[논문리뷰]Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks(CycleGAN)
논문리뷰
수업에서 기말 프로젝트를 위해 제가 처음으로 정독한 논문입니다
다른 소스들을 참고하지 않고 오로지 논문만을 보고 이해했고, 그것을 바탕으로 리뷰하겠습니다
기본적인 GAN만 아는 배경지식에서 시작하였습니다
경험해본 결과 GAN의 기본적인 concept만 알아도 충분히 이해할 수 있는 논문입니다.
참고로 GAN 공부는 나동빈씨의 유튜브를 통해 하였습니다 이해도 잘 되고 코드설명까지 해주셔 귀에 쏙쏙 들어오니 적극 추천합니다👍👍👍
Introduction
제안배경
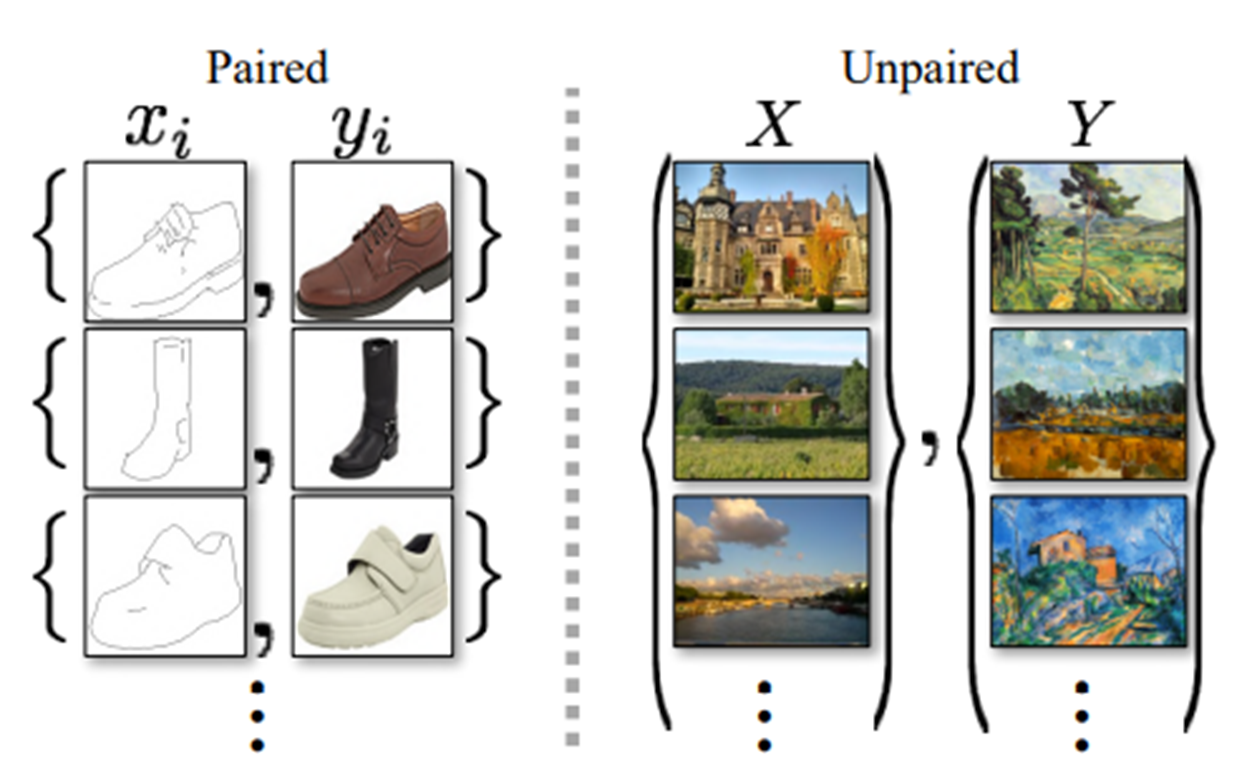
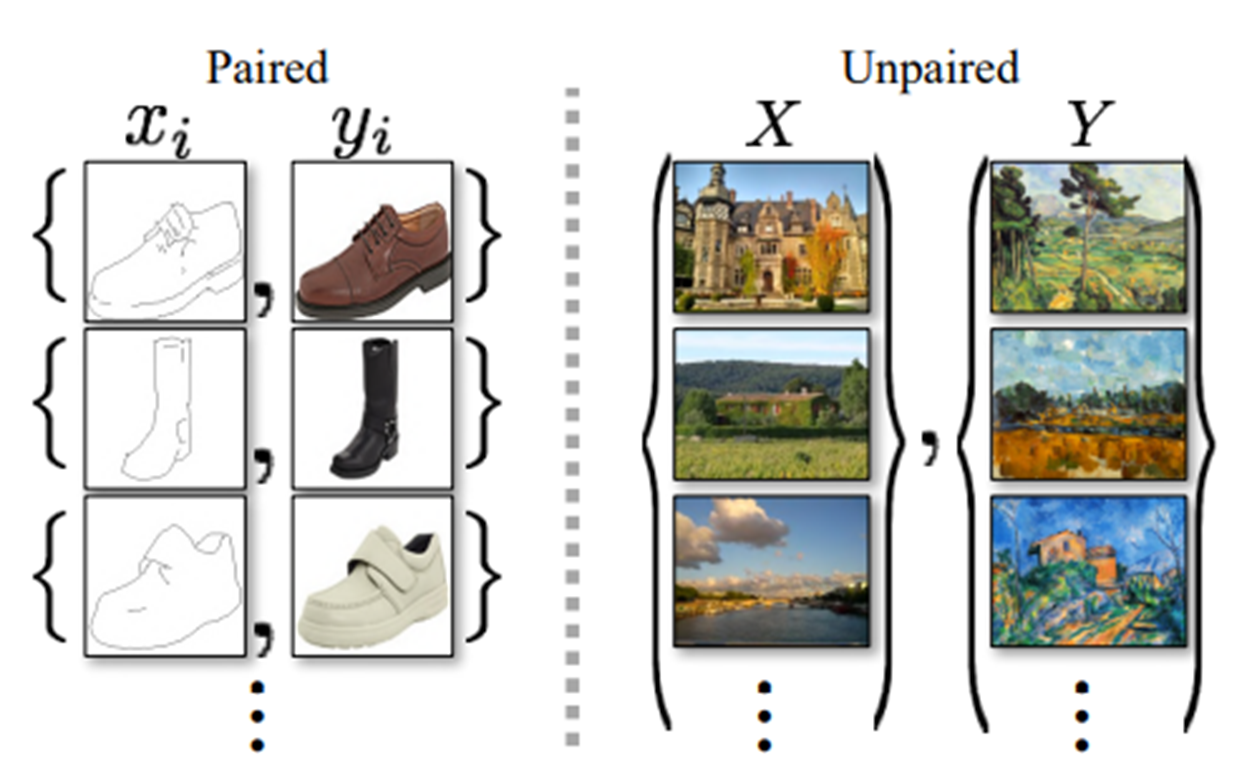
수년간 컴퓨터 비전, 이미지 처리, 컴퓨터 사진 및 그래픽에 대한 연구는 지도학습 즉 보시는 그림같이 pair 데이터셋(쌍을 이루는 데이터셋) 환경에서 강력한 변환시스템을 만들었습니다.
