GAN은 알겠는데, 그래서 어떤 GAN이 더 좋은건데? Evaluating Generative Adversarial Networks

👨🎓❓GAN의 성능은 도대체 어떻게 평가⚖해야 할까?

Generative Adversarial Networks, 줄여서 GAN은 2014년도에 Ian J. Goodfellow의 논문을 거쳐 오늘날까지 여러 논문들이 나오면서 큰 발전을 이루고 있다. 하지만, GAN의 성능을 평가하기 쉽지 않다. 왜냐하면 적당한 객관적인 평가 기준이 없기 때문이다.
평가 기준이 없다는 것은 당연히 문제가 될 수 밖에 없는데, 구체적으로
- 훈련 중 최종 GAN 모델 선택
- GAN의 기능을 시연하기 위해 생성된 영상을 선택
- GAN의 아키텍처 비교
- GAN의 구성 비교
위와 같은 상황에 문제가 생긴다.
👩💻🔎Manual Evaluation

사람이 직접 육안으로 GAN의 성능을 평가하는건 가장 일반적이고 직관적인 방법 중 하나이다. 이 방법은 보통 AMT를 사용하여 각각의 에포크(epoch)마다 생성된 이미지를 평가한다.
이 방법은 매우 간단한 방법이다. 하지만, 평가하는 사람에 따라(고정관념, 편견 등) 지표가 나누어지기 때문에 주관적이고, 평가하는 사람의 도메인 지식의 영향이 크기 때문에 적용할 수 있는 분야가 한정적이며, 심지어 Mode-collapse과 같은 현상을 잡아낼 수 없다.
Mode Collapse이란?

위와 같이 생성기가 항상 판별자에게 가장 그럴듯 해 보이는 이미지를 보여주기 위해 같은 이미지를 계속 생성하는 현상이다.
👨👧👧💻Qualitative(질적) GAN Generator Evaluation
📍Qualitative란?
예를 들어 "100명의 사람이 있다고 했을때 100명 중 웃고 있는 사람은 50명, 울고 있는 사람은 10명, 무표정인 사람은 40명이다."와 숫자로 표현할 수 없는 것을 의미한다.
질적 척도는 보통 인간의 주관적 평가가 수반되는 경우가 많다.
- Nearest Neighbors: 과적합(overfitting)을 감지하기 위해 생성된 이미지들을 교육 이미지의 가장 가까운 이웃 옆에 표시한다.
- Rapid Scene Categorization: 짧은 시간(100ms) 내에 생성된 이미지와 실제 이미지를 구별한다.
- Rating and Preference Judgment: 생성된 이미지의 적절도(fidelity)에 따라 모델의 등급을 매긴다.
- Evaluating Mode Drop and Mode Collapse: 알려진 모드(mode)가 있는 데이터 세트에서 모드는 생성된 데이터에서 모드 센터까지의 거리를 측정하여 계산한다.
- Investigating and Visualizing the Internals of Networks: Regards exploring and illustrating the internal representation and dynamics of models(space continuity) as well as visualizing learned features
🔨Rating and Preference Judgment
이 중 가장 많이 사용이 되는 qualitative GAN 생성기 모델은 Rating and Preference Judgment이다. 이 실험에서 인간 심판은 실제 및 생성된 이미지의 순위를 매기거나 비교를 한다.
🔧Rapid Scene Categorization
Rapid Scene Categorization 방법은 일방적으로 동일하지만, 이미지를 보고 평가하는 시간을 매우 짧게 제한하여 이 시간 동안 실제(real)인지 가짜(fake)인지 구별한다. 이미지는 종종 쌍으로(pair) 주어 인간 심판이 어떤 이미지가 더 현실적인지(더 real같은지) 구별한다. 점수 또는 등급은 여러 인간 심판들이 정한 평점의 평균이다.
해당 접근 방식의 큰 단점은 인간 심판의 성과(performance)가 고정적이지 않다는 점이다. 특히 생성된 이미지를 구별하는 방법에 대한 단서를 얻는 등 시간에 따라 개선이 될 수 있다.
🪓Nearest Neighbors
또 다른 인기 있는 접근 방법은 Nearest Neighbors이다. 이 경우는 도메인에서 실제 이미지의 예시를 선택하고 비교를 위해 하나 이상의 가장 유사한 생성된 이미지를 찾는다. Euclidean distance를 종종 유사한 이미지를 찾을때 쓴다. 이 접근 방식은 생성된 이미지가 얼마나 현실적인지 평가하기 위한 맥락으로 쓰기 유용하다.
