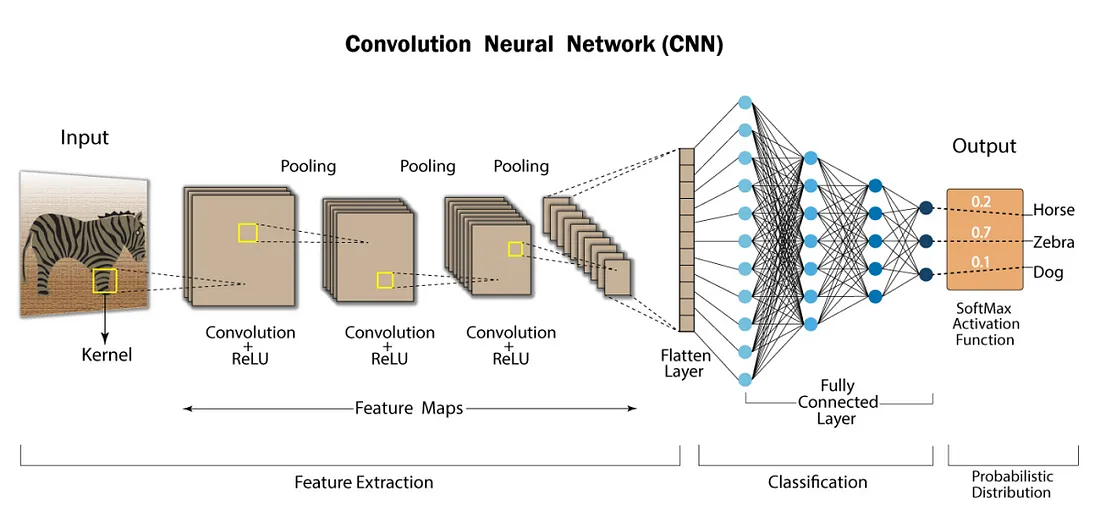
CNN (Convolutional Neural Networks)
- 입력 데이터의 공간적 구조를 파악하여 이미지, 객체 인식 분야에서 자주 사용하는 딥러닝 모델.
-
CNN의 구성 요소는 크게 네가지로 나눌 수 있다.
-
합성곱 계층 (Convolution Layer) : 입력 이미지에 복수의 필터(Kernel)를 적용하여 특징 맵(Feature Map)을 생성. 이를 통해 이미지의 다양한 특징을 추출할 수 있다.
- 키워드 : [Kernel, Convolution, Stride, Padding]
-
풀링 계층 (Pooling Layer) : 특징 맵의 크기를 줄여 계산량을 감소시키고, 중요한 특징을 강조한다.
- 키워드 : [Max Pooling, Average Pooling]
-
평탄화 계층 (Flattening Layers) : 입력된 다차원 배열(Feature Map)을 1차원 벡터로 변환한다.
-
완전 연결 계층 (Fully Connected Layer) : 추출한 특징을 기반으로 최종 분류를 수행한다. Softmax 함수를 활용해 각 클래스에 대한 확률을 계산.
- 키워드 : [ANN, SoftMax]
-
이미지의 숫자 표현
- 디지털 이미지는 작은 정사각형으로 이루어진 격자로 구성되며, 이 정사각형 하나하나를 '픽셀(Pixel)'이라고 한다.

-
Raster Graphics System에서 하나의 이미지는 다수의 픽셀로 표현된다.
