Perceptron의 분류 결과
-
Perceptron은 계단 함수를 사용하여 이진 분류를 진행한다. 즉, 예측값 이 0보다 크면 1, 0보다 작으면 0의 값으로 분류한다.
-
이렇듯 Perceptron의 분류 결과는 명목변수(norminal variable)이다. 명목변수는 단순한 구분기호이며, 순서/간격/비율/계산이 불가능한 가장 낮은 수준의 정보를 가지는 변수이다.
-
이진 분류의 결과를 비율변수(ratio variable), 즉 가장 높은 수준의 정보를 제공하는 변수로 변환할 수 있다면 보다 다양한 해석이 가능하며, 손실함수의 개념을 적용하여 모델이 얼마나 잘못된 예측을 하고 있는지를 수치적으로 나타낼 수 있을 것이다.
Logistic Regression
- Logistic Regression은 이진 분류 문제를 확률적 접근으로 해결하는 방법이다. 즉, 특정 데이터 포인트가 '클래스 0'에 속할 확률과 '클래스 1'에 속할 확률을 출력값으로 갖는다.
확률적 접근 : Logistic Function
-
Logistic Regression은 기본적으로 독립 변수들의 선형 결합(가중합)을 기반으로 한다.
-
이진 분류에서 확률은 다음과 같은 특성을 가져야한다.
-
-
확률을 선형 결합의 범위와 일치시키기 위해 로그 오즈(log-odds) 변환을 수행한다.
-
이를 Logistic Regression의 목표인 로 정리한다
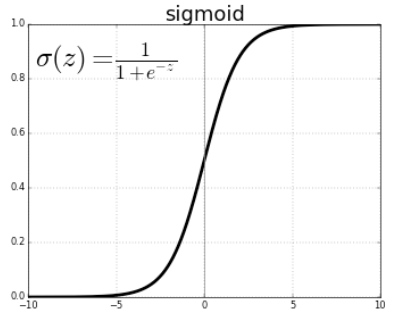
우변의 분자와 분모에 를 곱해 Sigmoid 함수로 변환한다.
-