하지만 pair데이터 셋을 얻는 것은 어렵고 비쌉니다.
또한 객체 변환과 같은 많은 작업의 경우 출력이 제대로 정의되지 않습니다.
그래서 저자들은 Unpaired dataset만으로 도메인 간 번역을 할 수 있는 알고리즘을 찾은 것입니다.
제안한 알고리즘
도메인 사이에 기본 관계가 있다고 가정합니다.
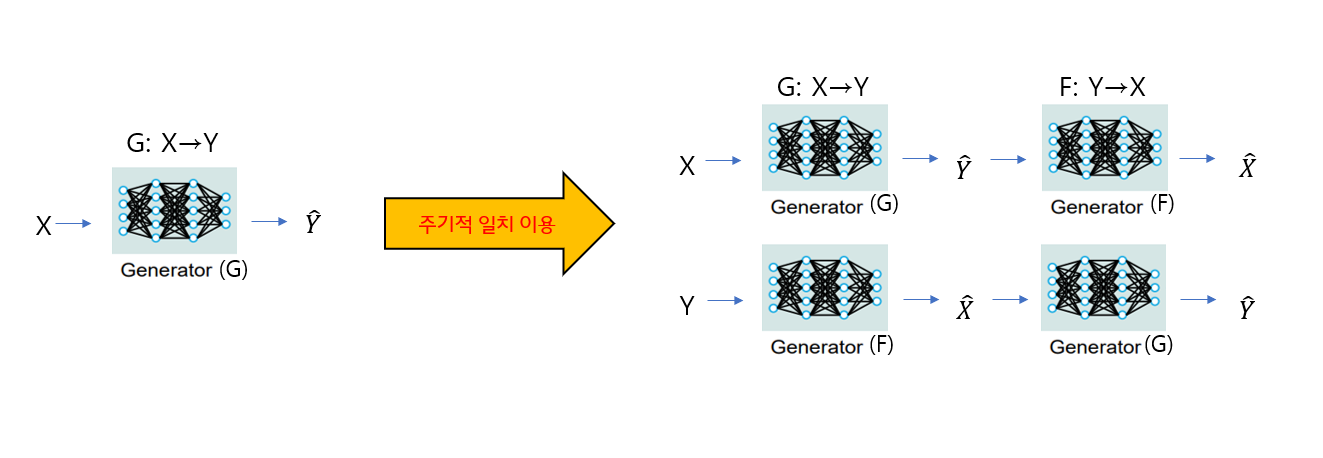
일반적으로 그림의 화살표 왼쪽같이 G를 X를 Y에 매핑하는 Generator라고하면 Y와 일치하는 Y^에대한 출력 분포를 유도할 수 있습니다.
하지만 동일한 분포를 유도하는 무수히 많은 Generator가 있기에 이러한 변환은 개별적인 X와 Y^이 의미 있는 방식으로 짝을 이룬다는 것을 보장하지 않습니다. 뿐만 아니라 적대적인 목표를 단독적으로 최적화하는 것도 어렵습니다. (종종 모든 입력 이미지가 동일한 출력 이미지에 매핑 되고 최적화가 진전을 이루지 못하는 잘 알려진 모드 축소 문제를 초래)
그래서 저자는 주기 일관성 특성을 이용하기로 합니다. 주기 일관성을 예를 들어 설명하자면 우리가 특정 문장을 영어에서 프랑스어로 번역하고, 그것을 다시 영어로 번역하면 원래의 문장으로 돌아와야 한다는 것입니다.
즉, X를 Y로 매핑하는 Generator G뿐만아니라 Y를X로 매핑하는 Generator F도 사용해 유의미하게 매핑 되는 Generator를 만드는 것입니다.
여기서 두개의 Generator는 일대일 대응이 되어야합니다.
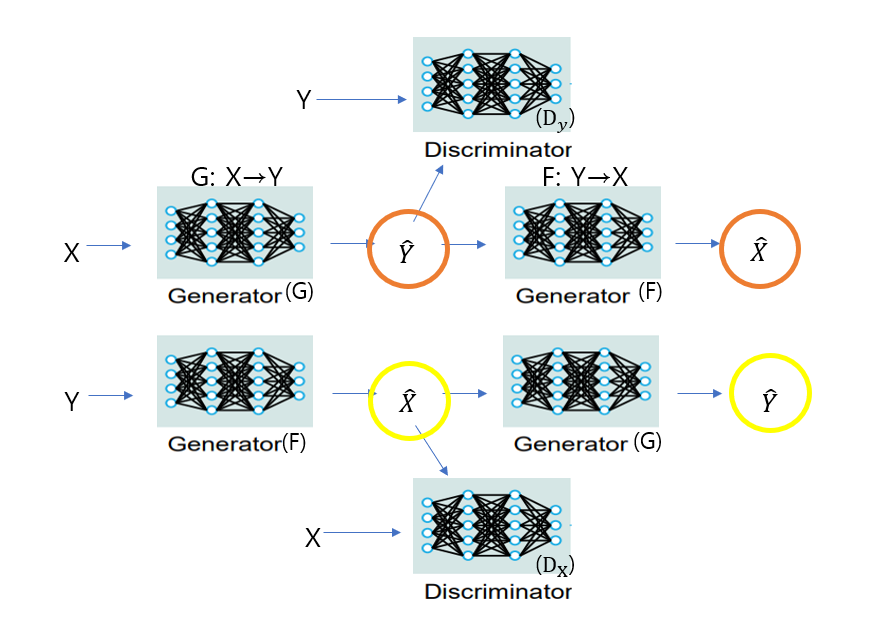
위 그림의 구조가 Cycle GAN입니다.
