Saito, Shunsuke, et al. "Pifu: Pixel-aligned implicit function for high-resolution clothed human digitization." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
abstract
We introduce Pixel-aligned Implicit Function (PIFu), a highly effective implicit representation that locally aligns pixels of 2D images with the global context of their corresponding 3D object. Using PIFu, we propose an end-to-end deep learning method for digitizing highly detailed clothed humans that can infer both 3D surface and texture from a single image, and optionally, multiple input images. Highly intricate shapes, such as hairstyles, clothing, as well as their variations and deformations can be digitized in a unified way. Compared to existing representations used for 3D deep learning, PIFu can produce high-resolution surfaces including largely unseen regions such as the back of a person. In particular, it is memory efficient unlike the voxel representation, can handle arbitrary topology, and the resulting surface is spatially aligned with the input image. Furthermore, while previous techniques are designed to process either a single image or multiple views, PIFu extends naturally to arbitrary number of views. We demonstrate high-resolution and robust reconstructions on real world images from the DeepFashion dataset, which contains a variety of challenging clothing types. Our method achieves state-of-the-art performance on a public benchmark and outperforms the prior work for clothed human digitization from a single image.
Key ideas
Implicit representation
Implicit function -> SDF
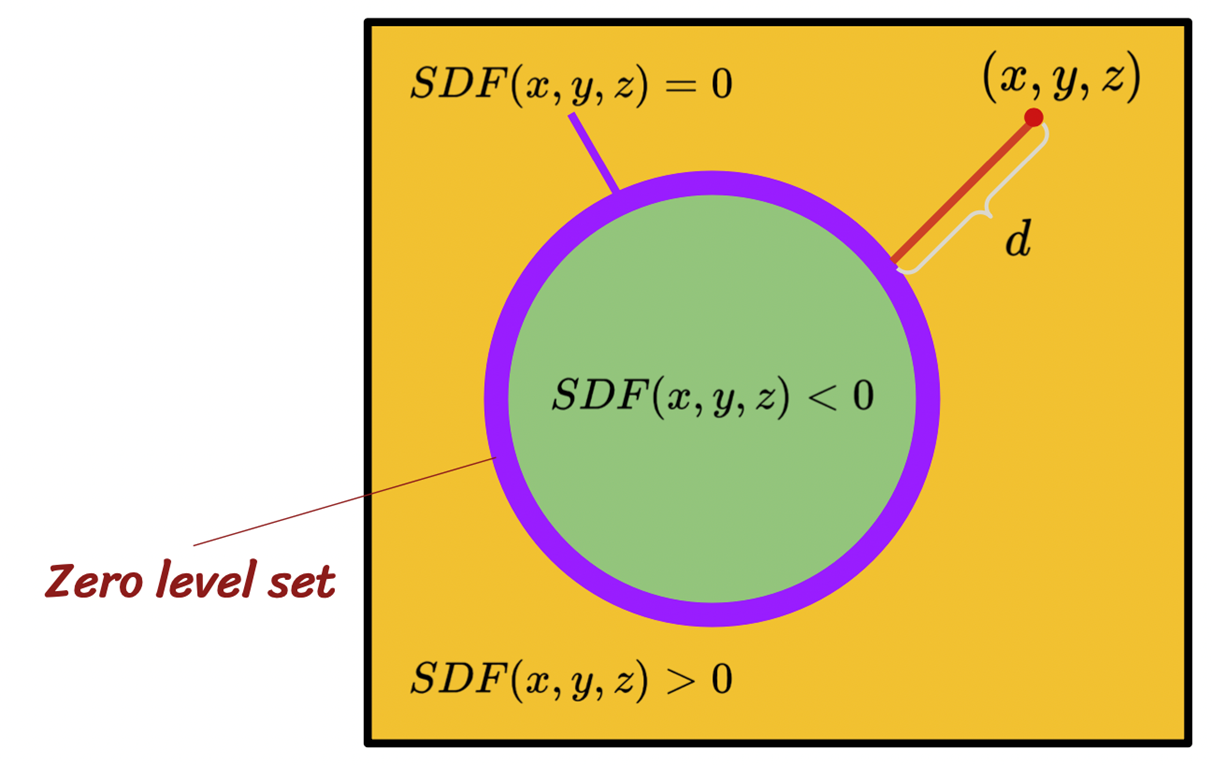
어떤 공간에 있는 특정한 함수(mesh)의 경계(surface)를 정의하는 함수를 SDF(signed distance function)라 한다.
