3. Efficient Training
3.1 Large-batch traninig
작은 batch size로 training 시키는 것과 비교하면, batch size가 클 경우 동일 epoch에서 validation accuracy가 낮게 나타나는 것을 확인할 수 있음. 따라서 본 논문에선느 single machine training에 대해 batch size를 확장하는것에 도움이 될 수 있는 four heuristics에 대해 실험을 함
Linear scaling learning rate
mini-batsch SGD에서 각 배치에서 샘플이 랜덤하게 선택되기 때문에 gradient descending은 random porcess였음. large batch size가 기울기의 nosie를 감소시켰기 때문에, learning rate을 증가 시킬 수 있었음. ResNet에서 했던 것처럼 batch size 256에 대해서 0.1을 inital learning rate로 잡고, batch size b로 변화 될 때마다 initial leraning rate를 0.1 x b/26으로 증가시켰음
Learning rate warmup
너무나도 큰 learning rate를은 numerical instability가 발생시킬 수도 있음. warmup heuristic에서 시작에서는 작은 learning rate를 사용하고, training porcess가 안정화 되었을 때는 initial learning rate를 변화시켰음. 처음에는 warm up을 위해 batch, initial leraning rate , 각 batch , learning rate를 으로 설정함
zero
ResNet은 multiple residual block으로, 각 block은 몇개의 convolution layer로 설정되어 있었음. input , block에서 마지막 layer의 output , residual block에서의 output . 마지막 block layer에서 batch normalization(BN) layer은 input을 standardzation하고, 이를 라고 할 때, scale transformation은 가 됨. 와 모두 learnable parameter로, eletments는 각각 1s와 0s로 각각 초기화 됨.
residual block의 마지막 모든 BN layer에서 으로 초기화를 하였음. 그 결과, 모든 residual block에서 inputs만을 return해주었기 때문에, 적은 layer를 가진 network와 같은 효과를 보기 때문에 초기 단계에서 학습이 쉬워짐
No bias decay
L2 regularization으로 모든 parameter가 0이 되도록 적용함. 기존 연구에서는 regularization은 weight의 overfitting을 막는 수단으로 권고한 것 처럼, convolution과 fully connected layer에서만 weight decay를 적용함. BN층에서의 bias와 를 포함한 parameter들은 unregularized한 상태로 남김
3.2 Low-precision training
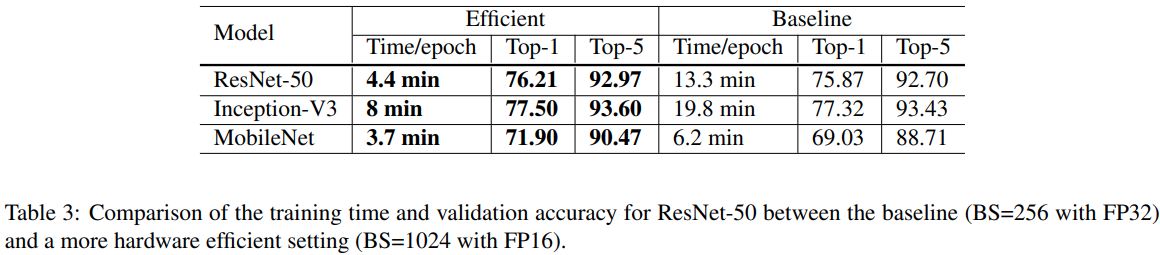
일반적으로 NN에서는 32bit floating point(FP32) precision으로 학습을 시킴. 예를 들어 Nvidia V100은 32FP에서는 14 TFLOPS이지만 FP16에서는 100TFLOPS가 넘어감. Table 3에서 보는 것과 같이, FP32에서 FP16으로 switching을 하면 속도가 2~3배 가속이 되는 것을 확인할 수 있음
이런 performance의 이점에도 불구하고, precision을 감소시키는 것은 범위를 감소시켜 training에 방해가 될 수 있음. Micikevicius et al이 제시한 mixed training 기법을 사용하였음. 모든 parameters와 activation을 FP16으로 구성하였고, 동시에 모든 parameter들은 FP32를 복제하여 updating을 하였음. 추가적으로 loss에 scalar를 곱하여서 gradient의 범위를 FP16으로 더 잘 정렬시켰음.