학습 한번 할때 Dataloader에서 X, Y를 뱉어내면 X는 Y에 매핑되게 Generator G를 훈련시키고 Y는 X에 매핑되게 Generator F를 각각 훈련시킵니다.
그 후 각각의 output을 각각의 Discriminator DY와 DX에 넣어 적대적 손실을 계산하고 주기 일관성 손실을 계산하기위해 앞서 훈련시킨 Generator G와F를 가져와 X와 Y를 재구성해 주기일관성 손실을 계산합니다.
혼동이 올 수도 있는데 그림 상 위, 아래에 있는 X^, Y^은 다른 것입니다.(혼란을 방지하기 위해 색깔로 표시해뒀습니다)
위에서의 Y^은 X를 Y처럼 만든것이고, X^은 그 Y^을 다시 원래 X처럼 만든 것입니다.
마찬가지로 아래서의 X^은 Y를 가지고 X처럼 만들고자한 것이고, Y^은 그 X^을 가지고 다시 Y로 되돌리고자 한 것으로 아예 다른 것입니다.
Formulation
총 손실은 적대적 손실과 주기일관성 손실을 더한 것입니다.
Adversarial Loss
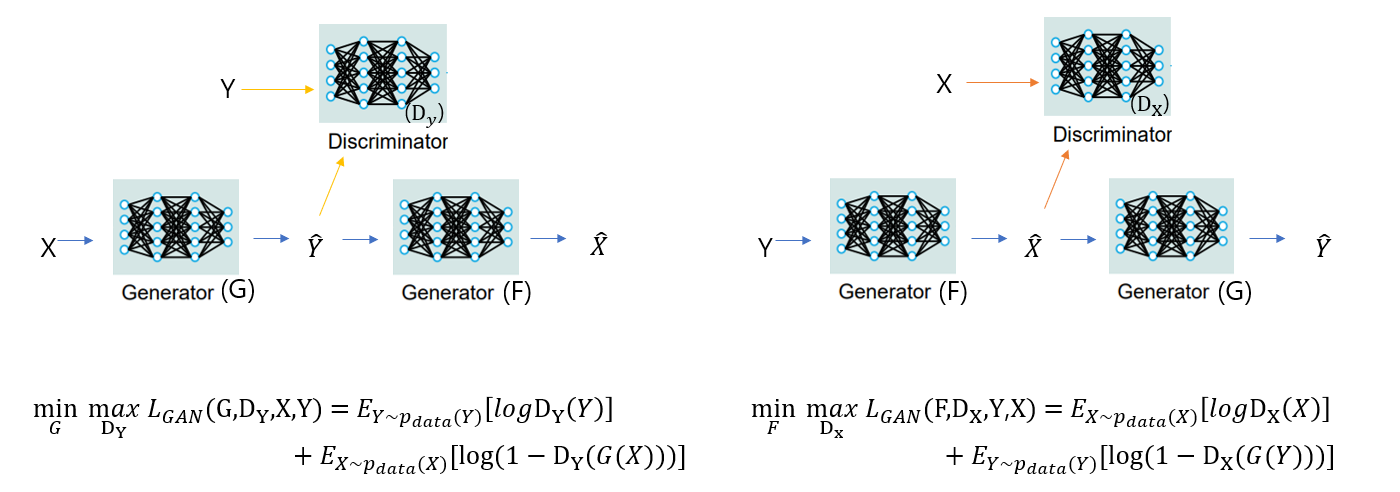
우선 Generator와 Discriminator가 각각 두 개로 적대적 손실도 두 개가 나옵니다.
그림의 왼쪽 구조와 공식으로 설명하겠습니다
Discriminator의 목표는 진짜인지 가짜인지 잘 구별하는 것이고 Generator의 목표는 가짜를 진짜같이 만드는 것입니다.
우선 왼쪽항은 G,DY,X,Y로 구성된 함수 LGAN이 있을 때 G는 LGAN의 값을 낮추려하고 DY는 LGAN의 값을 크게한다는 뜻입니다.
오른쪽항을 보시면 우선 Generator는 두번째항에만 관여합니다.
Generator가 목표대로 잘 작동한다면 Discriminator가 진짜라고 속아 output이 1에 가깝게 나와 항이 작아져 LGAN값이 작아질 것입니다.
반대로 Discriminator가 목표대로 잘 작동한다면 Discriminator에 Y를 넣으면 Discriminator의 output이 1에 수렴하고 Y^을 넣었을 때는 0에 수렴해 LGAN값이 최대로 높일 것입니다.
이게 식의 전부입니다.
오른쪽도 변수명만 다르지 동일한 식입니다.
생각보다 쉽죠?😆
Cycle Consistency Loss
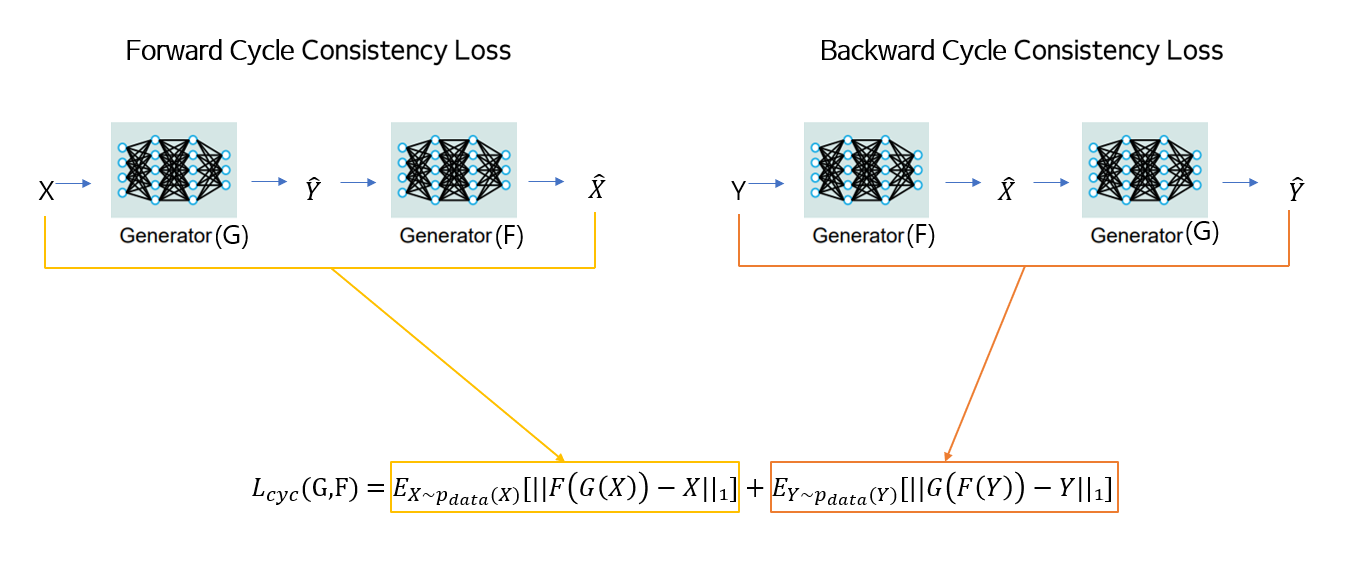
Generator G와F를 사용해서 변환한 것을 다시 변환해 재구성한 것과 원본을 비교해 주기 일관성 손실을 계산합니다.