(ie. 해상도 1920 x 1080 -> 총 2,073,600 픽셀) -
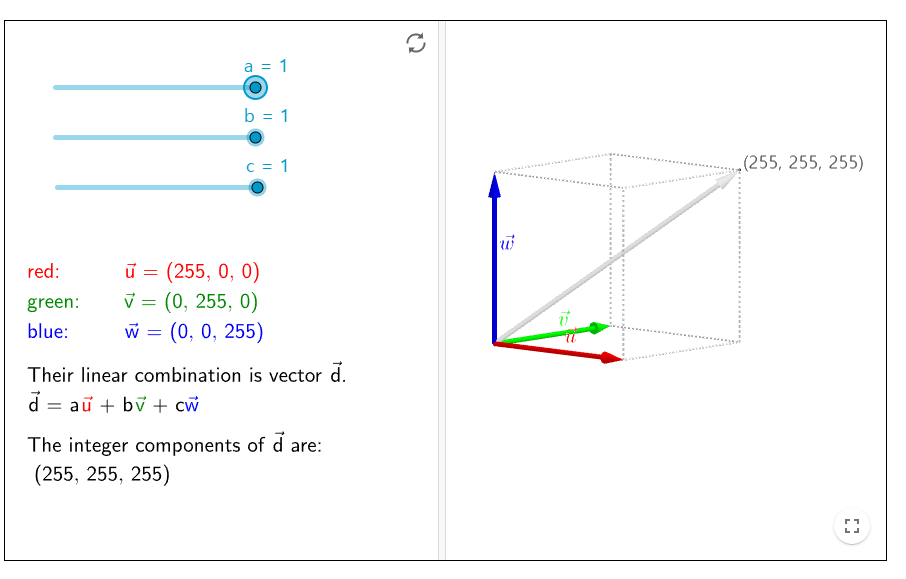
각 픽셀은 (Red, Green, Blue) 값의 조합으로 색을 나타내며, 이는 인간이 보는 시각적 정보로 변환된다.
-
RGB 각각은 8비트 메모리를 사용해 0~255의 밝기를 표현하며, 총 24비트(8x3)의 정보를 포함한다.
-
결과적으로, 하나의 픽셀은 벡터 (R, G, B)로 표현되며, 전체 이미지는 픽셀을 요소로 가지는 3차원 행렬(Width x Height x 3)로 나타낼 수 있다.
-
앞으로는 설명을 단순화하기 위해 흑백 이미지(Gray Scale Image)를 사용한다.
기본적인 개념은 RGB와 같지만, 픽셀당 8비트만 사용하며, Black 색상만 사용하는 방식이다.
즉, 각 픽셀 값은 0(검은색)에서 255(흰색) 사이의 값으로 표현된다.

합성곱 계층 (Convolution Layer)
Kernel
-
이제, 이미지를 행렬로 표현한 상태에서 커널(Kernel)에 대해 알아보자.
커널은 카메라 앱에서 사용하는 사진 필터라고 생각하면 이해하기 쉽다.
-
원본 이미지에 특정 행렬(커널)을 적용해 컨볼루션(합성곱) 연산을 수행하여 목적에 맞게 변환한다.

-
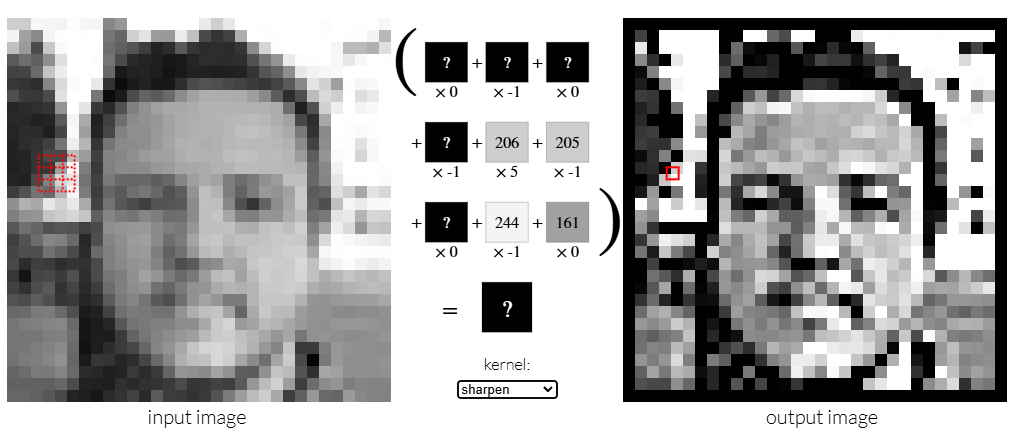
Kernel은 x 크기의 정사각형 행렬로, 목적에 따라 다양한 변환(Sharpen, Blur, Sobel Filter)을 통해 특정 특징을 강조하거나 추출하는데 사용한다.