SDF : 정의된 도형에 대하여 어떤 point의 거리를 기준으로 영역을 구분하는 함수
함수로 mesh를 저장할 수 있기 때문에 기존의 voxel 방식에 비하여 메모리효율적이다.

이러한 SDF를 딥러닝을 사용해 모델링한것을 Neural rander이라 한다.
Pixel-Aligned feature
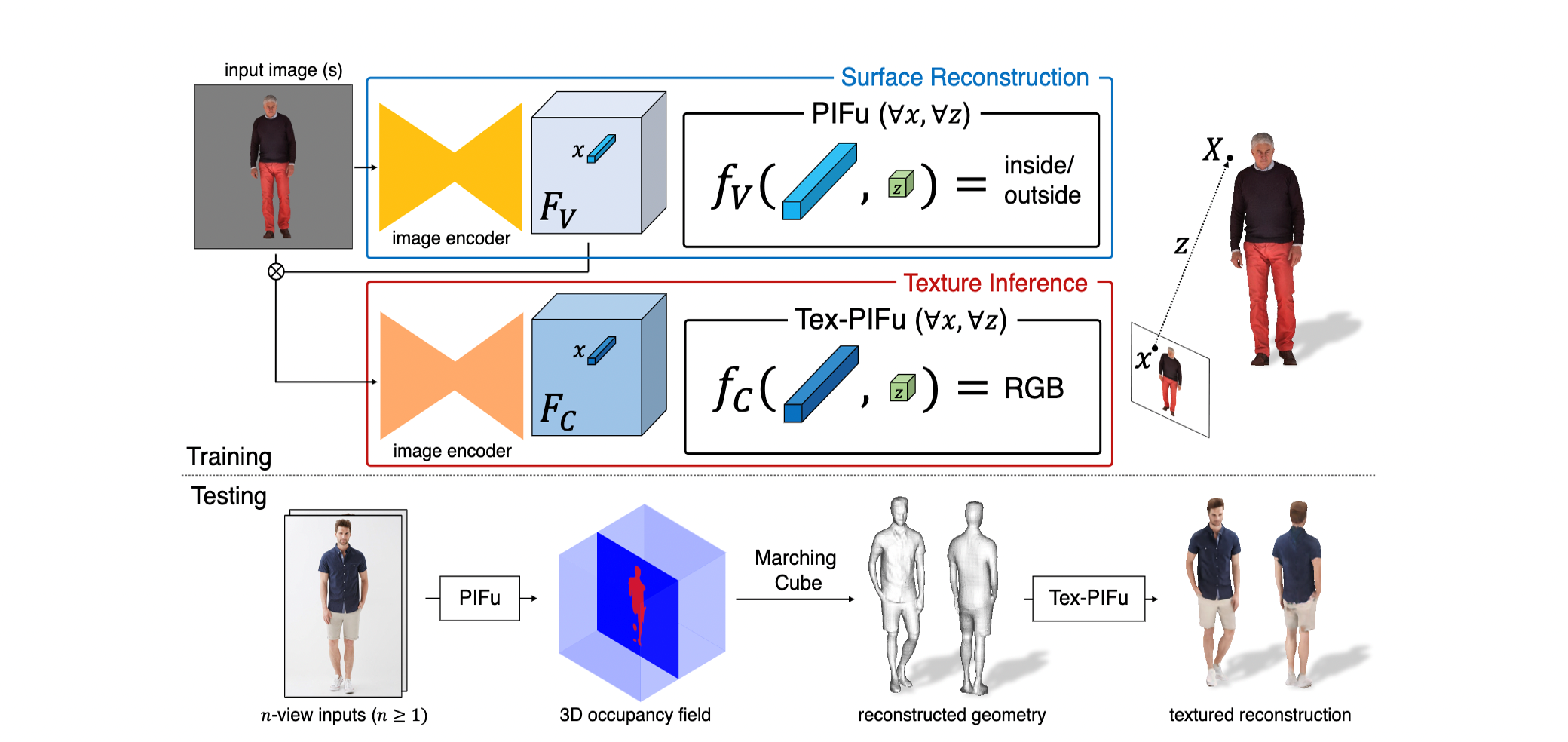
pifu pipline
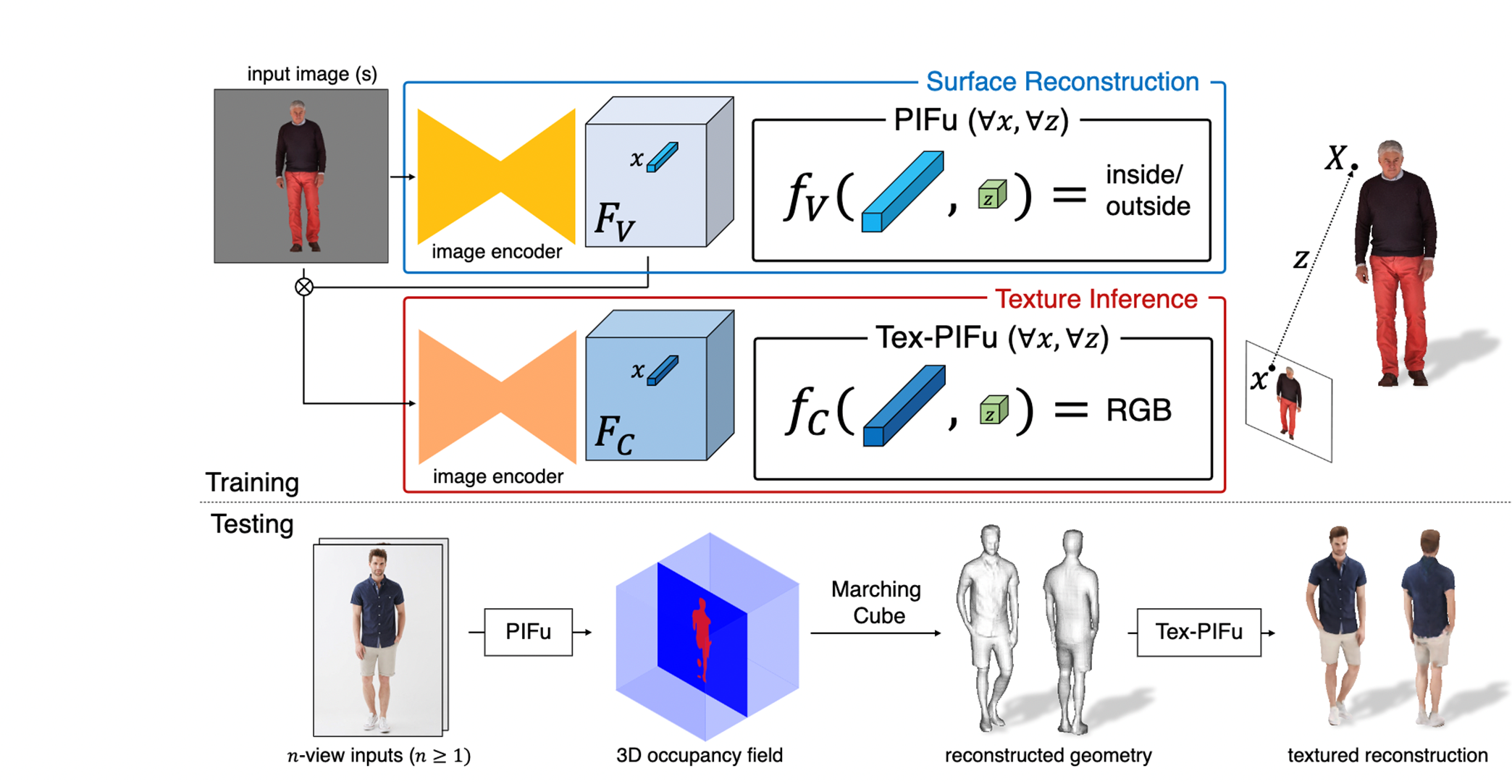
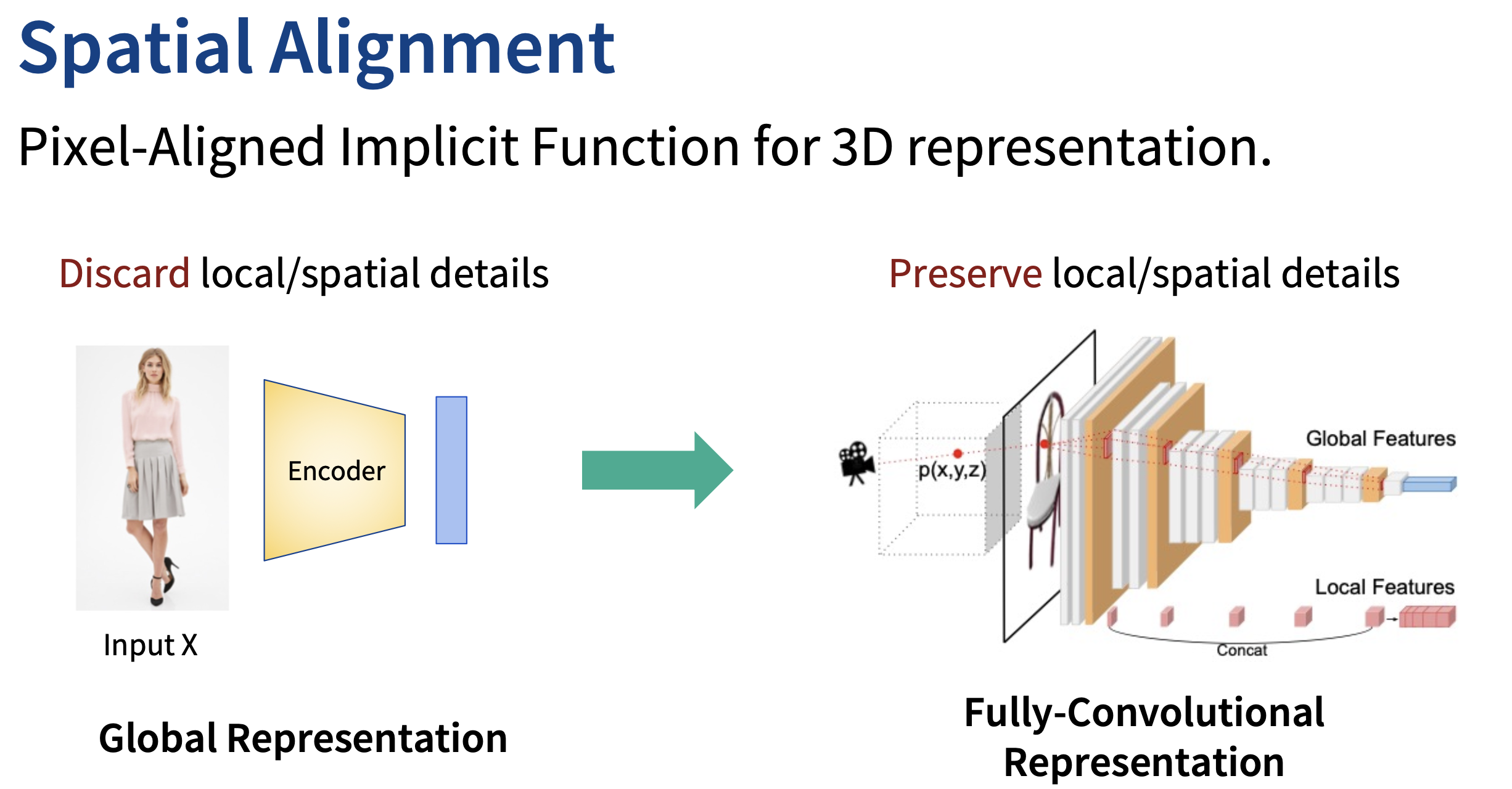
기존에 2d이미지를 3d 모델로 변환하는 방법들은 이미지의 전체적인 feature를 사용함에따라 지역적인 특징(discard local detail)들이 사라지는 