
🐛 정규표현식이란?
정규표현식(Regular Expression, RegEx)이란 문자열에서 특정한 패턴을 찾거나, 검사하거나, 바꾸기 위해 사용하는 표현식(패턴 언어)이다
- 정규표현식 종류
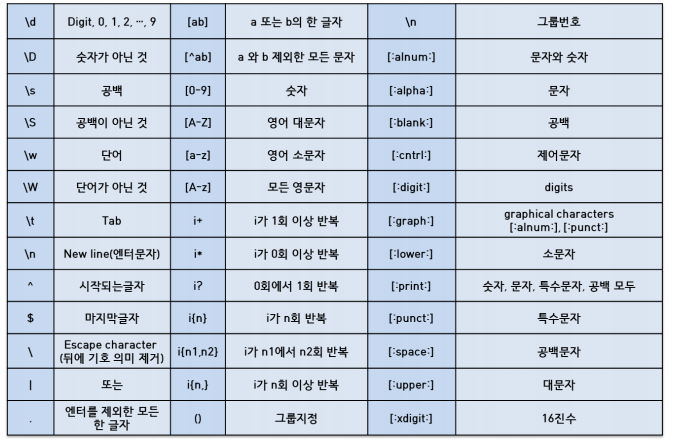
-
정규표현식 함수
-
REGEXP_REPLACE(대상, 찾을문자열, 바꿀문자열, 검색인덱스, 발견횟수, 옵션)
- 바꿀 문자열 생략 시 문자열 삭제
- 검색인덱스 생략 시 1
- 발견횟수 생략 시 0(모든)
- 옵션
- c : 대소를 구분하여 검색
- i : 대소를 구분하지 않고 검색
- m : 패턴을 다중라인으로 선언 가능
-
REGEXP_SUBSTR(대상, 패턴, 검색인덱스, 발견횟수, 옵션, 추출그룹)
- 정규식 표현식을 사용한 문자열 추출
- 옵션은 REGEXP_REPLACE와 동일
- 검색인덱스 생략 시 1
- 발견횟수 생략 시 1
- 추출그룹은 서브패턴을 추출 시 그 중 추출할 서브패턴 번호
-
REGEXP_INSTR(원본, 찾을패턴, 시작인덱스, 발견횟수, 출력옵션, 옵션, 추출그룹)
- 주어진 문자열에서 특정패턴의 시작 인덱스를 반환
- 시작인덱스 생략 시 처음부터 확인(DEFAULT : 1)
- 발견횟수 생략 시 처음 발견된 문자열 인덱스 리턴
- 출력옵션
- 0(DEFAULT) : 문자열의 시작인덱스 리턴
- 1 : 문자열의 끝인덱스 리턴
-
REGEXP_LIKE(원본, 찾을문자열, 옵션)
- 주어진 문자열에서 특정패턴을 갖는 경우 반환(WHERE절 사용만 가능)
- 옵션은 REGEXP_REPLACE와 동일
-
REGEXP_COUNT(원본, 찾을문자열, 시작인덱스, 옵션)
- 주어진 문자열에서 특정패턴의 횟수를 반환
- 옵션은 REGEXP_REPLACE와 동일
- 시작인덱스 생략 시 처음부터 스캔
-
🤢 정규표현식 사용해보기
1) 문자열이 특정 패턴과 일치하는지 확인 (WHERE절에서 사용)
SELECT EMP_NAME
FROM EMPLOYEE
WHERE REGEXP_LIKE(EMP_NAME, '^김'); -- 이름이 '김'으로 시작하는 사람 찾기2) 문자열 중에서 정규식 패턴에 맞는 부분만 추출
SELECT EMAIL,
REGEXP_SUBSTR(EMAIL, '@[A-Za-z0-9.-]+') AS DOMAIN -- 이메일 주소에서 도메인만 추출
FROM USERS;
| DOMAIN | |
|---|---|
| test@gmail.com | @gmail.com |
| hello@naver.com | @naver.com |
| vivi@nexon.com | @nexon.com |
3) 정규식 패턴이 문자열에서 시작하는 위치 반환
SELECT PHONE,
REGEXP_INSTR(PHONE, '-') AS FIRST_HYPHEN_POSITION -- 전화번호에서 하이픈(-)이 처음 나타나는 위치 찾기
FROM CONTACTS;
| PHONE | FIRST_HYPHEN_POSITION |
|---|---|
| 010-1234-5678 | 4 |
4) 문자열에서 정규식 패턴에 맞는 부분을 다른 문자열로 치환
SELECT EMP_NAME,
REGEXP_REPLACE(EMP_NAME, '[0-9]', '') AS CLEAN_NAME -- 이름에서 숫자 제거하기
FROM EMPLOYEE;| EMP_NAME | CLAEN_NAME |
|---|---|
| 홍길동4813048031 | 홍길동 |
| 김민숭3 | 김민숭 |
5) 특정 문자의 등장 횟수 세기
SELECT EMP_NAME,
REGEXP_COUNT(EMP_NAME, '윤') AS YUN_COUNT -- 이름에 '윤'이 몇 번 들어있는지 확인
FROM EMPLOYEE;| EMP_NAME | YUN_COUNT |
|---|---|
| 함지슝 | 0 |
| 김지윤 | 1 |
| 윤지윤 | 2 |
| 윤윤숭 | 2 |
6) 문장 속에서 패턴을 찾아 추출
SELECT REGEXP_SUBSTR(
'인수는 100kg이고, 지숭이는 50kg이며, 하리는 75kg이다',
'([0-9]+)kg', -- 패턴: 숫자 뒤에 'kg'가 오는 형태
1, -- position: 문자열의 처음(1번째)부터 검색
2, -- occurrence: 두 번째 매칭값(=50kg)
'i', -- match_parameter: 대소문자 구분 안 함(ignore case)
1 -- subexpr: 괄호로 묶은 첫 번째 그룹([0-9]+)
) AS SECOND_WEIGHT
FROM DUAL;| SECOND_WEIGHT |
|---|
| 50 |

Data Engineer