-
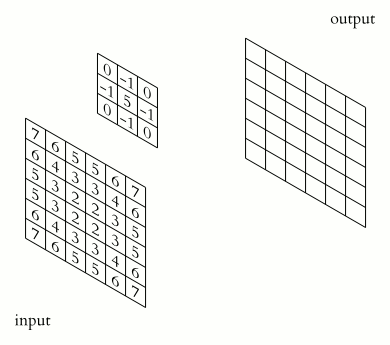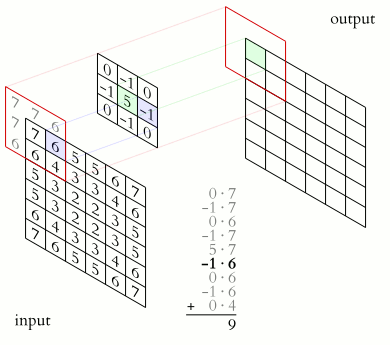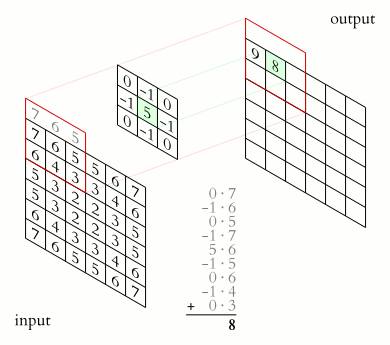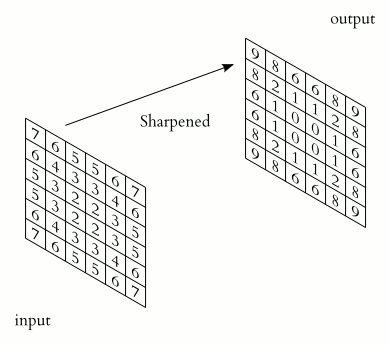
Convolution 과정은 이미지 행렬의 픽셀을 부터
까지의 픽셀 범위에 커널을 적용하고, 합성곱으로 표현하는 과정이다.- 일반적으로 커널의 크기 은 홀수로 설정한다. (커널의 중심 픽셀을 명확히 정의)
- 이 커질수록 합성곱에 포함되는 픽셀 범위가 넓어져 이미지의 넓은 정보를 반영할 수 있다.
- 따라서, 은 일반화의 정도로 해석할 수 있으며, 목적 및 데이터 특성에 맞는 크기로 설정한다.
- 커널을 이미지 전체에 반복 적용하며, 새로운 행렬로 변환된 이미지를 생성한다.
이후, 각 채널에서 생성된 결과는 합쳐져 최종 Convolution 결과로 출력된다.
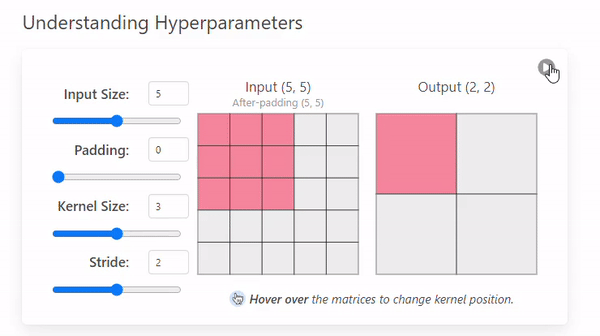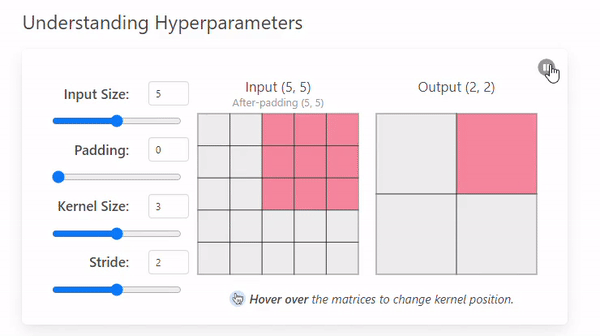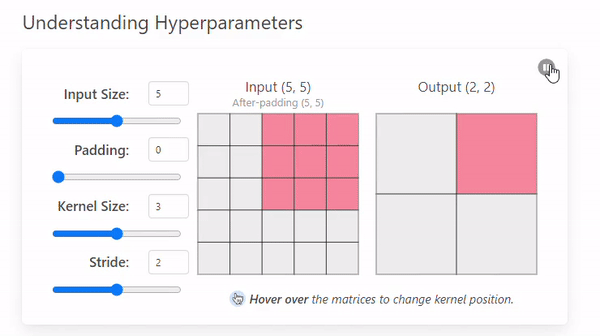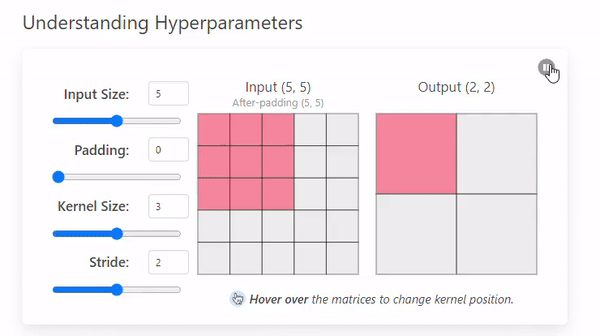
Stride
-
Stride는 커널이 이미지를 이동하며 연산할 때 건너뛰는 픽셀의 수를 의미한다.(= 발걸음)
