NLP은 언어를 이해하고 처리하는 컴퓨터 프로그램을 개발하는 인공지능 분야
- 개념
- 텍스트 데이터 처리: NLP는 텍스트 데이터를 기본 단위로 취급
- 토큰화(Tokenization): 텍스트 데이터를 분할하여 처리하는 과정
- 텍스트 분류(Text Classification): NLP는 텍스트 데이터를 카테고리로 분류하는 작업에 사용된다. 스팸 이메일 감지, 감정 분석, 토픽 분류 등이 포함
- 감정 분석(Sentiment Analysis): NLP는 텍스트에 담긴 감정을 분석하고 이해하는 데 사용된다. 제품 리뷰, 소셜 미디어 게시물 등에서 사용자 의견을 추출하고 분석
- 워드 임베딩(Word Embeddings): NLP는 단어를 벡터로 표현하는 기술
이를 통해 단어 간 유사성을 계산하고, 머신러닝 모델에 텍스트 데이터ㅡㄹㄹ 입력으로 공급

1. KoNLPy 한국어 정보처리 파이썬 패키지
1.
from konlpy.tag import Kkma
kkma = Kkma() # Kkma 클래스의 인스턴스 생성
2. 형태소 분석
from konlpy.tag import Kkma
kkma = Kkma() # Kkma 클래스의 인스턴스 생성
#출력
[('한국어', 'NNG'),
('분석', 'NNG'),
('을', 'JKO'),
('시작하', 'VV'),
('ㅂ니다', 'EFN'),
('.', 'SF')]
4. 한나눔 엔진 nouns
from konlpy.tag import Hannanum
hannanum = Hannanum()
hannanum.nouns('한국어 분석을 시작합니다 재미있어요~~') #명사분석
#출력 ['한국어', '분석', '시작']
5. 한나눔 morphs
hannanum.morphs('한국어 분석을 시작합니다 재미있어요~~')
#출력 ['한국어', '분석', '을', '시작', '하', 'ㅂ니다', '재미있', '어요', '~~']
6. 한나눔 pos
hannanum.pos('한국어 분석을 시작합니다 재미있어요~~')
#출력
[('한국어', 'N'),
('분석', 'N'),
('을', 'J'),
('시작', 'N'),
('하', 'X'),
('ㅂ니다', 'E'),
('재미있', 'P'),
('어요', 'E'),
('~~', 'S')]
2.워드 클라우드(Word Cloud)
워드 클라우드: 텍스트 데이터에서 자주 등장하는 단어를 시각적으로 나타내는 기술
텍스트 데이터의 핵심 주제나 키워드를 빠르게 파악하고 시각적으로 표현
- 특징
- 주어진 텍스트 데이터에서 각 단어의 빈도를 계산한다.
- 시각적 표현: 워드 클라우드는 단어를 시각적으로 나타낸다. 빈도 높은 단어는 글씨가 크게 표현
- 색상 및 레이아웃: 워드 클라우드에는 단어의 색상과 배치를 설정한다.
from wordcloud import WordCloud, STOPWORDS
import numpy as np
from PIL import Image
1. 그림 가져오기
text = open(r'C:\Users\edgar\Desktop\제로베이스\머신러닝\자연어\06_alice.txt').read()
print(text)
2. 픽셀 이미지를 출력하면 숫자로 나온다.
alice_mask = np.array(Image.open(r'C:\Users\edgar\Desktop\제로베이스\머신러닝\자연어\06_alice_mask.png'))
alice_mask
#출력
array([[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255],
...,
[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255]], dtype=uint8)
3.불용어를 set 집합으로만들기
stopwords = set(STOPWORDS)
stopwords
#출력
{'a',
'about',
'above',
'after',
'again',
'against',
4. 특정 단어 said 제외시키기
stopwords.add('said')
5. array로 변환한 데이터 시각화
array로 변환한 alice_mask를 시각화하기
plt.figure(figsize=(8,8))
plt.imshow(alice_mask, cmap = plt.cm.gray, interpolation= 'bilinear')

2-1 WordCloud 모듈은 자체적으로 단어를 추출해서 빈도수를 조사하고 정규화하는 기능을 가지고 있다.
wc = WordCloud(
background_color = 'white', max_words=2000, mask = alice_mask, stopwords=stopwords #최대글자 2000 #mask는 현재 array 엘리스
)
wc = wc.generate(text) #generate는 텍스트 데이터에서 가장 빈번하게 등장하는 단어를 추출하고 워드 클라우드를 생성
wc.words_ #단어들의 발생빈도
{'Alice': 1.0,
'little': 0.29508196721311475,
'one': 0.27595628415300544,
'know': 0.2459016393442623,
'went': 0.226775956284153,
# 발생빈도 시각화
plt.figure(figsize= (12,12))
plt.imshow(wc)
plt.axis('off')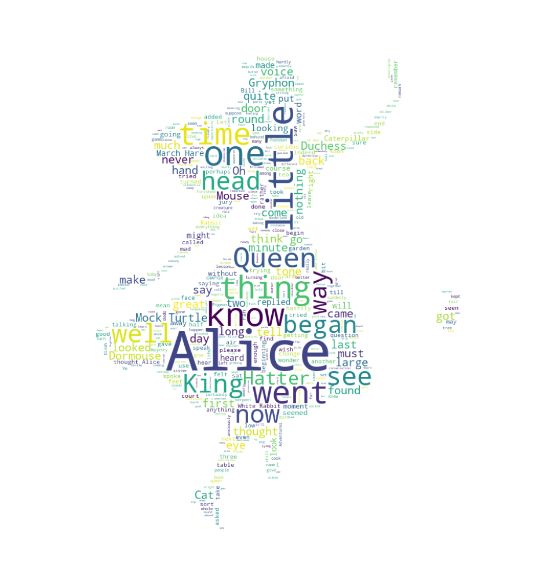
2-2 이미지 색깔 입히기
import random
#워드 클라우드에서 사용될 단어 색상 결정 함수
def grey_color_func(word, font_size, position, orientation, random_state=None, **kwargs): #orientation 단어의 방향, **kwargs 추가 키워드 인수
return 'hsl(0, 0%%, %d%%)' % random.randint(60, 100)
plt.figure(figsize=(12,12))
plt.imshow(wc.recolor(color_func = grey_color_func, random_state=13))
plt.axis('off')
plt.show()