논문에서는 L1norm을 이용해 원본과 재구성한 것의 차이를 계산하였습니다
Full Objective
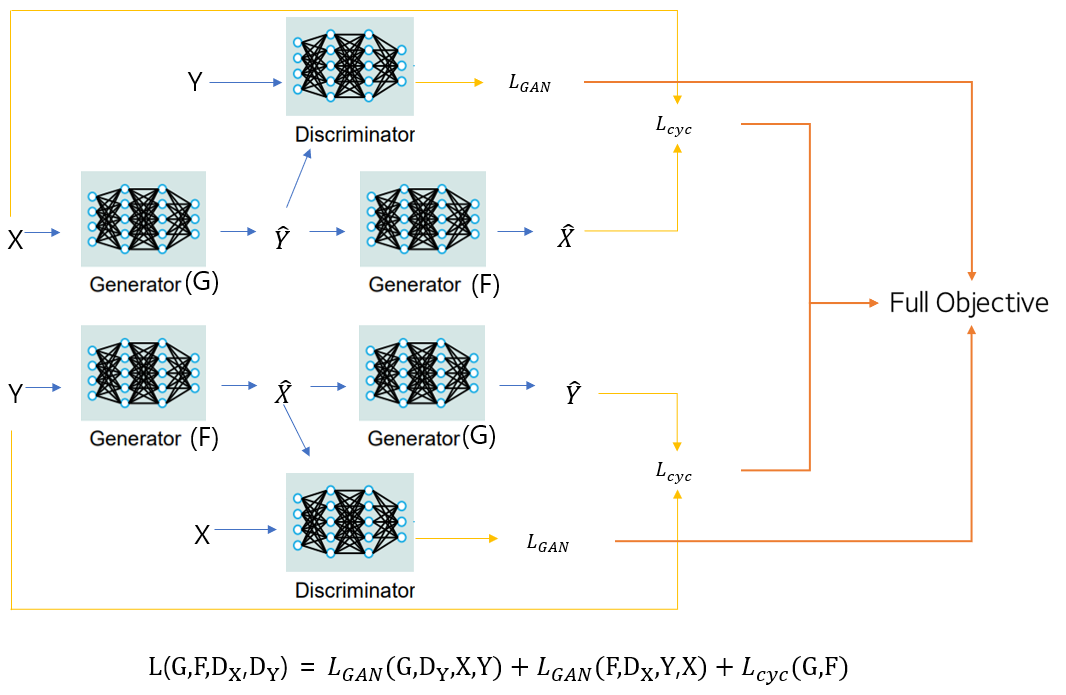
정리하자면 두 개의 Generator의 output들을 Discriminator에 입력으로 해 각각의 손실을 얻고, 주기일관성 손실을 얻기위해 앞에 학습한 서로의 Generator를 가져옵니다. 그후 다시 원본 분포에 가깝게 만든 output들로 주기일관성 손실을 계산하는 것입니다
추가적으로 논문에서는 실험부분에서 identity loss도 사용합니다. 이는 입력 데이터의 색상을 보존하기 위한 손실입니다. X를 Y로 매핑하는 Generator G에 입력으로 Y를 넣어 얻은 output Y^과 Y와의 거리(L1norm), Y를 X로 매핑하는 Generator F에 X를 넣어 얻은 output X^과 X와의 거리(L1norm)를 더한 것입니다.
이것은 Generator 학습 시 손실에 더해줍니다.
Experimental Results
실험1 - 모델별 성능 평가
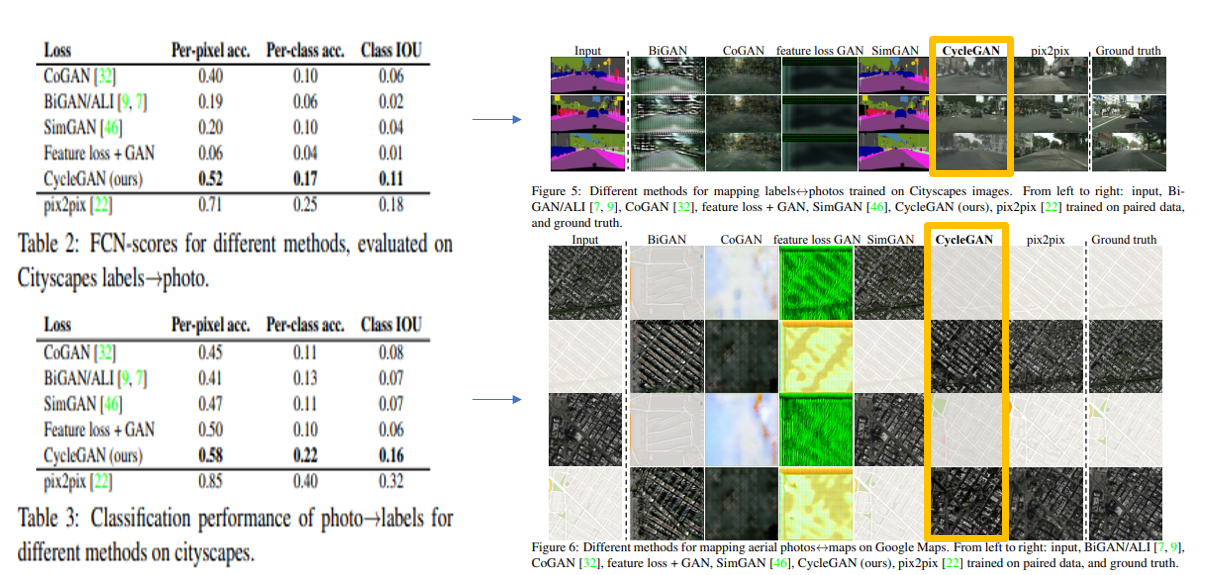
이 실험은 여러 모델로 변환작업을 해본 것입니다
오른쪽 사진을 보나 표를 보나 CycleGAN이 주목할만한 결과를 얻지는 못합니다.