-
Stride = 1
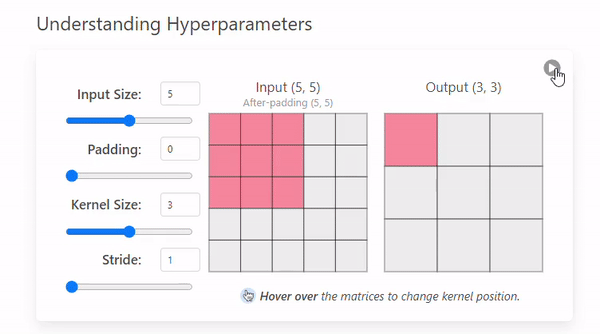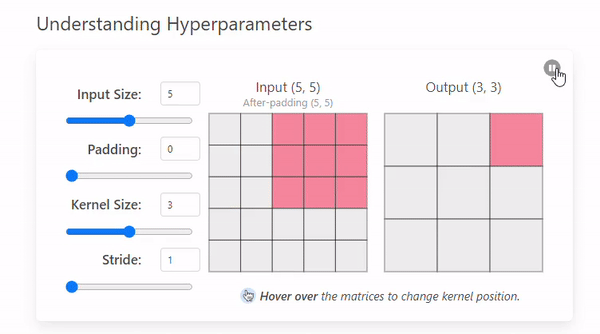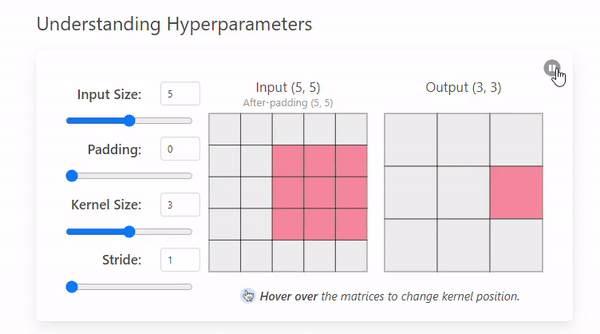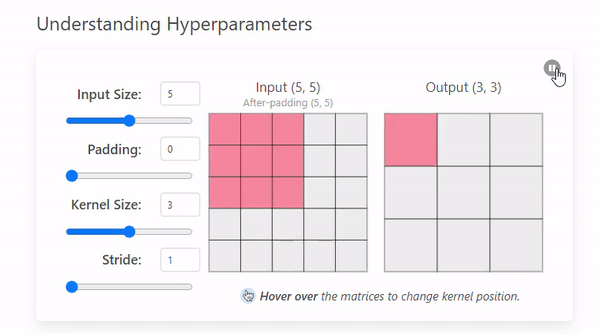
- Stride = 2
-
Stride 크기에 따른 특징
Stride 크기 Output 크기 특징 분석 범위 연산 비용 과적합 가능성 작은 Stride 크다 세밀 크다 높다 큰 Stride 작다 (압축됨) 광범위 작다 낮다
Padding
-
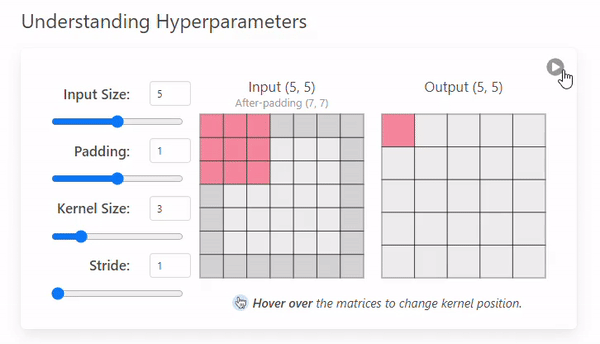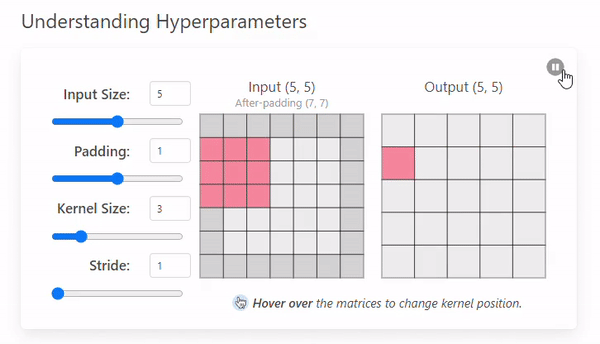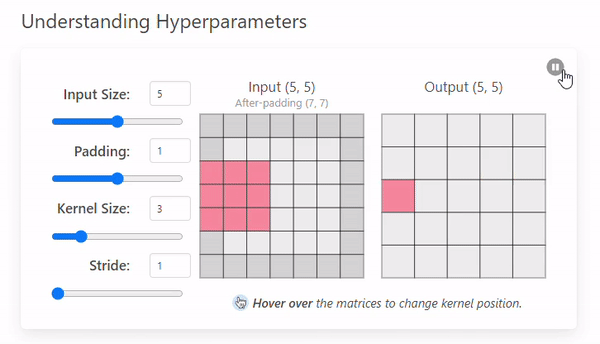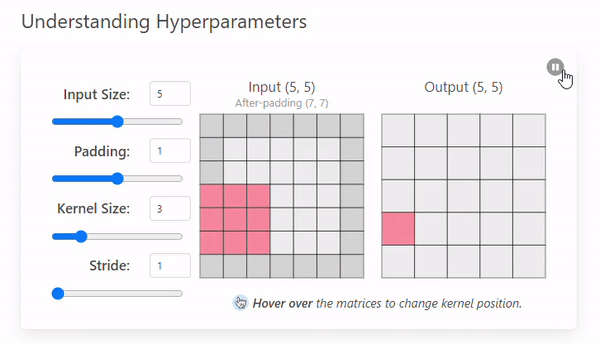
Padding은 입력 이미지의 가장자리에 추가적인 픽셀을 삽입하는 작업으로 출력 크기를 조절하거나, 가장자리 정보를 보존하기 위해 사용한다.
-
Stride = 1의 예시에 Padding = 1을 추가하여 비교해보자.
-
이미지의 가장자리에 추가 픽셀을 통해 (0, 0)부분의 픽셀 정보를 보존한다
-
입력 이미지의 크기가 증가하여, 출력 크기가 커진다.
-