경향이 있었는데 pifu는 이를 Unet 구조의 인코더를 사용해 각각의 필터에서 하나의 픽셀에 대해 Align한 feature를 뽑아 이를 SDF에 사용한다는 특징이 있다.
inference 과정에선 3차원 공간상의 점에 대한 정보가 없으므로 Pifu를 통해 3D occupancy field를 구하고(정해진 3D 좌표공간의 in/out을 훈련된 pifu로 예측할 수 있으므로) marching cube 알고리즘으로 3D geometry을 복원하는 과정을 거친다.
pifu SDF :
- : 3D coodinate
- : 𝑋 to 2D projection
- : depth val in camera coordinate space
- : 𝑥 feature = g(Image(𝑥))
의 결과로써 와 를 이어주는 ray 위의 점들에 대한 in/out 결과가 리턴된다.
pifu SDF Loss :
- : Ground truth of 3D occupany field
- : Pred term
- : number of sampled points
SDF를 훈련시키는것에 있어서 3d occupancy의 예측값과 GT의 l2를 loss로 사용했다.
Texture inference
Tex pifu :
- : 3D coodinate
- : 𝑋 to 2D projection
- : depth val in camera coordinate space
- : 𝑥 feature = g(Image(𝑥))
Tex pifu는 기존의 pifu와 동일한 네트워크에서 출력항만 RGB로 수정하여 surface의 색을 판단하기 위해 사용했다.