위 함수가 Logistic Regression에서의 활성화 함수이며, Perceptron의 계단함수와 달리 확률적 접근으로 분류를 진행할 수 있게 해준다.
- 여기서 가 로지스틱 함수이며, 시그모이드 함수의 한 종류이다.
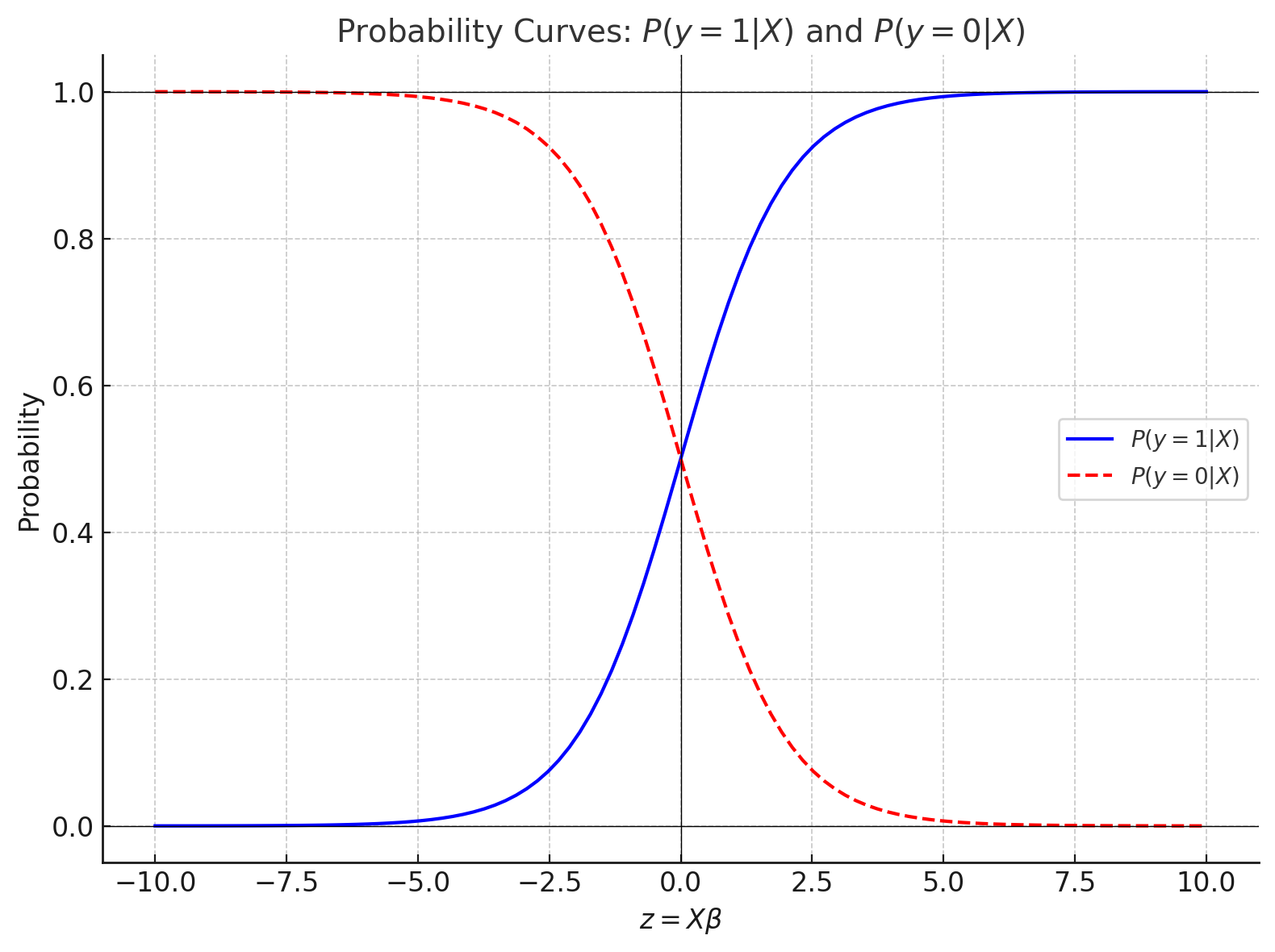
-
파란색 실선이 , 빨간색 점선이 의 그래프이다.
이때, 임을 확인할 수 있다. -
로지스틱 함수를 포함한 일반적인 시그모이드 함수는 다음과 같은 특성을 갖는다.
- 연속적이고 미분 가능하며, 1차 미분 그래프는 종 모양을 가진다.
- 단조 함수(monotonic function)이다 = 왼쪽에서 오른쪽으로 줄곧 상승하거나 줄곧 하강한다.
- 일 때, 한 쌍의 수평 점근선으로 수렴한다.
- 0보다 작은 값에서 볼록하고 0보다 큰 값에서 오목한, S자 형태의 그래프를 갖는다.
Logistic Regression의 손실함수
-
MSE(Mean Squared Error) : 선형 회귀 식과 실제 데이터 포인트의 거리를 기반으로 계산한다. 하지만 로지스틱 회귀에서는 확률 값의 비선형적인 특성을 반영하지 못해 일반적으로 사용하지 않는다.
-
Log Cost Function(Cross-Entropy Loss) : 확률의 특성을 반영하여, 예측값이 0 또는 1에 가까울수록 손실이 급격하게 줄어드는 비선형 손실 함수이다.
-
라고 할 때 비용(Cost)은 다음과 같다.
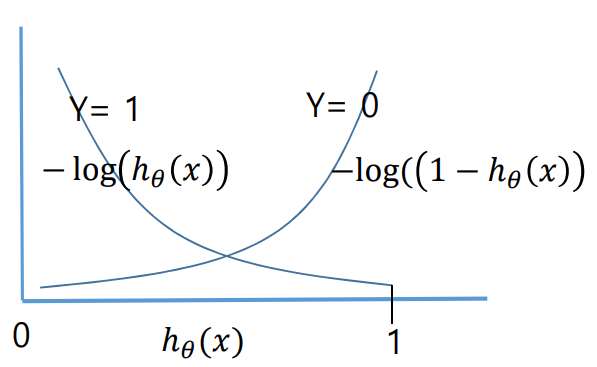
-
이진분류에서는 y가 0또는 1의 값을 가지므로, 손실함수를 다음과 같이 일반화할 수 있다.
