Faster RCNN은 RCNN 모델 군의 최상위 모델로 앞선 Fast RCNN의 단점이였던 selective search를 해결하기위해 RPN(region proposal network)를 도입하여 GPU연산이 가능해졌고 그로인해 RCNN 모델 군 중 real-time detection에 가장 근접한 모델이 되었으며 현재 object detection의 토대가 되는 모델이다.
Faster RCNN
Faster RCNN은 Fast RCNN의 거의 모든 부분을 상속한 모델이다. 대신 selective search를 통해 RoI를 추출하여 학습하는 과정대신 RPN이라는 구조를 만들어 GPU연산이 가능하게 만들었고 그에 필요한 anchor라는 개념을 추가하고 loss function 일부분을 수정하였다.
Architecture
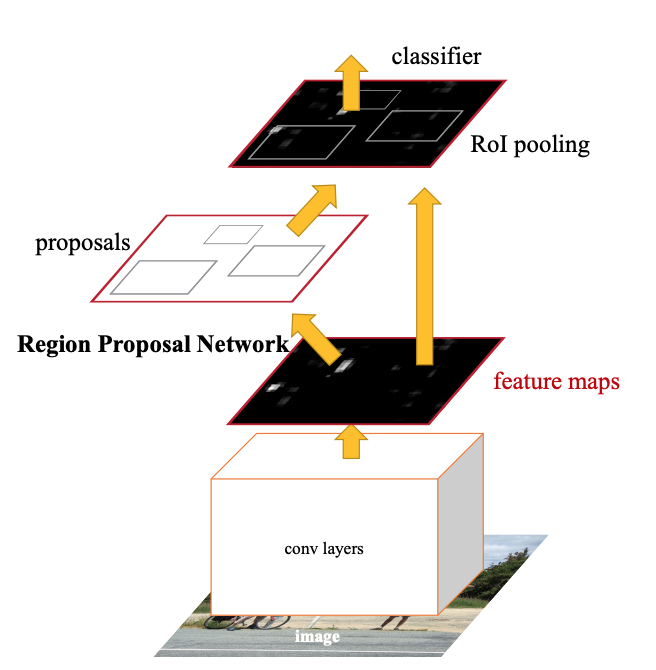
Faster RCNN의 기본적인 구조이다. Faster RCNN과 마찬가지로 backbone 모델을 통해 feature map을 구한 뒤 RPN 전달한 뒤에 bounding box regressor와 해당 위치에 object가 있을 확률값과 x,y,w,h를 리턴한다. 리턴받은 값을 가지고 기존 feature map에 투영한 뒤 RoI pooling을 통해 classifier에 전달해 최종적인 결과를 얻게된다.
- backbone을 통해 feature map을 구함
- 해당 feature map을 RPN 전달
- RPN에서 anchor box를 생성하여 각 box마다 object가 있을 확률과 박스 정보를 리턴
- 리턴값을 기존 feature map에 투영하여 RoI pooling
- pooling된 RoI를 classifier에 전달
Anchor Box
anchor box란 selective search로 찾은 RoI와 비슷하다. 차이점은 알고리즘을 이용해 명확한 후보들을 제안받는 것이 아닌 sub-sampling한 feature map에서 각 grid마다 임의로 설정한 개의 anchor box 생성하여 각각의 anchor box마다 object 여부를 연산하는 것이다.
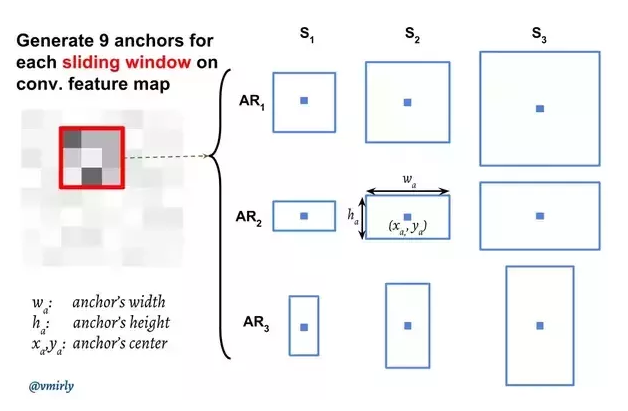
anchor box를 사용한다면 어떤 부분을 RoI로 봐야하는지 기준을 정하여야한다. 사진을 예시로하면 sliding window속 grid를 의 파란 사각형이고 gird를 중심으로 (1:1), (2:1), (1:2)의 비율을 가지는 서로 다른 9개의 anchor box를 각각의 RoI로 보고 연산을 한다

anchor box를 시각화한 사진은 다음과 같다.
