LeNet-5
현대 MNEST는 28x28을 받지만, LeNet-5는 32x32를 input 받을. 당시에 convolution은 아직 발전하지 않았기 때문에 전통적인 Fully Connected의 영향을 받음. 전통적인 Fully connected는 위치에 민감하기 때문에, Object가 한 가운데 위치하는 것이 좋았음. 그래서 padding을 하여 Object를 가운데 위치하게 함
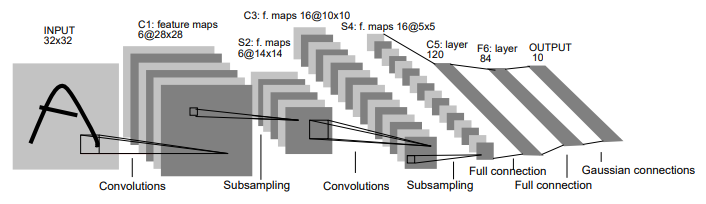
Input : 32x32
약간 더 크게 함. 당시 Convolution에 대한 이해가 크지 않았기 때문에, 전통적인 machine learning에 사용했던 이미지 전처리를 적용함
C1 : feature map 6@28x28
논문에는 설명이 없음. stride = 1, padding 없는 것을 기본 옵션으로 생각하면 됨.
S2 : f.maps 6@14x14
현대와 가장 많이 차이가 나는 부분. 현대의 pooling 방식이 아니라 학습을 통해 a를 곱하여 줄임.
학습을 통하여 줄이기 때문에 훨씬 더 특징을 그대로 가질 것이라는 이론적인 생각을 함.
결과적으로는 현대적인 방식인 학습을 통해 줄일 필요가 없음. 왜냐면 그대로 줄여도 C1에서 결국은 다른 형태로 학습이 되기 때문에 학습을 할 필요가 없음
나중에 비슷한 개념이 나옴. unpooling : 두개가 같은 결과인데, 각각 학습할 필요 없이 앞에만 잘 학습되면 산술연산에서 잘 나오면 값이 다름
줄이는 이유? 계산 복잡도 때문에. 크기를 줄여 계산 복잡도를 줄이고, 구해야 하는 weight를 작게해서 학습 데이터를 작아도 rhoscksgdma
- 딥러닝이 나중에 나온 이유
1) 데이터의 크기
2) 알고리즘
3) HW 성능 - invarient : x가 어떤 함수에 들어갔는데, 함수가 이동이나 회전을 해도 결과값은 같음. pooling을 하는 이유.
- pooling 대신 stride를 크게 해도 됨. stride를 크게 하면 크기가 줄어듦. 어쨌든 단순 연산이기 때문에. stride를 바꾸면 다른 convolution이 됨. 계산 결과가 줄어들기 때문에 요즘에는 pooling 안 쓰는 방법을 많이 씀.
stride를 크게 하면 특징을 잡기 어려움
C3 : f. map@10x10
S4 : f.maps 16@5x5
동일하게 pooling
activation function을 : tanh
왜 tanh? 당시 ReLU가 없었음
tanh는 문제점?
LeNet-5는 input 크기, pooling 방법, activation 빼고는 잘 만든 모델
명확한 한계점 : gradient vanishing 문제 해결하지 못함
-> 2000년대 후반까지 해결이 안 됨
gradient vanishing 때문에 학습이 안 되는 문제가 생김 -> under fitting
AlexNet
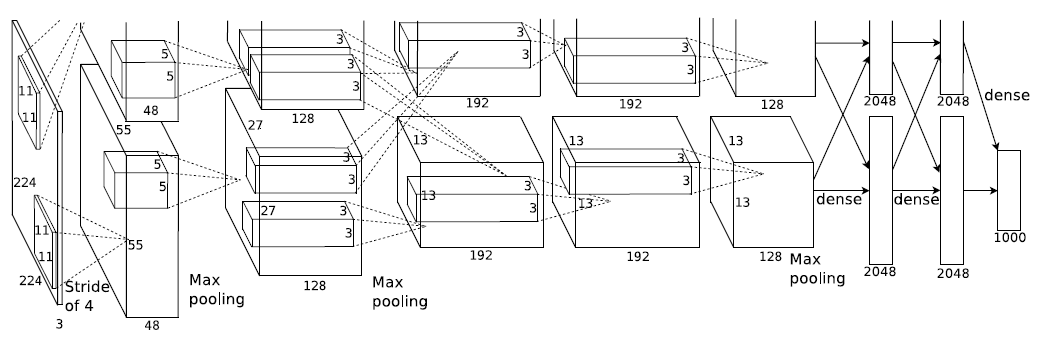
특징
-
HW 문제로 병렬로 학습함
-
ReLU의 등장으로 gradient vanishing 문제를 해결함
- ReLU 문제점
Dying ReLU(Dead Neuron) 문제 생김. 한번 0으로 시작하면 계속 0으로 전달되는 문제가 간혹 생김.
2014년도에 Leaky ReLU로 문제를 해결함. - ReLU 장점
ReLU : gradient에서 빠르게 학습됨
- Local Response Normalization(LRN) : 2014년도에 LRN 기법은 전혀 영향을 미치지 않음을 발견함. 2015년도에 Batch Normalization이 대세가 되고서 새로운 패러다임이 바뀜
- Normalization?
deep해지니까, 값들이 학습에 따라 weight bias의 범위가 매번 바뀌어 수렴이 잘 안되는 under fitting 문제가 발생함
따라서 학습이 잘되게 이전 layer와 비슷한 형태로 만들어주는 기법. 2010년도에 LRN 이전에 Google에서 Local Constrast Normalization(LCN)이 나옴.
-
Overlapping Pooling : 큰 영향을 주지 못함. Overlapping을 안 해도 학습에 따라 잘 조절이 됨
-
Data Augumentation
Data를 늘린다고 성능이 좋아지는 것이 아니라 Overfitting을 막는 것. 보통은 224x224짜리가 학습 데이터라고 할 때, 256x256짜리로 랜덤하게 자르는 방법을 사용. data는 충분해야 하고 대표성을 띄어야 함. 성능이란 accuracy를 올리는 것이 아님.
https://www.tensorflow.org/tutorials/images/data_augmentation -
Drop Out
Random하게 없앰으로서 data 수를 줄어들게 함
Drop out 자체는 ensemble technique. 요즘에는 drop out을 안 쓰는 추세. 2015년도 batch normalization이 나오고 나서, drop out을 안 쓰는 추세가 됨.
[참고]
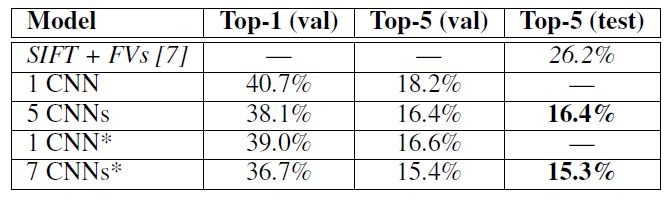
5CNNs / 7CNNs : ensemble model을 사용했다는 것
- Initialization : zero-mean Gaussian distribution
요즘에 잘 안 쓰는 technique. 학습을 빨리하기 위해서 initialization은 ReLU 때문에 1로 둠
