로지스틱(Logistic Regression)
- 분류(Classification) 문제를 다루기 위한 통계적 기계 학습 알고리즘이며 분류(classification)알고리즘이다.
- 주로 이진 분류(Binary Classification)문제를 다루며, 샘플을 구 개의 클래스 중 하나로 분류하는 데 사용된다.
- 특징
1.로지스틱 함수: 로지스틱 함수 or 시그모이드 함수 를 사용하여 입력 특성과 가중치의 선형 결합을 변환한다. 0과 1사이의 값을 출력하며 이를 확률로 해석할 수 있다.
- 이진 분류:이진 분류에서 많이 사용한다. ex) 스팸 메일 여부, 질병 발병 여부 예측
- 최적화: 로지스틱 회귀 모델을 학습하기 위해 최적화 알고리즘 사용 루고 손실을
최소화하는 방향으로 모델 파라미터(가중치) 조정한다.
시그모이드 사용
import numpy as np
z = np.arange(-10, 10, 0.01)
g = 1 / (1+np.exp(-z))
import matplotlib.pyplot as plt
plt.plot(z, g)
plt.grid()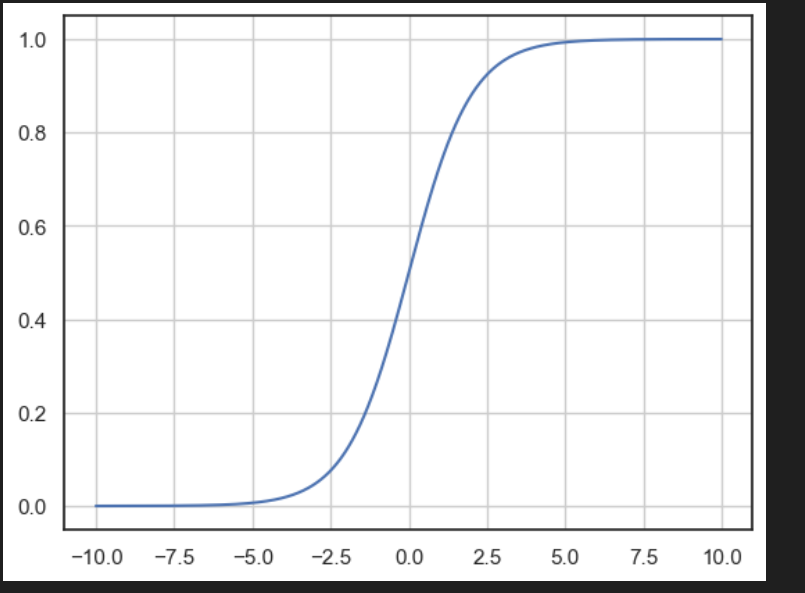
gca 설정값 변경
GCA(Get Current Axes): 현재 활성화된 그래프(figure)에서 사용되고 있는 축(axes)객체를 가져온다. (선을 가져온다.)
# gca 설정값을 변경한다.
plt.figure(figsize=(12,8))
ax = plt.gca()
ax.plot(z,g)
ax.spines['left'].set_position('zero') #축을 옮긴다. (zero 0 수치인곳)
ax.spines['bottom'].set_position('center')
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none') #오른쪽과 위쪽 축 제거
plt.show()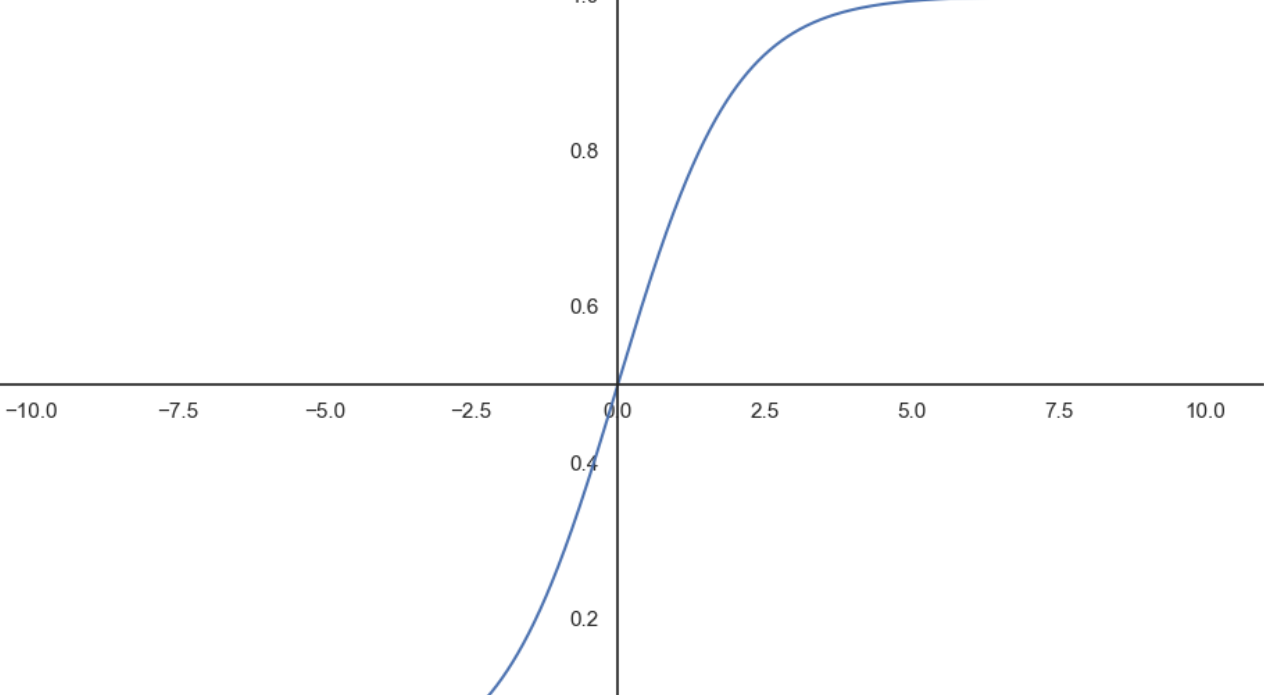