하지만 종종 지도학습인 Pix2Pix와 유사한 품질로 변환이 되었다는 것을 주목해서 보시면 됩니다.
실험2 - Loss Function
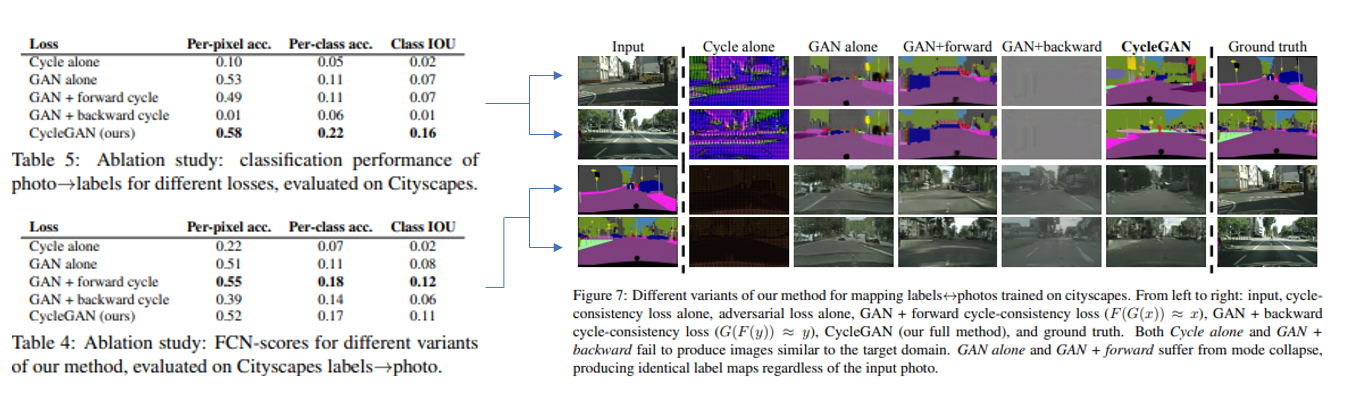
Cycle alone은 주기일관성 손실만 사용했을 때, GAN alone은 적대적손실만 사용했을 때, 세-네번째는 적대적 손실과 양방향 주기 일관성 손실이 아니라 각각 한 방향의 주기일관성 손실을 쓸때이고, 마지막이 저자가 제안한 주기일관성 손실과 적대적손실을 다 사용했을때입니다.
맨위 적대적 손실이랑 주기일관성 각각만 사용했을때 결과가 크게 저하된것을 볼수있는데 이로써 둘개 모두가 결과에 중요하다는 것을 알 수 있습니다.
또한 주기일관성 손실을 하나씩만 쓰면 종종 훈련 불안정성을 야기하고 모드 붕괴를 유발하며, 특히 제거된 매핑 방향에 대해 모드 붕괴를 유발한다는 것을 발견했다고 합니다.
실험3 - 이미지 재구성 품질

그림은 재구성된 이미지의 몇 가지 무작위 샘플 입니다.
사진,지도 예시와 같이 하나의 도메인이 훨씬 다양한 정보를 나타내는 경우에도 재구성된 영상이 원본 X에 가까운 경우가 많다는 것을 관찰되었습니다.
응용

사진을 여러 화풍으로 바꾸거나 오른쪽 그림처럼 그림을 사진처럼 바꾸기도합니다.
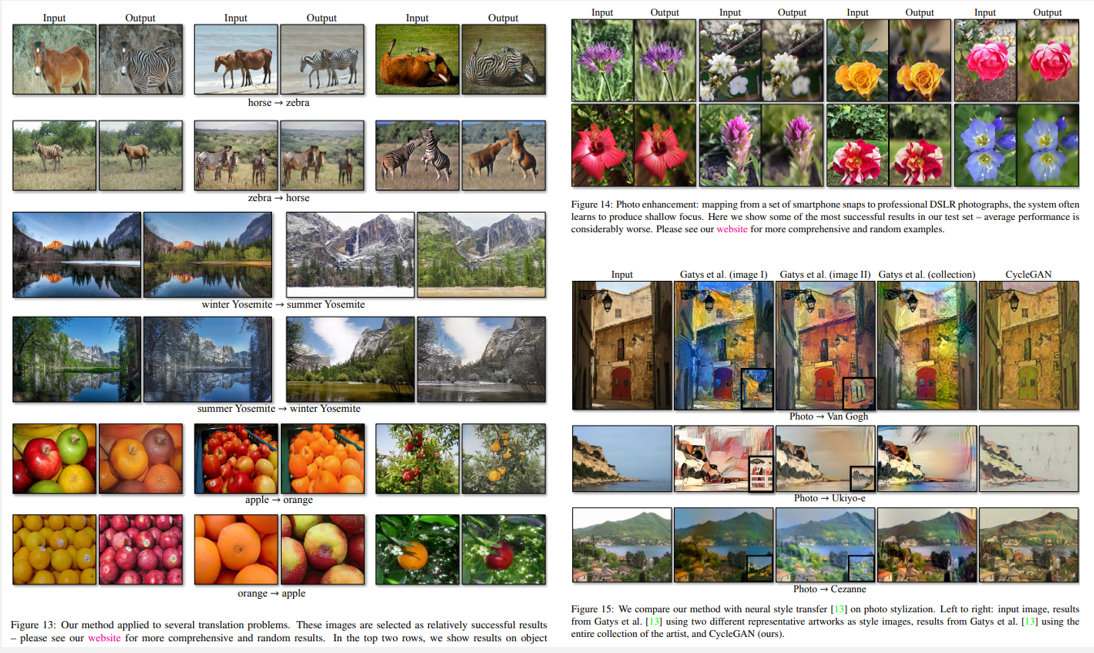
또한 말을 얼룩말로 변환을 하거나, 겨울을 여름으로 혹은 여름을 겨울로 바꾸거나, 오렌지,사과를 양방향으로 바꾸고, 그냥 사진을 아웃오브포커스사진으로 바꾸는 등 많은 응용이 가능합니다.