3. 영어의 연어(collocation)

import nltk
# 불용어 데이터 다운로드
nltk.download('stopwords')
ko.collocations()
# 초등학교 저학년; 근로자 육아휴직; 육아휴직 대상자; 공무원 육아휴직
data = ko.vocab().most_common(150)
font_path = 'C:/Windows/Fonts/malgun.ttf' # 'Malgun Gothic' 폰트 경로
relative_scaling = 0.2
background_color = 'white'
wordcloud = WordCloud(
font_path=font_path,
relative_scaling=relative_scaling, #상대적인 크기를 조절하는 매개변수
background_color=background_color
).generate_from_frequencies(dict(data)) #빈도 정보를 입력으로 받아 워드 클라우드 이미지 생성
plt.figure(figsize= (12,8))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()

4. 나이브베이즈
- 기계 학습 분야에서 나이브 베이즈 분류 는 특성들 사이 독립을 가정하는 베이즈 정리를 적용한 확률 분류기의 일종
- 텍스트 분류에 사용됨으로 문서를 여러 범주(스팸, 스포츠, 정치)중 하나로 판단하는 문제에 대한 대중적인 방법으로 남아있다.
- 적절한 전처리를 하면 더 진보 된 방법들 서포트 벡터 머신과도 충분한 경잭력을 보임을 알 수 있다.
- skelarn에서는 fit를 사용하지만 나이브베이즈 에서는 train(t)사용
from nltk.tokenize import word_tokenize
import nltk
1.
# Naive Bayes 분류기는 지도학습이라서 정답을 알려주어야 한다.
train = [
('i like you', 'pos'),
('i hate you', 'neg'),
('you like me', 'neg'),
('i like her', 'pos'),
]
2.
train[0][0]
'i like you'
3.
# word_tokenize는 띄어쓰기를 기준으로 단어를 분리한다.
sentence = train[0]
word_tokenize(sentence[0])
['i', 'like', 'you']
4.
#코드설명: train 리스트에 있는 학습 데이터에서 텍스트를 토큰화하고 모든 단어를 소문자로 변환하여 집합(set)에 저장한다.
#결과로 출력되는 집합은 중복 단어를 제거한 모든 단어 집합
#즉 출력된 결과는 중복 단어가 제거되어 나타난 결과가 출력된다.
all_words = set(
word.lower() for sentence in train for word in word_tokenize(sentence[0])
)
all_words
#출력 {'hate', 'her', 'i', 'like', 'me', 'you'}
5.
t = [({word: (word in word_tokenize(x[0]))for word in all_words}, x[1]) for x in train]
t
#{word: (word in word_tokenize(x[0]))for word in all_words}, x[1] 이부분은 i like you 즉 train데이터의 문장 의미
# x[1]은 pos, neg
# word_tokenize(x[0])는 텍스트를 단어로 토큰화하는 작업 수행
#word in word_tokenize(x[0]) 단어가 해당 문장에 존재하는지 여부를 True ,False로 반환
#출력
[({'me': False,
'like': True,
'hate': False,
'her': False,
'i': True,
'you': True},
'pos'),
({'me': False,
'like': False,
'hate': True,
'her': False,
'i': True,
'you': True},
'neg'),....
6. 학습
classifier = nltk.NaiveBayesClassifier.train(t)
7.
classifier.show_most_informative_features() #가장 많은 정보를 가지고 있는 특성 나열
#해석 hate가 없을 확률이 pos가 1.7 확률로 pos
#her가 없을 확률이 1.7 활률로 neg
#출력
hate = False pos : neg = 1.7 : 1.0
her = False neg : pos = 1.7 : 1.0
i = True pos : neg = 1.7 : 1.0
8.
test_sentence = 'i like MeRui'
test_sent_features = {
word.lower(): (word in word_tokenize(test_sentence.lower())) for word in all_words
}
test_sent_features
#출력
{'me': False,
'like': True,
'hate': False,
'her': False,
'i': True,
'you': False}
9. 결과 출력
classifier.classify(test_sent_features)
#만들어낸 말뭉치와 데이터에 의해서 학습 해본 결과 'i like MeRui' pos가 되었다.