Log Cost Function의 특징
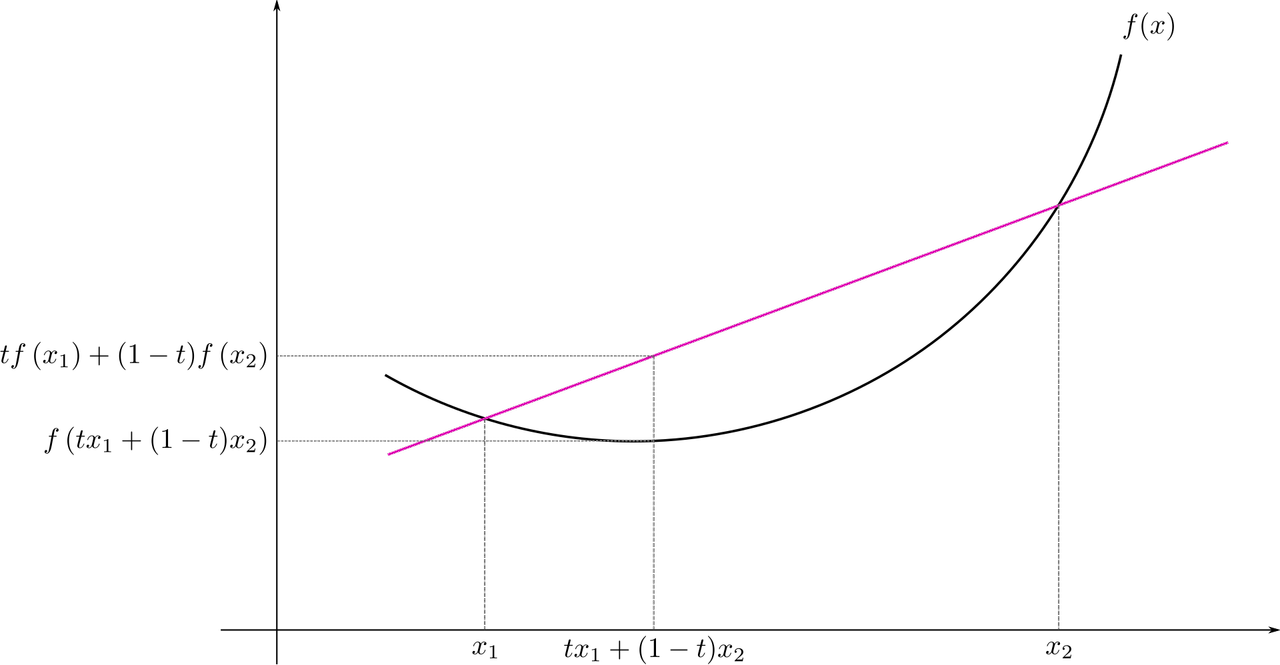
- Convex Funciton : 아래로 볼록한 형태를 가지며, 함수 위의 두 점을 연결한 선분이 항상 함수 곡선보다 위에 위치하여, 단 하나의 전역 최소점만 가진다. 따라서, 경사 하강법(Gradient Descent)을 사용하여 최적의 계수를 찾는 데 매우 유리하다.
-
MLE에서 최적 추정량 = Log Cost Function에서 최적 추정량
-
이진 분류이기 때문에 MLE에서 이항분포를 가정한다.
따라서, 데이터 전체에 대한 우도 함수는 다음과 같다.
-
계산의 편의성을 위해 로그 우도 함수로 변환한다.
-
위 식을 과 의 경우로 나눠 적절하게 표현해준다.
-
이때, Log Cost Function을 로그 우도 함수의 음(-)의 형태로 정의된다.
-
따라서, Log Cost Function을 최소화하는 과정은 로그 우도 함수를 최대화하는 과정과 동일하다.
-
즉, Log Cost Function을 통해 구한 추정량은 이론적으로 이항 분포에 가장 적합한 추정량이다.
-
확률적 접근의 이점
-
출력 값의 해석 가능성 :
- 보다 으로 예측한 것이 신뢰도가 더 높다는 의미를 가진다.
- 불확실성이 큰 데이터에 대해서는 확률이 에 가까운 값을 출력하여, 모델이 해당 데이터를 예측하는 데 확신이 낮음을 표현할 수 있다.
- 회귀계수를 오즈비(odds ratio, )로 변환하여 독립변수 가 한 단위 증가할 때 특정 클래스에 속할 확률의 상대적 변화를 해석할 수 있다.
