ANN(Artificial Neural Network)
-
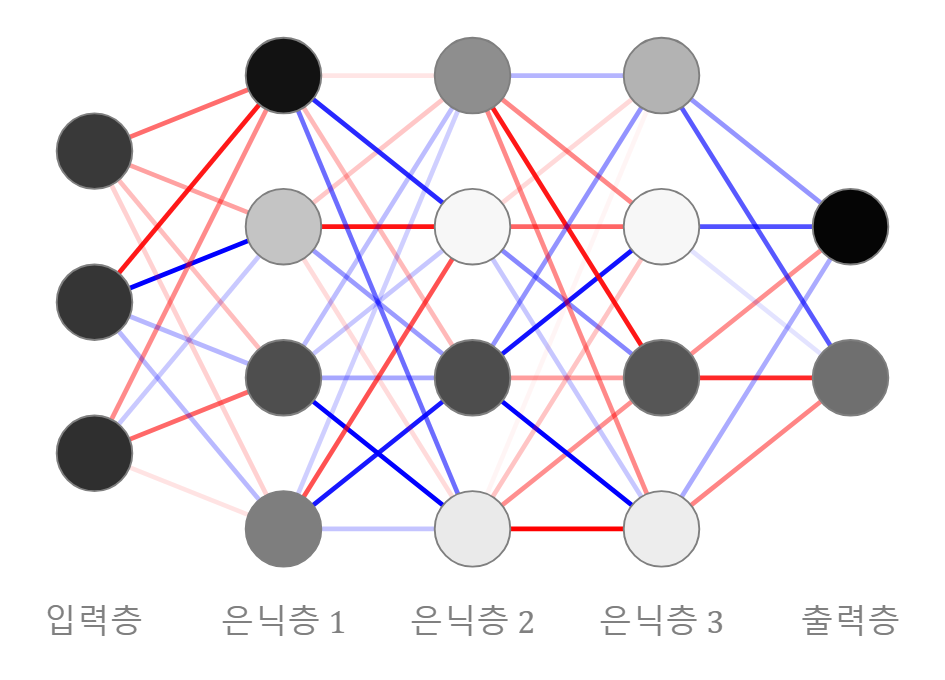
Perceptron은 단일 뉴런으로 구성된 모델로, 입력 데이터에 가중치를 곱한 선형 결합 값에 활성화 함수(계단 함수)를 적용하여 이진 분류를 수행한다. 위 그림에서 표시된 하나의 원이 하나의 Perceptron과 동일한 의미를 갖는다.
-
ANN(Artificial Neural Network)은 동물의 신경망(Neural Network)을 모방한 형태로, Perceptron의 다중 뉴런 구조를 확장한 학습기이다. 다층 구조를 통해 더 복잡한 패턴과 비선형 관계를 학습할 수 있다.
-
ANN는 세가지 층으로 구성된다.
-
입력층 (Input Layer) : 입력층은 원본 데이터를 네트워크로 전달하는 층이며, 입력 데이터의 특징(feature) 수가 입력층의 뉴런 개수와 일치한다.
-
은닉층 (Hidden Layer) : 이전 층의 데이터를 기반으로, 가중치(weight)와 바이어스(bias)를 사용해 선형 결합한 뒤, 비선형 활성화 함수를 적용하여 다음 층으로 전달한다.
-
출력층 (Output Layer) : 출력층은 마지막 은닉층의 출력을 사용하여 최종 예측값을 계산한다. 문제의 목적, 유형에 따라 사용하는 뉴런의 수와 활성화 함수가 달라진다.
-
-
ANN의 주요한 특징은 다음과 같다.
-
1. 비선형 학습기
- Perceptron이나 Logistic Regression과 달리, ANN은 중간에 은닉층(Hidden Layer)을 추가함으로써 단순 선형 모델의 한계를 극복하고, 복잡한 비선형 관계를 학습할 수 있다.