-
대칭 패딩을 적용한 경우 Output Size의 공식은 다음과 같다.
-
ex) 입력 크기: 5x5, Kernel 크기: 3x3, Padding = 1, Stride = 1
-
-
일반적인 패딩의 종류
Padding 종류 설명 특징 Valid Padding
(No Padding)패딩 없음, 커널이 이미지 내부 영역만 활용 출력 크기 감소
가장자리 정보 손실 발생Same Padding 출력 크기를 입력 크기와 동일하게 유지하기 위해 패딩 추가 출력 크기 유지
가장 널리 사용됨Zero Padding 이미지의 가장자리를 0으로 채움 Same Padding 구현에 주로 사용됨
합성곱 계층의 출력
-
합성곱 계층 (Convolution Layer)에서는 kernel과 Convolution을 통해 이미지를 변환하고, Stride와 Padding이라는 파라미터를 사용하여 출력 사이즈를 조절할 수 있었다.
- 합성곱 계층에서 출력 이미지는 커널의 개수, 즉 만큼 생성된다.

- 각각의 출력 이미지는 원본 이미지의 서로 다른 특징을 강조/추출한 형태이다.
-
출력 이미지 행렬에 활성화 함수(Relu, ...)를 적용하여 Feature Map을 만들어 낸다.
-
활성화 함수를 적용하는 이유 :
- 비선형성 추가: 복잡한 패턴을 학습할 수 있도록 변환.
- 특징 강조: ReLU 등으로 양수 값만 남겨 특징이 두드러지게 표현.