Tex pifu Loss :
- : Ground truth of RGB on surface point
- : Pred term
- : number of sampled points
- : 이고 ~
기존의 pifu loss( )를 사용하면 가 표면의 RGB 뿐만 아니라 3D 표면까지 예측하므로 오버피팅이 일어나게 된다 따라서 논문에서는 texture를 추론하는 image encoder의 조건에 앞서 훈련한 surface feature()를 넣어주어서 tex-image encoder가 새로운 오브젝트(훈련시에 볼 수 없었던 shape, pose, topology)에 대하여 오직 RGB에만 집중할 수 있도록 해준다. 또한 surface의 point 하나만 예측하는것이 아니라 3D surface의 주변 점들까지 훈련할 수 있도록 ~ offset을 추가했다.
Spatial sampling
- iso-surface : 같은 레벨의 3d occupancy(매쉬의 표면을 자르면 나오는 등고선같은 표면)

iso-surface sampling만 사용하였을 경우 오버피팅이 일어나는것을 확인하였고 uniform sampling만 사용하였을 경우에는 언더피팅이 일어나는것을 확인하였다. 결과적으로 두가지 방법을 같이 사용하는것이 가장 좋은 sampling 방법인 것을 Figure 9에서 확인 할 수 있었다.
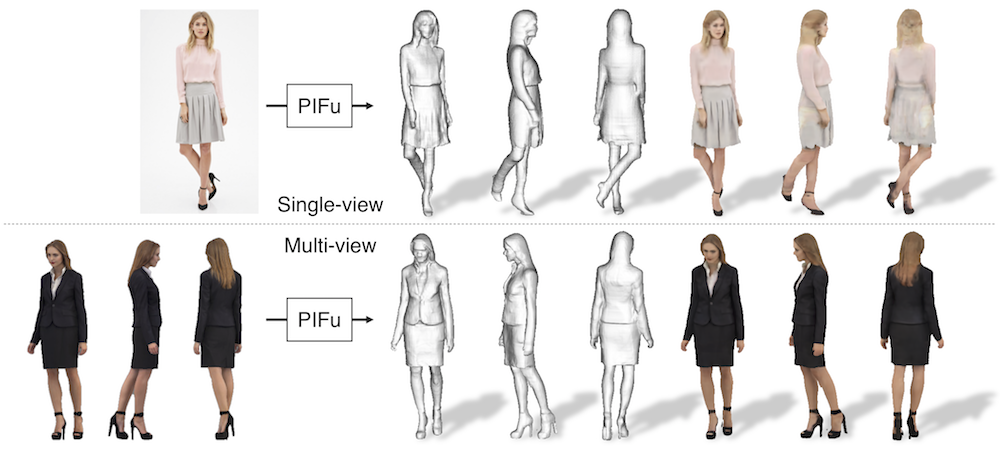
Multi-view stereo

Pifu에서 사용하는 pixel-aligned function인 를 임베딩 네트워크 와 다중 view 추론 네트워크 로 분리하여 멀티 뷰 기능을 구현할 수 있다. 공간에 있는 3D 점() 에 대하여 은 각 view들의 임베딩 feature들을 인코딩하고 는 에서 인코딩한 임베딩 feature들을 aggregate 하여 SDF와 RGB를 판단합니다.
Result
Quantitative Result
- P2S : average point-to-surface Euclidean distance
- Chamfer : iso-surface의 차이를 측정하는 방법

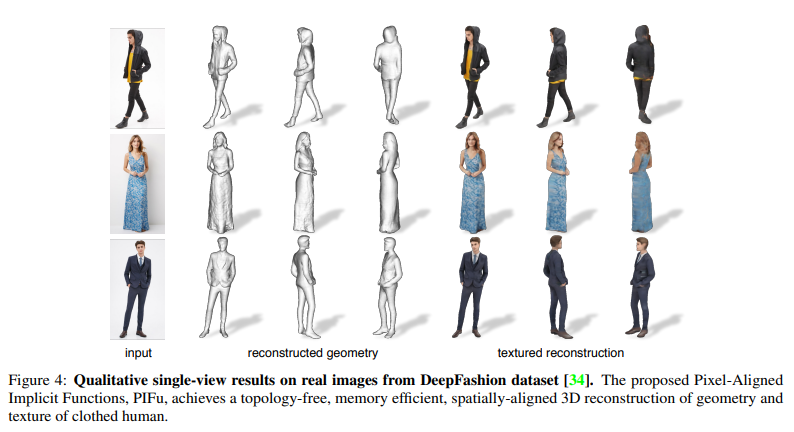
Qualitative Result