1. MNIST

1.mnist 데이터셋을 불러오기
import tensorflow as tf
mnist = tf.keras.datasets.mnist #TensorFlow 의 Keras API를 사용하여 MNIST 데이터셋을 로드하기 위한 준비
#훈련 데이터와 테스트 데이터로 분할한다. (x_train,x_Test)이미지 데이터 (y_train,y_test)는 해당 이미지의 레이블 포함
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train/255, x_test/255 #이미지 데이터는 0~255까지의 픽셀을 가지고 있으며 이 값을 255나누어 0,1 사이의 값으로 정규화
2. TensorFlow를 사용하여 간단한 신경망 모델 구성
#TensorFlow를 사용하여 간단한 신경망 모델을 구성
# MNIST 데이터셋의 손글씨 숫자 이미지를 분류하기 위해 사용될 수 있다.
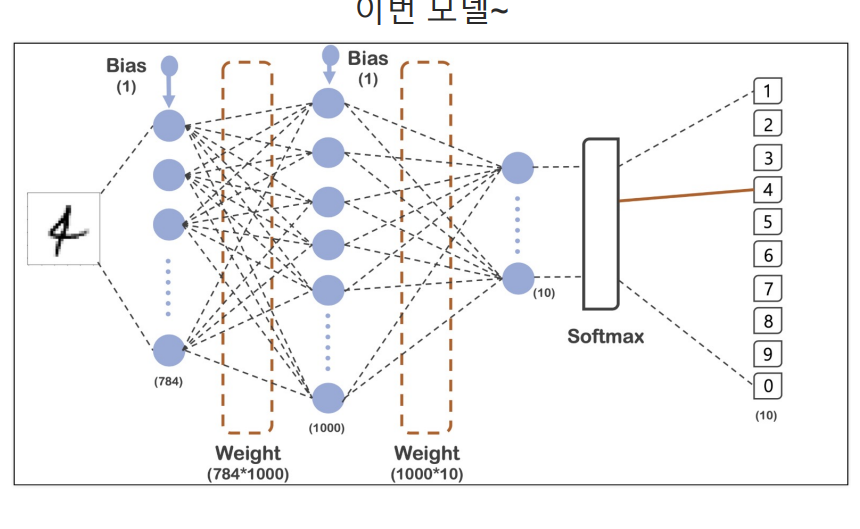
model = tf.keras.models.Sequential([#층을 순차적으로 쌓아 올릴 수 있는 모델을 만든다. 각 층은 입력 데이터를 받아 처리한 후 결과를 다음 층으로 전달
tf.keras.layers.Flatten(input_shape=(28,28)),# 이 층은 입력 이미지를 1차원 배열로 변환한다. MNIST 이미지는 28*28 픽셀이므로, 784개의 값을 가진 1차원 배열로 평탄화
tf.keras.layers.Dense(1000, activation = 'relu'),#이 층은 완전 연결(또는 밀집)층이다. 1000개의 뉴런 있으며 각 뉴런은 이전 층의 모든 뉴런과 연결
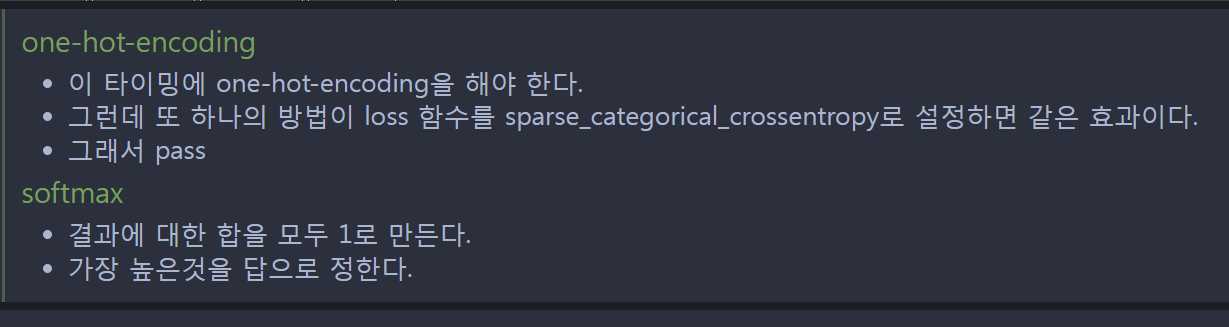
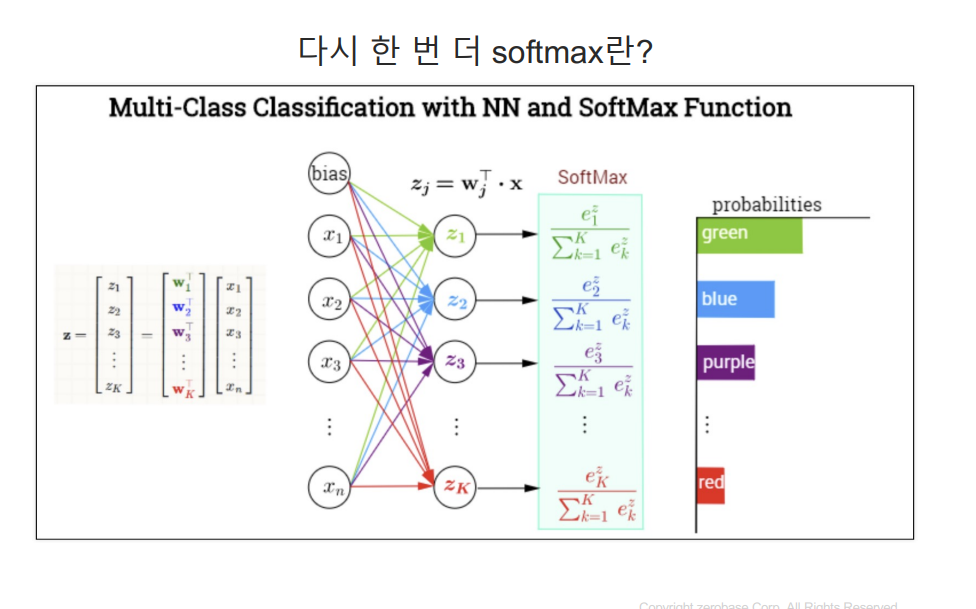