input image size = 600x800
sub-sampling ratio = stride(factor) = 16
일 때 RPN에 전달되는 feature map size는
이 되는데 반올림하여
girds가 된다.
그리고 각 grid 중심에 9개의 anchor box를 생성하여 총 개의 box를 연산한다. 때문에 다양한 크기의 object를 detect 할 수 있다.
*stride(factor): sub-sampling ratio와 같은 이유는 원본 이미지에서 feature map 까지 줄어든 비율이기 때문이며 Tensorflow Faster rcnn모델의 pipeline.config 파일에도 height_stride: 16, width_stride: 16 작성되어있다.
- anchor box는 anchor generate layer에서만 만들어지며 사진들과 같이 실제로 박스를 만드는 것이 아닌 해당 범위 안에 있는 feature value를 계산하는 것이다.
- grid의 중심또한 가상의 점일 뿐이다. 컴퓨터의 pixel처럼 feature map이 표현할 수 있는 최소 영역이기 때문에 해당 그리드를 중심으로 상하좌우 범위만큼 anchor box로 설정한다면 grid의 중심에 box가 생성되는 것과 같다.
- anchor box의 scale은 w, h이고 aspect ratio는 w, h의 비율을 의미한다. box의 크기는 각 scale마다 비율이 1:1일 때를 보존하여 계산한다.
- 통상적으로 aspect ratio는 [0.5, 1, 2]로 사용하는데 코드상으로 구현하기 쉽기 때문이다.
예를 들어 aspect ratio가 1:2일 때 이면
->
한 변의 길이 이고 다른 한 변의 길이는 이 된다.
또한 이기 때문에 [1:2,1:1,2:1]은 [0.5,1,2]와 같다
> from math import sqrt
> print([[s*sqrt(r), s/sqrt(r)] for s in scales] for r in ratios])
>>[[5.656854249492381, 11.313708498984761]
>>[11.313708498984761, 22.627416997969522]
>>[22.627416997969522, 45.254833995939045]]
>>[[8.0, 8.0]
>>[16.0, 16.0]
>>[32.0, 32.0]]
>>[[11.313708498984761, 5.656854249492381]
>>[22.627416997969522, 11.313708498984761]
>>[45.254833995939045, 22.627416997969522]]RPN
RPN(region proposal network)는 기존의 selective search를 대체하기 위한 기법으로 anchor box를 생성하고 object 여부를 점수로 나타내고 해당 object의 left-top(x,y)좌표, w(width), h(height)를 반환한다.