- 학습 효율성 개선: 네트워크가 더 빠르고 효과적으로 학습 가능.
-
-
파라미터를 통해 Feature Map의 출력 사이즈를 조절할 수 있지만, 합성곱 계층의 가장 중요한 요소는 특징 추출과 선형/비선형 변환을 통해 원본 이미지의 다양한 특징을 표현하는 Feature Map을 구성하는 것이다.
풀링 계층 (Pooling Layers)
- 풀링 계층에서는 합성곱 계층에서 생성한 Feature Map의 차원을 축소하며, 주요 특징을 추출하는 것이 목표이다.
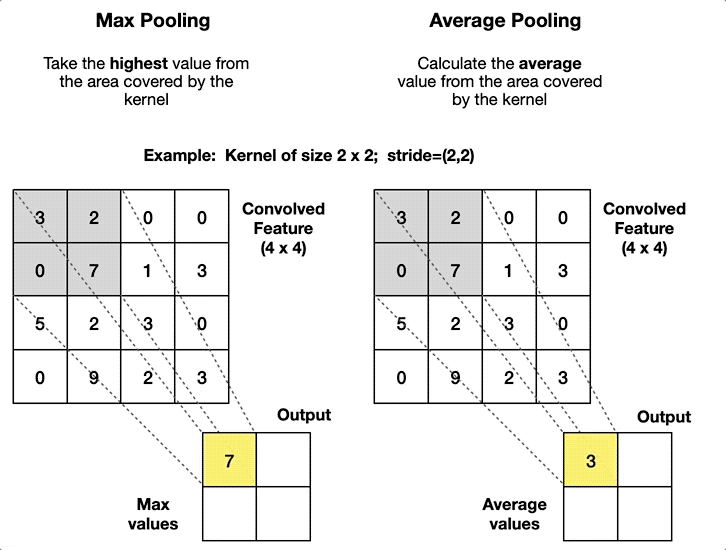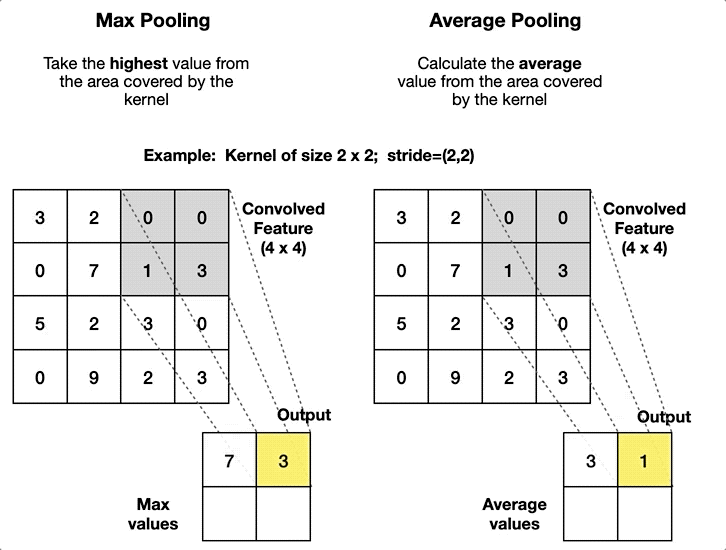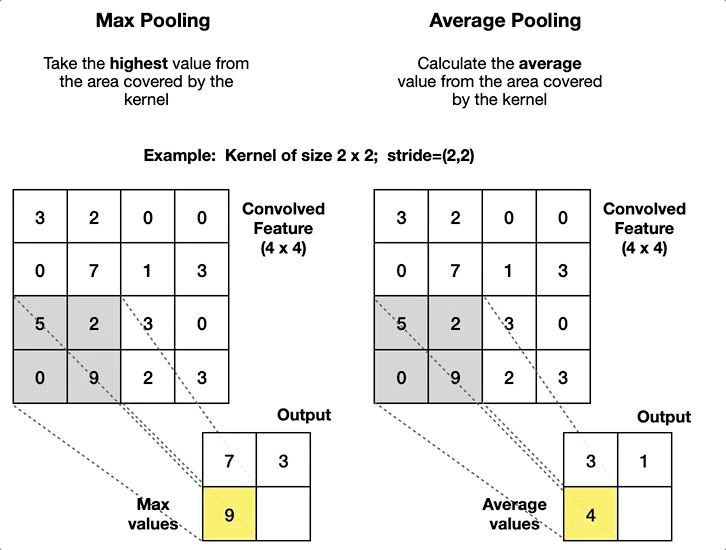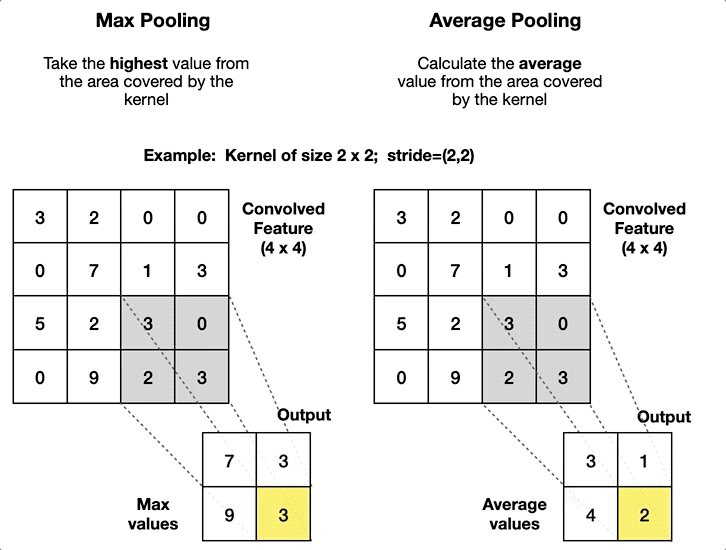
풀링 (Pooling)
-
작동 원리
-
fixed-size window(ex. 2x2, 3x3, ...)를 Stride만큼 이동하며 주요 특징을 추출한다.
-
윈도우 크기와 Stride 설정에 따라 풀링 영역이 서로 겹칠 수도, 겹치지 않을 수도 있다.
-
-
일반적인 풀링의 종류
풀링 방식 설명 특징 활용 사례 Max Pooling 윈도우 내에서 가장 큰 값을 선택 중요 특징 강조
크기 감소이미지에서 경계선/윤곽선 탐지 Average Pooling 윈도우 내 평균값을 계산 부드러운 요약
노이즈 감소저해상도 이미지나 음성 데이터 처리 Global Pooling Feature Map 전체에 대해 Max 또는 Average 풀링 수행 1x1로 축소
전역 특징 요약네트워크 끝단
풀링 계층의 결과물
-