tf.keras.layers.Dense(10, activation = 'softmax')#이 층도 완전 연결 층 이층에는 10개의 뉴런이 있으며, MNIST 데이터셋의 10개 클래스(0~9까지의 숫자)해당
#활성화 함수로는 softmax가 사용되어 10개 클래스 각각에 대한 확률 분포를 출력한다.
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
#앞서 정의한 신경망 모델 컴파일 한다. 컴파일은 훈련을 ㅅ시작하기 전에 필요한 설정을 수행하는 단계
#optimizer:모델 훈련시 사용할 최적화 알고리즘을 지정한다. adam은 매우 효율적이고 계산 비용이 적으며, 별도의
#파라미터 조정 없이도 좋은 결과를 낼 수 있는 인기 있는 최적화 알고리즘
#loss 모델 오차 측정하는 손실 함수 지정 sparse_categorical_crossentropy는 다중 클래스 분류 문제에 사용되며, 레이블이 정수 형태로 제공될떄 사용
#이 손실 함수는 모델의 예측이 실제 레이블과 얼마나 차이가 나는지 측정한다.
#결론: 이코드는 MNIST 손글씨 숫자를 분류할 수 있는 신경망 모델이 생성된다. 이모델은 28*28 픽셀의 이미지를 입력으로 받아, 해당 이미지가
#어떤 숫자를 나타내는지에 대한 확률분포를 출력한다.
3.입력 데이터와 레이블을 받아, 주어진 에포크 동안 모델을 훈련시키면서 가중치를 업데이트한다.
hist = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=10, batch_size=100, verbose=1)
#validation_data: 모델을 훈련할 떄 동시에 검증할 데이터 세트를 지정 에포크 마다 모델의 성능을 검증 데이터 세트에서도 평가
#batch_size: 한번에 처리할 샘플의 수 지정
#verbose: 훈련 진행 상황을 어떻게 표시할지 지정 verbose=1은 진행 막대와 함께 에포크마다 손실 지표 출력 설정
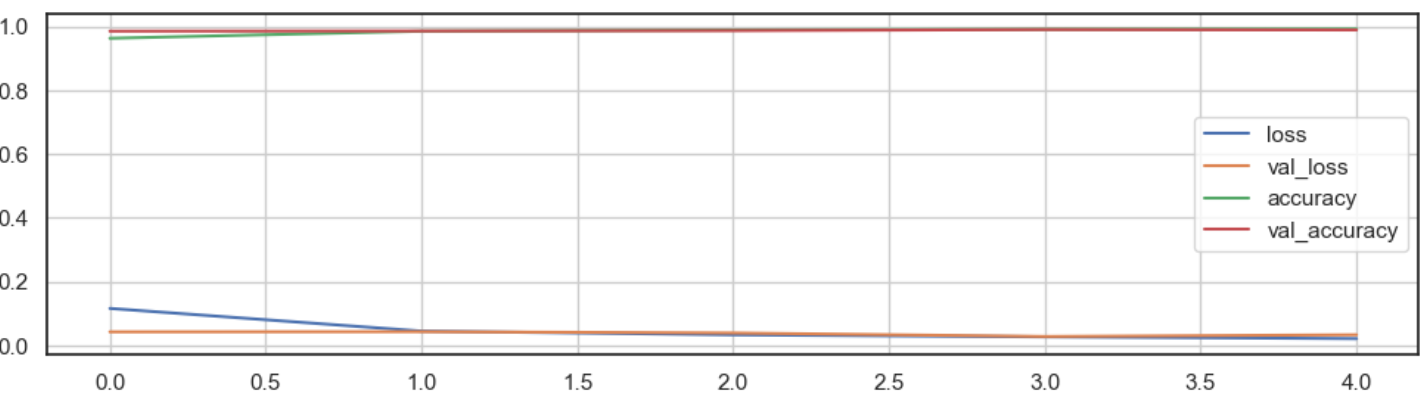
4. 시각화
#좋은 결과가 나왔다.