Limitations

첫번째, 결과가 균일하게 잘 나오지 않는다는 것입니다. 색상, 질감 변경을 포함하는 변환작업에서는 종종 성공하나 기하학적 변화가 필요한 작업은 거의 성공하지 못 합니다. (ex - 고양이를 개로 변환하는 작업) 저자는 이러한 기하학적 변화를 다루는 것은 앞으로의 풀어 가야할 중요한 문제라고 언급합니다.
두번째로는 training dataset의 특성 분포에서 야기되는 문제입니다. 예를 들어 설명하면 말을 얼룩말로 변환하는 모델을 학습시킬 때 training dataset에 사람이 들어가지 않고 학습하게 되면 사람이 포함되어 있는 사진으로 test를 한다면 사람도 얼룩말의 패턴을 가지게 변환됩니다.
마지막으로는 쌍으로 구성된 훈련 데이터로 달성할 수 있는 결과와 쌍으로 구성되지 않은 방법에 의해 달성된 결과 사이의 차이가 여전하다는 것입니다. 어떤 경우에는 이 차이를 좁히기 매우 어렵거나 심지어 불가능할 수 있다고 합니다.
직접 구현한 Vanilla CycleGAN (Pytorch)
구현 설명에 앞서 저는 논문에 나와있는 네트워크 구조를 따라하지 않았습니다.
앞서 설명드렸다시피 기본 GAN만 아는 상태였는데 논문에서는 Discriminator를 PatchGAN으로 구현했습니다.
그래서 제 지식 내에서 구현을 하였다는 것을 참고바랍니다.
Generator는 기본 U-net으로, Discriminator도 기본 분류 모델로 직접 구현하였습니다
논문 실험에서 사용되는 데이터셋 중 summer2winter_yosemite 데이터셋을 사용하였습니다.
변수명들은 논문에서 사용된 이름으로 사용하였습니다
코드는 저의 깃허브에 있습니다
1 데이터 불러오기
train_X_path = sorted(glob.glob("./summer2winter_yosemite/trainA/* ",recursive=True))
train_Y_path = sorted(glob.glob("./summer2winter_yosemite/trainB/* ",recursive=True))
test_X_path = sorted(glob.glob("./summer2winter_yosemite/testA/* ",recursive=True))
test_Y_path = sorted(glob.glob("./summer2winter_yosemite/testB/* ",recursive=True))2 CustomDataset 정의
class MyDataset(torch.utils.data.Dataset):
def __init__(self, x_dir, y_dir,transform=None):
super().__init__()
self.transform = transform
self.x_img = x_dir
self.y_img = y_dir
def __len__(self):
return len(self.x_img)
def __getitem__(self, idx):
x_img = self.x_img[idx]
y_img = self.y_img[idx%len(self.y_img)]
x_img = cv2.imread(x_img)
y_img = cv2.imread(y_img)
x_img= cv2.cvtColor(x_img, cv2.COLOR_BGR2RGB)
y_img= cv2.cvtColor(y_img, cv2.COLOR_BGR2RGB)
if self.transform!=None:
augmented = self.transform(image=x_img,image2=y_img)
x_img = augmented['image']
y_img = augmented['image2']
y_img = np.transpose(y_img,(2,0,1))
x_img = np.transpose(x_img,(2,0,1))
return x_img,y_img3 Argumentation 정의 (논문에 나와있지 않지만 사용)
aug = albumentations.Compose([
albumentations.Resize(280, 280),
albumentations.RandomCrop(256, 256),
albumentations.augmentations.transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
],additional_targets={'image2':'image'})4 Dataset과 Dataloader 선언
train_dataset = MyDataset(train_X_files,train_Y_files,transform=aug)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=3,shuffle=True)5 Generator에 필요한 Block 정의
def conv_block(in_dim,out_dim,act_fn):
model=nn.Sequential(
nn.Conv2d(in_dim,out_dim,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(out_dim),
act_fn
)
return model
def conv_trans_block(in_dim,out_dim,act_fn):
model=nn.Sequential(
nn.ConvTranspose2d(in_dim,out_dim,kernel_size=3,stride=2,padding=1,output_padding=1),
nn.BatchNorm2d(out_dim),
act_fn
)
return model
def maxpool():
pool=nn.MaxPool2d(kernel_size=2,stride=2,padding=0)
return pool
def conv_block_2(in_dim,out_dim,act_fn):
model = nn.Sequential(
conv_block(in_dim,out_dim,act_fn),
nn.Conv2d(out_dim,out_dim, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_dim),
)
return model 6 Generator 정의
class UnetGenerator(nn.Module):
def __init__(self,in_dim,out_dim,num_filter):
super(UnetGenerator,self).__init__()
self.in_dim = in_dim
self.out_dim = out_dim
self.num_filter = num_filter
act_fn = nn.LeakyReLU(0.2, inplace=True)
self.down_1 = conv_block_2(self.in_dim,self.num_filter,act_fn)
self.pool_1 = maxpool()
self.down_2 = conv_block_2(self.num_filter*1,self.num_filter*2,act_fn)
self.pool_2 = maxpool()
self.down_3 = conv_block_2(self.num_filter*2,self.num_filter*4,act_fn)
self.pool_3 = maxpool()
self.down_4 = conv_block_2(self.num_filter*4,self.num_filter*8,act_fn)
self.pool_4 = maxpool()
self.down_5 = conv_block_2(self.num_filter*8,self.num_filter*16,act_fn)
self.pool_5 = maxpool()
self.bridge = conv_block_2(self.num_filter*16,self.num_filter*32,act_fn)
self.trans_1 = conv_trans_block(self.num_filter*32,self.num_filter*16,act_fn)
self.up_1 = conv_block_2(self.num_filter*32,self.num_filter*16,act_fn)
self.trans_2 = conv_trans_block(self.num_filter*16,self.num_filter*8,act_fn)
self.up_2 = conv_block_2(self.num_filter*16,self.num_filter*8,act_fn)
self.trans_3 = conv_trans_block(self.num_filter*8,self.num_filter*4,act_fn)
self.up_3 = conv_block_2(self.num_filter*8,self.num_filter*4,act_fn)
self.trans_4 = conv_trans_block(self.num_filter*4,self.num_filter*2,act_fn)