👨💼📊Quantitative(양적) GAN Generator Evaluation
📍Qualitative란?
예를 들어 "100명의 사람이 있는데, 1살부터 100살까지 한 명씩 있다."와 숫자로 표현하고 측정할 수 있는 것을 의미한다. (이산형 자료 or 연속형 자료)
양적 척도를 구하는 방법은 매우 많다.
- Average Log-likelihood
- Coverage Metric
- Inception Score (IS)
- Modified Inception Score (m-IS)
- Mode Score
- AM Score
- Frechet Inception Distance (FID)
- Maximum Mean Discrepancy (MMD)
- The Wasserstein Critic
- Birthday Paradox Test
- Classifier Two-sample Tests (C2ST)
- Classification Performance
- Boundary Distortion
- Number of Statistically-Different Bins (NDB)
- Image Retrieval Performance
- Generative Adversarial Metric (GAM)
- Tournament Win Rate and Skill Rating
- Normalized Relative Discriminative Score (NRDS)
- Adversarial Accuracy and Adversarial Divergence
- Geometry Score
- Reconstruction Error
- Image Quality Measures (SSIM, PSNR and Sharpness Difference)
- Low-level Image Statistics
- Precision, Recall and F1 Score
🧪Average Log-likelihood
Goodfellow가 쓴 최초의 GAN 논문에서는 생성된 이미지의 품질을 알기 위해 Average Log-likelihood를 사용했다. 이 방법은 생성자가 얼마나 훈련 이미지의 분포를 잘 캡처하는지 추정하는 방식이다.
하지만 이 방식은 사소한 모델에 유리하며 시각적 충실도와 관련이 없다. 그럴 뿐만 아니라 고차원 공간에서 실제 가능성(likelihood)를 근사화하지 못하거나 모델의 순위(rank)를 매기지 못한다. 따라서 일반적으로 GAN 평가에 효과적이지 않다고 밝혀졌다.
최신 논문들을 기준으로 생성된 이미지를 평가하기 위하여 채택된 두 가지 지표는 바로 IS와 FID이다.
🎈Inception Score
IS(Inception Score)는 2016년에 “Improved Techniques for Training GANs"이라는 논문에 처음 제안이 되었으며, 현재 대부분의 논문들이 IS를 사용하여 선행 기술에 비해 개선된 점을 보여줄 때 많이 사용이 된다. 즉, GAN의 성능 평가에 널리 사용되는 지표이다.
생성된 이미지를 평가할 때 중요한 지표는 두 가지가 있는데, 첫 번째는 Fidelity(이미지의 질)이고, 두 번째는 Diversity(이미지의 다양성)이다.
IS는 이미지 목록을 가져와서 점수로 단일 부동 소수점 숫자를 반환한다. 이 점수는 두 가지를 동시에 측정한다.
- 이미지의 퀄리티(이미지의 품질)
- 이미지의 다양성
이 두 가지가 모두 사실이라면 점수가 높아진다. 둘 중 하나 또는 둘 다 거짓이라면 점수는 낮아진다. 이는 GAN이 다른 여러가지 이미지를 생성할 수 있음을 의미한다. 이 점수의 하한은 0이며, 수학적으로 가능한 가장 높은 점수는 무한대이지만, 실제로는 무한하지 않은 상한선이 나타날 수 있다.
https://stats.stackexchange.com/questions/351947/whats-the-maximum-value-of-kullback-leibler-kl-divergence
🎈🎈Inception Score는 어떻게 작동할까?
먼저, IS는 "Rethinking the Inception Architecture for Computer Vision" 논문에 나온 Inception v3를 사용하여 생성된 이미지를 분류한다. 구체적으로 각 이미지가 학습된 클래스들과 얼마나 많이 닮았는지, 그리고 알려진 클래스에 걸쳐 얼마나 다양한 이미지 세트를 캡처하는지를 단일 이미지에 대한 라벨의 확률 분포로 반환한다. (각 값은 0.0에서 1.0 사이의 값이며, 총합은 1.0이다.)