#이상적인 수렴 상황 그래프
import matplotlib.pyplot as plt
plot_target = ['loss','val_loss', 'accuracy','val_accuracy']
plt.figure(figsize=(12,5))
for each in plot_target:
plt.plot(hist.history[each], label=each)
plt.legend()
plt.grid()
plt.show()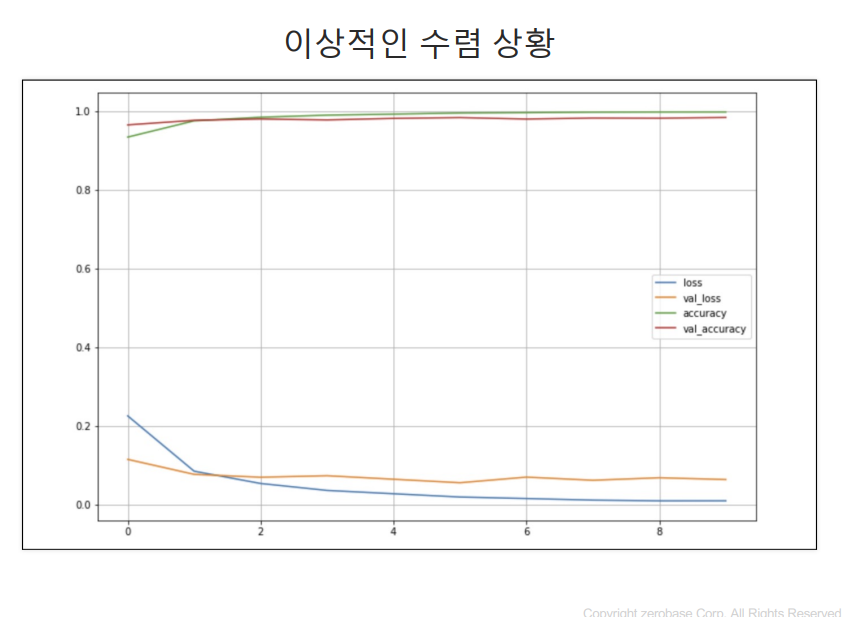
5. 모델 예측 수행
predicted_result = model.predict(x_test)
predicted_labels = np.argmax(predicted_result, axis=1) # 각 샘플에 대한 예측된 클래스를 찾기 위해 np.argmax 함수 사용
# axis=1 매개변수는 각 샘플의 10개 클래스에 대한 확률중 가장 높은 확률을 가진인덱스 찾도록 지시
predicted_labels[:10]
출력