이전 합성곱 계층에서 전달받은 Feature Map에 풀링을 적용하여, 다음 합성곱 계층이나 평탄화 레이어에 전달한다.
-
풀링된 Feature Map의 특징
-
풀링은 각 Feature Map에 독립적으로 적용되므로 Feature Map의 개수는 변하지 않는다.
-
Feature Map의 차원이 축소되어 연산 비용이 감소된다.
-
주요 특징만 남기고 불필요한 정보는 제거되어, 노이즈에 강건해지고 과적합 위험이 줄어든다.
-
평탄화 레이어 (Flattening Layers)
-
일련의 "Convolution - Pooling" 과정을 거친 후, Fully Connected Layer 앞에서 다차원 Feature Map을 1차원 벡터로 변환하는 계층.
-
CNN의 Fully Connected Layer는 1차원 데이터를 입력으로 사용하기 때문에, 이 과정은 필수적이다.
# Feature Map : 3 x 3 x 2
Feature Map 1 =
[1, 2, 3]
[4, 5, 6]
[7, 8, 9]
Feature Map 2 =
[10, 11, 12]
[13, 14, 15]
[16, 17, 18]
# Flatten Vector : 1 x 18
Flatten =
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18]
-
Convolution Layer와 Pooling Layer에서 학습된 다양한 특징들을 결합하여, 최종적으로 분류(Classification) 또는 예측(Regression) 작업에 적합한 형식으로 변환한다.
-
평탄화는 단순히 데이터 형식을 1차원으로 변환하는 과정이므로, 정보 손실은 없다.