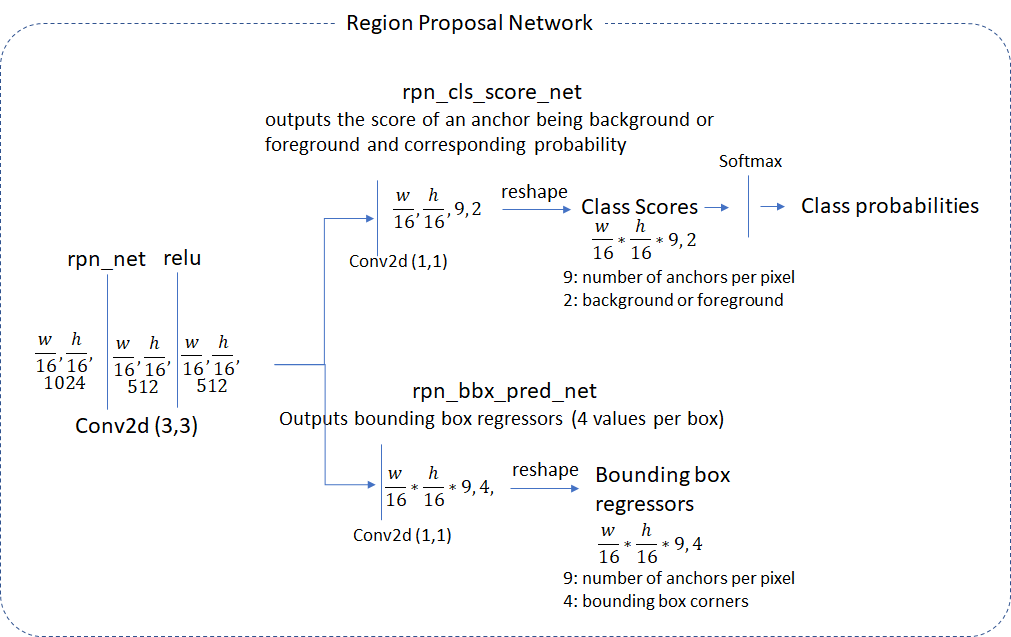
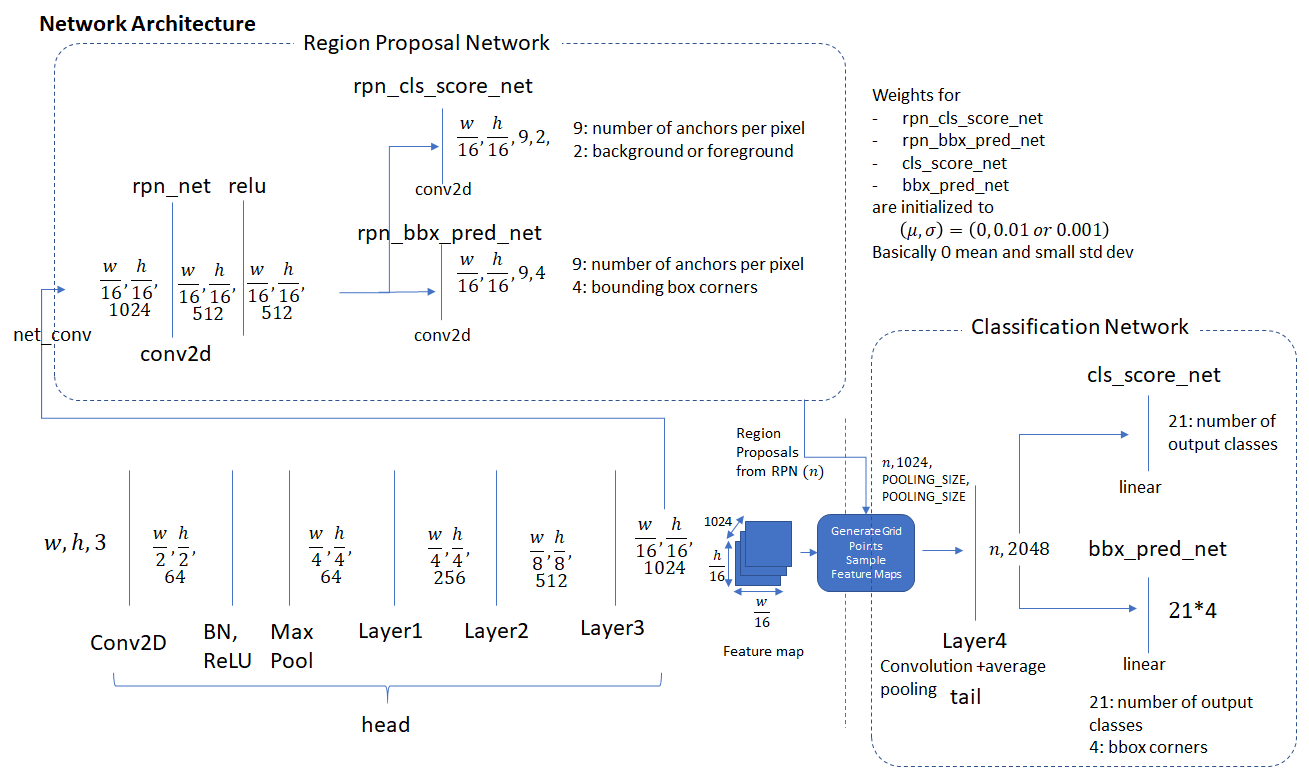
RPN의 내부 구조이다. 먼저 backbone에서 feature map을 입력받아 RPN 내부에서 (3,3)conv과 samepadding을 통해 resolution을 보존한 뒤 각각 classification과 bbox regression 연산을 수행한다. 그 후 class score 순으로 정렬한 뒤 상위 N개의 anchor box들만 NMS시킨 후에 도출된 정보를 기존의 feature map에 투영하여 RoI pooling을 거쳐 classifier에(Fast RCNN) 전달된다.