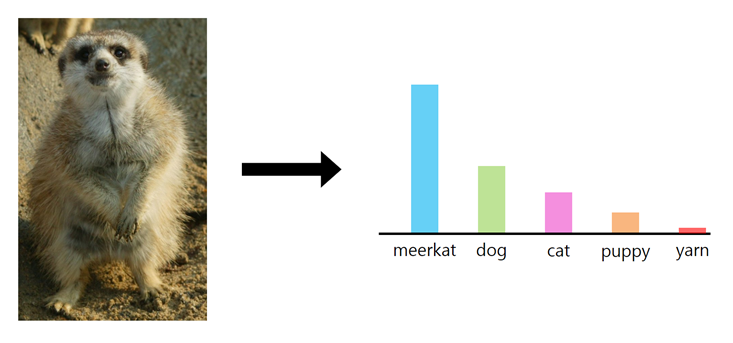
첫 번째 그림의 경우는 이미지에 올바른 형식이 하나만 포함되어 있으며 분류기의 출력은 좁은 분포이다. 즉, 하나의 피크에 집중을 하였다.
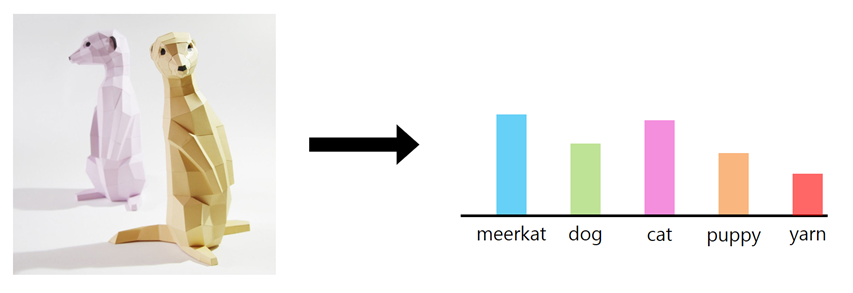
두 번째 분류기의 경우는 이미지가 여러 항목에 가깝게 포함이 되었기 때문에 유사한 높이의 막대들로 이루어진, 균일한 분포에 더 가깝다. 즉, 레이블 중 하나일 가능성이 같은 것이다.
GAN으로부터 만들어진 이미지를 분류기를 통해 생성된 이미지의 속성을 측정할 수 있다. 그 다음엔 생성된 많은 이미지들에 대한 레이블 확률 분포를 결합하는 것이다.
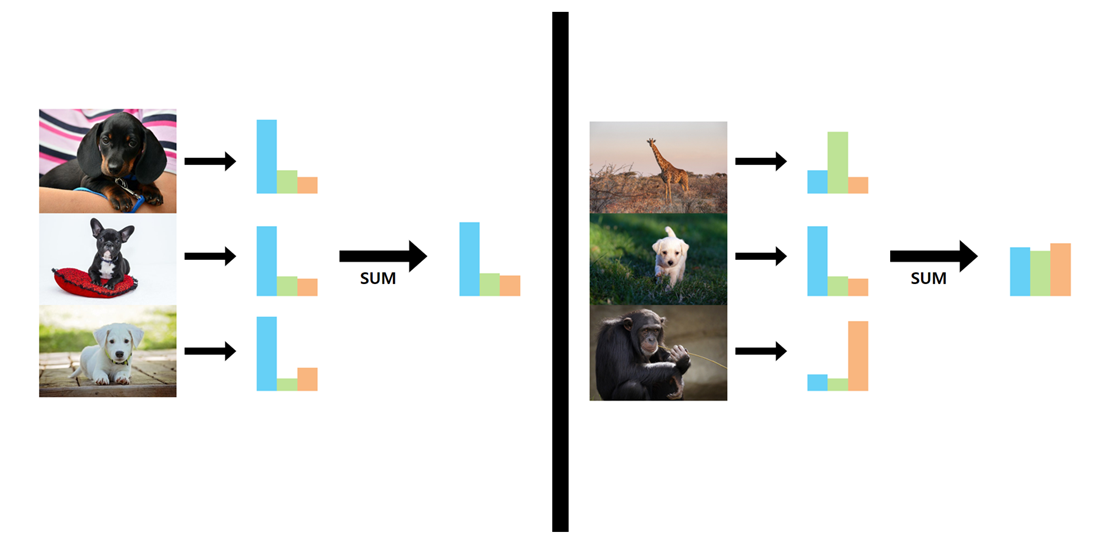
본 논문의 저자는 50,000개의 생성된 이미지 샘플들을 사용하여 라벨의 분포를 합산한 새로운 분포를 "marginal" 분포라고 명칭을 정했다. 이 marginal 분포는 생성기의 출력이 얼마나 다양한지를 알려준다.