self.up_4 = conv_block_2(self.num_filter*4,self.num_filter*2,act_fn)
self.trans_5 = conv_trans_block(self.num_filter*2,self.num_filter*1,act_fn)
self.up_5 = conv_block_2(self.num_filter*2,self.num_filter*1,act_fn)
self.out = nn.Sequential(
nn.Conv2d(self.num_filter,self.out_dim,3,1,1),
nn.Tanh(), #필수는 아님
)
def forward(self,input):
down_1 = self.down_1(input)
pool_1 = self.pool_1(down_1)
down_2 = self.down_2(pool_1)
pool_2 = self.pool_2(down_2)
down_3 = self.down_3(pool_2)
pool_3 = self.pool_3(down_3)
down_4 = self.down_4(pool_3)
pool_4 = self.pool_4(down_4)
down_5 = self.down_5(pool_4)
pool_5 = self.pool_5(down_5)
bridge = self.bridge(pool_5) #torch.Size([2, 1024, 8, 8])
trans_1 = self.trans_1(bridge)#torch.Size([2, 512, 16, 16])
concat_1 = torch.cat([trans_1,down_5],dim=1)
up_1 = self.up_1(concat_1)
trans_2 = self.trans_2(up_1)
concat_2 = torch.cat([trans_2,down_4],dim=1)
up_2 = self.up_2(concat_2)
trans_3 = self.trans_3(up_2)
concat_3 = torch.cat([trans_3,down_3],dim=1)
up_3 = self.up_3(concat_3)
trans_4 = self.trans_4(up_3)
concat_4 = torch.cat([trans_4,down_2],dim=1)
up_4 = self.up_4(concat_4)
trans_5 = self.trans_5(up_4)
concat_5 = torch.cat([trans_5,down_1],dim=1)
up_5 = self.up_5(concat_5)
out = self.out(up_5)
return out7 Discriminator에 필요한 Block 정의
def make_disc_block(input_channels, output_channels, kernel_size=3, stride=2, final_layer=False):
if not final_layer:
return nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size, stride),
nn.BatchNorm2d(output_channels),
nn.LeakyReLU(0.2)
)
else:
return nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size, stride)
)
def fullyconnected(in_channel,out_channel):
fc = nn.Linear(in_channel,out_channel)
return fc8 Discriminator 정의
class Discriminator(nn.Module):
def __init__(self, im_chan=3, hidden_dim=8):
super(Discriminator, self).__init__()
# Discriminator모델 구성하기
self.disc = nn.Sequential(
make_disc_block(im_chan, hidden_dim, kernel_size=4),
make_disc_block(hidden_dim, hidden_dim * 2),
make_disc_block(hidden_dim*2, hidden_dim * 4),
make_disc_block(hidden_dim*4, hidden_dim * 4),
make_disc_block(hidden_dim * 4, hidden_dim*2),
make_disc_block(hidden_dim * 2, 1,final_layer=True)
)
self.fc = fullyconnected(3*3, 1)
self.act = nn.Sigmoid()
def forward(self, image):
disc_pred = self.disc(image)
disc_pred = self.fc(disc_pred.view(len(disc_pred), -1)) # discriminator의 판별 결과 (0:fake, 1:real)
disc_pred = self.act(disc_pred)
return disc_pred.view(len(disc_pred), -1)9 하이퍼 파라미터 선언
img_size = 256
in_dim = 3
out_dim = 3
num_filters = 32
lr=0.000210 Discriminator와 Generator 선언
generatorG = UnetGenerator(in_dim=in_dim,out_dim=out_dim,num_filter=num_filters).to(device)
generatorF = UnetGenerator(in_dim=in_dim,out_dim=out_dim,num_filter=num_filters).to(device)
discriminatorDy = Discriminator().to(device)
discriminatorDx = Discriminator().to(device)11 가중치 초기화 함수 정의
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)12 각각의 Discriminator와 Generator 가중치 초기화
generatorG = generatorG.apply(weights_init)
generatorF = generatorF.apply(weights_init)
discriminatorDy = discriminatorDy.apply(weights_init)
discriminatorDx = discriminatorDx.apply(weights_init)13 Loss 및 Optimizer 선언
adversarial_loss=nn.BCELoss()
cycleConsistent_loss=nn.L1Loss()
identity_loss=nn.L1Loss()
optimizer_GG = torch.optim.Adam(generatorG.parameters(), lr=lr, betas=(0.5, 0.999))
optimizer_GF = torch.optim.Adam(generatorF.parameters(), lr=lr, betas=(0.5, 0.999))
optimizer_Dy = torch.optim.Adam(discriminatorDy.parameters(), lr=lr, betas=(0.5, 0.999))
optimizer_Dx = torch.optim.Adam(discriminatorDx.parameters(), lr=lr, betas=(0.5, 0.999))14 모델 학습
import time
from tqdm.auto import tqdm
lambdaA=10
n_epochs=100
start_time = time.time()
for epoch in tqdm(range(n_epochs)):
for X,Y in tqdm((train_loader)):
X, Y = X.float().to(device), Y.float().to(device)
# ---------------------
# Train Discriminator
# ---------------------
optimizer_Dy.zero_grad()
optimizer_Dx.zero_grad()
dis_real_X=discriminatorDx(X)
dis_real_Y=discriminatorDy(Y)
Y_hat_forward = generatorG(X) #여름사진을 겨울사진으로
X_hat_forward = generatorF(Y) #겨울사진을 여름사진으로
dis_fake_Y=discriminatorDy(Y_hat_forward)
dis_fake_X=discriminatorDx(X_hat_forward)
#discriminatorDy에 대한 adversarial loss
real_loss_Dy = adversarial_loss(dis_real_Y, torch.ones_like(dis_real_Y))
