import pandas as pd
# CSV 파일 경로
csv_file_path = r'C:\Users boston.csv'
df = pd.read_csv(csv_file_path, sep='\s+')
df.columns = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'PRICE']
boston = df
boston
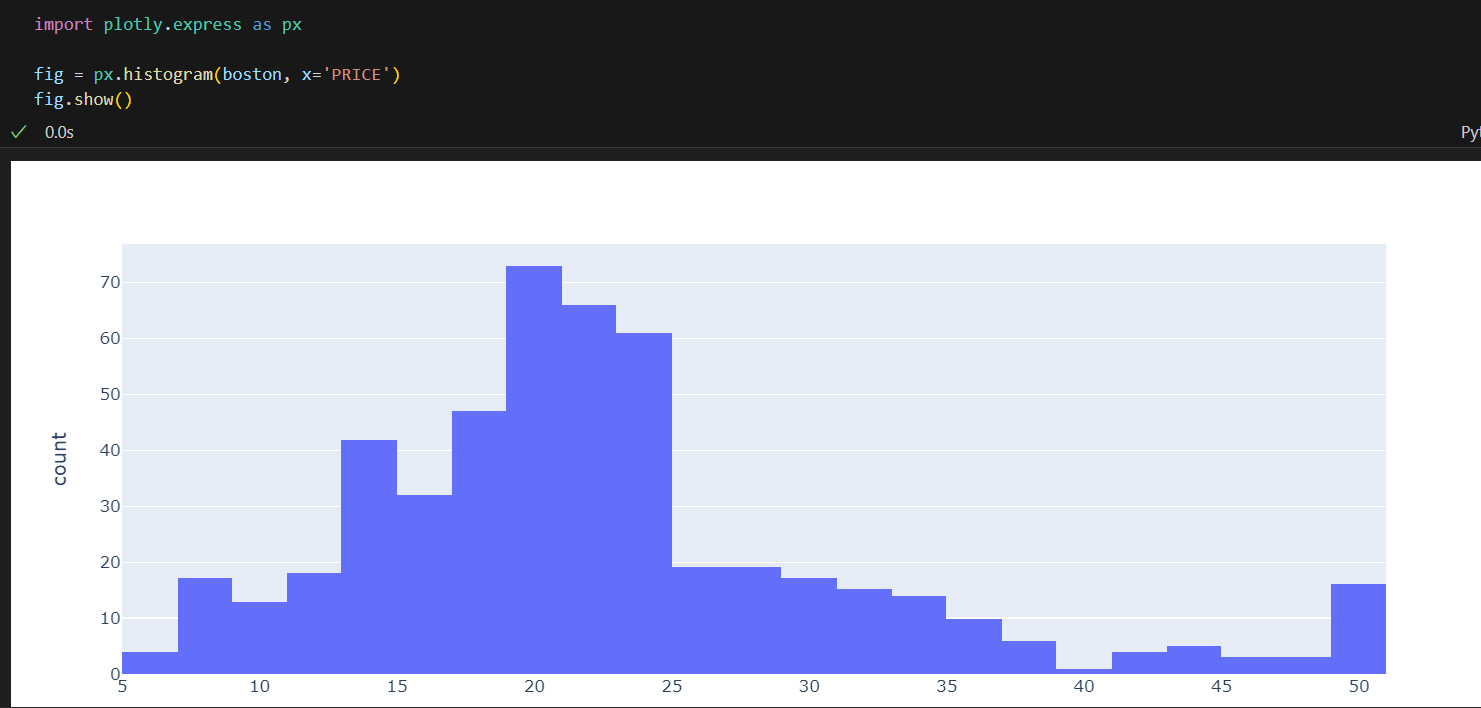
-
가격기준 히스토그램
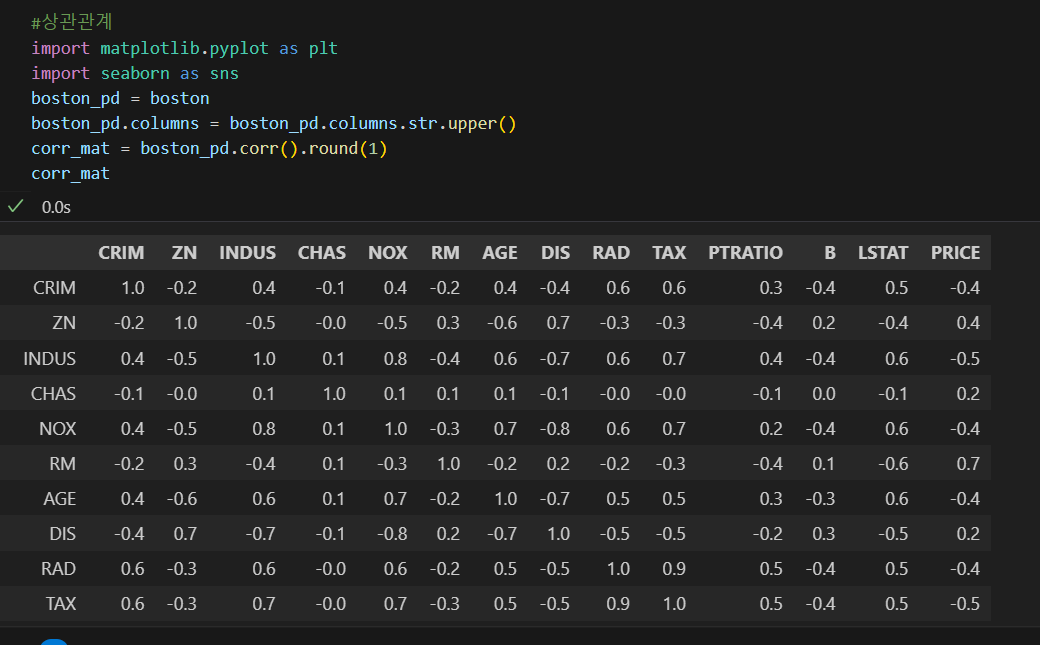
-
상관관계
-
히트맵 (sns.heatmap(data=corr_mat, annot=True, cmap='bwr'))
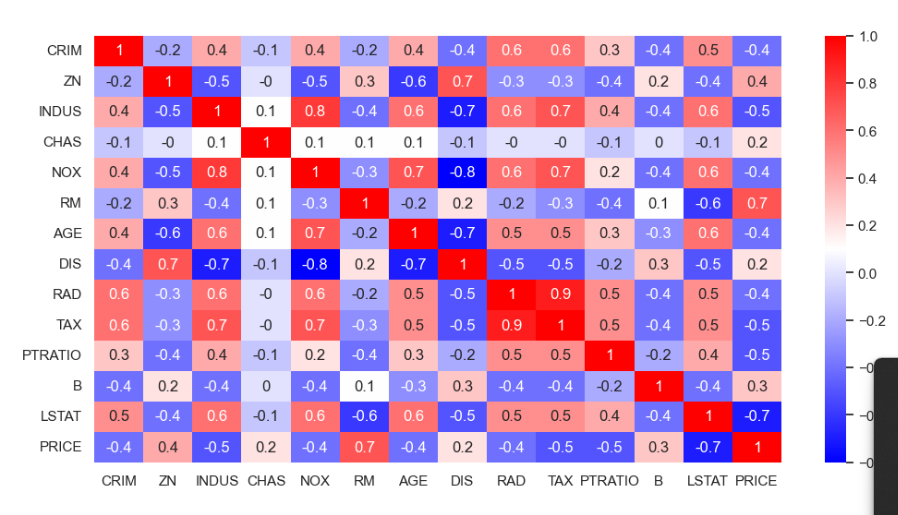
-
선형회귀
sns.set_style('darkgrid')
sns.set(rc={'figure.figsize': (12,6)})
fig, ax = plt.subplots(ncols=2)