- 은닉층에서 활성화 함수(ReLU, Tanh 등)를 적용하여 데이터를 변환하며, 입력 데이터와 출력값 간의 비선형성을 학습한다.
-
2. end-to-end 모델
- ANN은 입력층에서부터 출력층까지 데이터를 End-to-End 방식으로 처리하며, 은닉층을 거치며 점진적으로 데이터를 변환하여 최종 결과값을 도출한다.
- 출력층의 활성화 함수 종류에 따라 분류 문제(Sigmoid, Softmax)와 회귀 문제(Linear Activation)를 모두 해결할 수 있다.
- 이러한 접근은 Logistic Regression에서 시그모이드 함수를 활성화 함수로 사용하여 분류 문제를 회귀 형태로 풀었던 선행 연구를 기반으로 발전한 것이다.
-
뉴런 (노드)
-
위 그림에서 하나의 원이 하나의 뉴런(노드)에 해당하며, 이전 층의 데이터를 받아 연산을 수행한 뒤, 결과를 다음 층으로 전달하는 기본 연산 단위이다.
-
입력층에서의 뉴런 : 원본 데이터의 특징(feature) 수를 의미한다.
-
은닉층에서의 뉴런 : 다음 층에서 사용할 특징(feature)의 수를 결정하며, 데이터가 변환되는 차원의 크기를 나타낸다.
-
출력층에서의 뉴런 : 문제 정의에 따라 정하는 예측값의 수를 의미한다. 회귀의 경우 변환하지 않은 하나의 예측값, 이진 분류의 경우 Sigmoid 변환된 하나의 예측값, 다중 분류의 경우는 Softmax와 같은 변환을 통해 얻는 n개의 예측값이다.
-
-
하나의 뉴런에서 어떤 일이 일어나는지 간단하게 알아보자.
- 이전 층의 모든 뉴런에서 출력값을 받아온다
- 뉴런에 정의된 가중치와 바이어스를 사용해 선형 결합을 진행한다.
- 선형 결합 값에 특정 활성화 함수를 적용하여 비선형 변환을 진행한다.
- 변환된 값을 다음 층의 모든 뉴런에게 전달한다.
-
뉴런과 관련된 추가 사항
-
입력층 바로 다음 은닉층의 뉴런 수가 입력층보다 적다면, 데이터의 중요한 정보를 충분히 학습하지 못해 언더피팅(Underfitting) 문제가 발생할 수 있다.
-
반대로, 은닉층의 뉴런 수가 과도하게 많다면, 과적합(Overfitting) 문제를 초래할 가능성이 있다.
-
일반적으로 초기 은닉층에서는 많은 뉴런을, 그리고 출력층에 가까울수록 적은 뉴런을 사용한다. 이는 점차 의미 있는 고차원 정보를 요약하는 과정으로 볼 수 있으며, 과적합 방지에도 도움이 되는 설계 방법이다.
-
경우에 따라 은닉층마다 균등한 뉴런 수를 사용하여 데이터를 균등하게 처리할 수도 있으며, 선행 연구나 도메인 지식을 기반으로 특정 분포의 뉴런을 설정할 수 있다.
-
은닉층
-
은닉층은 뉴런을 열 방향으로 묶은 단위로, 입력층에서 얻은 원본 데이터를 변환하여 새로운 특징(feature)을 추출하고, 출력층에서 결과를 예측할 수 있도록 중간 다리 역할을 한다.
-
뉴런에서는 활성화 함수를 적용하여 비선형 변환을 진행한다. 따라서, 초기 은닉층은 저수준의 특징을 학습하지만, 마지막 은닉층은 고수준의 추상적 특징을 학습하게 된다.
-
결과적으로 은닉층의 개수는 원본 특징의 비선형 변환 정도를 의미한다고 볼 수 있다.