fake_loss_Dy = adversarial_loss(dis_fake_Y, torch.zeros_like(dis_fake_Y))
d_loss_Dy = ((real_loss_Dy + fake_loss_Dy)/2)
#discriminatorDx에 대한 adversarial loss
real_loss_Dx = adversarial_loss(dis_real_X, torch.ones_like(dis_real_X))
fake_loss_Dx = adversarial_loss(dis_fake_X, torch.zeros_like(dis_fake_X))
d_loss_Dx = ((real_loss_Dx + fake_loss_Dx)/2)
#discriminator full loss
Ld=d_loss_Dy+d_loss_Dx
Ld.backward(retain_graph=True)
optimizer_Dy.step()
optimizer_Dx.step()
# -----------------
# Train Generator
# -----------------
optimizer_GG.zero_grad()
optimizer_GF.zero_grad()
Y_hat_forward = generatorG(X) #여름사진을 겨울사진으로
X_hat_forward = generatorF(Y) #겨울사진을 여름사진으로
Y_hat_backward = generatorG(X_hat_forward) #여름사진을 겨울사진으로 바꾼 것을 다시 여름사진으로
X_hat_backward = generatorF(Y_hat_forward) #겨울사진을 여름사진으로 바꾼 것을 다시 겨울사진으로
#양방향에 대한 cycle consistency loss
cycle_forward=cycleConsistent_loss(X,X_hat_backward)
cycle_backward=cycleConsistent_loss(Y,Y_hat_backward)
Lcyc=lambdaA*(cycle_forward+cycle_backward)
#generatorG에 대한 adversarial loss
dis_fake_Y=discriminatorDy(Y_hat_forward)
g_loss_Y = adversarial_loss(dis_fake_Y,torch.ones_like(dis_fake_Y))
#generatorF에 대한 adversarial loss
dis_fake_X=discriminatorDx(X_hat_forward)
g_loss_X = adversarial_loss(dis_fake_X,torch.ones_like(dis_fake_X))
#identity loss
Lidentity=0.5*lambdaA*(identity_loss(generatorG(Y),Y)+identity_loss(generatorF(X),X))
#generator에 대한 총 adversarial loss
Lgan=g_loss_Y+g_loss_X
#generator full loss
Lg=Lcyc+Lgan+Lidentity
Lg.backward(retain_graph=True)
optimizer_GG.step()
optimizer_GF.step()
print('[epoch {}/{}] [D loss: {:.6f}] [G loss: {:.6f}] [Elapsed time: {:.2f}s]'.format(epoch,n_epochs,Ld,Lgan,time.time() - start_time))#에폭의 마지막 loss만 뽑아봄
#output 결과 확인
predict=Y_hat_forward[0].detach().cpu().numpy()
predict=0.5*(predict+1)
X=X[0].detach().cpu().numpy()
X=0.5*(X+1)
Y=Y[0].detach().cpu().numpy()
Y=0.5*(Y+1)
plt.figure(figsize=(16,18))
plt.subplot(1,3,1)
plt.imshow(np.transpose(X,(1,2,0)))
plt.subplot(1,3,2)
plt.imshow(np.transpose(Y,(1,2,0)))
plt.subplot(1,3,3)
plt.imshow(np.transpose(predict,(1,2,0)))
plt.show()
#모델 저장
torch.save(generatorG.state_dict(), 'model_generatorG_s2w_.pt')
torch.save(generatorF.state_dict(), 'model_generatorF_s2w_.pt')
torch.save(discriminatorDy.state_dict(), 'model_discriminatorDy_s2w_.pt')
torch.save(discriminatorDx.state_dict(), 'model_discriminatorDx_s2w_.pt')15 Test를 위해 모델 불러오기
generatorG.load_state_dict(torch.load('model_generatorG_s2w.pt'))
generatorF.load_state_dict(torch.load('model_generatorF_s2w.pt'))16 Test Dataset에 적용할 transform 함수 정의
trans = albumentations.Compose([
albumentations.Resize(256, 256),
albumentations.augmentations.transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
],additional_targets={'image2':'image'})17 Test Dataset과 Dataloader 선언
test_dataset = MyDataset(test_X_files,test_Y_files,transform=trans)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=1,shuffle=False)18 모델 Test
generatorG.eval()
generatorF.eval()
discriminatorDy.eval()
discriminatorDx.eval()
cur_step=0
with torch.no_grad():
for X,Y in tqdm(test_loader):
X,Y=X.float().to(device), Y.float().to(device)
winter=generatorG(X).detach().cpu()
summer=generatorF(Y).detach().cpu()
if cur_step % 10 == 0 and cur_step > 0:
X=X[0].detach().cpu().numpy()
X=0.5*(X+1)
Y=Y[0].detach().cpu().numpy()
Y=0.5*(Y+1)
winter=winter[0].detach().cpu().numpy()
winter=0.5*(winter+1)
summer=summer[0].detach().cpu().numpy()
summer=0.5*(summer+1)
print("summer->winter")
plt.figure(figsize=(16,18))
plt.subplot(1,2,1)
plt.imshow(np.transpose(X,(1,2,0)))
plt.subplot(1,2,2)
plt.imshow(np.transpose(winter,(1,2,0)))
plt.show()
print("winter->summer")
plt.figure(figsize=(16,18))
plt.subplot(1,2,1)
plt.imshow(np.transpose(Y,(1,2,0)))
plt.subplot(1,2,2)
plt.imshow(np.transpose(summer,(1,2,0)))
plt.show()
cur_step += 1결과 및 구현 후기
- GAN의 대표적인 단점인 불안정성때문인지, 코드 문제인지는 모르겠지만 학습이 될 때가 있고 안 될 때가 있었습니다. 이에 대한 코멘트 너무너무 환영합니다ㅠㅠ
- Discriminator와 Generator의 수준이 비슷해야 균형적이게 잘 학습되는데 처음에는 잘 몰라 Discriminator를 너무 똑똑?하게 만들어 학습되지 않는 현상을 경험해봤습니다. 그래서 Discriminator의 layer와 파라미터 수를 줄여가며 균형을 찾아갔습니다.
- 보통의 모델들은 loss를 기준으로 모델을 저장하지만 GAN은 다른 경우이다보니 저장 기준을 모르겠어서 매 epoch마다 저장했습니다. 찾아보니 이또한 현재 활발히 연구되고 있는 주제 중 하나란 것을 알게 되었습니다
만약 제 코드에서 오류를 발견하신다면 댓글로 코멘트 부탁드립니다 !!!!
참고