sns.regplot(x="RM", y="PRICE", data=boston_pd, ax=ax[0])
sns.regplot(x="LSTAT", y="PRICE", data=boston_pd, ax=ax[1])
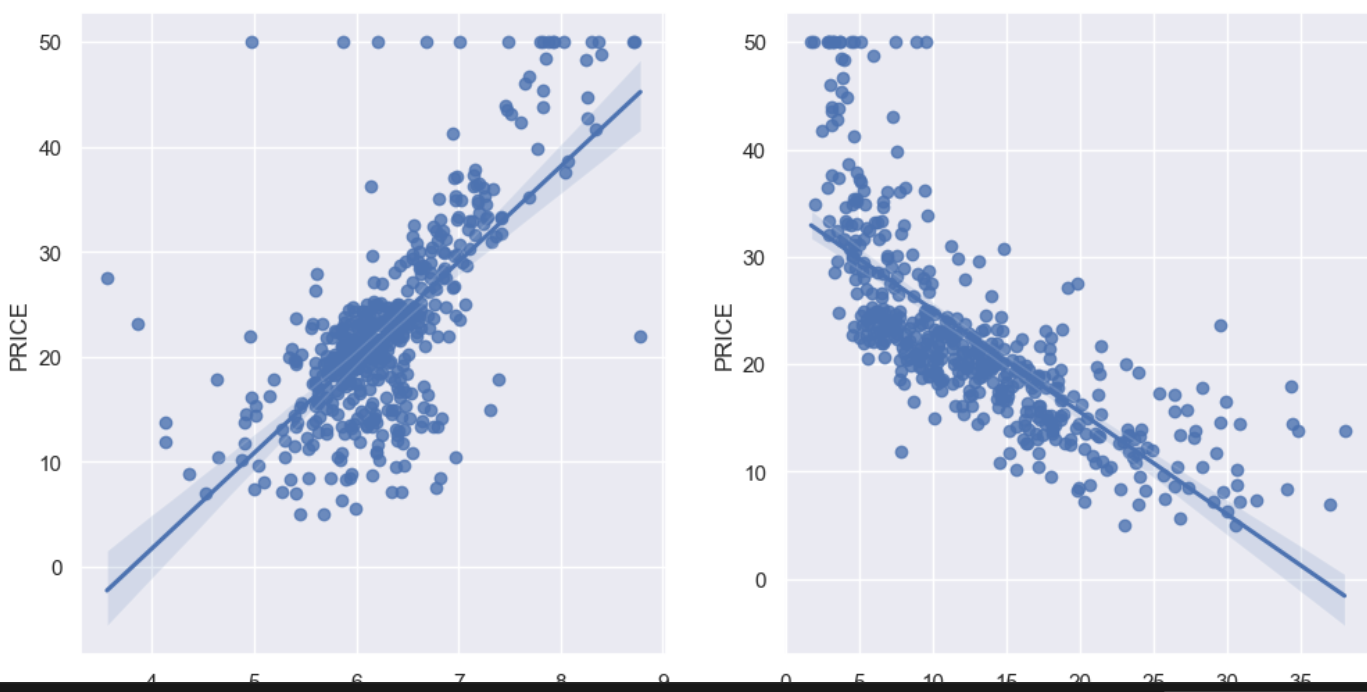
회귀 모델 사용
1. 모델 선택
#모델 선택
from sklearn.model_selection import train_test_split
X = boston_pd.drop('PRICE', axis=1)
y = boston_pd['PRICE']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
2. 선형 회귀로 모델학습하기
#선형 회귀로 모델학습
from sklearn.linear_model import LinearRegression
#price 컬럼 값이 존재하지 않아 실습불가
reg = LinearRegression()
reg.fit(X_train, y_train)
3. 모델평가