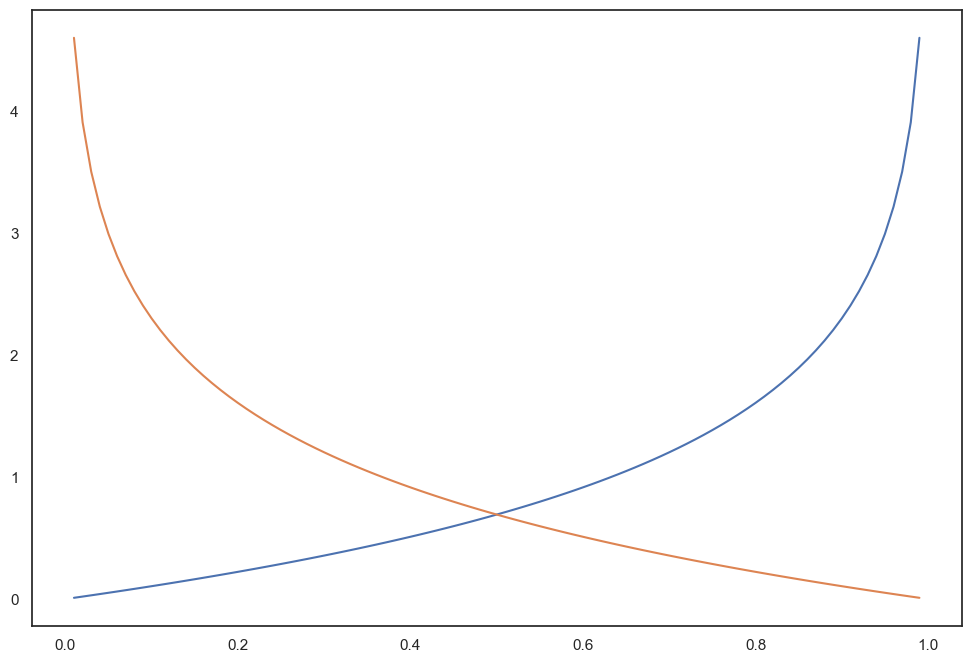
Cost Function 그래프
Cost Fubnction(비용 함수or 손실 함수): 모델의 예측값과 실제값 사이의 차이 또는 오차를 측정하는데 사용하며 모델을 학습하고 파라미터를 조정하는 과정에서 최소화하려는 목표로 사용
1. 모델평가: 얼마나 좋은지 예측한다. 예측값과 실제값 사이의 차이를 계산하여 모델의 성능 평가
2. 모델 학습:Cost Function을 최소화하는 방향으로 모델의 파라미터를 조정
3. 과적합(Overfitting)방지 :과적합을 방지하기 위해 Cost Function을 사용하여 모델의 복잡도를 제어
h = np.arange(0.01, 1, 0.01)
C0 = -np.log(1-h)
C1 = -np.log(h)
plt.figure(figsize=(12,8))
plt.plot(h, C0, label='y=0')
plt.plot(h, C1, label='y=1')
로지스틱 회귀 실습
import pandas as pd
wine_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/wine.csv'
wine = pd.read_csv(wine_url, index_col=0) #Unnamed:0 삭제 index_col=0
wine
wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']]
X = wine.drop(['taste','quality'],axis=1)
y = wine['taste']
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state= 13)
-------------------------------------------------
#간단 로지스틱 회귀 테스트
from sklearn.linear_model import LogisticRegression
#이진 분류나 다중 클래스 분류문제에서 사용된다.
