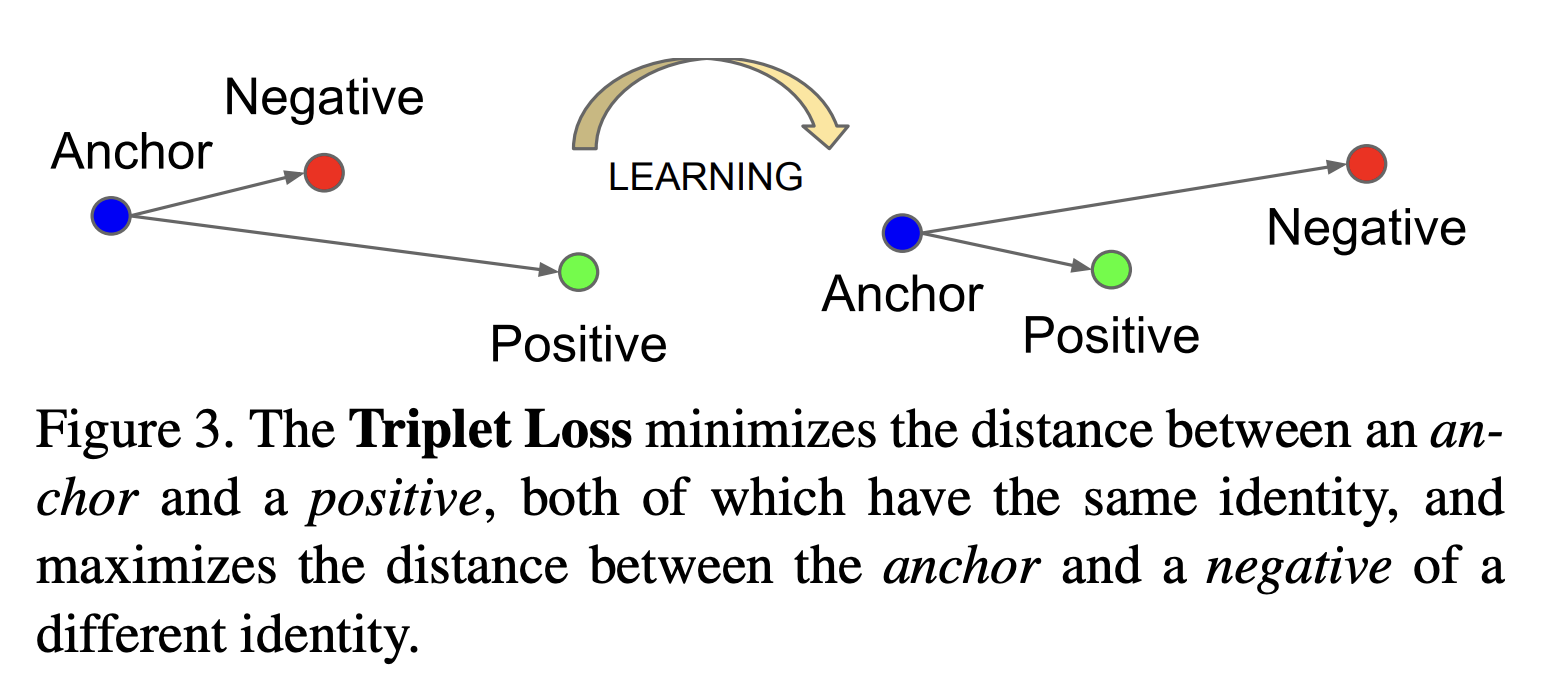
앞서 2가지 Loss()로 그룹 스케일의 대응관계를 만들고, 네트워크를 세부적으로 개선하기 위해 Triplet Loss를 사용한다.
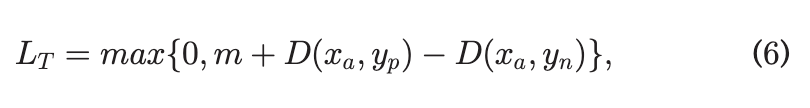
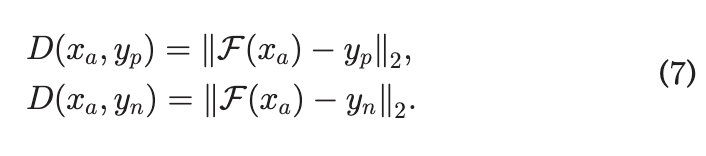
는 Anchor에서 긍정항과 부정항의 거리를 측정하여 긍정항의 거리가 부정항의 거리보다 낮아지도록 한다.
