CNN의 input size가 고정된 있는 것부터 SPPNet은 시작합니다. 기존 존문에서는 고정된 사이즈로 input을 하기 위해서 crop하는 경우가 있는데, 이렇게 되면 이미지 전체의 정보를 못 담는 다는 것이 이 논문의 시작이었습니다.
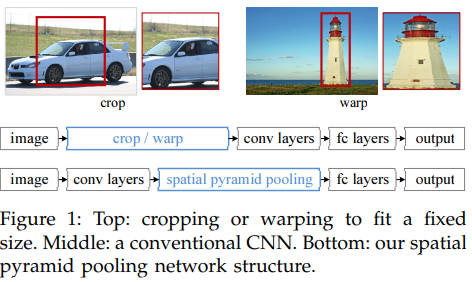
위의 구조는 기존 논문에서 제시했던, 이미지를 crop/warp하는 등 변형해서 CNN에 돌리는 것이고, 아래 구조는 이 논문에서 제시는 SPPNet의 구조입니다.
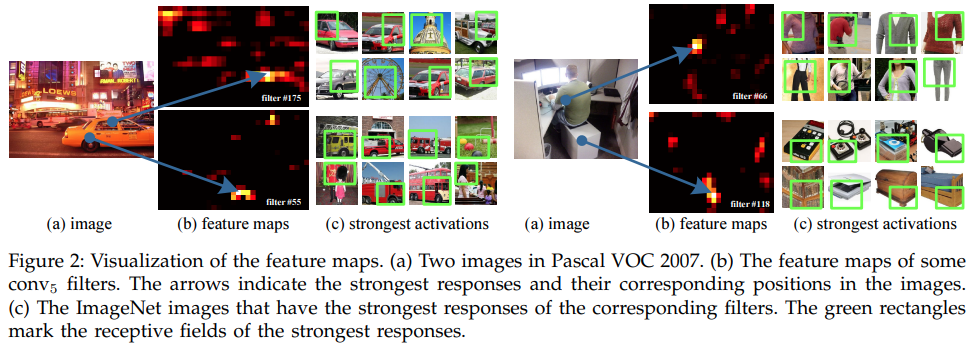
Fig2.에서 보는 것과 같이, Convolutional layer는 sliding-window 방식으로 작동하며, activation의 spatial arrangement를 대변하는 feature map을 뽑아냅니다. 따라서, convolutional layers는 fixed image size가 필요없고, 어떤 사이즈든지 feature map을 뽑아낼 수 있는 것입니다. 게다가, fixed-size는 deeper stage인 fully-connected layer로만 들어갑니다.
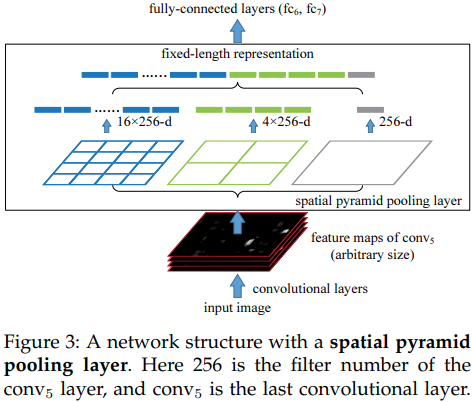

이 논문에서는 Spatial pyramid pooling(SPP)에 대해 논합니다. SPP layer를 마지막 convolutional layer의 윗부분에 추가를 하여서, fixed-length outputs을 뽑아냅니다.
SPP는 deep CNNs에서 몇가지 특성이 있습니다.
1. SPP는 input size와 상관없이 fixed length output을 생성시킬 수 있습니다
2. SPP는 siling window pooling은 오직 하나의 window size를 사용하지만, SPP는 multi-level spatial bins를 사용합니다. Multi-level pooling은 object deformation에 robust해집니다
3. SPP는 input scale에 flexibility하기 때문에 다양한 scale의 feature를 pooling 할 수 있습니다
다양한 이미지 사이즈를 input을 할 수 있고, 이를 학습을 시킨다는 것은 scale-invariance를 증가시키고, overfitting을 감소시킨다는 의미입니다. SPPNet은 Object detection에서도 좋은 성능을 보였습니다. RCNN이 VOC와 ImageNet dataset에서 좋은 성능을 보여줬지만 이미지당 지속적으로 depp convolutional networks에 raw pixels들을 적용시키다보니 느렸던 단점이 있습니다. 하지만 SPPNet은 전체 이미지를 오직 한 번만, convolutional layer들에 적용시키고, SPP layer로 feature들을 뽑아내다보니 지곤 RCNN에 비해 1/100로 시간을 감소시키는 장점이 있었습니다.
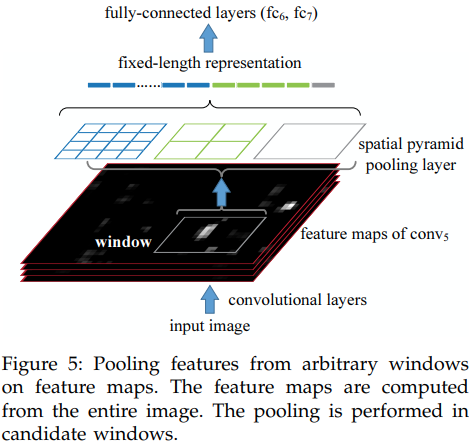
SPPNet은 Object detection에서도 사용할 수 있습니다.