이제 마지막 단계는 이미지가 뚜려하게 보이는지와 생성기의 출력에 다양성이 있는지를 하나의 점수로 결합하는 것이다. 다행히 모든 출력은 확률 분포이기 때문에 서로 비교할 수 있다.

위의 그림에서 좌측 부분과 같이 각 이미지가 각각의 Label에 따라 분류가 잘 되고, 동시에 우측 부분과 같이 집합적으로 다양성을 갖는 것이 목표이다. 따라서 각 이미지의 Label 분포를 전체 이미지 세트의 marginal label 분포와 비교하면 얼마나 다른지 점수를 얻을 수 있다. 더 많이 다를수록 점수가 더 높아지는 개념인 것이다.
이 점수를 생성하기 위해 Kullback-Leibler divergence(KL 발산)를 사용하는데, KL 발산은 두 확률 분포가 얼마나 유사하거나 다른지에 대한 척도이다.
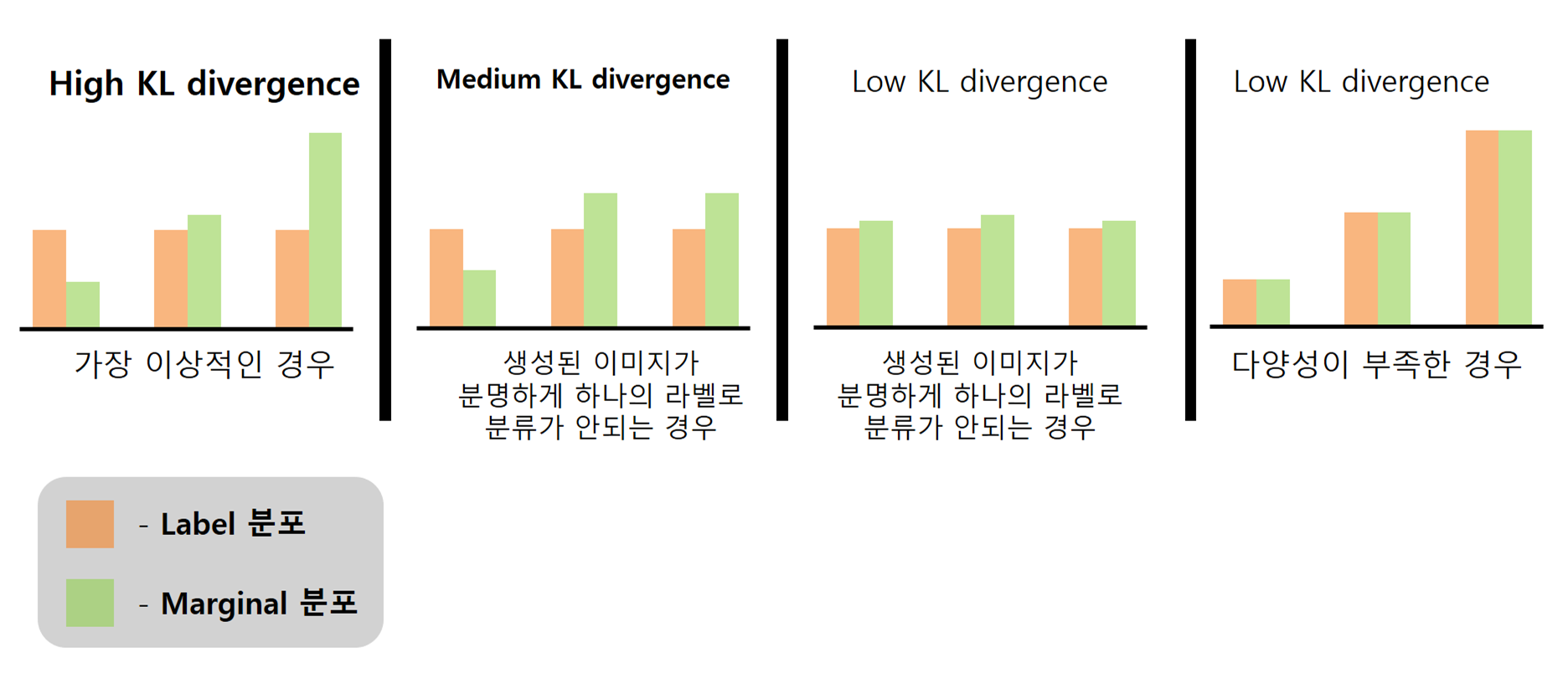
요약하자면, 위의 그림의 좌측 부분과 같이 각각의 생성된 이미지에 대해 고유 Label이 있으며, 동시에 생성된 이미지의 전체 집합이 다양한 범위의 Label을 가질때 점수가 가장 높다. 이 점수가 바로 Inception Score이다!!