5.3)Progressive Training
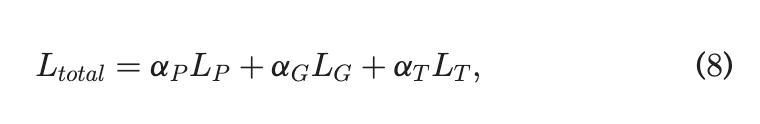
는 각각의 Loss의 Trade off 상수로써 사용되어진다.
6.Experiments
6.1)Implementation Details
6.2)Ablation Study

Fig. 10 shows the retargeting results generated by the domain translation networks that are trained with (a) LP loss only; (b) LP and LG losses; and (c) LP , LG, and LT losses. It can be seen that the retargeting results are improved in fine detail by adding the LG and LT loss terms to the network training.
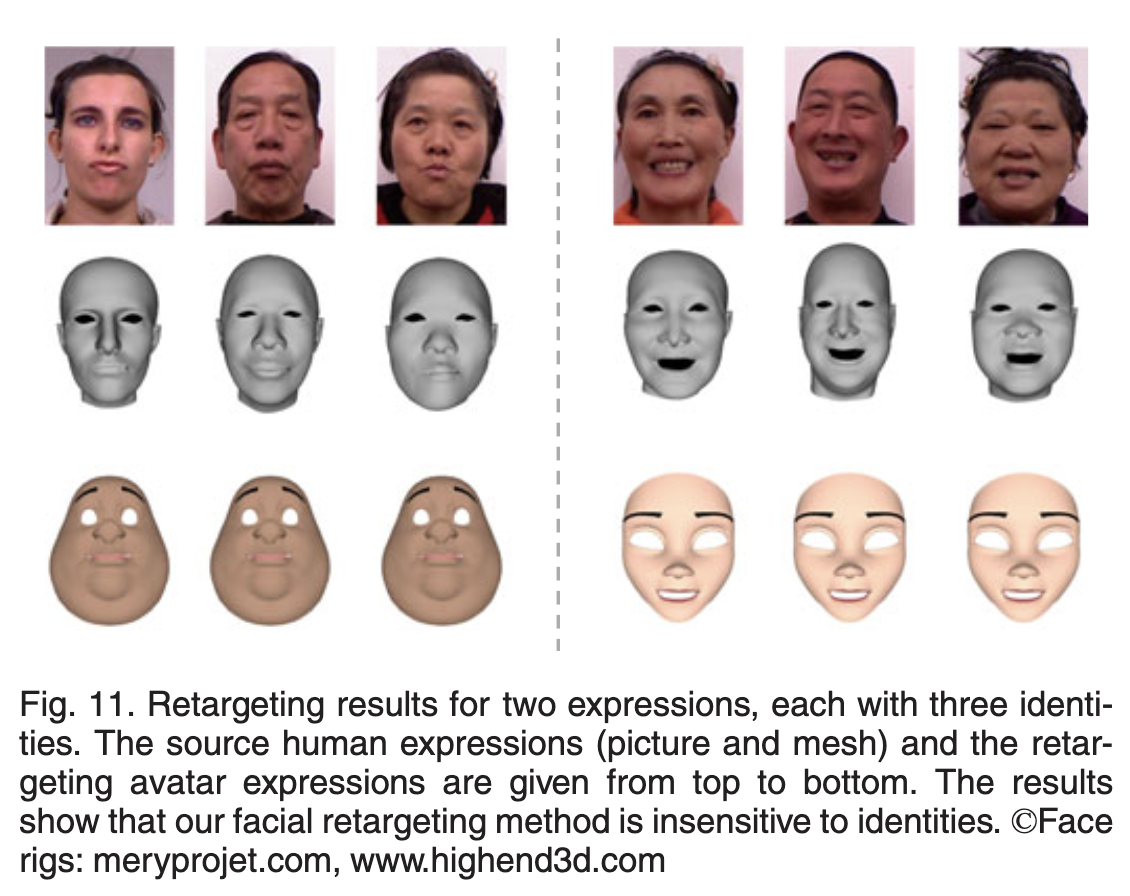
disentangled human expression representation 방법을 사용하여 얼굴을 표현하는것에 있어서 일반화가 잘 된것을 확인할 수 있다.