array([7, 2, 1, 0, 4, 1, 4, 9, 5, 9], dtype=int64)
#라벨과 예측값 확인해보기
y_test[:10]
array([7, 2, 1, 0, 4, 1, 4, 9, 5, 9], dtype=uint8)
6. 예측에 실패한 갯수
wrong_result = []
for n in range(0, len(y_test)):
if predicted_labels[n] != y_test[n]:
wrong_result.append(n)
len(wrong_result)
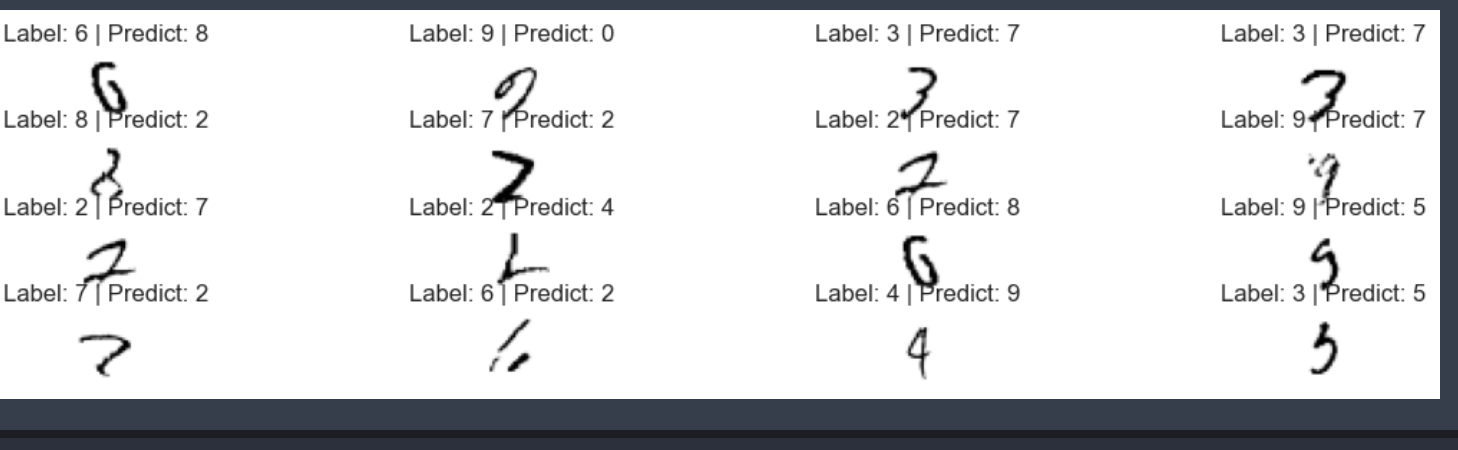
7. 실패한 예측 시각화 해보기
plt.figure(figsize=(14,3))
for idx, n in enumerate(samples):
plt.subplot(4, 4, idx+1)
plt.imshow(x_test[n].reshape(28,28), cmap = 'Greys')
plt.title('Label: '+ str(y_test[n]) + ' | Predict: ' + str(predicted_labels[n]))