-
다양한 임계값 조정 가능
- 임계값을 높게 설정하면 보수적인 분류, 작게 설정하면 공격적인 분류가 가능하다.
- 문제의 특성에 맞게 위험 관리를 하거나, 비대칭적인 클래스 분포를 다룰 수 있다.
-
다중 클래스 확장성
- 소프트맥스 함수를 사용하면 다중 클래스 분류 문제로 자연스럽게 확장할 수 있는 유연성을 제공한다.
-
평가 지표의 다양성
- ROC 곡선을 통해 임계값에 따른 모델 성능, AUC 값을 사용하여 모델의 전체적인 성능을 평가할 수 있다.
scikit-learn의 Logistic Regression
| parameter | default value | description | option |
|---|---|---|---|
penalty | l2 | 규제(정규화) 방식 | l1, l2, elasticnet, none |
dual | False | 이중 최적화 문제를 풀지 여부. 고차원 데이터에 주로 사용 | bool |
tol | 1e-4 | 손실 함수의 수렴 허용 오차. 작은 값일수록 더 정밀한 수렴 | float |
C | 1.0 | 규제 강도(역수). 작은 값일수록 규제가 강하게 작용 | float |
fit_intercept | True | 절편을 학습할지 여부 | bool |
intercept_scaling | 1 | liblinear 솔버에서 절편의 스케일을 조정 | float |
class_weight | None | 클래스 가중치 설정. 'balanced'는 클래스 불균형을 자동 조정 | dict, balanced |
solver | lbfgs | 최적화 알고리즘 설정 | newton-cg, lbfgs, liblinear, sag, saga |
max_iter | 100 | 최대 반복 횟수. 수렴하지 않으면 이 값을 늘릴 수 있음 | int |
multi_class | auto | 다중 클래스 분류 방식 | auto, ovr, multinomial |
n_jobs | None | 병렬 처리할 작업 수. -1은 모든 CPU 코어 사용 | int |
verbose | 0 | 학습 과정에서 로그 출력 여부. 값이 높을수록 상세한 로그 출력 | int |
warm_start | False | 이전 학습 결과를 재사용할지 여부 | bool |
l1_ratio | None | elasticnet의 L1과 L2 규제의 혼합 비율. | 0~1 |
solver

| 알고리즘 | 설명 | 사용 상황 | 장점 | 단점 |
|---|---|---|---|---|
newton-cg | Newton-CG 방식 | 고차원 문제, 다중 클래스 분류 | 고정밀, 빠른 수렴 | 대규모 데이터에서 비효율적 |
lbfgs | L-BFGS 방식 | 다중 클래스 분류, 대규모 데이터 | 메모리 효율적, 안정적 | 일부 상황에서 수렴 속도 느릴 수 있음 |
liblinear | 작은 데이터셋에 적합 | 작은 데이터셋, 이진 분류 | L1/L2 규제 모두 지원 | 다중 클래스 분류에 비적합 |
sag | Stochastic Average Gradient | 대규모 데이터셋 | 대규모 데이터에서 효율적 | 작은 데이터에서 비효율적 |
saga | 개선된 SAG | L1, L2, ElasticNet 규제 | 모든 규제에서 성능 우수 | 작은 데이터셋에서 비효율적 |
multi_class
| 옵션 | 설명 | 사용 상황 |
|---|---|---|
auto | solver에 따라 자동으로 결정 | lbfgs, newton-cg, sag, saga와 함께 사용할 때 multinomial로 설정되며, liblinear와 함께 사용할 때는 ovr로 설정됨 |
ovr | One-vs-Rest. 각 클래스에 대해 독립적으로 이진 분류기를 학습하여 다중 클래스 문제 해결 | 이진 분류 문제를 다중 클래스 문제로 확장할 때 사용. 기본적인 방식으로, 모든 solver와 함께 사용할 수 있음 |
multinomial | 다항 로지스틱 회귀를 사용하여 다중 클래스 문제 해결 | lbfgs, newton-cg, sag, saga에서만 지원되며, 클래스가 세 개 이상인 경우에 적합 |
사진 출처
-
Sigmoid : 직접 생성
-
Log Cost Function : 강의자료
-
볼록함수 : Convex function 설명
-
solver : LogisticRegression - scikit-learn