-
은닉층의 개수가 많아지면 복잡한 데이터를 표현할 수 있는 능력이 증가하지만, 과적합 문제가 발생할 수 있다. 이를 방지하기 위해 정규화 기법(Dropout, L2 Regularization)을 사용할 수 있다.
학습 방법
-
ANN에서의 목적은 Loss를 최소화 하는 방향으로 학습을 진행하는 것이다.
-
이전까지 살펴본 학습기는 은닉층이 없는 ANN와 같다. 따라서 직접적으로 Loss를 최소화 시키는 가중치와 바이어스를 찾을 수 있다.
-
ANN에서는 은닉층이 추가된다. 즉, 은닉층에서 가중치와 바이어스가 어떤 방향으로 수정되어야 Loss가 최소화 되는지를 직접적으로 파악할 수 없다.
-
역전파(Back Propagation)는 은닉층의 가중치와 바이어스가 Loss를 줄이는 방향으로 수정되도록 기울기를 계산하는 알고리즘이다.
-
역전파 (Back Propagation)
- 역전파는 출력층에서 시작해 기울기를 Chain Rule을 통해 계산하여 이전 은닉층으로 전파하는 방식이다.
-
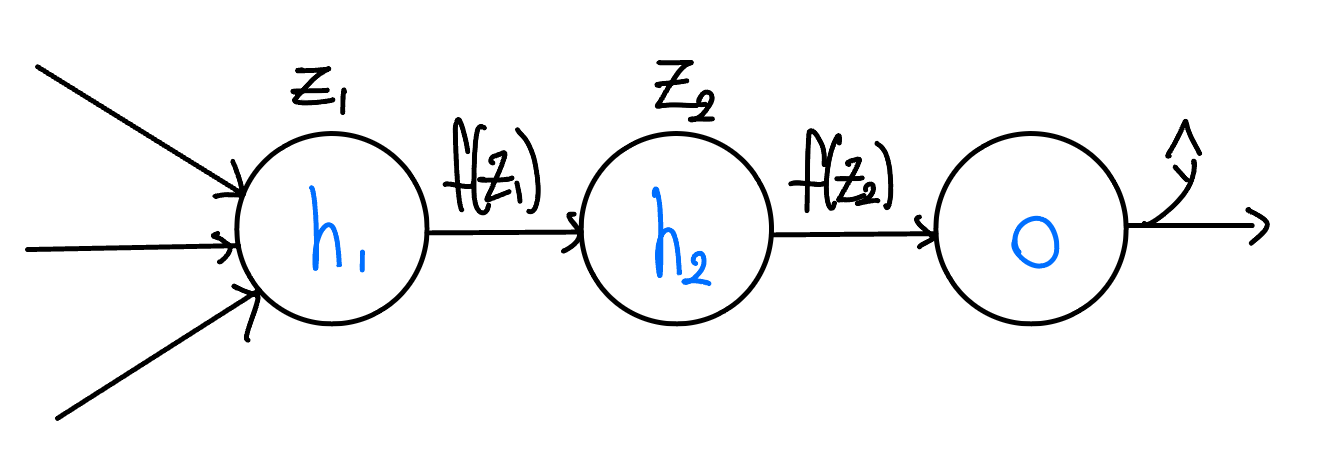
은닉층이 2개, 각각 뉴런이 1개인 간단한 회귀 문제 예시를 통해 역전파 알고리즘의 기본에 대해 알아보자. (바이어스는 제외)
- : 첫 은닉층의 선형 결합 결과 ()
- : 활성화 함수에 을 넣은 결과
- : 두 번째 은닉층의 선형 결합 결과 ()
- : 활성화 함수에 을 넣은 결과
- : 출력층의 예측 결과값 ()
- : 실제값
- 출력층에서 기울기 계산
출력층에서의 손실 함수 에 대해 의 기울기를 계산한다.출력층에서 의 기울기는 다음과 같이 계산된다:따라서:
- 두 번째 은닉층에서의 기울기 계산
두 번째 은닉층 의 기울기는 출력층의 기울기를 Chain Rule을 통해 계산한다.여기서:따라서:
- 첫 번째 은닉층에서의 기울기 계산
첫 번째 은닉층 의 기울기도 마찬가지로 Chain Rule을 통해 계산한다:여기서:따라서:
-
역전파는 출력층에서 계산된 기울기를 Chain Rule을 통해 이전 은닉층으로 전파하면서 각 층의 가중치와 바이어스에 대한 기울기를 계산한다.