plt.axis('off')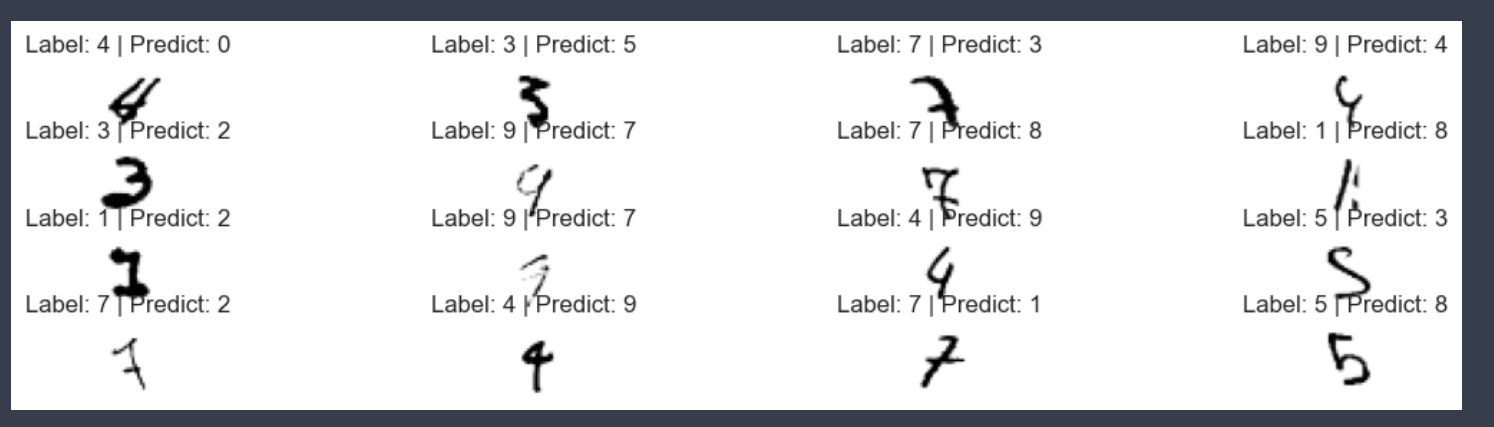
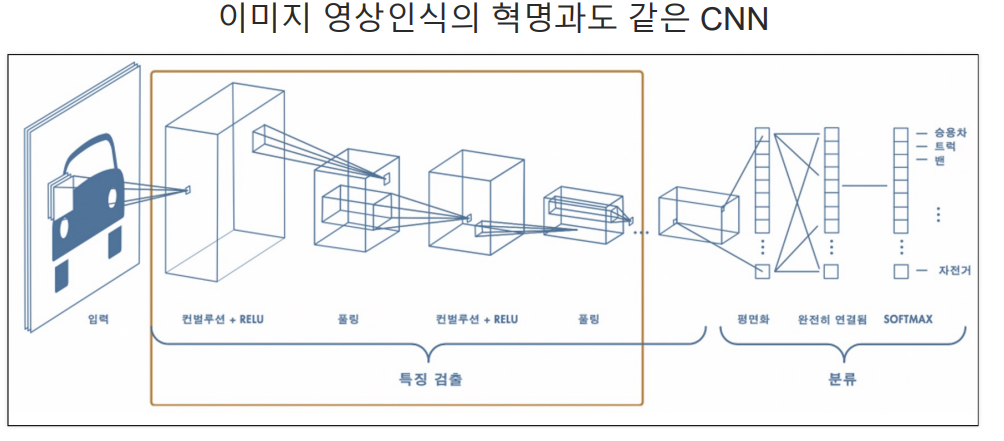
2. CNN
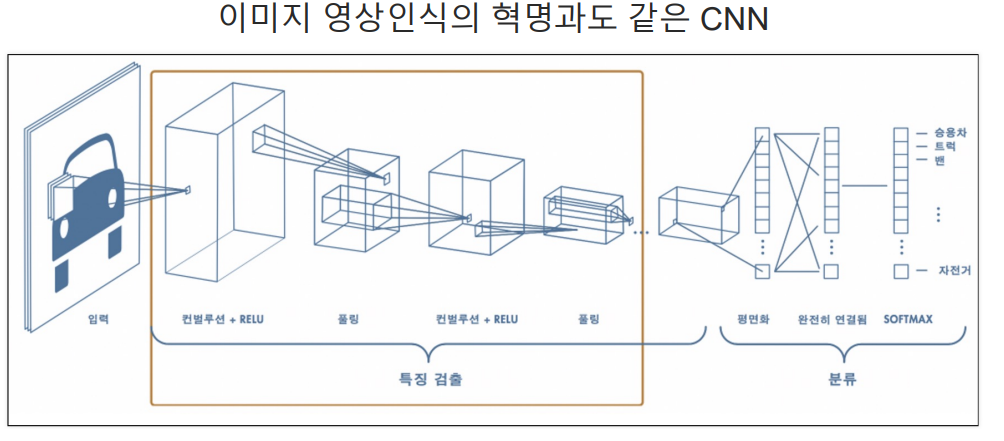
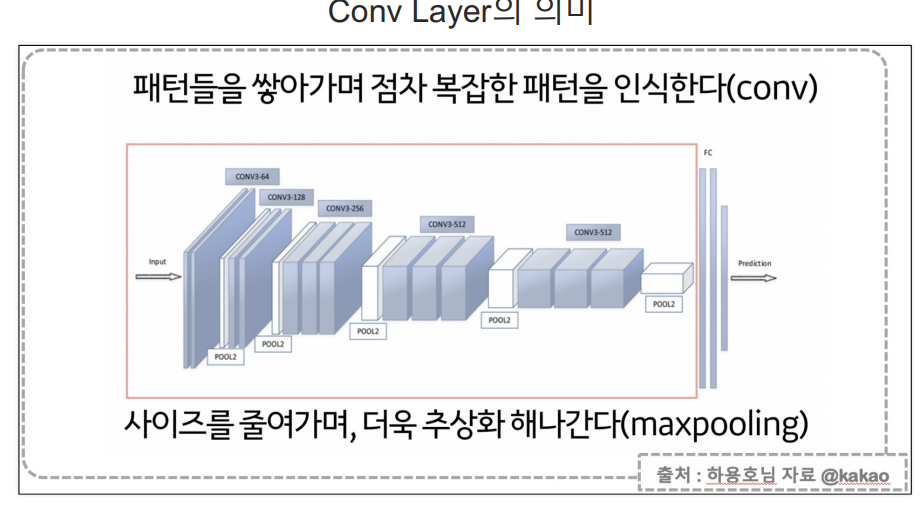
- Convolutional Nerual Network은 딥러닝에서 이미지 처리, 비디오 인식, 이미지 분류 등의
컴퓨터 비전 작업에 사용되는 신경망 - CNN은 구조가 입력 데이터의 형태를 고려하여 특별히 설계되었으며, 이미지와 같은 2차원 데이터를 처리할 때효과


- Convolutional Layer(합성곱 계층): 이미지의 지역적인 부분을 인식하기 위해 사용
- 작은 필터(혹은 커널) 사용하여 이미지 전체를 스캔하며, 필터와 이미지 간의 합성곱 연산 수행
- 이 과정을 통해 특징 맵(feature map)생성되며, 이미지에서 특정 패턴이나 특징을 강조한다.
