kNN
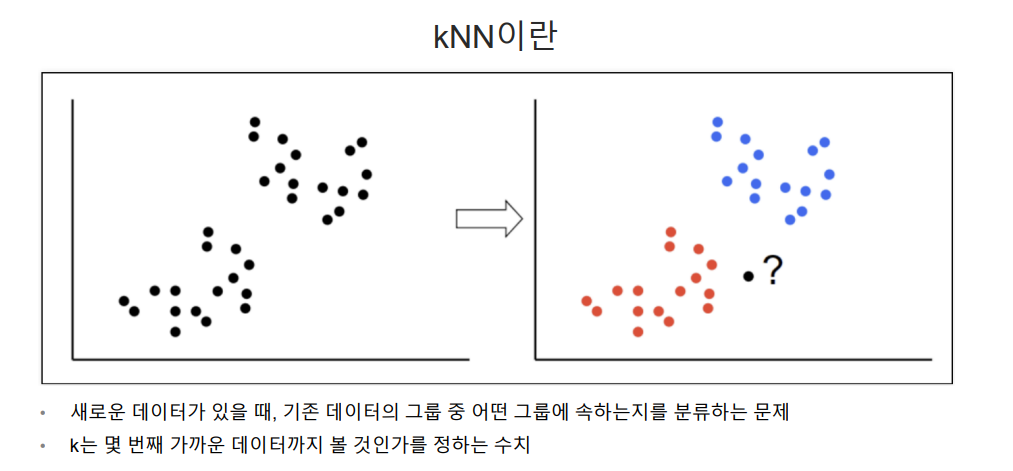
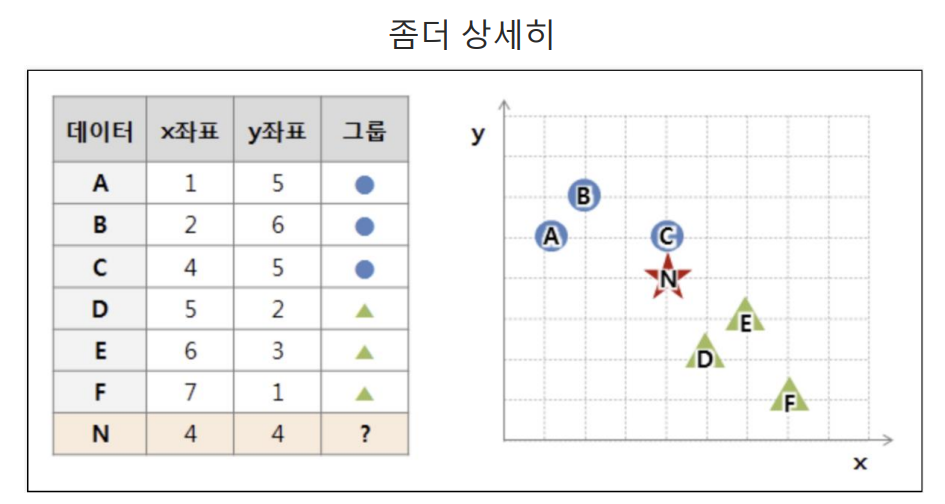
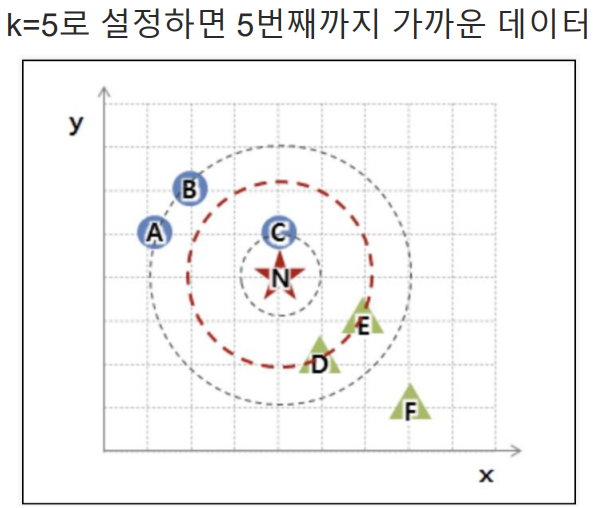
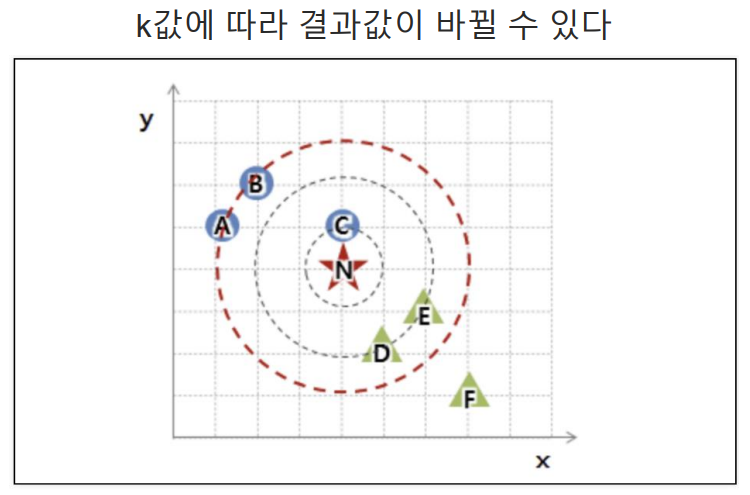
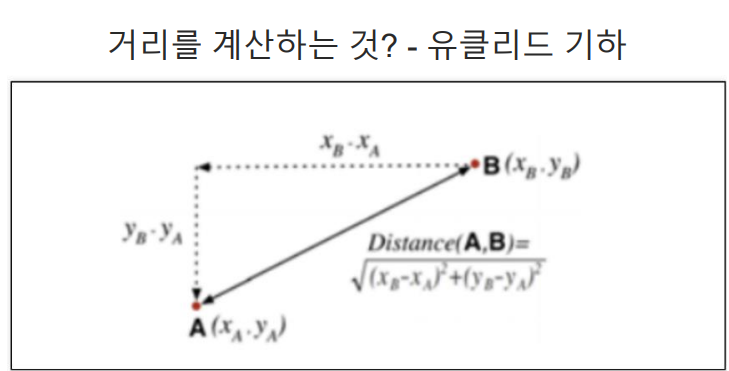
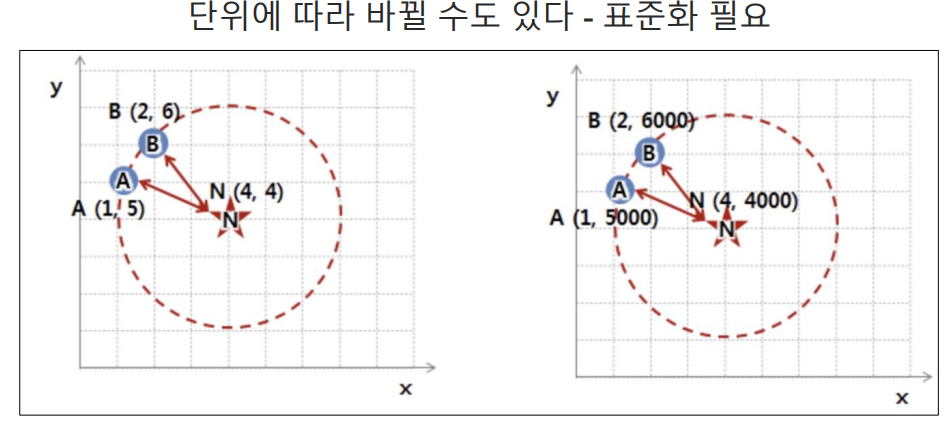

최근접이웃(K Nearest Neighber):지도학스(Supervised Learning)의 일종으로, 분류(Classification)와 회귀(Regression) 문제에 사용되는 간단하면서도 강력한 알고리즘이다. 주로 패턴 인식, 데이터 마이닝, 추천 시스템 등 다양한 분야에서 활용된다.
- 동작 원리
- 학습(Training): 먼저, 알고리즘이 학습 데이터 세트를 사용하여 데이터의 특징을 학습한다. 각 데이터 포인트는 해당 데이터의 특징 벡터와 그에 해당하는 레이블 또는 값을 가지고 있어야 한다.
- 거리 측정(Measuring Distance): 예측하려는 데이터 포인트와 학습 데이터 포인트 사이의 거리를 측정한다. 주로 유클리드 거리(Eucllidean Distance)가 사용된다.