6.3)Comparison

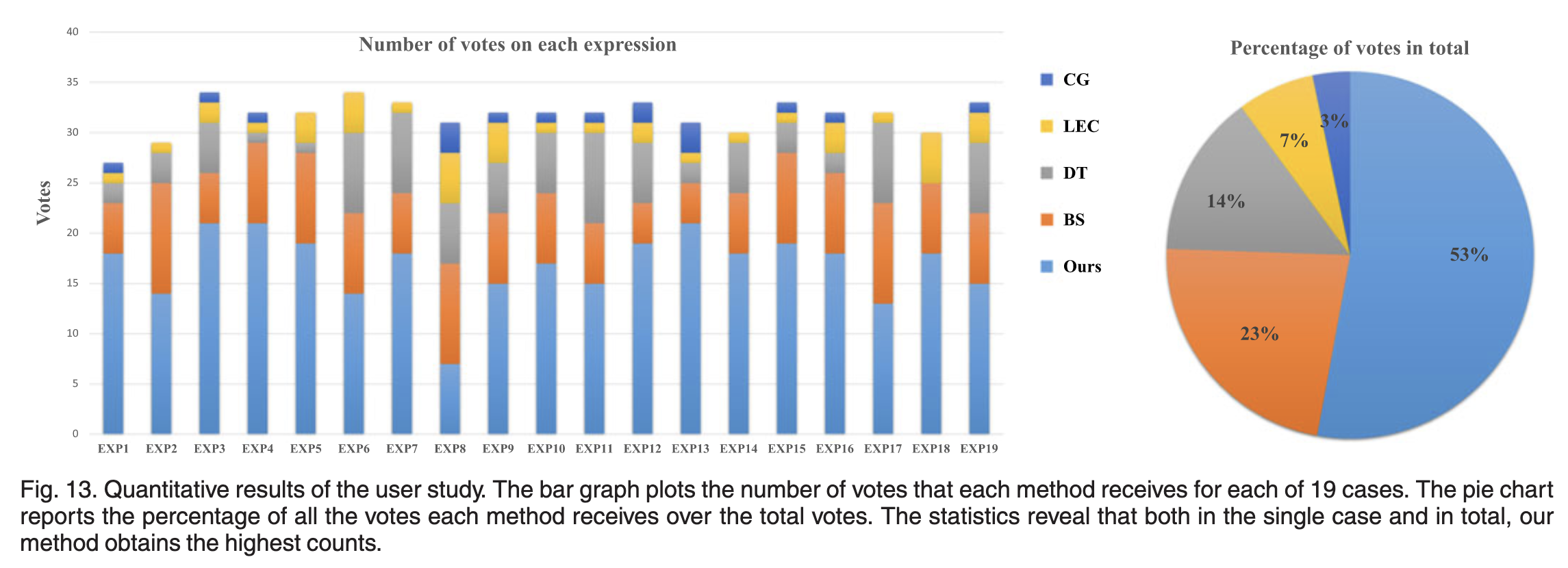
6.4)Evalustion
To evaluate the VAE networks, we visualize the embedding of training and testing data in Fig. 14 and calculate thereconstruction errors in Table 1.
From the qualitative andquantitative results, it can be found that the trained modelcan be generalized to unseen data, and the learned latentspace can cover the testing expressions well.As for the translation network, because there is noground-truth data (i.e., human-avatar expression pairs), weconducted an alternative experiment.
We chose two subjectsfrom the FaceWarehouse dataset as the source and targetcharacters, and then we trained a translation network follow-ing the same settings.
We computed the positional errors ofvertices between the transferred results and the ground-truth data. The last step was to compare our method with theblendshape-based method (BS) and the deformation transfermethod (DT). Both qualitative and quantitative results aregiven in Fig. 15. The results show that our method givessmaller errors than BS but larger errors than DT. There aretwo reasons for DT to have smaller errors than our methodin this experiment. First, the source and target human facemodels share the same topology, so the landmark corre-spondences are accurate. However, this is generally not truein the scenarios where the source is a human model and thetarget is an avatar model. Second, the shape differencebetween human subjects is relatively small, which makes itdifficult for our annotators to discriminate the better expres-sion from a triplet.
7.Discussion
8.Conclusion