from sklearn.metrics import mean_squared_error
pred_tr = reg.predict(X_train)
pred_test = reg.predict(X_test)
rmse_tr = np.sqrt(mean_squared_error(y_train, pred_tr))
rmse_test = np.sqrt(mean_squared_error(y_test, pred_test))
4. 출력
print("RMSE train: ", rmse_tr)
print("RMSE test: ", rmse_test)
#RMSE train: 4.821041974435382
#RMSE test: 4.256804937894875
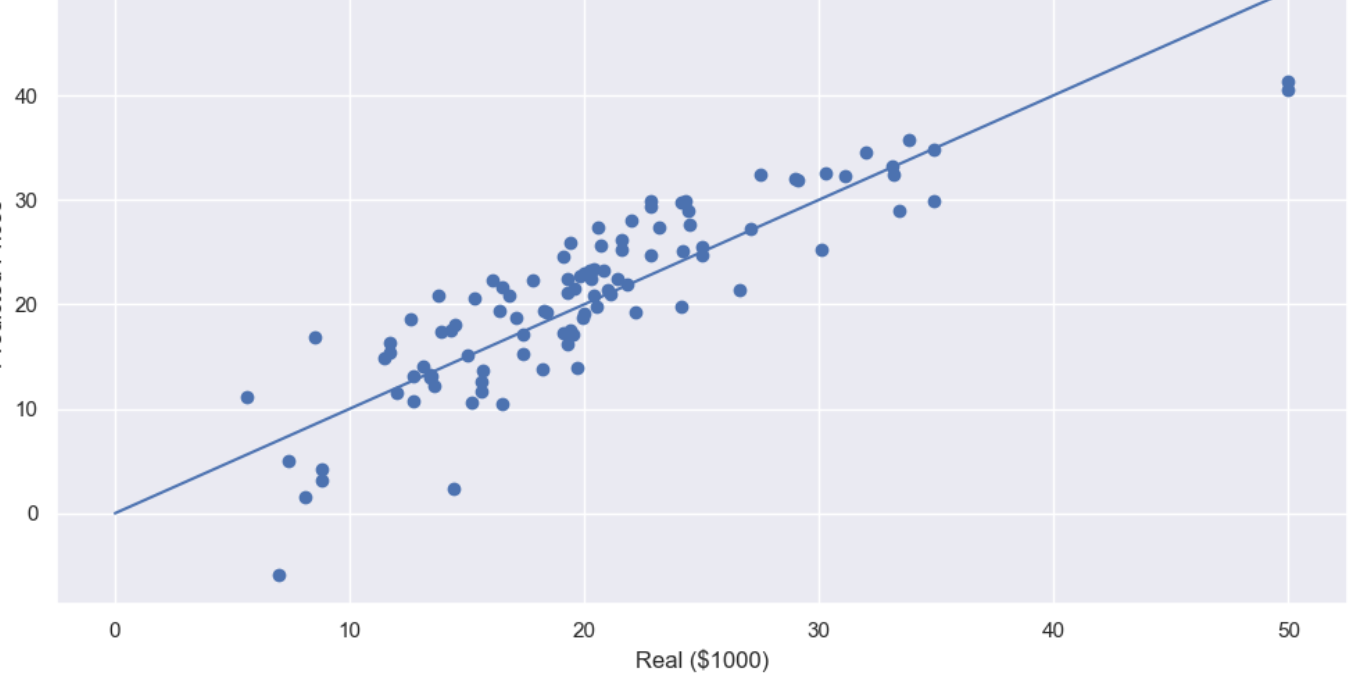
5. 테스트 모델 출력
plt.scatter(y_test, pred_test)
plt.xlabel('Real ($1000)')
plt.ylabel('Predicted Prices')
plt.plot([0,50], [0,50])
plt.show()