🎈🎈🎈 Inception Score의 한계점
Inception Score의 한계점은 "A Note on the Inception Score" 논문에 나와있다.
- 분류기의 훈련 데이터 세이트에 없는 무언가를 생성하는 경우

예를 들어 Glass Frog의 경우는 ILSVRC 2014 dataset에 포함되지 않는다. 만일 Glass Frog의 이미지를 고품질로 생성하더라도 해당 이미지가 특정 Label로 분류가 되지 않기 때문에 항상 낮은 IS를 받을 수 맊에 없다.
https://image-net.org/challenges/LSVRC/2014/browse-synsets.php
- 분류기의 훈련 데이터와 다른 레이블 세트를 사용하여 이미지를 생성하는 경우

만일 개미 데이터셋으로 GAN의 학습을 진행한 경우에는 당연히 개미 사진만 생성을 하게 되므로 즉, 다양성이 부족하다고 판단이 되기 때문에 IS 점수가 낮다.
- 분류기 네트워크가 이미지 품질 개념과 관련된 특징을 감지 할 수 없는 경우
ICCV 2019에 소개된 "SRM : A Style-based Recalibration Module for Convolutional Neural Networks" 논문과 같이 이미지 분류 네트워크는 content보다 style을 더 중요하게 여긴다.
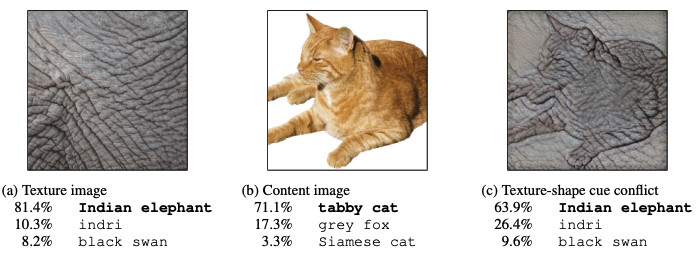
이처럼 만일 (c) 부분과 같은 이미지를 GAN이 생성하다러다도 이미지 분류 네트워크는 텍스쳐에 포커스를 더 맞추는 경향이 있기 때문에 인간의 눈으로는 좋은 결과물이 아니더라도 높은 IS 점수를 받을 수 있다.
- 생성기가 이미지의 클래스(라벨) 당 하나의 이미지만 생성하고 각 이미지를 여러번 반복하는 경우

만일 위와 같이 여러 클래스에 대해 좋은 품질의 같은 이미지를 생성하는 경우는 어떻게 될까?
이렇게 되면 높은 IS의 조건에 충족하기 때문에 높은 점수를 받는다. 이처럼 IS는 클래스 내의 다양성을 측정할 수 없다.
- 생성기가 훈련 데이터를 그대로 기억하고 복제하는 경우

훈련 데이터를 GAN이 그대로 복제해버린다면 이 역시 마찬가지로 높은 IS의 조건에 충족한다. 하지만, GAN의 목적인 실제같은 가짜 이미지를 생성하는 것이 아니기 때문에 이는 곧 IS의 한계점이라고 볼 수 있다.
❄️Frechet Inception Distance
FID(Frechet Inception Distance)점수는 실제 이미지와 생성된 이미지에 대해 computer vision 특징에 대한 통계 측면에서 두 그룹이 얼마나 유사한지 즉, 벡터 사이의 거리를 계산하는 메트릭이다.
이 점수가 낮을수록 두 그룹의 이미지가 더 유사하거나 통계가 더 유사하다는 뜻이기 때문에 점수가 낮을수록 성능이 좋다. 참고로 만점은 0.0이다.
FID 점수는 GAN의 의해 생성된 이미지의 품질을 평가하는데 사용되며, 낮은 점수는 고품질 이미지와 잘 연관된다.
❄️❄️FID란 무엇인가?
이제 본격적으로 FID가 왜 나오게 되었고, 무엇인지에 대해 알아보겠다.