- K-최근접 이웃 찾기(Finding k Nearest Neighbors): 거리가 가장 가까운 k개의 학습 데이터 포인트를 찾는다.
- 다수결 투표(Majority Vote): 분류 문제의 경우, k개의 최근접 이웃 중에서 가장 많은 수의 이웃이 어떤 클래스에 속하는지 투표를 통해 결정한다. 회귀 문제의 경우, k개의 최근접 이웃의 값 평균을 구하여 예측값을 계산한다.
- 요약: 최근접이웃은 학습시키는 과정이 없으며, 예측할 때마다 거리를 계산하기 때문에 실시간 예측이 가능하다는 장점이 있다. 또한, 간단한 구현과 하이퍼파라미터인 k를 조정하여 모델 성능을 조절할 수 있다는 점에서 사용하기 쉽다.
GBM

GBM(Graduebt Biistubg Machine): 앙상블 학습 알고리즘이며
약한 학습기(weak learner)를 결합하여 학습 모델을 만든다.
회귀, 분류에서 사용한다.
- 특징
- 부스팅(Boosting):약한 학습기(weak learner)들을 순차적으로 훈련하고 예측 오차를 보정하며 진화시킨다. 각 학습기는 이전 학습기가 만든 오차를 보완하도록 훈련된다.
- 그레디언트: 손실 함수(Loss Function)의 그레디언트(기울기)정보를 활용하여 모델을 학습하는 방식을 의미한다. 즉, 오차의 그레디언트를 이용하여 예측값을 업데이트한다.
- 약한 학습기: 결정 트리(Decision Tree)를 약한 학습기로 사용한다. 각 결정 트리는 데이터의 일부를 학습하고 예측을 수행한다. 이렇게 각각의 결정 트리는 데이터의 패턴을 학습하고 예측을 수행한다.
- 과적합 제어: GBM은 오차 보정을 통해 과적합(Overfitting)을 제어하려고 노력한다. 오차를 보정하면서 모델이 데이터에 과도하게 적합되는 것을 방지하며 일반화 성능을 향상시킨다.
- 하이퍼파라미터 튜닝: GBM 모델은 여러 하이퍼파라미터를 조절할 수 있으며, 이를 튜닝하여 모델 성능 최적화
- 속도가 매우 느리다.
XGBoost

- 부스팅 알고리즘: XGBoost는 부스팅 알고리즘이며 약한 학습기를 순차적으로 훈련하여 예측 오차를 보정하고 모델 정확도를 향상한다.
- 그레디언트 부스팅: 손실 함수의 그레디언트(기울기)정보를 활용하여 예측값을 업데이트한다. 오차를 최소화하기 위해 모델 학습을 한다.
- 결정 트리 앙상블: 다수의 결정 트리를 조합하여 강력한 앙상블 모델을 형성한다.
- 속도와 성능: 빠른 속도와 높은 성능을 제공한다. 다양한 최적화 기법과 병렬 처리를 통해 빠른 훈련 및 예측을 가능하게 한다.
- 튜닝 가능한 하이퍼파라미터: 다양한 하이퍼파라미터를 조절하여 모델을 세밀하게 튜닝할 수 있다. 하이퍼파라미터의 조정을 통해 모델 성능을 최적화한다.
- 과적합 제어: 과적합 방지
- 자동 조기 중단(Early Stopping): 교차 검증을 통해 모델 성능을 모니터링하고, 지정된 조기 중단 기준을 충족하면 훈련을 조기 중단 한다.
LGBM
- 그레디언트 부스팅 알고리즘: LGBM은 그레디언트 부스팅 알고리즘 기반이다.
약한 학습기(weak learner)들을 순차적으로 훈련하고 예측 오차를 보정하여 모델 향상- 히스토그램 기반 부스팅:데이터를 빠르게 정렬하고 분할하기 위해 히스토그램 활용하는 방식. 이러한 방식은 훈련 속도를 크게 향상시킨다.
- 빠른 속도와 메모리 효율성: XGBoost와 비교하여 빠른 속도와 낮은 메모리 사용량을 제공
- 다양한 데이터 유형 지원: LGBM은 범주형 데이터를 자동으로 처리하고, 다양한 유형의 데이터에 적용