Loss Function
= mini-batch당 anchor box index
= 번째 anchor box가 object일 확률
= object이면(positive) 1, 아니면(negative) 0
= 예측한 bbox의 좌표
= ground truth와 positive anchor의 오차
= balancing parameter( = 10)
= 학습하는 class 갯수( = 256 mini-batch size)
= 학습하는 class 갯수( ~ 2400)
논문에선 RPN에서 학습할 때 positive anchor를 3가지 방법으로 할당한다고 설명한다.
- ground truth box와 가장 높은 IoU를 가지는 anchor box -> positive
- ground truth box와 IoU가 0.7 이상인 anchor box -> positive
- ground truth box와 IoU가 0.3 이하인 anchor box -> negative
이 때 하나의 GTbox(ground truth box)가 여러개의 anchor box를 positive anchor로 할당 할 수 있다고 한다. 또한 positive도 negative도 아니라면 훈련에서 제외된다고 말한다.
= 10주어 (log loss)와 의 가중치를 비슷하게 조절한다.
Translation-Invariant Anchors
논문에서 RPN의 특성으로 위치불변성(translation-invariace)을 설명한다. 기존의 multibox 방식은 객체의 위치가 바뀌면 객체라고 인식하지 못하는 한계가 있지만 RPN은 sliding window 기법으로 객체의 위치가 변하여도 잘 인식하다고 설명하고있다.
또한 가장 중요한 점은 파라미터의 수가 확연히 줄어든 것이다. 기존 GoogleNet의 multibox는 (4(x,y,w,h)+1(object)) X 800(number of box) X 1536(channle of feature map) = 개의 파라미터를 가지는 fully connected layer이지만 512(number of channel) X (4(x,y,w,h) + 2(object and score)) X 9 = 개의 파라미터를 가지는 fully convolution layer이기 때문에 overfitting의 위험도가 작다고 논문에서 설명하고있으며 학습 및 검증에도 빠른 속도를 보여줄 것이다.
Traning Faster RCNN
Faster RCNN은 end-to-end 학습이 가능하지만 앞선 RCNN모델들 처럼 3개의 모듈(backbone, RPN, classifier)을 따로 학습시킨다
- classifier를 제외한 RPN과 backbone을 학습
- RPN을 제외한 backbone과 classifier 학습
- RPN만 학습
- classifier만 학습
이처럼 각각의 모듈을 번갈아가며 학습하는 것을 alternating training이라고 논문에선 설명한다.
Reference
한국IT교육원 23년 3/6 ~ 3/10
Based on Andrew Ng
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Object Detection and Classification using R-CNNs
Design Anchor Boxes for Object Detection
갈아먹는 Object Detection [4] Faster R-CNN
논문 리뷰 - Faster R-CNN 톺아보기
Faster R-CNN 논문(Faster R-CNN: Towards Real-Time ObjectDetection with Region Proposal Networks) 리뷰