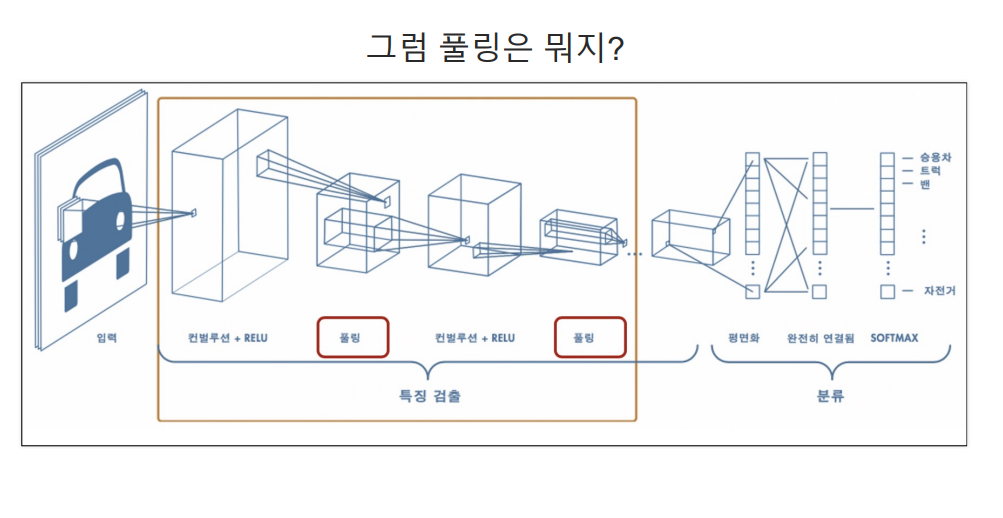




- Pooling Layer(풀링 계층)Convolutional Neural Network 에서 사용되며 특징 맵의 크기를
줄이고 중요한 정보를 유지하여 계산량을 감소시키고 과적합을 방지
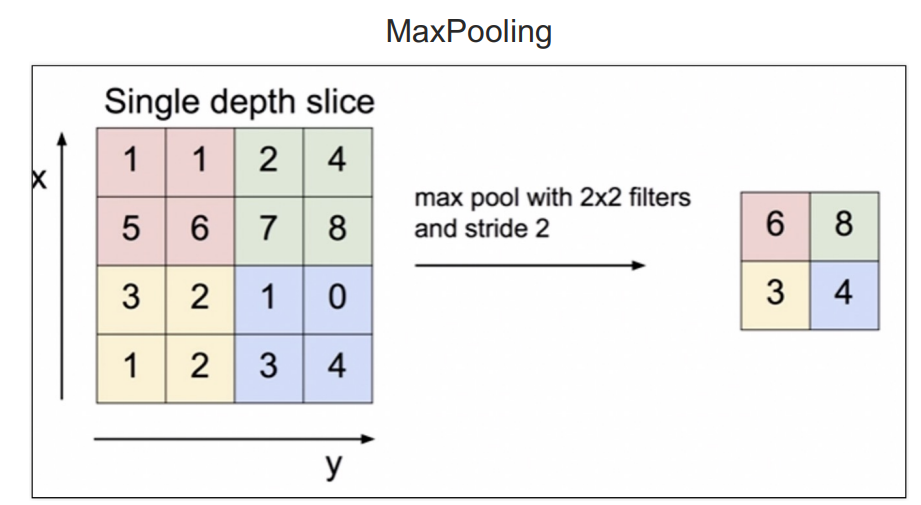
- Max Pooling(최대 풀링): 입력 영역에서 가장 큰 값을 선택하여 출력한다.
- 중요한 특징을 강조하고 덜 중요한 정보를 제거한다.