-
위 수식을 통해 각 층의 가중치가 Loss에 미치는 영향을 파악하고, 이를 기반으로 가중치를 업데이트하는 방식으로 ANN이 학습을 진행한다.
활성화 함수
-
활성화 함수는 뉴런에서 입력 데이터를 비선형적으로 변환하여 복잡한 데이터 패턴을 학습할 수 있도록 돕는다. 이는 단순 선형 모델이 아닌 비선형 관계를 학습하게 하는 데 필수적이다.
-
ANN은 역전파(Backpropagation)를 통해 가중치와 바이어스를 업데이트하므로, 활성화 함수는 미분 가능해야 기울기를 계산할 수 있다.
- 주요 활성화 함수
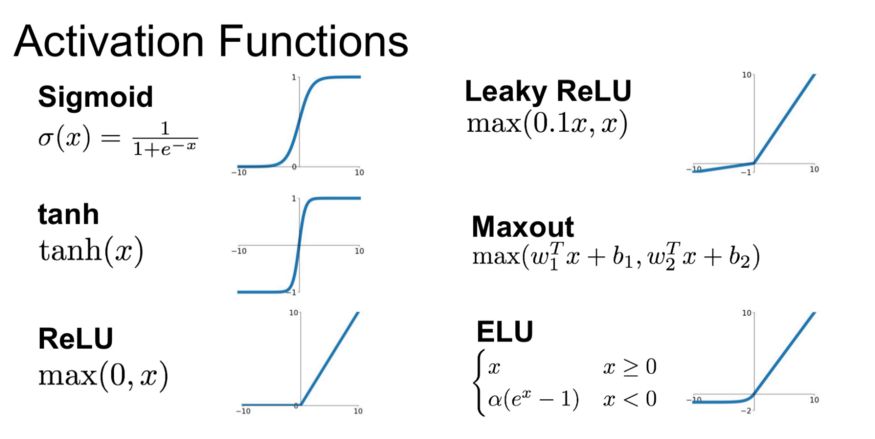
- ReLU(Rectified Linear Unit) : 가장 널리 사용되는 활성화 함수로, 연산이 간단하고 학습 속도가 빠르다.
- Tanh : 출력값을 -1에서 1로 제한하며, 음수와 양수의 구분이 필요한 경우 사용한다.
- Sigmoid : 값이 0과 1 사이로 제한되며, 이진 분류의 출력층에서 사용한다.
-
기울기 소실 문제 (Gradient Vanish)
-
ANN은 역전파를 통해 학습하는 과정에서 초기 은닉층의 기울기는 해당 은닉층의 뒤쪽 은닉층의 기울기를 지속적으로 곱해주는 형태가 된다.
-
이때, 1보다 작은 기울기가 반복적으로 곱해지면 초기 은닉층의 기울기는 0에 가까워질 수 있다.
-
결과적으로 기울기가 사라져 학습이 진행되지 않는 현상이 발생할 수 있다.
-
Sigmoid, Tanh의 경우 출력값의 범위가 작아 Gradient Vanish 문제가 발생할 가능성이 높다.
-
반면, ReLU는 양수 입력에 대해 기울기가 일정하여 기울기 소실 문제가 발생하지 않는다. 그러나 죽은 뉴런 문제가 발생할 수 있어, 이를 개선한 Leaky ReLU, Parametric ReLU 등이 사용되기도 한다.
-