from sklearn.metrics import accuracy_score #분류 문제의 정확도 측정
#로지스틱 모델링 및 학습실행
lr = LogisticRegression(solver = 'liblinear', random_state=13)
#최적화 수행 SOLVER
#solver ='liblinear' 최적화 알고리즘(데이터가 작으면 liblinear사용)
#다른 옵션: newton-cg, lbfgs, sag, saga
lr.fit(X_train, y_train)
y_pred_tr = lr.predict(X_train)
y_pred_test = lr.predict(X_test)
print('Train Acc:',accuracy_score(y_train, y_pred_tr))
print('Train Acc:',accuracy_score(y_test, y_pred_test))
#Train Acc: 0.7425437752549547
#Train Acc: 0.7438461538461538
from sklearn.pipeline import Pipeline #파이프라인 가져오기
from sklearn.preprocessing import StandardScaler #데이터 전처리 단계에서 사용할 StandardScaler 가져온다.
# StandardScaler는 입력 데이터의 평균을 0으로 표준 편차를 1로 만들어 데이터를 표준화한다.
estimators = [ #파이프라인에 사용할 단계 정의
('Sclaer', StandardScaler()), #Scaler는 StandardScaler로 데이터를 표준화 하는 역할
('clf', LogisticRegression(solver='liblinear', random_state= 13)) # clf는 로지스틱 회귀 모델을 사용하여 분류 작업 수행
]
pipe = Pipeline(estimators)
#파이프라인 출력
pipe.fit(X_train, y_train)
y_pred_tr = lr.predict(X_train)
y_pred_test = lr.predict(X_test)
print('Train Acc:',accuracy_score(y_train, y_pred_tr))
print('Train Acc:',accuracy_score(y_test, y_pred_test))
#Train Acc: 0.7425437752549547
#Train Acc: 0.7438461538461538
결정 트리 (Decision tree
#트리 생성
from sklearn.tree import DecisionTreeClassifier
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
#결정트리 파이프라인
models = {
'logistic regression': pipe,
'decision tree':wine_tree
}
from sklearn.metrics import roc_curve
for model_name, model in models.items():
#model_name 딕셔너리 key값
#model 딕셔너리 values
#딕셔너리 반복을 위한 items()
print(model_name)
print('---------------')
print(model)
#출력
#logistic regression
#---------------
#Pipeline(steps=[('Sclaer', StandardScaler()),
# ('clf',
# LogisticRegression(random_state=13, #solver='liblinear'))])
#decision tree
#---------------
#DecisionTreeClassifier(max_depth=2, random_state=13)
#그래프출력
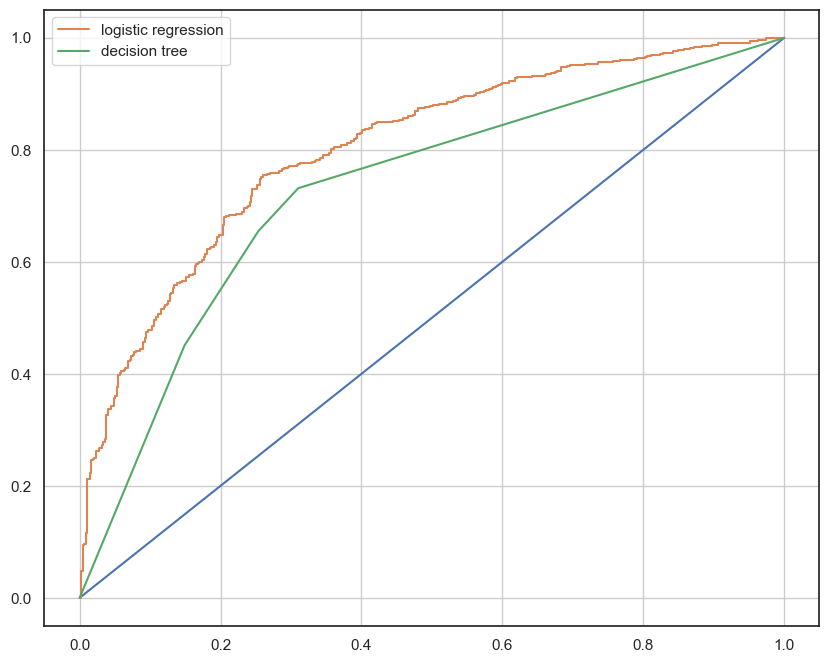
plt.figure(figsize=(10,8))
plt.plot([0,1], [0,1]) # x,y (0,0)(1,1)까지 그래프 범위
for model_name, model in models.items():
pred = model.predict_proba(X_test)[:, 1] # predict_proba 1에속할 확률을 반환하기 위해 [:,1]사용 (predict_proba 모델이 예측한 결과의 확률 반환)
fpr, tpr, thresholds = roc_curve(y_test, pred)#ROC곡선 계산한다.
plt.plot(fpr, tpr, label=model_name)
plt.grid()
plt.legend()
plt.show()