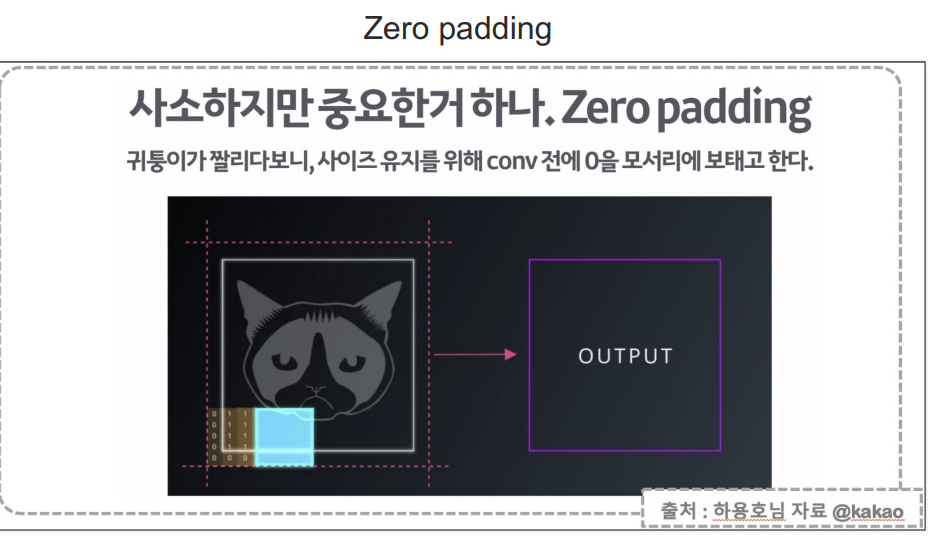
- Zero padding은 Convolutional Neural Network(CNN)에서 합성곱 계층(Convolutional Layer)을
적용할 때, 입력 데이터 주변을 0으로 채우는 기법이다. - 공간적 차원을 유지: 합성곱 연산을 수행할 때 입력 데이터의 크기가 축쇠되는 것을 방지하며 이를 통해
네트워크 깊이가 깊어져도 공간적 차원(너비와 높이)을 유지할 수 있다. - 경계 정보 활용: 입력 데이터의 가장자리 부분에 있는 정보도 중앙 부분과 동일하게 활용하며
이는 이미지의 가장자리에 중요한 정보가 위치할 때 중요하다.



- Droput 딥러닝 모델을 훈련할 때 과적합을 방지하기 위해 사용되는 기법 중 하나이다. 이방법은 훈련 과정에서
네트워크의 일부 뉴런을 무작위로 비활성화함으로 모델이 특정 뉴런에 지나치게 의존하는 것을 방지한다.
3. CNN 실습
1.데이터 받고정리
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
X_train, X_test = x_train/255, x_test/255
X_train = X_train.reshape((60000,28,28,1)) #6만개의 훈련 이미지를 (28,28) 크기의 2D 배열에서(28,28,1)
#크기의 3D 배열로 변환 여기서 1은 흑백 이미지를 나타내는 채널수
X_test = X_test.reshape((10000,28,28,1))
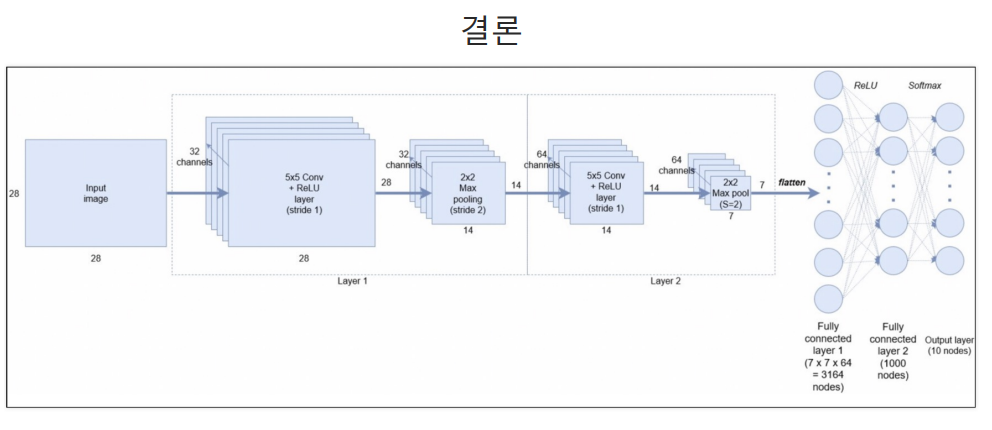
2. Convolutional Neural Network 모델 구축 예시
#CNN은 주로 이미지 분류, 객체 감지 등 태스크에 사용
from tensorflow.keras import layers, models
model = models.Sequential([
layers.Conv2D(32, kernel_size=(5, 5), strides=(1, 1), padding='same', activation='relu', input_shape=(28, 28, 1)),
#32개의 필터와(5,5)크기의 커널을 가진 합성곱 레이어, padding='same'는 입력과 출력의 크기를 동일하게 유지한다.