3.3 Experiment Results
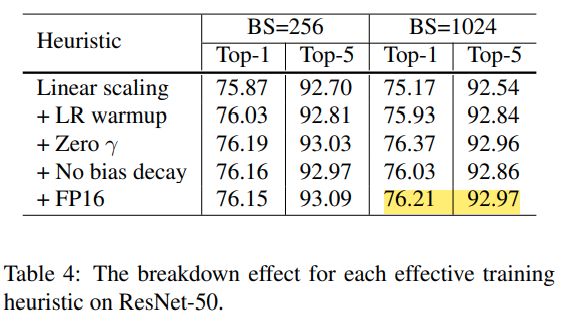
batch size를 256에서 1024로 증가시켰을 때 정확도가 top1에서 정확도가 약 0.9% 감소되었고, 나머지 3개의 hueristic이 차이를 보충하지만, trainig 종료시 F32에서 F16으로 전환하여도 정확도에는 영향을 끼치지 않음.
4. Model Tweaks
model tweak은 특정 convolution에서 stride를 변화시키거나 하는 등의 network architecture를 minor하게 조정하는 것을 의미함
4.1 ResNet Architecture
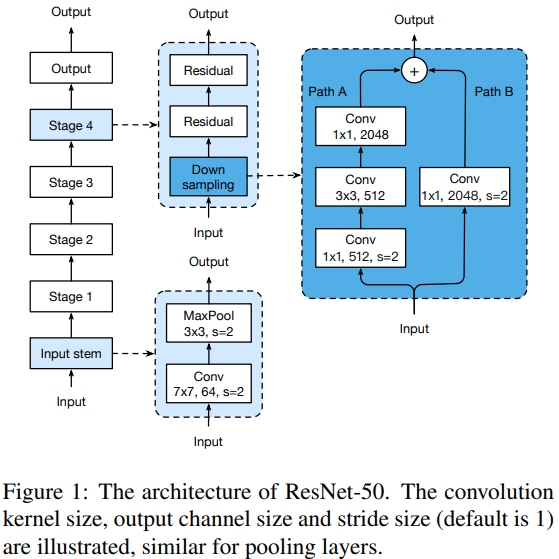
4.2 ResNet Tweaks
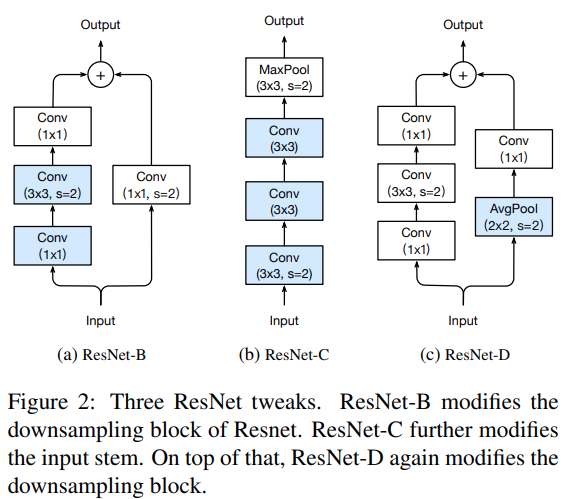
ResNet-C
기존 연구에서 밝혔든, convolution의 계산 비용은 kernel의 width나 height에 이차적(quadratic)함. 7x7 convolution은 3x3 convolution에 비해 conputiational cost가 5.4배 더 컸음. 그래서, input stem에서 7x7 convolution을 3x3 convolution으로 대체(Figure 2b)하고, 첫 번째와 두 번재의 convlution에는 stride를 2로 하여 output을 32개로, 마지막 convolution은 64개의 channel로 설정하였음
ResNet-B
stride 2인 1x1 kernel을 사용하기 때문에 pathA에서의 convolution이 3/4의 input feature map을 무심.
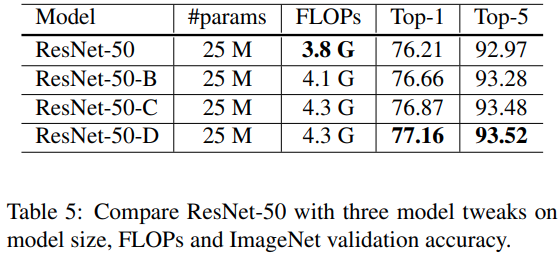
4.3. Experiment Results
ResNet-B는 downsampling block의 경로 A에서 더 많은 정보를 수신하고, ResNet50에 비해서 validation 정확도를 약 0.5%를 향상시킴. 7x7 convolution을 3x3 convolution으로 대체시키면 0.2% 향상됨. downsampling block의 경로 B에서 더 많은 정보를 얻으면 validation이 개선됨