FID는 “GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium.”이라는 논문에서 처음 제안이 되었으며, 기존의 IS(Inception Score)를 개선시키기 위해 오직 GAN의 성능 평가를 위해 특별히 개발이 되었다.
Inception Score는 생성된 이미지만 사용하여 성능을 평가하는 반면, FID는 대상 도메인의 실제 이미지 모음 통계와 생성된 이미지 모음 통계를 비교해 평가를 진행한다.
이미지의 평균과 공분산을 계산하여 다변량 가우시안(multivariate Gaussian)으로 요악한 뒤, 이러한 두 분포 사이의 거리는 Wasserstein-2 distance라고 불리는 Frechet distance를 사용하여 측정이 된다.
❄️❄️❄️ 어떻게 FID를 계산할까?
FID는 먼저 pretrained된 Inception v3를 사용한다. 정확히는 Inception v3에서 출력 레이어를 제거하고 출력이 마지막 풀링 레이어의 활성화(activation)을 사용한다. 이 출력 레이어에는 총 2,048개의 활성화(activation)이 있으므로, 각 이미지는 2,048개의 활성화 특징으로 예측이 된다.
먼저, 실제 이미지가 표현되는 방법을 참조하기 위해 생성할려는 도메인의 실제 이미지 모음에 대한 2,048개의 특징 벡터를 구한다. 그리고 생성된 이미지에 대한 특징 벡터도 구한다.
이렇게 구한 벡터들을 활용해 위의 식과 같은 논문의 방정식을 거쳐 FID 점수를 구한다. 위의 식에서 점수를 d^2로 표현하며, 이는 곧 거리(distance)이며 제곱 단위이다.
m과 m_c는 각각 실제 이미지 및 생성된 이미지의 기능별 평균(feature-wise mean)을 나타내며 이때 2,048개의 벡터에서 각 요소는 이미지에서 관찰되는 평균 특징이다.
C와 C_w는 sigma 즉, 실제 특징 벡터와 생성된 벡터에 대한 공분산 행렬이다.
||m - m_w||^2는 두 평균 벡터간의 합계 제곱 차이다. 그리고 Tr은 대각합을 나타낸다.
# example of calculating the frechet inception distance
import numpy
from numpy import cov
from numpy import trace
from numpy import iscomplexobj
from numpy.random import random
from scipy.linalg import sqrtm
# calculate frechet inception distance
def calculate_fid(act1, act2):
# calculate mean and covariance statistics
mu1, sigma1 = act1.mean(axis=0), cov(act1, rowvar=False)
mu2, sigma2 = act2.mean(axis=0), cov(act2, rowvar=False)
# calculate sum squared difference between means
ssdiff = numpy.sum((mu1 - mu2)**2.0)
# calculate sqrt of product between cov
covmean = sqrtm(sigma1.dot(sigma2))
# check and correct imaginary numbers from sqrt
if iscomplexobj(covmean):
covmean = covmean.real
# calculate score
fid = ssdiff + trace(sigma1 + sigma2 - 2.0 * covmean)
return fid
# define two collections of activations
act1 = random(10*2048)
act1 = act1.reshape((10,2048))
act2 = random(10*2048)
act2 = act2.reshape((10,2048))
# fid between act1 and act1
fid = calculate_fid(act1, act1)
print('FID (same): %.3f' % fid)
# fid between act1 and act2
fid = calculate_fid(act1, act2)
print('FID (different): %.3f' % fid)
위의 코드는 NumPy를 사용하여 FID를 구현한 것이다.
TensorFlow의 공식 구현은 효율성을 위해 약간 다른 순서로 계산 요소를 구현하고 수치적 불안정성을 처리하기 위해 행렬 제곱근 주위에 추가 검사를 도입였다. 즉, 만일 FID를 계산하는데 문제가 발생한 경우는 공식 구현을 검토해야 한다.
Reference
Inception Score: https://medium.com/octavian-ai/a-simple-explanation-of-the-inception-score-372dff6a8c7a
Frechet Inception Score: https://machinelearningmastery.com/how-to-implement-the-frechet-inception-distance-fid-from-scratch/

Inception score 한계점 부분 직전 그림의 legend가 잘못된 것 같습니다. Marginal 과 label distribution 색이 서로 바뀌어 있는 것 아닌가요? (이와 별개로, 본문은 잘 읽었습니다!)