#input_shape=(28,28,1)은 입력 이미지의 크기를 (28,28) 흑백(1채널)설정
#
layers.MaxPool2D(pool_size=(2, 2), strides=(2, 2)),
#2,2크기의 풀링 윈도우를 사용하는 최대 풀링 레이어.
#strides2,2는 풀링 윈도우를 2픽셀씩 이동
layers.Conv2D(64, (2, 2), activation='relu', padding='same'),
#64개의 필터와 2,2 크기의 커널을 가진 또 다른 합성곱 레이어
layers.MaxPool2D(pool_size=(2, 2), strides=(2, 2)),
#두번쨰 최대 풀링 레이어
layers.Dropout(0.25),
#25%의 드롭아웃 비율을 가진 드롭아웃 레이어 이는 과적합 방지하기 위해 사용
layers.Flatten(),#다차원 입력을 1차원 배열로 평탄화 이것은 합성곱/풀링 레이어와 완전 연결 게리어 사이의 연결을 돕는다.
layers.Dense(1000, activation='relu'),
#1000개의 유닛을 가진 연결 레이어
layers.Dense(10, activation='softmax')
#10개의 유닛(클래스 수와 일치)을 가진 출력 레이어
#activation='softmax'는 다중클래스 분류를 위해 사용되며, 출력 값의 총합이 1이 되도록 활률을 반환
])
#요약: 이모델은 28*28 픽셀 크기의 흑백 이미지를 입력으로 받아, 10개의 다른 클래스 중 하나로 분류하는데 사용
#xe) MNIST 손글씨 숫자 분류
3. 모델 정보확인
model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 28, 28, 32) 832
max_pooling2d_4 (MaxPoolin (None, 14, 14, 32) 0
g2D)
conv2d_5 (Conv2D) (None, 14, 14, 64) 8256
max_pooling2d_5 (MaxPoolin (None, 7, 7, 64) 0
g2D)
dropout_2 (Dropout) (None, 7, 7, 64) 0
flatten_2 (Flatten) (None, 3136) 0
dense_4 (Dense) (None, 1000) 3137000
dense_5 (Dense) (None, 10) 10010
=================================================================
Total params: 3156098 (12.04 MB)
Trainable params: 3156098 (12.04 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
4. CNN 모델 컴파일
#최적화 알고리즘 Adam 사용 학습률을 자동으로 조절하는 기능을 가진 효율적인 최적화 알고리즘이다.
#loss 손실함수
#평가지표로 Accuracy 사용
model.compile(optimizer='adam', loss = 'sparse_categorical_crossentropy', metrics=['accuracy'])
5.훈련 과정에서 발생한 여러 이벤트에 대한 정보를 담은 History 객체 반환
#이객체를 사용하면 훈련과 검증 손실, 정확도 등의 값을 시각화하고 분석할수있다.
#validation_data: 검증 데이터셋 X_test, y_test (과적합되지 않고 일반화된 성능을 가지는지 확인하기 위함)
hist = model.fit(X_train, y_train, epochs=5, verbose=1, validation_data=(X_test, y_test))
6.시각화
#좋은 결과가 나왔다.
#이상적인 수렴 상황 그래프
import matplotlib.pyplot as plt
plot_target = ['loss','val_loss', 'accuracy','val_accuracy']
plt.figure(figsize=(12,5))
for each in plot_target:
plt.plot(hist.history[each], label=each)
plt.legend()
plt.grid()
plt.show()
8. 샘플 예측
predicted_result = model.predict(x_test)
predicted_labels = np.argmax(predicted_result, axis=1) # 각 샘플에 대한 예측된 클래스를 찾기 위해 np.argmax 함수 사용
# axis=1 매개변수는 각 샘플의 10개 클래스에 대한 확률중 가장 높은 확률을 가진인덱스 찾도록 지시
predicted_labels[:10]
#결과
array([7, 2, 1, 0, 4, 1, 4, 9, 5, 9], dtype=int64)
9. 잘못 예측 수 확인
wrong_result = []
for n in range(0, len(y_test)):
if predicted_labels[n] != y_test[n]:
wrong_result.append(n)
len(wrong_result)
#결과 110개
10. 시각화
samples = random.choices(population =wrong_result, k=16)
plt.figure(figsize=(14,3))
for idx, n in enumerate(samples):
plt.subplot(4, 4, idx+1)
plt.imshow(x_test[n].reshape(28,28), cmap = 'Greys')
plt.title('Label: '+ str(y_test[n]) + ' | Predict: ' + str(predicted_labels[n]))
plt.axis('off')
11. Accuracy 확인
score = model.evaluate(X_test, y_test)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
#출력
Test loss: 0.033526815474033356
Test accuracy: 0.9894999861717224