Global Pooling VS Flatten Layer
| 항목 | Flatten Layer | Global Pooling |
|---|---|---|
| 목적 | 다차원 데이터를 1차원 벡터로 변환 | Feature Map의 전역적 특징을 요약 |
| 출력 크기 | ||
| 활용 | Fully Connected Layer와 결합 | Fully Connected Layer 없이 분류 수행 가능 |
| 장점 | 모든 데이터를 유지, 복잡한 패턴 학습 가능 | 파라미터 감소로 연산량 최적화 가능 |
| 단점 | 파라미터 수 증가로 과적합 가능성 | 정보 손실 발생 가능 |
-
Global Pooling과 평탄화 계층은 CNN의 마지막 부분에서 서로 대체 가능하며, 설계 목적에 따라 선택 가능하다.
-
평탄화 계층을 사용하는 경우 :
- Fully Connected Layer와 함께 사용하는 전통적인 CNN 설계
- 모든 데이터를 유지해 더 많은 정보를 학습에 활용하고 싶은 경우
-
Global Pooling을 사용하는 경우 :
- Fully Connected Layer가 없는 간소화된 모델(예: ResNet, GoogLeNet) 설계
- 소규모 데이터셋이나 메모리 제한 환경에서 파라미터 최적화가 필요한 경우
-
완전 연결 계층 (Fully Connected Layer)
- CNN의 완전 연결 계층은 우리가 알고 있는 ANN과 동일한 구조/역할을 수행한다.
(ANN 기초)
CNN 학습과정
분류 예시를 통한 CNN 과정 정리
-
Initialize Kernel, Fully Connected Layer weights
- 각 커널 및 Fully Connected Layer의 가중치는 랜덤 초기화된 값(일반적으로 0에 가까운 소수값)으로 초기화된다
-
Foward Pass
-
Convolution & Pooling:
- 입력 이미지에 대해 Convolution Layer → Pooling Layer의 연속된 연산을 수행하여 Feature Map을 생성.
- 각 단계에서 특징 추출을 진행하며, 데이터가 압축된다.
-
Flatten & Fully Connected Layer:
-
Pooling Layer의 출력을 Flatten Layer에서 1차원 벡터로 변환
-
Fully Connected Layer에서 입력된 Flatten 벡터를 기반으로 분류 진행
-
-
-
Calculate Loss
- 손실 함수(Cross Entropy)를 통해 Loss를 계산
-
Backpropagation
-
Fully Connected Layer:
- Loss에 대한 기울기(Gradient)를 계산하고, 역전파(Backpropagation)를 통해 가중치를 수정.
- Flattening Layer의 직전 뉴런까지만 역전파를 수행.
-
Flatten Layer (비학습):
- Flatten Layer는 크기의 기울기를 로 복원하여 직전 Layer의 Feature Map과 같은 크기로 변환한다.
- 이후, 직전 Layer(여기서는 Pooling Layer)로 해당 기울기를 전달.
-
Pooling Layer (비학습):
-
이전 레이어에서 전달받은 기울기와 Pooling 함수의 미분을 사용해 Convolution Layer로 전달할 기울기를 계산.
-
이 과정에서 Pooling 함수의 미분을 사용해 기울기를 적절히 분배하는데, 이를 Routing이라고 한다.
-
-
Convolution Layer:
- Pooling Layer를 거쳐 역전파된 손실은 각 Convolution Layer의 커널에 전달된다.
-
-
Iteration
- 수정된 가중치를 사용하여 다시 Forward Pass → ... → Update Weights를 반복
- 데이터셋 전체를 여러 번 학습(Epoch)하여 손실을 점진적으로 줄인다.
CNN의 강점
-
CNN(Convolutional Neural Network)은 초기 층에서 세부적인 특징(로컬 패턴)을 학습하고, 이후 층에서는 이를 바탕으로 더 일반화된 특징(글로벌 패턴)을 추출하는 과정을 반복적으로 진행하는 구조라고 할 수 있다.
-
초기 층 (Shallow Layers):
- 세부적인 특징(로컬 패턴)을 학습
ex) 합성곱 계층과 풀링 계층을 통해 에지, 선, 텍스처등 저수준의 특징을 추출.
- 세부적인 특징(로컬 패턴)을 학습
-
깊은 층 (Deep Layers):
- 여러 층에서 추출된 세부적/중간적 특징을 조합하여 전체적인 형태나 고수준의 특징을 학습 ex) 전체 얼굴, 자동차, 동물 등 추상적이고 일반화된 개념을 학습.
-
-
CNN은 이러한 계층적 구조(hierarchical structure)를 사용하기 때문에, 높은 일반화 성능을 기대할 수 있다.
참고자료
